个人项目
| 这个作业属于哪个课程 | 软件工程4班 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 实现个人项目:论文查重 |
这个作业的GitHub地址:作业地址
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 15 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 200 | 180 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 200 |
| Design Spec | 生成设计文档 | 5 | 15 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| Design | 具体设计 | 20 | 30 |
| Coding | 具体编码 | 240 | 120 |
| Code Review | 代码复审 | 20 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 40 |
| Reporting | 报告 | 30 | 60 |
| Test Repor | 测试报告 | 20 | 20 |
| Size Measurement | 计算工作量 | 10 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 15 | 10 |
| 合计 | 650 | 755 |
计算机接口的设计与实现过程
使用python标准库difflib中的类difflib.SequenceMatcher计算相似度,输出格式化的相似度百分比。本程序主要分为四个模块,分别是文件读取模块,文件转换模块,文件分析模块,以及控制各个模块的主函数。
文件读取模块
def read_file(path):
# 读取文件
try:
with open(path, 'r', encoding='utf-8') as file:
return file.read()
except FileNotFoundError:
print(f'文件不存在:{path}')
except Exception as e:
print(f'读取文件时发生错误:{e}')
return None
文件转换模块
def lowercase(text):
# 去除文本当中的标点符号并将文本小写
try:
text = text.translate(str.maketrans('', '', string.punctuation)).lower().replace(' ', '')
return text
except Exception as e:
print(f'处理文本时发生错误:{e}')
return None
文件重复率计算模块
def calculate_similarity(original_text, copied_text):
# 计算两个文本的相似度
matcher = difflib.SequenceMatcher(None, original_text, copied_text)
matching_blocks = matcher.get_matching_blocks()
matching_amount = sum(block.size for block in matching_blocks)
if max(len(original_text), len(copied_text)) != 0:
copy_percentage = matching_amount / max(len(original_text), len(copied_text))
return copy_percentage
return -1
主函数模块
def main():
# 主函数。处理命令行输入,读取文件,计算相似度,并输出结果。
# 检查命令行参数
if len(sys.argv) != 4:
print("用法:python main.py 原文文件路径 抄袭文件路径 输出文件路径")
sys.exit(1)
# 获取文件路径
original_path, copied_path, output_path = sys.argv[1:]
# 读取文件内容
original_text = read_file(original_path)
copied_text = read_file(copied_path)
# 文本预处理
original_text = lowercase(original_text)
copied_text = lowercase(copied_text)
# 计算查重率
similarity_percentage = calculate_similarity(original_text, copied_text)
if similarity_percentage == -1: # 异常标识-1
with open(output_path, 'a', encoding="utf_8") as output_file:
output_file.write("ERROR")
return
# 写入输出文件
with open(output_path, 'w', encoding="utf_8") as output_file:
output_file.write(f"{similarity_percentage:.2%}")
if __name__ == "__main__":
main()
计算模块接口部分的性能改进
使用Pycharm中的性能分析软件profiler可以得到性能分析图和各模块所消耗的时间
性能分析图
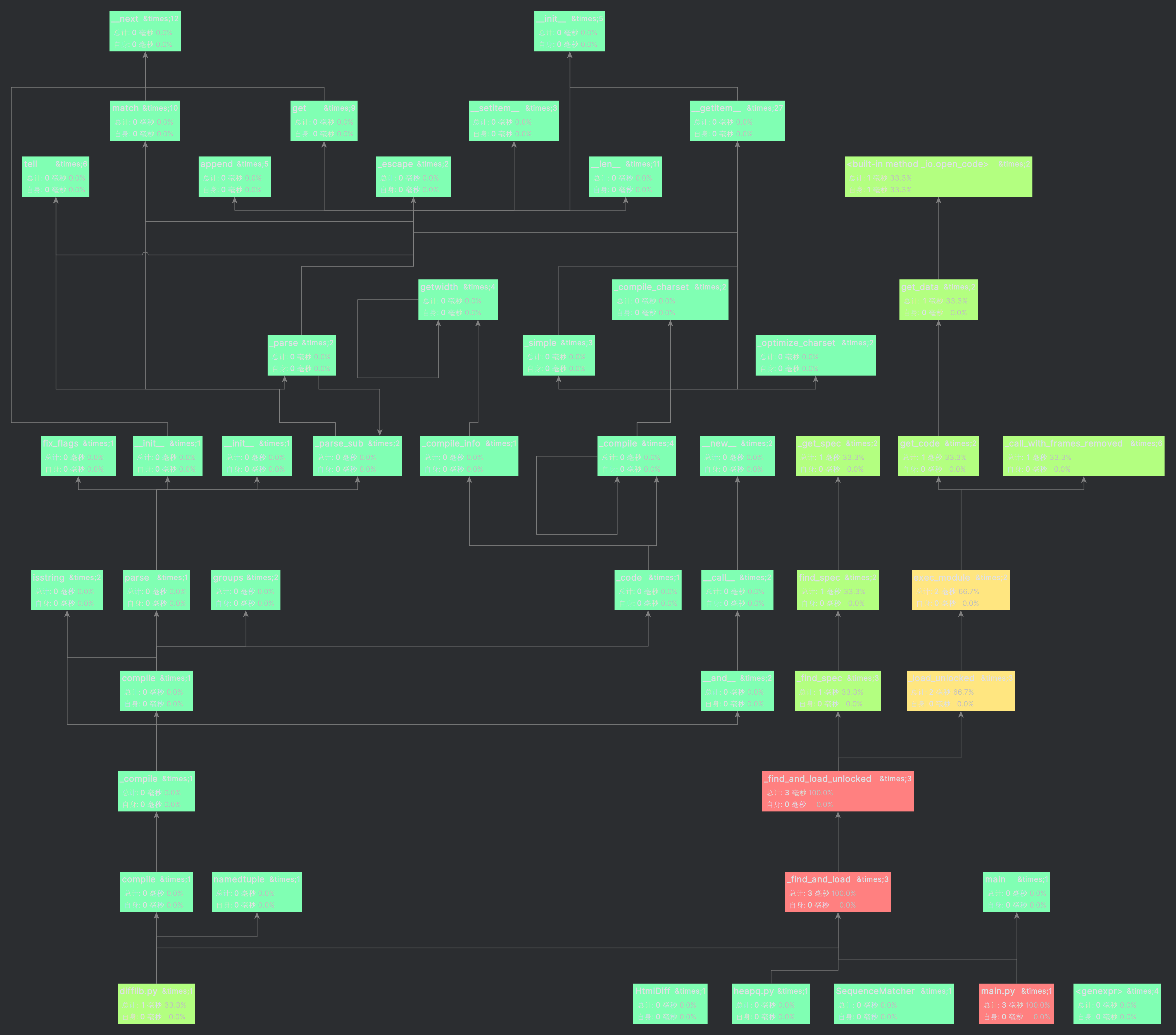
函数消耗时间展示
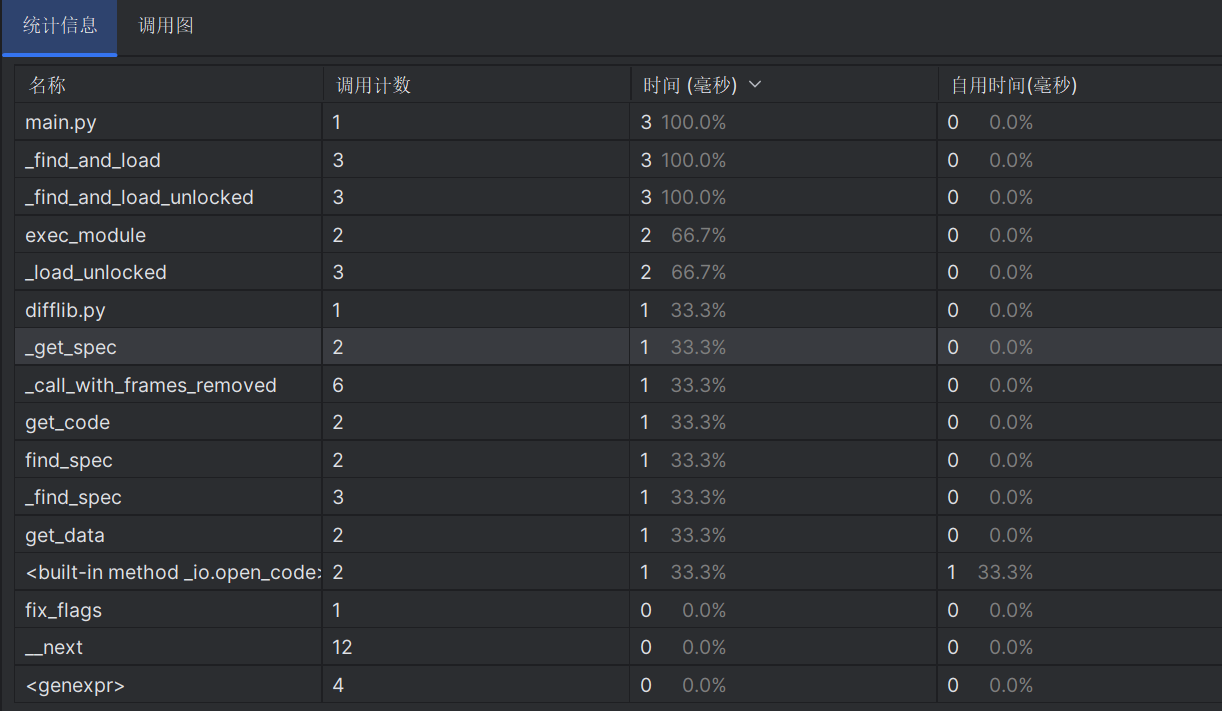
可以看到消耗时间最大的是主函数,其调用其他模块所花费时间较多,其次就是文件的查找和读写模块。
计算模块部分单元测试展示
测试模块部分代码
def test_read_file(self):
# 测试文件的读写功能
temp_file = 'temp_test_file.txt'
with open(temp_file, 'w', encoding='utf-8') as file:
file.write('testfile.')
self.assertEqual(read_file(temp_file), 'testfile.')
os.remove(temp_file)
def test_none_file(self):
self.assertEqual(read_file('invalid_file.txt'), FileNotFoundError)
def test_translate(self):
# 测试文件的预处理模块
text = "testfile."
preprocessed_text = lowercase(text)
self.assertEqual(preprocessed_text, "testfile")
def test_same(self):
# 测试相同文本的相似度
original_text = "Hello, world!"
copied_text = "Hello, world!"
self.assertEqual(calculate_similarity(lowercase(original_text), lowercase(copied_text)), 1)
测试模块主要十个部分,分别是测试文件的读写功能,测试文件的预处理模块,测试相同文本的相似度,测试文本只有一半的情况等等,首先定义了一个测试用例类TestPlagiarismDetection用来测试main函数中的三个函数,read_file,lowercase,calculate_similarity。
测试思路:本次测试模块的设计用到了python标准库中的unitest测试模块进行测试,如在测试文件的读写功能中,创建一个临时文件 temp_test_file.txt,写入内容 'testfile.',然后使用 read_file 函数读取这个文件的内容。测试目的是验证 read_file 能正确读取文件内容。读取后,文件被删除。在test_none_file模块中,尝试使用 read_file 读取一个不存在的文件名 'invalid_file.txt'。期望返回值是 FileNotFoundError。

单元测试得到的测试覆盖率:

计算模块部分异常处理说明
使用Python标准库中的difflib.SequenceMatcher来计算两个文本字符串之间的相似度,其中matching_blocks = matcher.get_matching_blocks()用来获取匹配的块,matching_amount = sum(block.size for block in matching_blocks)计算匹配量,然后检查两个对比的test中的字符量是否都不为零,避免程序错误。
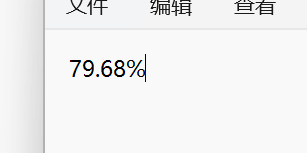
测试查重情况:![image]()
![image]()





 浙公网安备 33010602011771号
浙公网安备 33010602011771号