与答辩有关资料
倒排索引 传送门
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。
关键字提取算法TF-IDF 传送门
TF,是Term Frequency的缩写,就是某个关键字出现的频率,具体来讲,就是词库中的某个词在当前文章中出现的频率。那么我们可以写出它的计算公式:
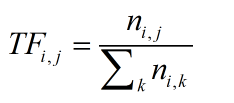
TF(i,j):关键词j在文档i中的出现频率。n(i,j):关键词j在文档i中出现的次数。
比如,一篇文章一共100个词汇,其中“机器学习”一共出现10次,那么他的TF就是10/100=0.1。这么看来好像仅仅是一个TF就能用来评估一个关键词的重要性(出现频率越高就越重要),其实不然,单纯使用TF来评估关键词的重要性忽略了常用词的干扰。常用词就是指那些文章中大量用到的,但是不能反映文章性质的那种词,比如:因为、所以、因此等等的连词,在英文文章里就体现为and、the、of等等的词。这些词往往拥有较高的TF,所以仅仅使用TF来考察一个词的关键性,是不够的。这里我们要引出IDF,来帮助我们解决这个问题。
IDF:IDF,英文全称:Inverse Document Frequency,即“反文档频率”。先看什么是文档频率,文档频率DF就是一个词在整个文库词典中出现的频率,就拿上一个例子来讲:一个文件集中有100篇文章,共有10篇文章包含“机器学习”这个词,那么它的文档频率就是10/100=0.1,反文档频率IDF就是这个值的倒数,即10。因此得出它的计算公式:
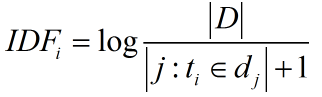
其中:
IDF(i):词语i的反文档频率
|D|:语料库中的文件总数
|j:t(i)属于d(j)|出现词语i的文档总数
+1是为了防止分母变0。
于是这个TF*IDF就能用来评估一个词语的重要性。
还是用上面这个例子,我们来看看IDF是怎么消去常用词的干扰的。假设100篇文档有10000个词,研究某篇500词文章,“机器学习”出现了20次,“而且”出现了20次,那么他们的TF都是20/500=0.04。再来看IDF,对于语料库的100篇文章,每篇都出现了“而且”,因此它的IDF就是log1=0,他的TF*IDF=0。而“机器学习”出现了10篇,那么它的IDF就是log10=1,他的TF*IDF=0.04>0,显然“机器学习”比“而且”更加重要。
总结:这算法看似简单,实际上在SEO搜索引擎优化啊,文本分类方面用的挺多的,面试时也常常作为信息论知识储备来出题。
文本相似度的计算-向量空间模型(TF*IDF) 传送门
向量空间模型:在向量空间模型中,文本用D(Document)表示,特征项(Term)用t表示,特征项指出现在文本D中并能够代表文本D的内容的基本语言单位,可以由词或者短句构成。文本可以用特征项进行表示D(t1,t2,t3…tn),其中ti(1<=k<=n)表示特征项。通常在建立向量空间模型时,一般都会给每个特征项一个权值来表示该特征项对该文本的重要性,权值的取定有多种方式,常见的就是取TF-IDF值。即D(t1,w1,t2,w2,t3,w3,…tn,wn),可简化为D(w1,w2,w3…wn),我们把这个称为该文本的向量表示。如:某文本的特征项为a,b,c,d,权值为:40,30,20,10。那么该文本的向量表示为D(40,30,20,10)。
附:阮一峰 TF-IDF与余弦相似性的应用(一):自动提取关键词 传送门
阮一峰 TF-IDF与余弦相似性的应用(二):找出相似文章 传送门
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
搜索引擎核心技术详讲 传送门
文档(Document)
文档集合(Document Collection)
文档编号(Document ID):每个文档被赋予一个唯一的ID
单词编号(Word ID):每个单词被赋予一个唯一的ID
倒排索引(Inverted Index):由单词词典和倒排文件组成。
单词词典(Lexicon):保存单词集合,单词词典内每条索引项记载单词本身的一些信息以及倒排列表的指针。
倒排文件(Inverted File):由倒排列表组成。
二 倒排索引需要记录的内容:单词出现过的文档ID、单词在每个文档中出现的次数、单词在每个文档中出现的位置(非必需,只有当系统支持短语查询时,才需要)
三 单词词典的实现:一般采用的数据结构:哈希列表或者是B树
查询处理
一次一文档(Document at a Time):搜索引擎接收到用户的查询后,首先将每个单词的倒排列表从磁盘读入内存。然后以倒排列表中包含的文档为单位,计算每个文档与查询的最终相似性得分,最后返回得分最后的K个文档。该方法以文档为单位,纵向进行分数累计,之后移动到后续文档接着计算,即计算过程是“先纵向再横向”的。整个过程,我们只需要在内存中维护一个大小为K的优先队列,用来保存计算过程中得分最高的K个文档即可。
一次一单词(Term at a Time):搜索引擎接收到用户的查询后,首先将每个单词的倒排列表从磁盘读入内存。然后以词典中的单词为单位,一次一单词是采取“先横向再纵向”的方式。在单词---文档矩阵中首先进行横向移动,在计算完毕某个单词倒排列表中包含的所有文档后,接着计算下一个单词倒排列表中包含的文档ID,即进行纵向计算,如果发现某个文档ID已经有了得分,则在原先得分基础上进行累加。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号