接口请求超时问题排查过程
2017-05-20 01:21 清风软件测试开发 阅读(18553) 评论(1) 收藏 举报接口请求超时问题排查过程
问题描述:
客户调用时20线程并发请求接口共1000次,部分请求发生超时(5s以上),以及15%的丢包率(很恐怖)
问题可能原因思考:
1、接口服务的系统延时。
2、调用方多线程代码执行延迟。
3、双方网络运营商不同导致网络延迟以及丢包。
排查过程:
接口服务的系统延时:
1、程序执行时间排查
刚好系统代码有记录一次接口请求代码从执行开始到返回接口的总耗时,对1000次请求的请求记录导出,发现只有850条记录,而且执行时间都在100ms以内。
说明接口服务代码没有问题,而且证实了15%的丢包率。
2、排查nginx负载路由的延迟
配置nginx的日志格式:
log_format main
'$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"
"$upstream_response_time request_time $request_time"';
新增了upstream_response_time 和 request_time
upstream_response_time:从 Nginx 建立连接 到 接收完数据并关闭连接
request_time:从 接受用户请求的第一个字节 到 发送完响应数据
如果把整个过程补充起来的话 应该是:
[1用户请求][2建立 Nginx 连接][3发送响应][4接收响应][5关闭 Nginx 连接]
那么 upstream_response_time 就是 2+3+4+5
但是 一般这里面可以认为 [5关闭 Nginx 连接] 的耗时接近 0
所以 upstream_response_time 实际上就是 2+3+4 而 request_time 是 1+2+3+4
二者之间相差的就是 [1用户请求] 的时间,如果用户端网络状况较差 或者传递数据本身较大
再考虑到 当使用 POST 方式传参时 Nginx 会先把 request body 缓存起来
而这些耗时都会累积到 [1用户请求] 头上去
这样就解释了为什么 request_time 有可能会比 upstream_response_time 要大。
那为什么客户端网络问题或者数据量大会导致request_time增加?
因为请求参数过大或者客户端网络延迟会导致请求数据在传输过程拆包,服务端接收时包多自然获取时间增加。
问题复现前还没有加日志,所以排查时没有排查该问题。如果request_time确实比upstream_response_time 要大很多,那问题就可以怀疑到客户端网络问题以及运营商网络问题了。
调用方多线程代码执行延迟:
我们要求下,向客户索要了客户的http调用工具类
开始排查客户工具类代码是否有延迟问题....
1、发现代码中每一次请求都会创建一个httpClient对象,这就很懵逼了...
因为每次创建httpClient对象都要将其初始化一次,显然是没有必要的,所以讲httpClient声明为static,在类加载时就创建该对象。
private static CloseableHttpClient HTTP_CLIENT = getClient();
2、自己创建线程池对象
ExecutorService executorService = Executors.newFixedThreadPool(20);
然后开始本地网络执行调用,发现接口的响应时间很短100ms左右,而且大部分接口调用代码的执行时间也跟接口响应时间接近,说明大多是接口调用代码执行时间都很短;但问题就是这少数调用代码执行时间都在2~6秒之间,这就很恐怖了。
之后发现这少数的调用数量刚好和线程池的size数量相同。
经过排查发现,当线程池初始化完后,会等工具类的加载包括httpClient的初始化过程,所以所有线程一直在等工具类的加载和httpClient的初始化完成才开始执行,因此第一批线程执行调用会包含类加载以及httpClient的初始化,因此导致线程数量的调用执行延迟。
因此考虑,在线程池创建之前,就把工具类加载好,然后调用接口。
private static CloseableHttpClient HTTP_CLIENT;
public static void init() {
HTTP_CLIENT = getClient();
}
以上,保证线程池初始化前先加载工具类
TianTest.init();
ExecutorService executorService = Executors.newFixedThreadPool(20);
综上,客户端代码的延迟问题得以解决。
双方网络运营商不同导致网络延迟以及丢包
由于在本地测试没有发生丢包情况和延迟过长情况,这就需要客户配合再次测试,复现丢包以及延迟问题。
然后检查接口服务器nginx的request_time 和 upstream_response_time的差距,如果差距很大那就是客户端网路问题了。
原文地址https://blog.csdn.net/sinat_30802291/article/details/85166787
========================================================================
========================================================================
记一次接口请求超时的问题解决过程
我有一个项目,部署在两个不同的服务器A和B,然后调用同一个接口,其中服务器A在毫秒级内返回,服务器B大概10秒左右才返回。
由此我认为响应时间久与代码逻辑没有关系,可能是跟网络传输有关系,所以我在宿主机服务器使用curl去访问看看响应需要多少时间

结果耗时还是需要十秒左右
于是我一开始认为与代码无关的想法又有点动摇了,我决定开启mysql的慢查询看看是不是某个查询耗时比较久导致的
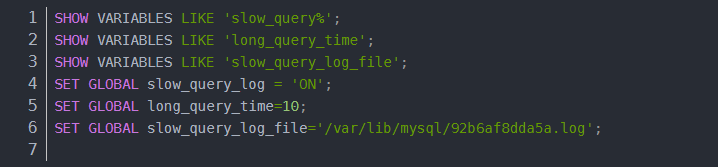
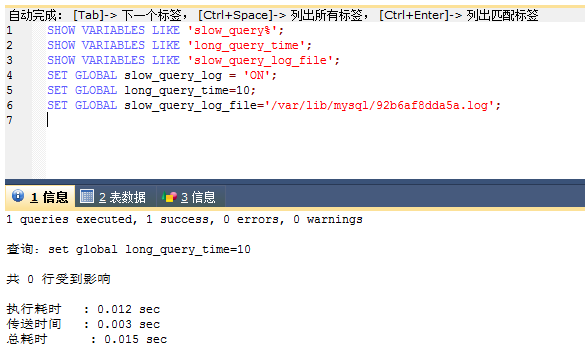
但是慢查询日志里也没有输出什么东西

慢查询也没发现什么端倪,于是我之后在代码里输出一些时间信息看看具体是哪一块代码耗时比较长导致的了:
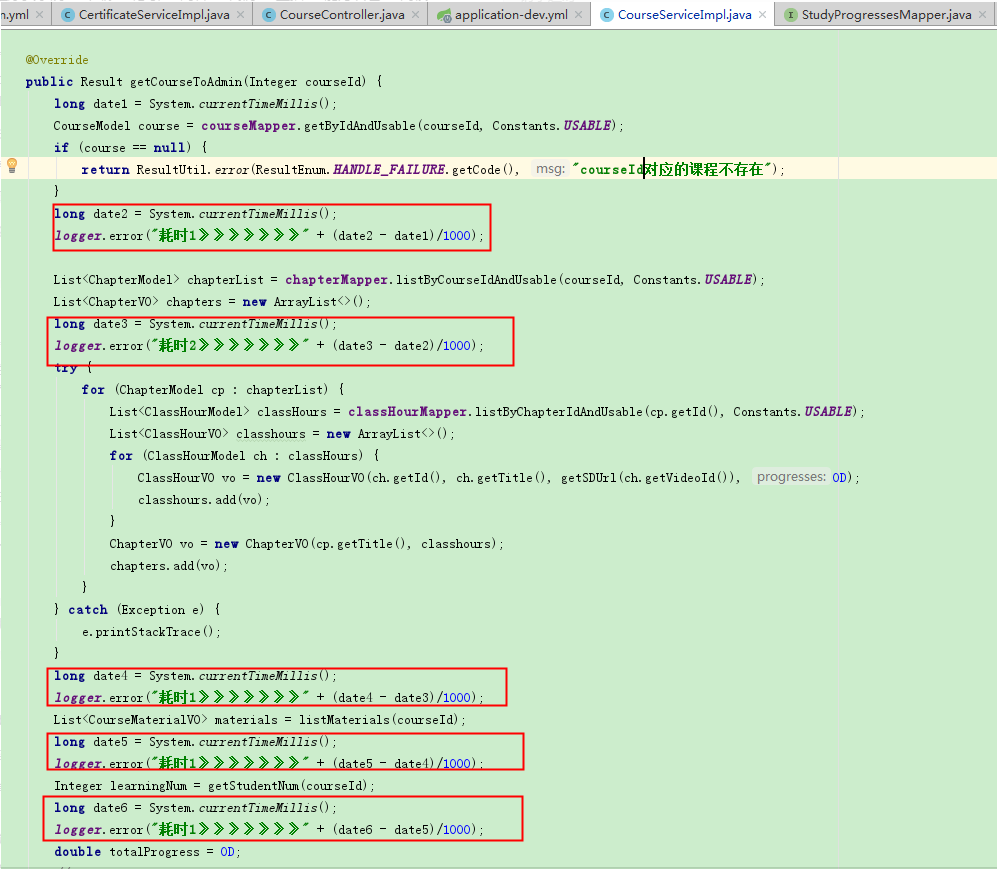

结果发现是两个for循环那里耗时10秒,然后继续在for循环的逻辑里面多输出一些log,其实一开始我基本定位到问题了,我猜想是要么就是redis出了问题,要么就是请求阿里的时候响应比较耗时,但是估计redis的问题会大一点。

于是我重启了redis,响应速度立马上来了,至此问题解决。
原文地址https://blog.csdn.net/aimashi620/article/details/102459457
===============================================================================
===============================================================================
作为程序员,应该有一套排查问题的思路,下面以界面响应慢为出发点进行整理(后端开发程序员一枚,前端不过多描述)。
设计到的工具:jstack、jmap、jstat(这三个是jre自带的)、Windows资源监视器、Windows性能监视器(perfmon.exe)、wireshark、ProcessExplorer、mat(dump分析工具)、程序员计算器、PsExec64.exe(提权工具)等。
下面的问题排查的思维导图,可以摘取其中的一部分按顺序进行排查,需要注意以下一点:
1,使用jstack、jmap、jstat工具查看JVM状态时,一般都需要用PsExec64工具进行提权,提权方法:PsExec64.exe /s cmd(本次提权只在当前cmd窗口有效);
2,当CPU高的时候,首先应该排查是有是由于内存或者IO引起的CPU高,所以应该先查看内存与IO的状态;
3,jstat -gcutil查看GC次数,如果需要导出GC前后的dump进行分析比较,可以使用jinfo动态设置JVM属性(jinfo -flag +HeapDumpBeforeFullGC <pid>;jinfo -flag +HeapDumpAfterFullGC <pid>;jinfo -flag HeapDumpPath=E:\heapdump <pid>),不需要重启。
4,netstat导出的端口文件,如果端口使用过多,可以使用wireshark抓包查看,但是如果需要抓取本机调用的请求,需要执行命令:route add 本机ip mask 255.255.255.255 网关ip 。
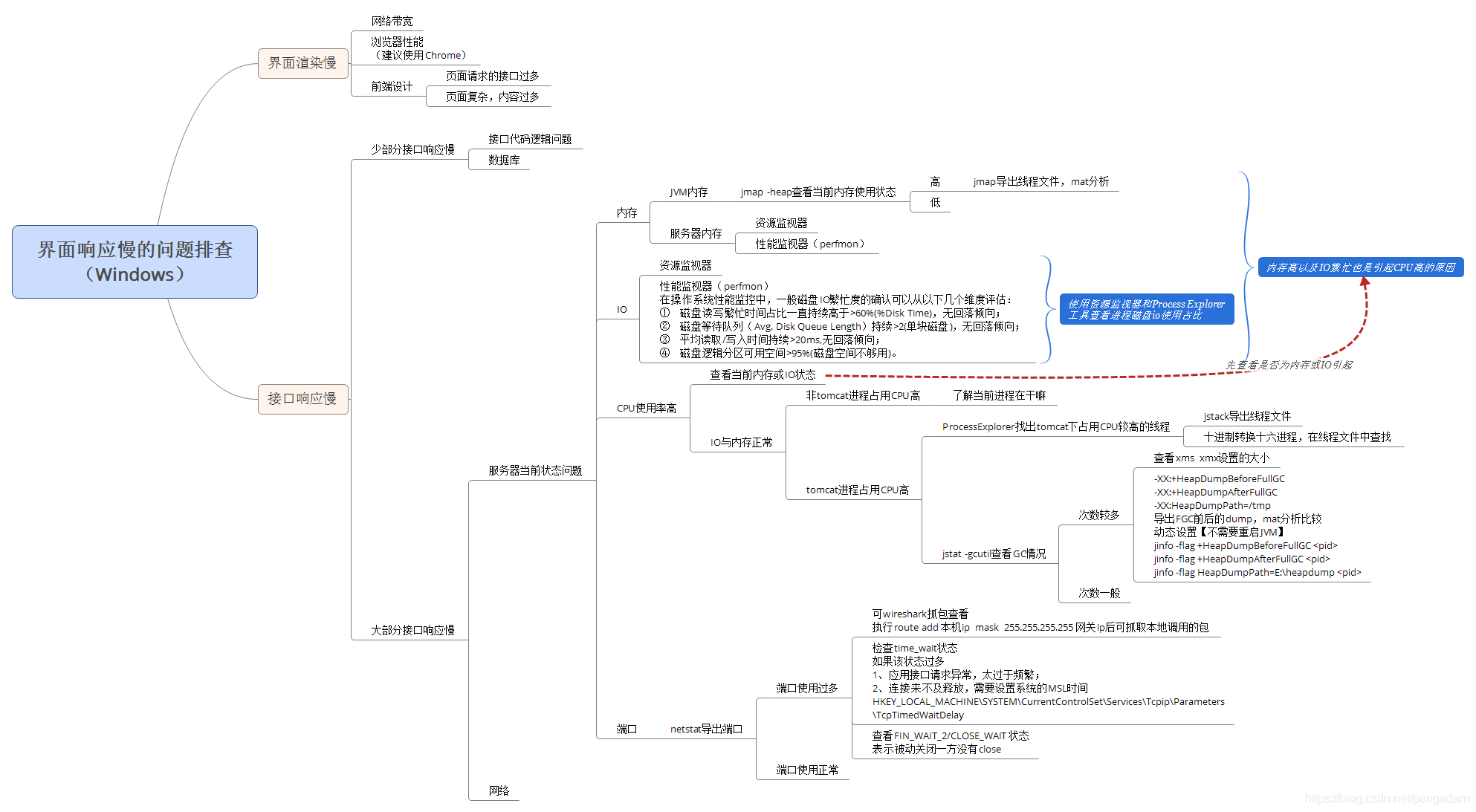
原文链接:https://blog.csdn.net/pangadam/article/details/86300171

 浙公网安备 33010602011771号
浙公网安备 33010602011771号