



python的一些内置方法
目录
- 字符串的内置方法
- 列表内置方法
- 字典内置方法
- 可变类型与不可变类型
- 队列与堆栈
- 作业
字符串的内置方法
- 移除字符串首尾的指定字符
- A = '111james111'(移除字符首尾'111')
-
- 关键单词'strip'(除去)左(left)右(right)
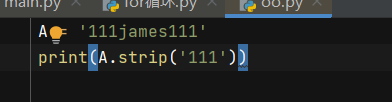
A = '111james111'
print(A.strip('111'))固定格式print(变量名.strip('要去除的字符'))
同理:
print(A.lstrip('111')) (去除左边的'111'此处的'l'也就是left的缩写)
print(a.rstrip('111')) (去除右边的'111'此处的'r'也就是right的缩写)
- 大小写相关操作
-
name = 'YUFAN'
-
将所有英文字母小写
-
- 关键单词 'lower'(下方的)
- 格式:print(变量名.lower())
-
将所有英语字母大写
-
- 关键单词upper
- 格式:print(变量名.upper)
-
bool布尔值
-
- 判断字符串当中英文字母是否是纯大写/小写
- print(变量名.islower/isupper())
-
补充:
-
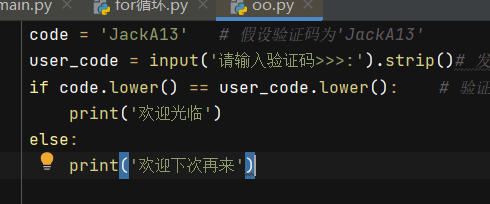
- 验证码(在不区分大小写的情况下输入正确的内容)
code = 'JackA13' # 假设验证码为'JackA13'
user_code = input('请输入验证码>>>:').strip()# 发送给用户的登录界面 去除登录时的空格
if code.lower() == user_code.lower(): # 验证码大小写和用户输入一致
print('欢迎光临')
else:
print('欢迎下次再来')
- 判断字符串的开头与结尾的字符是否正确
-
运用单词
-
- startswith(start + swith)理解(开始+开关)
- endswith(end + swith)理解(结束+开关)
-
结构: print(变量名.startswith/endswith('vlaue'))
- 格式化输出
- 占位符:%s %d...... (python基础里有介绍有兴趣的朋友可以往前翻)😄
- format方法>>>:分四类
# 类似占位符 不过这次是'{}'
eg : print('截至本月为止,您的话费还剩{}元,请及时充值,如有需要请拨打{}')(52,10086)
# 利用索引方法与占位符相似
# 直接将自己需要的vlaue填入在输出
eg : print('{姓名}住在上海浦东,年龄是{年龄}'.format(name='于帆','年龄'=22))
#如未结束的编码出现想关可直接添加
- 拼接字符串
- 直接添加即可
-
- eg('变量名'+'变量名') # 两个变量相连
- ('变量名'*'变量名') # 重复循环两个变量相连
- 替换字符串中指定的字符
- 关键词 replace(替换取代)
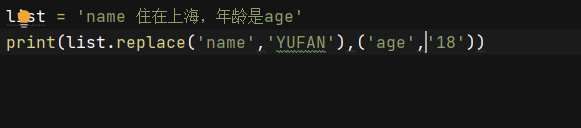
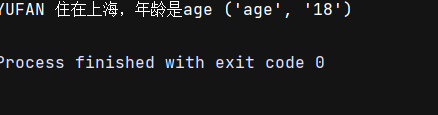
list = 'name 住在上海,年龄是age'
print(list.replace('name','YUFAN'),('age','18')
# 这种替换相当于world里的crt1+h一次替换所有
如果相一次替换可在后加间隔类似与索引取值的等差
- 判断字符串中是否是纯数字
name = 'YUFAN'
# 字符串里没有数字 在输出bool后结果为False
age = '18'
#str里为纯数字 输出bool为 True
- 其他可能运用的单词
find('发现')常用于索引
print(k,find('查找的value'))
如果打印结果为'-1'意思是没有找到所取的内容
index(索引)与find作用相当,由于得不到相关value会直接报错不推荐使用
print(K.center(数字,'相关的符号'))
print(k.ljust(数字,'相关符号'))
print(k.rjust(数字,'相关符号'))
print(k.z(zero)fill(数字))
- 补充
captalize:首字母大写
变量名.captalize()
swapcase: 大小写反转
变量名.swapcase()
title:每个单词的首字母大写
变量名.title()
列表内置方法
- 类型转换
- int和float不能被转换
- 类型结构:print(k('value'))
- 常见的list操作
- 索引取值
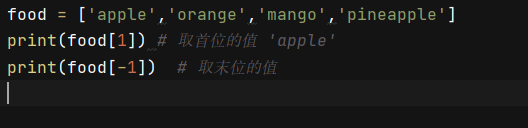
food = ['apple','orange','mango','pineapple']
print(food[1]) # 取首位的值 'apple'
print(food[-1]) # 取末位的值
- 切片操作 # 与str切片操作相似
- 间隔
格式:
print(k[0:4]) # 在'k' list中取出前三位元素
print(k[0:5:2]) #间隔为2的在K中取值
- 统计list中的元素个数
关键词: len
print(len(k))
- 添加元素的方式
-
- 尾部追加元素: # 关键词 :append
food.append('peach')
print(food)
-
- 指定位置加入单元素
-
- 关键词:insert(插入)
food.insert(0,cola)
print it
-
- 合并列表
-
-
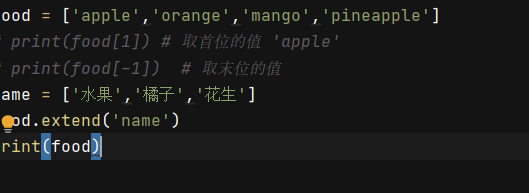
- 关键词:extend
-
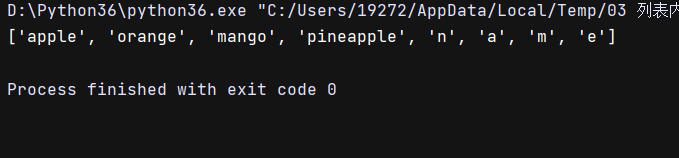
name = ['水果','橘子','花生']
food.extend('name')
print(food)
- 删除方式
- 关键词 :del
del k[元素位置]
print(k)
- 就地删除
- 关键词:remove
food.remove('apple')
print(food)
- pop延迟删除
- 修改元素
- 排序
升序:k.sort
降序:k.sort(reserse=True
- 翻转list
关键词: reverse
k.reverse() print(k)
- 比较运算
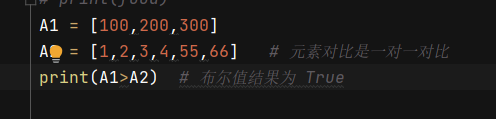
A1 = [100,200,300]
A2 = [1,2,3,4,55,66] # 元素对比是一对一对比
print(A1>A2) # 布尔值结果为 True
- 统计list中的元素出现个数
- 关键词: count
K = [11,1,1,1,1,1,1,2,2,3,3,3,3,3,3]
print(k.count(1)) # 统计元素1的出现次数
eg : k.clear #直接清空list
print(k)
可变&不可变的类型
ps:这里指的是地址变化
A = '1111apple1111'
print(A.strip('111')) #strip用于删除A中'1111'
(本身的地址并没有改变)
print(A) #还是不变的
总结:str是不可更改的 list是可以更改的
队列与堆栈
- 队列
- 先进先出
按顺序进
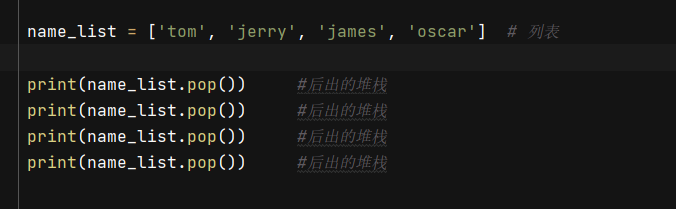
name = ['james','tim','AK']
# 在用append进行末尾添加
naem.append(添加内容)
出
for i in name
print(i)
print(name.pop)
。。。
- 堆栈
- 与队列没有太大变化,后出则不用for循环


 浙公网安备 33010602011771号
浙公网安备 33010602011771号