

第二次作业
模式识别
- 根据已有知识的表达(函数映射),针对待识别模式,判别决策其所属的类别或者预测其对应的回归值,是一种推理过程,可划分为“分类”和“回归”两种形式。
- 模式识别任务的模型通过机器学习获得。
机器学习
利用训练样本,对目标函数进行学习优化(参数、模型结构等),得到理想的模型的过程。
提高泛化能力:选择模型;通过调节正则系数,降低过拟合的程度
评估模型性能方法:留出法、K折交叉验证、留一验证等
性能指标度量:准确度、精度、召回率、曲线度量等
MED分类器:基于欧式距离,没有考虑特征变化的不同及特征之间的相关性。在高维空间中,该决策边界是一个超平面,且该平面垂直且二分连接两个类原型的线。掌握决策边界方程及其推导。
MICD分类器:基于马氏距离,经过特征正交白化,去除特征变化的不同及特征之间的相关性,但会选择方差较大的类。
贝叶斯规则:已知先验概率和观测概率,模式𝒙属于类𝐶𝑖后验概率的计算公式为: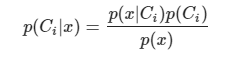
MAP分类器:将测试样本决策分类给后验概率最大的那个类。给定所有测试样本, MAP分类器选择后验概率最大的类,等于最小化平均概率误差,即最小化决策误差。

贝叶斯分类器:在MAP分类器基础上,加入决策风险因素,得到贝叶斯分类器,给定一个测试样本𝒙,贝叶斯分类器选择决策风险最小的类。
给定所有测试样本 {𝒙},贝叶斯分类器的决策目标: 最小化期望损失。
监督式学习
参数化方法(学习这些解析表达函数中的参数):
- 最大似然估计:
给定的𝑁 个训练样本都是从𝑝(𝒙|𝜃)采样得到的、且都符合iid条件,则所有样本的联合概率密度为:![]() 该函数称为似然函数(Likelihood function)
该函数称为似然函数(Likelihood function)
学习参数𝜃的目标函数:![]() 使得该似然函数最大
使得该似然函数最大 - 贝叶斯估计(具有不断学习的能力)
给定参数𝜃分布的先验概率以及训练样本,估计参数θ分布的后验概率
![]()
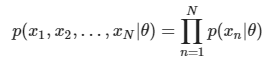 该函数称为似然函数(Likelihood function)
该函数称为似然函数(Likelihood function)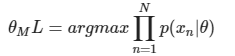 使得该似然函数最大
使得该似然函数最大
非参数化方法(基于概率密度估计技术):
- KNN估计 给定𝒙,找到其对应的区域𝑅使其包含𝑘个训练样本,以此计算𝑝(𝒙) 。可以自适应的确定𝒙相关的区域𝑅的范围,但不是真正的概率密度表达,概率密度函数积分是 ∞ 而不是1。例如,在k=1时。
第三章内容不少,涉及一些线代和概率论知识,有一些决策边界方程推导啥的还挺头疼。重点是一些知识点之间的比较,理解过后会对这些分类器、估计方法等印象更深,不容易搞混。
线性判据与回归
生成模型:给定训练样本{Xn},直接在输入空间内学习其概率密度函数p(x)。
优势:可以根据p(x)采样新的样本数据,检测出较低概率的数据,实现离群点检测。
劣势:如果是高维的x,需要大量训练样本才能准确的估计p(x) ;否则,会出现维度灾难问题。
判别模型:给定训练样本{Xn},直接在输入空间内估计后验概率p(Ci|x)。
优势:快速直接、省去了耗时的高维观测似然概率估计。
线性判据:如果判别模型f(x)是线性函数,则f(x)为线性判据。可以用于两类分类,决策边界是线性的,也可以用于多类分类,相邻两类之间的决策边界也是线性的。优势:计算量少:在学习和分类过程中,线性判据方法都比基于学习概率分布的方法计算量少。

- w决定了决策边界H的方向,w0决定了决策边界的偏移量(相对于坐标原点的位置),使其能够满足两个类输出值分别为正负。
监督式学习过程:基于训练样本及其标签,设计目标函数,学习w和w0;识别过程:将待识别样本x带入训练好的判据方程。
问题:训练样本个数通常远远大于参数个数,导致解不唯一。
最优解:设计目标函数,加入约束条件,提高泛化能力。






对偶法的优势:无论主问题的凸性如何,对偶问题始终是一个凸优化问题。凸优化的性质:局部极值点就是全局极值点。所以,对偶问题的极值是唯一的全局极值点。因此,对于难以求解的主问题(例如,非凸问题或者NP难问题),可以通过求解其对偶问题,得到原问题的一个下界估计。

学习总结:
知识是终身受用的,基础很重要,有些地方内容是前后贯通的,先介绍了基本概念,再在后续内容加以应用。老师在上课提出了很多问题,对学习也很有帮助,自学自己是很少会意识到这方面的细节的。几个分类器的知识在上机实践中对里面的原理也更加深刻。机器学习在生活中应用也很广泛,由于客观原因,课程比较紧促,老师讲解也很清晰,部分公式推不通得自己私下花点功夫,很受用,也有点难的一门课。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号