


DL 2 自动微分模块
自动微分模块
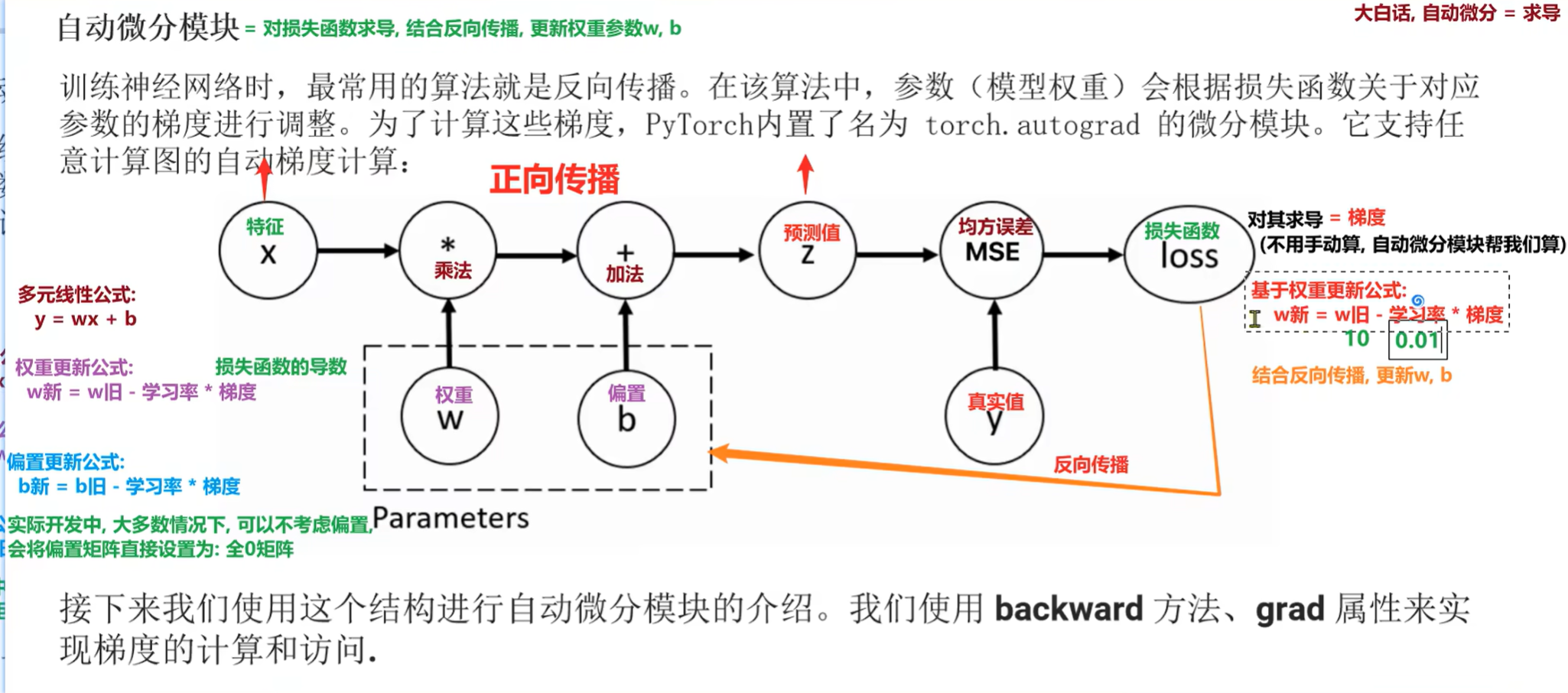
1. 自动微分模块=对损失函数求导,结合反向传播,更新权重参数w,b
 pytorch不支持向量张量对向量张量的求导,只支持标量张量对向量张量的求导
pytorch不支持向量张量对向量张量的求导,只支持标量张量对向量张量的求导
import torch
# 定义参数,requires_grad默认为false
w = torch.tensor(10, requires_grad=True, dtype=torch.float32)
# 定义损失函数
loss = w ** 2 + 20
print(f'梯度函数类型:{type(loss.grad_fn)}')
print(f'权重初始值w:{w}, loss:{loss}')
for i in range(0, 10):
# 计算损失
loss = w ** 2 + 20
# 梯度清零 w.grad.zero_(), 默认梯度会累加
# 至此(第一次的时候),还没有计算梯度, 所以w.grad = Node,要做非空判断
if w.grad is not None:
w.grad.zero_()
# 反向传播,计算梯度,梯度 = 损失函数的倒数,计算完毕后,会记录到w.grad属性中
# loss是一个标量,若非标量可通过loss.sum().backward()来保证loss是1个标量
loss.backward()
# 更新参数
# .data 返回一个与原始张量共享相同数据存储的新张量,但不共享计算历史和梯度信息。
# w.data = w.data - w.grad * 0.01
# 不推荐使用data,推荐使用以下
# 注意:w = w - 0.01 * w.grad 错误,因为当你执行 w = w - 0.01 * w.grad 时,
# 实际上创建了一个新的张量,这个新张量不再需要梯度(因为在 torch.no_grad() 上下文中创建),所以后续的循环迭代中无法计算梯度。
with torch.no_grad():
w -= 0.01 * w.grad # 使用 -= 进行原地更新
print(f'第{i}次,更新后的权重w:{w}, loss:{loss}')
2.detach()
若张量允许自动微分则不能转换为numpy,需要使用detach拷贝一份
另外,detach后与原变量共享同一块空间
import torch
import numpy as np
t1 = torch.tensor([10, 20], requires_grad=True, dtype=torch.float)
print(f't1:{t1}, type:{type(t1)}') # t1:tensor([10., 20.], requires_grad=True), type:<class 'torch.Tensor'>
# 通过 detach(),拷贝一份张量,然后转换
# t2 = t1.detach().numpy()
# 注意: t1 和 t2 和 t3 共享同一块空间
t2 = t1.detach()
t3 = t2.numpy()
# 测试 共享同一块空间
t1.data[0] = 1
print(f't1:{t1}, type:{type(t1)}') # t1:tensor([ 1., 20.], requires_grad=True), type:<class 'torch.Tensor'>
print(f't2:{t2}, type:{type(t2)}') # t2:tensor([ 1., 20.]), type:<class 'torch.Tensor'>
print(f't3:{t3}, type:{type(t3)}') # t3:[ 1. 20.], type:<class 'numpy.ndarray'>
#测试 detach
print(f't1:{t1.requires_grad}') # True
print(f't2:{t2.requires_grad}') # False
3. PyTorch构建线性回归模型
import torch
from torch.utils.data import TensorDataset # 创建x和y张量数据集对象
from torch.utils.data import DataLoader # 创建数据集加载器
import torch.nn as nn # 损失函数和回归函数
from torch.optim import SGD # 随机梯度下降函数, 取一个训练样本算梯度值
from sklearn.datasets import make_regression # 创建随机样本, 工作中不使用
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 1-创建线性回归样本 x y coef(w) b
# numpy对象 ->张量Tensor ->数据集对象TensorDataset ->数据加载器DataLoader
def create_datasets():
x, y, coef = make_regression(n_samples=100, # 样本数
n_features=1, # 特征数
noise=10, # 标准差, 噪声, 样本离散程度
coef=True, # 返回系数, w
bias=14.5, # 截距 b
random_state=0)
# 将数组转换成张量
x = torch.tensor(data=x)
y = torch.tensor(data=y)
# print('x->', x)
# print('y->', y)
# print('coef->', coef)
return x, y, coef
# 2-模型训练
def train(x, y, coef):
# 创建张量数据集对象
datasets = TensorDataset(x, y)
print('datasets->', datasets)
# 创建数据加载器对象
# dataset: 张量数据集对象
# batch_size: 每个batch的样本数
# shuffle: 是否打乱样本
dataloader = DataLoader(dataset=datasets, batch_size=16, shuffle=True)
print('dataloader->', dataloader)
# for batch in dataloader: # 每次遍历取每个batch样本
# print('batch->', batch) # [x张量对象, y张量对象]
# break
# 创建初始回归模型对象, 随机生成w和b, 元素类型为float32
# in_features: 输入特征数 1个
# out_features: 输出特征数 1个
model = nn.Linear(in_features=1, out_features=1)
print('model->', model)
# 获取模型对象的w和b参数
print('model.weight->', model.weight)
print('model.bias->', model.bias)
print('model.parameters()->', list(model.parameters()))
# 创建损失函数对象, 计算损失值
criterion = nn.MSELoss()
# 创建SGD优化器对象, 更新w和b
optimizer = SGD(params=model.parameters(), lr=0.01)
# 定义变量, 接收训练次数, 损失值, 训练样本数
epochs = 100
loss_list = [] # 存储每次训练的平均损失值
total_loss = 0.0
train_samples = 0
for epoch in range(epochs): # 训练100次
# 借助循环实现 mini-batch SGD 模型训练
for train_x, train_y in dataloader:
# 模型预测
# train_x->float64
# w->float32
y_pred = model(train_x.type(dtype=torch.float32)) # y=w*x+b
print('y_pred->', y_pred)
# 计算损失值, 调用损失函数对象
# print('train_y->', train_y)
# y_pred: 二维张量
# train_y: 一维张量, 修改成二维张量, n行1列
# 可能发生报错, 修改形状
# 修改train_y元素类型, 和y_pred类型一致, 否则发生报错
loss = criterion(y_pred, train_y.reshape(shape=(-1, 1)).type(dtype=torch.float32))
print('loss->', loss)
# 获取loss标量张量的数值 item()
# 统计n次batch的总MSE值
total_loss += loss.item()
# 统计batch次数
train_samples += 1
# 梯度清零
optimizer.zero_grad()
# 计算梯度值
loss.backward()
# 梯度更新 w和b更新
# step()等同 w=w-lr*grad
optimizer.step()
# 每次训练的平均损失值保存到loss列表中
loss_list.append(total_loss / train_samples)
print('每次训练的平均损失值->', total_loss / train_samples)
print('loss_list->', loss_list)
print('w->', model.weight)
print('b->', model.bias)
# 绘制每次训练损失值曲线变化图
plt.plot(range(epochs), loss_list)
plt.title('损失值曲线变化图')
plt.grid()
plt.show()
# 绘制预测值和真实值对比图
# 绘制样本点分布
plt.scatter(x, y)
# 获取1000个样本点
# x = torch.linspace(start=x.min(), end=x.max(), steps=1000)
# 计算训练模型的预测值
y1 = torch.tensor(data=[v * model.weight + model.bias for v in x])
# 计算真实值
y2 = torch.tensor(data=[v * coef + 14.5 for v in x])
plt.plot(x, y1, label='训练')
plt.plot(x, y2, label='真实')
plt.legend()
plt.grid()
plt.show()
x, y, coef = create_datasets()
train(x, y, coef)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号