06-数据库连接池、JDBCTemplate
一、数据库连接池
1.1、概念:
其实就是一个容器(集合),存放数据库连接的容器。
当系统初始化好后,容器被创建,容器中会申请一些连接对象,当用户来访问数据库时,从容器中获取连接对象,用户访问完之后,会将连接对象归还给容器。
1.2、优点:
1、节约资源 -->因为建立连接耗费资源。 2、用户访问高效。
1.3、原理
数据库连接池负责分配管理和释放数据库连接,它允许应。用程序重复使用一个现有的数据库连接,而不是再重新建立一个:释放空闲时间超过最大空闲时间的数据库连接来避免没有释放数据库链接而引起的数据库库连接遗漏。这项技术明显他提高了数据库操作的性能。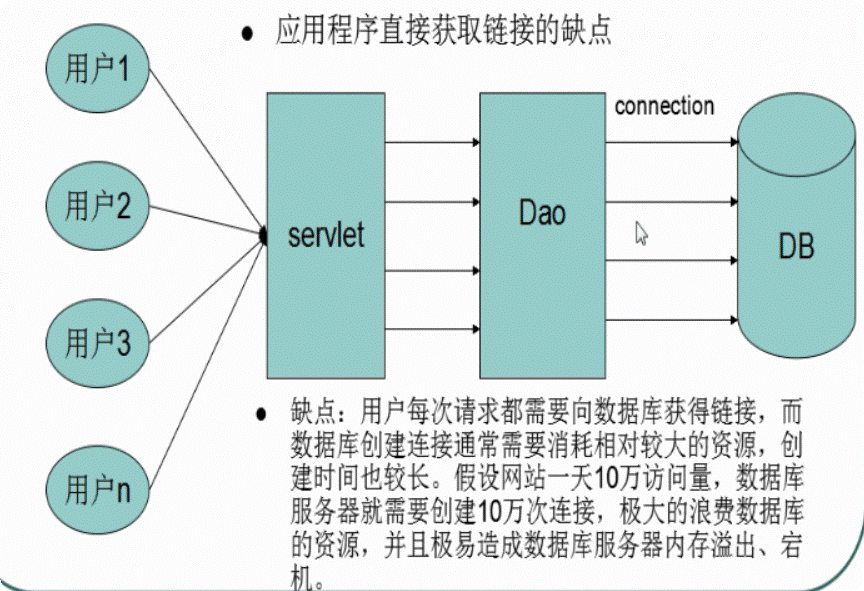
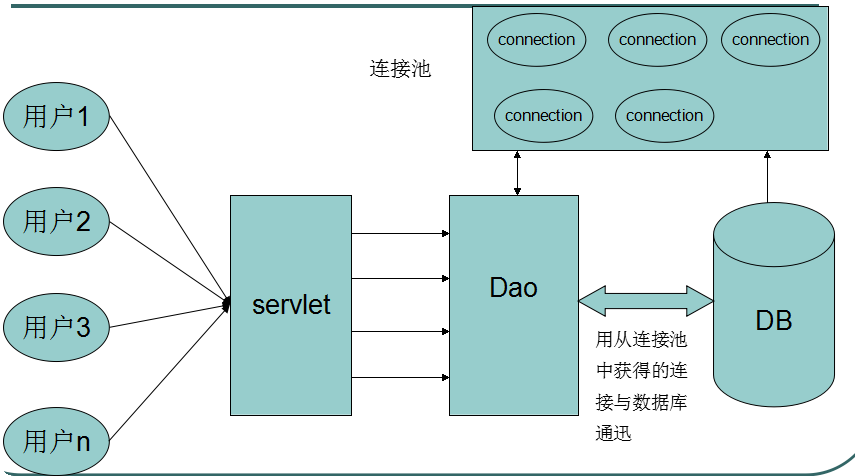
1.4、实现
标准接口:DataSource接口,javax.sql包下的。
该工厂用于提供到此 DataSource对象所表示的物理数据源的连接。作为 DriverManager工具的替代项。
DataSource对象是获取连接的首选方法。
1、基本实现 - 生成标准的 Connection 对象。
2、连接池实现 - 生成自动参与连接池的 Connection 对象。此实现与中间层连接池管理器一起使用。
3、分布式事务实现-生成一个 Connection 对象,该对象可用于分布式事务,大多数情况下总是参与连接池。此实现与中间层事务管理器一起使用。
方法:
获取连接:getConnection()
归还连接:conn.close()----如果是连接池获取的,归还此连接对象。节约创建连接对象的资源。
一般我们不去实现它,数据库连接池由数据库厂商是实现。
C3P0:数据库连接池技术
Druid:数据库连接池实现技术,由阿里巴巴提供的。
1.5、C3P0
1、导入jar包 (两个) c3p0-0.9.5.2.jar mchange-commons-java-0.2.12.jar
2、定义配置文件:
c3p0.properties 或者 c3p0-config.xml。直接将文件放在src目录下即可。
3、创建核心对象:数据库连接池对象 ComboPooledDataSource。
4、getConnection()。
<c3p0-config>
<!-- 使用默认的配置读取连接池对象 -->
<default-config>
<!-- 连接参数 -->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/dbday04</property>
<property name="user">root</property>
<property name="password">123456</property>
<!-- 连接池参数 -->
<!-- 初始化连接数量 -->
<property name="initialPoolSize">5</property>
<!-- 最大连接数量 -->
<property name="maxPoolSize">10</property>
<!-- 超时时间 -->
<property name="checkoutTimeout">3000</property>
</default-config>
<named-config name="otherc3p0">
<!-- 连接参数 -->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/dbday04</property>
<property name="user">root</property>
<property name="password">123456</property>
<!-- 连接池参数 -->
<property name="initialPoolSize">5</property>
<property name="maxPoolSize">8</property>
<property name="checkoutTimeout">1000</property>
</named-config>
</c3p0-config>
大于最大等待时间到了抛异常 checkoutTime(单位:ms)。
代码:
//1.创建数据库连接池对象 DataSource ds = new ComboPooledDataSource(); //2. 获取连接对象 Connection conn = ds.getConnection();
1.6、Druid
优点:
可以对sql性能进行监控,以进行sql调优。
密码高度的加密。性能高。服务器标准配置下,sql查询语句查询几微妙
1、导入jar包 druid-1.0.9.jar
2、定义配置文件
是properties形式的
可以叫任意名称,可以放在任意目录下
driverClassName=com.mysql.jdbc.Driver url=jdbc:mysql://127.0.0.1:3306/dbday04 username=root password=123456 initialSize=5 maxActive=10 maxWait=3000
注意:driverClassName:驱动类名,可以不配置,会根据url自动识别。
3、加载配置文件。Properties
4、获取数据库连接池对象:通过工厂来获取。DruidDataSourceFactory
5、获取链接:getConnection
代码:
//3.加载配置文件 Properties pro = new Properties(); InputStream is = DruidDemo.class.getClassLoader().getResourceAsStream("druid.properties"); pro.load(is); //4.获取连接池对象 DataSource ds = DruidDataSourceFactory.createDataSource(pro); //5.获取连接 Connection conn = ds.getConnection();
附注:
添加依赖,add as lib让IDEA可以看到里面的细节,不然以为是压缩包
放在包名(即文件夹下)类加载器找不到。
druid没有严格要求在src下。
二、Spring JDBC
2.1、概述
Spring框架对JDBC的简单封装。提供了一个JDBCTemplate对象简化JDBC的开发。
2.2、创建JdbcTemplate对象。依赖于数据源DataSource。
JdbcTemplate template = new JdbcTemplate(ds);
2.3、调用JdbcTemplate的方法来完成CURD操作
update():
执行DML语句。增、删、改语句;-->也可以完成DDL语句
queryMap():
查询结果将结果集封装为map集合,将列名作为key,将值作为value。将该条记录封装为一个map集合。
注意:盖房的结果集长度只能是1。
queryForList():
查询结果将结果集封装为list集合。
注意:将每一条记录封装为一个Map集合,再将Map集合装载到List集合中List<Map<String,Object>>
query():
查询结果,将结果封装为JavaBean对象。
query的参数:RowMapper
一般使用BeanPropertyRowMapper实现类。可以完成数据到JavaBean的自动封装。
new BeanPropertyRowMapper<类型>(类型.class);
注意:
实体类中基本数据类型用包装类来写。
一般要求列名和javabean的成员变量名一致。-->一般如果数据库字段中间使用_,类中成员变量使用驼峰写法。
数据库中:字段id
JavaBean:属性uid,而方法setId getId。==>也可以,setXxx,getXxx中Xxx(属性)要和数据库字段对应即可。
uid成员变量 ,setId==>id是属性。setid也可以,大小写可以忽略。
但是在反射的:Method eat_method = personClass.getMethod("eAT",String .class); 方法名不一致的话,会报NoSuchMethodException。
所以该框架的底层实现应该是先找到所有的方法名的数组,在跟从数据库中获取的字段进行忽略大小的匹配。在调用对应的set、get方法。
实现原理:
List<Emp> list = template.query(sql, new BeanPropertyRowMapper<Emp>(Emp.class));
Emp.class使用反射的原理。
Method method(setXxx) = Emp.class.getMethod("set"+字段名(默认全部小写?),类型.class)。
queryForObject:查询结果,将结果封装为对象。
一般用于聚合函数的查询。
Emp e = template.queryObject(sql, new BeanPropertyRowMapper<Emp>(Emp.class),1001);==》先将查询的记录封装成一个Emp对象,再返回此对象。
附注:
1、pro.load(DruidUtils.class.getClassLoader().getResourceAsStream("druid.properties"));
pro.load(DruidUtils.class.getResourceAsStream("druid.properties"));
加载资源的路径:前者(Class类对象)指向的是src下,后者(ClassLoader类对象)指向的是类所在的文件夹。
2、xxx.class.getClassLoader
xxx可以是任意类,只要在src下,指向的路径相同且唯一,即src下。
附注:
1、类加载到方法区,里面的静态区(静态代码块)
2、pstmt.setString(1,"xxx");
所有的占位符都可以用setString来设置预编译语句对象的值,mysql对于数据类型较为弱化。应该是自动解析字符串成为对应字段的数据类型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号