02-Oracle
一、视图
视图就是封装了一条复杂查询的语句。
语法:
CREATE VIEW 视图名称 AS 子查询
CREATE OR REPLACE VIEW 视图名称 AS 子查询
CREATE OR REPLACE VIEW 视图名称 AS 子查询 WITH READ ONLY


---视图 ---视图的概念:视图就是提供一个查询的窗口,所有数据来自于原表。 ---查询语句创建表 create table emp as select * from scott.emp; select * from emp; ---创建视图【必须有dba权限】 create view v_emp as select ename, job from emp; ---查询视图 select * from v_emp; ---修改视图[不推荐] update v_emp set job='CLERK' where ename='ALLEN'; commit; ---创建只读视图 create view v_emp1 as select ename, job from emp with read only; ---视图的作用? ---第一:视图可以屏蔽掉一些敏感字段。 ---第二:保证总部和分部数据及时统一。
Oracle中的对象:
二、索引
索引是用于加速数据存取的数据对象。合理的使用索引可以大大降低 i/o 次数,从而 提高数据访问性能。索引有很多种这里主要介绍常用的几种:
为什么添加了索引之后,会加快查询速度呢?
图书馆:如果杂乱地放书的话检索起来就非常困难,所以将书分类,然后再建一个箱子,箱子里面放卡片,卡片里面可以按类查询,按书名查或者类别查,这样的话速度会快很多很多, 这个就有点像索引。索引的好处就是提高你找到书的速度,但是正是因为你建了索引,就应该有人专门来维护索引,维护索引是要有时间精力的开销的,也就是说索引是不能乱建的,所以建索引有个原则:如果有一个字段如果不经常查询,就不要去建索引。现在把书变成我们的表,把卡片变成 我们的索引,就知道为什么索引会快,为什么会有开销。
创建索引:
1、单列索引
单列索引是基于单个列所建立的索引,比如:
CREATE index 索引名 on 表名(列名)
2、复合索引
复合索引是基于两个列或多个列的索引。在同一张表上可以有多个索引,但是要求列的组合必须不同,如:
Create index emp_idx1 on emp(ename,job);
Create index emp_idx1 on emp(job,ename);
索引的使用原则:
在大表上建立索引才有意义
在 where子句后面或者是连接条件上的字段建立索引
表中数据修改频率高时不建议建立索引
---索引 --索引的概念:索引就是在表的列上构建一个二叉树 B+Tree ----达到大幅度提高查询效率的目的,但是索引会影响增删改的效率。 ---单列索引 ---创建单列索引 create index idx_ename on emp(ename); ---单列索引触发规则,条件必须是索引列中的原始值。 ---单行函数,模糊查询,都会影响索引的触发。 select * from emp where ename='SCOTT' ---复合索引 ---创建复合索引 create index idx_enamejob on emp(ename, job); ---复合索引中第一列为优先检索列 ---如果要触发复合索引,必须包含有优先检索列中的原始值。 select * from emp where ename='SCOTT' and job='xx';---触发复合索引 select * from emp where ename='SCOTT' or job='xx';---不触发索引 select * from emp where ename='SCOTT';---触发单列索引。
三、pl/sql基本语法
PL/SQL(Procedure Language/SQL)
PLSQL 是 Oracle 对sql 语言的过程化扩展,指在 SQL 命令语言中增加了过程处理语句(如分支、循 环等),使 SQL语言具有过程处理能力。把SQL 语言的数据操纵能力与过程语言的数据处理能力结合 起来,使得 PLSQL面向过程但比过程语言简单、高效、灵活和实用。
3.1、pl/sql程序语法
程序语法:
declare
说明部分 (变量说明,游标申明,例外说明 〕
begin
语句序列 (DML 语句〕…
exception
例外处理语句
End;
3.2、常量和变量的定义
在程序的声明阶段可以来定义常量和变量。
3.2.1、变量的基本类型就是 oracle 中的建表时字段的变量如 char, varchar2, date, number, boolean, long
定义语法:
varl char(15);
Psal number(9,2);
说明变量名、数据类型和长度后用分号结束说明语句。
常量定义:
married constant boolean:=true
---pl/sql编程语言 ---pl/sql编程语言是对sql语言的扩展,使得sql语言具有过程化编程的特性。 ---pl/sql编程语言比一般的过程化编程语言,更加灵活高效。 ---pl/sql编程语言主要用来编写存储过程和存储函数等。 ---声明方法 ---赋值操作可以使用:=也可以使用into查询语句赋值 declare i number(2) := 10; s varchar2(10) := '小明'; ena emp.ename%type;---引用型变量 emprow emp%rowtype;---记录型变量 emp{empno,ename,job,...} begin dbms_output.put_line(i); dbms_output.put_line(s); select ename into ena from emp where empno = 7788; dbms_output.put_line(ena); select * into emprow from emp where empno = 7788; dbms_output.put_line(emprow.ename || '的工作为:' || emprow.job); end;
3.2.2、引用变量
Myname emp.ename%type;
引用型变量,即my_name 的类型与emp 表中 ename 列的类型一样 。
在 sql中使用 into 来赋值
---声明方法 ---赋值操作可以使用:=也可以使用into查询语句赋值 declare i number(2) := 10; s varchar2(10) := '小明'; ena emp.ename%type;---引用型变量 emprow emp%rowtype;---记录型变量 emp{empno,ename,job,...} begin dbms_output.put_line(i); dbms_output.put_line(s); select ename into ena from emp where empno = 7788; dbms_output.put_line(ena); select * into emprow from emp where empno = 7788; dbms_output.put_line(emprow.ename || '的工作为:' || emprow.job); end;
3.2.3、记录型变量
Emprec emp%rowtype
记录变量分量的引用
emp_rec.ename:='ADAMS'
3.3、if分支
语法 1:
IF 条件 THEN 语句 1;
语句 2;
END IF;
语法 2:
IF 条件 THEN 语句序列 1;
ELSE 语句序列 2;
END IF;
语法 3:
IF 条件 THEN 语句;
ELSIF 语句 THEN 语句;
ELSE 语句;
END IF;
---pl/sql中的if判断 ---输入小于18的数字,输出未成年 ---输入大于18小于40的数字,输出中年人 ---输入大于40的数字,输出老年人 declare i number(3) := ⅈ begin if i<18 then dbms_output.put_line('未成年'); elsif i<40 then dbms_output.put_line('中年人'); else dbms_output.put_line('老年人'); end if; end;
3.4、LOOP循环语句
语法 1:
WHILE total <= 25000 LOOP
.. .
total : = total + salary;
END LOOP;
语法 2:
Loop EXIT [when 条件];
……
End loop
语法3:
FOR I IN 1 . . 3 LOOP
语句序列 ;
END LOOP ;
---pl/sql中的loop循环 ---用三种方式输出1到10是个数字 ---while循环 declare i number(2) := 1; begin while i<11 loop dbms_output.put_line(i); i := i+1; end loop; end; int i = 1 while( i < 11){ i ++; } ---exit循环 declare i number(2) := 1; begin loop exit when i>10; dbms_output.put_line(i); i := i+1; end loop; end; ---for循环 declare begin for i in 1..10 loop dbms_output.put_line(i); end loop; end;
3.5、游标Cursor
在写 java 程序中有集合的概念,那么在 pl/sql 中也会用到多条记录,这时候我们就要用到游标, 游标可以存储查询返回的多条数据。
语法:
CURSOR 游标名 [ (参数名 数据类型,参数名 数据类型,...)] IS SELECT 语句; --->获得一个类似list的数据
游标的使用步骤:
打开游标: open c1; (打开游标执行查询)
取一行游标的值: fetch c1 into pjob; (取一行到变量中)
关闭游标: close c1;(关闭游标释放资源)
游标的结束方式 exit when c1%notfound
注意: 上面的 pjob 必须与 emp表中的 job 列类型一致:
定义:pjob emp.empjob%type;
---游标:可以存放多个对象,多行记录。 ---输出emp表中所有员工的姓名 declare cursor c1 is select * from emp; emprow emp%rowtype; begin open c1; loop fetch c1 into emprow; exit when c1%notfound; dbms_output.put_line(emprow.ename); end loop; close c1; end; -----给指定部门员工涨工资 declare cursor c2(eno emp.deptno%type) is select empno from emp where deptno = eno; en emp.empno%type; begin open c2(10); loop fetch c2 into en; exit when c2%notfound; update emp set sal=sal+100 where empno=en; commit; end loop; close c2; end; ----查询10号部门员工信息 select * from emp where deptno = 10;
四、存储过程
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的 SQL 语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象,任何一个设计良好的数据库应用程序都应该用到存储过程。
创建存储过程的语法:
create [or replace] PROCEDURE 过程名[(参数名 in/out 数据类型)]
AS
begin
PLSQL子程序体;
End;
或者:
create [or replace] PROCEDURE 过程名[(参数名 in/out 数据类型)]
is
begin
PLSQL子程序体;
End;
---存储过程 --存储过程:存储过程就是提前已经编译好的一段pl/sql语言,放置在数据库端 --------可以直接被调用。这一段pl/sql一般都是固定步骤的业务。 ----给指定员工涨100块钱 create or replace procedure p1(eno emp.empno%type) is i number(3); begin i := 10; update emp set sal=sal+100 where empno = eno; commit; end; select * from emp where empno = 7788; ----测试p1 declare begin p1(7788); end;
五、存储函数
create or replace function 函数名(Name in type, Name in type, ...) return 数据类型
is
结果变量 数据类型;
begin
return(结果变量);
end函数名;
存储过程和存储函数的区别:
一般来讲,过程和函数的区别在于函数可以有一个返回值;而过程没有返回值。 但过程和函数都可以通过 out 指定一个或多个输出参数。我们可以利用out 参数,在过程和函数中实现返回多个值。
----通过存储函数实现计算指定员工的年薪 - ----存储过程和存储函数的参数都不能带长度 ----存储函数的返回值类型不能带长度 create or replace function f_yearsal(eno emp.empno%type) return number is s number(10); begin select sal*12+nvl(comm, 0) into s from emp where empno = eno; return s; end; ----测试f_yearsal ----存储函数在调用的时候,返回值需要接收。 declare s number(10); begin s := f_yearsal(7788); dbms_output.put_line(s); end;
---out类型参数如何使用 ---使用存储过程来算年薪 create or replace procedure p_yearsal(eno emp.empno%type, yearsal out number) is s number(10); c emp.comm%type; begin select sal*12, nvl(comm, 0) into s, c from emp where empno = eno; yearsal := s+c; end; ---测试p_yearsal declare yearsal number(10); begin p_yearsal(7788, yearsal); dbms_output.put_line(yearsal); end; ----in和out类型参数的区别是什么? ---凡是涉及到into查询语句赋值或者:=赋值操作的参数,都必须使用out来修饰。
---存储过程和存储函数的区别 ---语法区别:关键字不一样, ------------存储函数比存储过程多了两个return。 ---本质区别:存储函数有返回值,而存储过程没有返回值。 ----------如果存储过程想实现有返回值的业务,我们就必须使用out类型的参数。 ----------即便是存储过程使用了out类型的参数,起本质也不是真的有了返回值, ----------而是在存储过程内部给out类型参数赋值,在执行完毕后,我们直接拿到输出类型参数的值。 ----我们可以使用存储函数有返回值的特性,来自定义函数。 ----而存储过程不能用来自定义函数。 ----案例需求:查询出员工姓名,员工所在部门名称。 ----案例准备工作:把scott用户下的dept表复制到当前用户下。 create table dept as select * from scott.dept; ----使用传统方式来实现案例需求 select e.ename, d.dname from emp e, dept d where e.deptno=d.deptno; ----使用存储函数来实现提供一个部门编号,输出一个部门名称。 create or replace function fdna(dno dept.deptno%type) return dept.dname%type is dna dept.dname%type; begin select dname into dna from dept where deptno = dno; return dna; end; ---使用fdna存储函数来实现案例需求:查询出员工姓名,员工所在部门名称。 select e.ename, fdna(e.deptno) from emp e;
六、触发器
数据库触发器是一个与表相关联的、存储的 PL/SQL 程序。每当一个特定的数据操作语句 (Insert,update,delete)在指定的表上发出时,Oracle 自动地执行触发器中定义的语句序列。
触发器可用于:
数据确认
实施复杂的安全性检查
做审计,跟踪表上所做的数据操作等
数据的备份和同步
触发器的类型
语句级触发器 :
在指定的操作语句操作之前或之后执行一次,不管这条语句影响了多少行 。
行级触发器(FOR EACH ROW) :
触发语句作用的每一条记录都被触发。在行级触发器中使用 old 和 new伪记录变量, 识别值的状态。
语法:
CREATE [or REPLACE] TRIGGER 触发器名
{BEFORE | AFTER}
{DELETE | INSERT | UPDATE [OF 列名]}
ON 表名
[FOR EACH ROW [WHEN(条件) ] ]
DECLARE
BEGIN
PLSQL 块
End 触发器名
---触发器,就是制定一个规则,在我们做增删改操作的时候, ----只要满足该规则,自动触发,无需调用。 ----语句级触发器:不包含有for each row的触发器。 ----行级触发器:包含有for each row的就是行级触发器。 -----------加for each row是为了使用:old或者:new对象或者一行记录。 ---语句级触发器 ----插入一条记录,输出一个新员工入职 create or replace trigger t1 after insert on person declare begin dbms_output.put_line('一个新员工入职'); end; ---触发t1 insert into person values (1, '小红'); commit; select * from person; ---行级别触发器 ---不能给员工降薪 ---raise_application_error(-20001~-20999之间, '错误提示信息'); create or replace trigger t2 before update on emp for each row declare begin if :old.sal>:new.sal then raise_application_error(-20001, '不能给员工降薪'); end if; end; ----触发t2 select * from emp where empno = 7788; update emp set sal=sal-1 where empno = 7788; commit;
----触发器实现主键自增。【行级触发器】 ---分析:在用户做插入操作的之前,拿到即将插入的数据, ------给该数据中的主键列赋值。 create or replace trigger auid before insert on person for each row declare begin select s_person.nextval into :new.pid from dual; end; --查询person表数据 select * from person; ---使用auid实现主键自增 insert into person (pname) values ('a'); commit; insert into person values (1, 'b'); commit;
在触发器中触发语句与伪记录变量的值: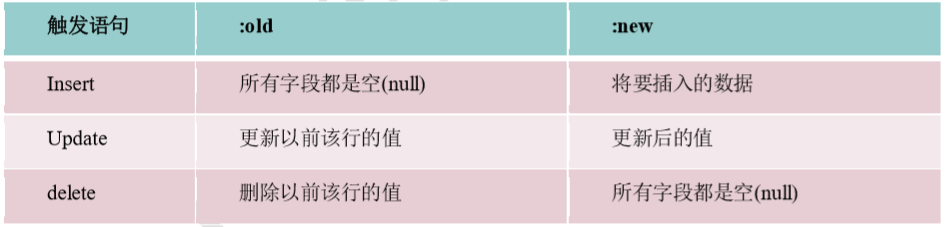
七、java程序调用存储过程
7.1、java连接oracle的jar包
7.2、数据库连接字符串
String driver="oracle.jdbc.OracleDriver"; String url="jdbc:oracle:thin:@192.168.106.10:1521:orcl"; String username="scott"; String password="tiger";
7.3、实现过程的调用
public class OracleDemo { @Test public void javaCallOracle() throws Exception { //加载数据库驱动 Class.forName("oracle.jdbc.driver.OracleDriver"); //得到Connnection连接 Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@192.168.106.10:1521:orcl", "itheima", "itheima"); //得到预编译的Statement对象 PreparedStatement ps = conn.prepareStatement("select * from emp where empno = ?"); //给参数复制 ps.setObject(1, 7788); //执行数据库进行查询操作 ResultSet rs = ps.executeQuery(); //输出结果 while(rs.next()){ System.out.println(rs.getString("ename")); } //释放资源 rs.close(); ps.close(); conn.close(); } /** * java调用存储过程 * {?= call <procedure-name>[(<arg1>,<arg2>, ...)]} 调用存储函数使用 * {call <procedure-name>[(<arg1>,<arg2>, ...)]} 调用存储过程使用 * @throws Exception */ @Test public void javaCallProcedure() throws Exception { //加载数据库驱动 Class.forName("oracle.jdbc.driver.OracleDriver"); //得到Connnection连接 Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@192.168.106.10:1521:orcl", "itheima", "itheima"); //得到预编译的Statement对象 // PreparedStatement ps = conn.prepareStatement("select * from emp where empno = ?"); CallableStatement ps = conn.prepareCall("{call p_yearsal(?, ?)}"); //给参数赋值 ps.setObject(1, 7788); ps.setObject(2, 2000); ps.registerOutParameter(2, OracleTypes.NUMBER); ps.execute(); System.out.println(ps.getObject(2)); //执行数据库进行查询操作 /*ResultSet rs = ps.executeQuery(); //输出结果 while(rs.next()){ System.out.println(rs.getString("ename")); }*/ //释放资源 // rs.close(); ps.close(); conn.close(); } @Test public void javaCallFunction() throws Exception { //加载数据库驱动 Class.forName("oracle.jdbc.driver.OracleDriver"); //得到Connnection连接 Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@192.168.106.10:1521:orcl", "itheima", "itheima"); //得到预编译的Statement对象 CallableStatement ps = conn.prepareCall("{?= call f_yearsal(?)}"); //给参数赋值 ps.setObject(2, 7788); ps.registerOutParameter(1, OracleTypes.NUMBER); ps.execute(); System.out.println(ps.getObject(1)); //释放资源 ps.close(); conn.close(); } }
sql示例
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.itheima</groupId> <artifactId>jdbc_oracle</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>com.oracle</groupId> <artifactId>ojdbc14</artifactId> <version>10.2.0.4.0</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> </dependencies> </project>
---视图 ---视图的概念:视图就是提供一个查询的窗口,所有数据来自于原表。 ---查询语句创建表 create table emp as select * from scott.emp; select * from emp; ---创建视图【必须有dba权限】 create view v_emp as select ename, job from emp; ---查询视图 select * from v_emp; ---修改视图[不推荐] update v_emp set job='CLERK' where ename='ALLEN'; commit; ---创建只读视图 create view v_emp1 as select ename, job from emp with read only; ---视图的作用? ---第一:视图可以屏蔽掉一些敏感字段。 ---第二:保证总部和分部数据及时统一。 ---索引 --索引的概念:索引就是在表的列上构建一个二叉树 B+Tree ----达到大幅度提高查询效率的目的,但是索引会影响增删改的效率。 ---单列索引 ---创建单列索引 create index idx_ename on emp(ename); ---单列索引触发规则,条件必须是索引列中的原始值。 ---单行函数,模糊查询,都会影响索引的触发。 select * from emp where ename='SCOTT' ---复合索引 ---创建复合索引 create index idx_enamejob on emp(ename, job); ---复合索引中第一列为优先检索列 ---如果要触发复合索引,必须包含有优先检索列中的原始值。 select * from emp where ename='SCOTT' and job='xx';---触发复合索引 select * from emp where ename='SCOTT' or job='xx';---不触发索引 select * from emp where ename='SCOTT';---触发单列索引。 ---pl/sql编程语言 ---pl/sql编程语言是对sql语言的扩展,使得sql语言具有过程化编程的特性。 ---pl/sql编程语言比一般的过程化编程语言,更加灵活高效。 ---pl/sql编程语言主要用来编写存储过程和存储函数等。 ---声明方法 ---赋值操作可以使用:=也可以使用into查询语句赋值 declare i number(2) := 10; s varchar2(10) := '小明'; ena emp.ename%type;---引用型变量 emprow emp%rowtype;---记录型变量 emp{empno,ename,job,...} begin dbms_output.put_line(i); dbms_output.put_line(s); select ename into ena from emp where empno = 7788; dbms_output.put_line(ena); select * into emprow from emp where empno = 7788; dbms_output.put_line(emprow.ename || '的工作为:' || emprow.job); end; ---pl/sql中的if判断 ---输入小于18的数字,输出未成年 ---输入大于18小于40的数字,输出中年人 ---输入大于40的数字,输出老年人 declare i number(3) := ⅈ begin if i<18 then dbms_output.put_line('未成年'); elsif i<40 then dbms_output.put_line('中年人'); else dbms_output.put_line('老年人'); end if; end; if(i<18){ }else if(i<40){ } ---pl/sql中的loop循环 ---用三种方式输出1到10是个数字 ---while循环 declare i number(2) := 1; begin while i<11 loop dbms_output.put_line(i); i := i+1; end loop; end; int i = 1 while( i < 11){ i ++; } ---exit循环 declare i number(2) := 1; begin loop exit when i>10; dbms_output.put_line(i); i := i+1; end loop; end; ---for循环 declare begin for i in 1..10 loop dbms_output.put_line(i); end loop; end; ---游标:可以存放多个对象,多行记录。 ---输出emp表中所有员工的姓名 declare cursor c1 is select * from emp; emprow emp%rowtype; begin open c1; loop fetch c1 into emprow; exit when c1%notfound; dbms_output.put_line(emprow.ename); end loop; close c1; end; -----给指定部门员工涨工资 declare cursor c2(eno emp.deptno%type) is select empno from emp where deptno = eno; en emp.empno%type; begin open c2(10); loop fetch c2 into en; exit when c2%notfound; update emp set sal=sal+100 where empno=en; commit; end loop; close c2; end; ----查询10号部门员工信息 select * from emp where deptno = 10; ---存储过程 --存储过程:存储过程就是提前已经编译好的一段pl/sql语言,放置在数据库端 --------可以直接被调用。这一段pl/sql一般都是固定步骤的业务。 ----给指定员工涨100块钱 create or replace procedure p1(eno emp.empno%type) is i number(3); begin i := 10; update emp set sal=sal+100 where empno = eno; commit; end; select * from emp where empno = 7788; ----测试p1 declare begin p1(7788); end; concat() ----通过存储函数实现计算指定员工的年薪 - ----存储过程和存储函数的参数都不能带长度 ----存储函数的返回值类型不能带长度 create or replace function f_yearsal(eno emp.empno%type) return number is s number(10); begin select sal*12+nvl(comm, 0) into s from emp where empno = eno; return s; end; ----测试f_yearsal ----存储函数在调用的时候,返回值需要接收。 declare s number(10); begin s := f_yearsal(7788); dbms_output.put_line(s); end; ---out类型参数如何使用 ---使用存储过程来算年薪 create or replace procedure p_yearsal(eno emp.empno%type, yearsal out number) is s number(10); c emp.comm%type; begin select sal*12, nvl(comm, 0) into s, c from emp where empno = eno; yearsal := s+c; end; ---测试p_yearsal declare yearsal number(10); begin p_yearsal(7788, yearsal); dbms_output.put_line(yearsal); end; ----in和out类型参数的区别是什么? ---凡是涉及到into查询语句赋值或者:=赋值操作的参数,都必须使用out来修饰。 ---存储过程和存储函数的区别 ---语法区别:关键字不一样, ------------存储函数比存储过程多了两个return。 ---本质区别:存储函数有返回值,而存储过程没有返回值。 ----------如果存储过程想实现有返回值的业务,我们就必须使用out类型的参数。 ----------即便是存储过程使用了out类型的参数,起本质也不是真的有了返回值, ----------而是在存储过程内部给out类型参数赋值,在执行完毕后,我们直接拿到输出类型参数的值。 ----我们可以使用存储函数有返回值的特性,来自定义函数。 ----而存储过程不能用来自定义函数。 ----案例需求:查询出员工姓名,员工所在部门名称。 ----案例准备工作:把scott用户下的dept表复制到当前用户下。 create table dept as select * from scott.dept; ----使用传统方式来实现案例需求 select e.ename, d.dname from emp e, dept d where e.deptno=d.deptno; ----使用存储函数来实现提供一个部门编号,输出一个部门名称。 create or replace function fdna(dno dept.deptno%type) return dept.dname%type is dna dept.dname%type; begin select dname into dna from dept where deptno = dno; return dna; end; ---使用fdna存储函数来实现案例需求:查询出员工姓名,员工所在部门名称。 select e.ename, fdna(e.deptno) from emp e; ---触发器,就是制定一个规则,在我们做增删改操作的时候, ----只要满足该规则,自动触发,无需调用。 ----语句级触发器:不包含有for each row的触发器。 ----行级触发器:包含有for each row的就是行级触发器。 -----------加for each row是为了使用:old或者:new对象或者一行记录。 ---语句级触发器 ----插入一条记录,输出一个新员工入职 create or replace trigger t1 after insert on person declare begin dbms_output.put_line('一个新员工入职'); end; ---触发t1 insert into person values (1, '小红'); commit; select * from person; ---行级别触发器 ---不能给员工降薪 ---raise_application_error(-20001~-20999之间, '错误提示信息'); create or replace trigger t2 before update on emp for each row declare begin if :old.sal>:new.sal then raise_application_error(-20001, '不能给员工降薪'); end if; end; ----触发t2 select * from emp where empno = 7788; update emp set sal=sal-1 where empno = 7788; commit; ----触发器实现主键自增。【行级触发器】 ---分析:在用户做插入操作的之前,拿到即将插入的数据, ------给该数据中的主键列赋值。 create or replace trigger auid before insert on person for each row declare begin select s_person.nextval into :new.pid from dual; end; --查询person表数据 select * from person; ---使用auid实现主键自增 insert into person (pname) values ('a'); commit; insert into person values (1, 'b'); commit; ----oracle10g ojdbc14.jar ----oracle11g ojdbc6.jar


 浙公网安备 33010602011771号
浙公网安备 33010602011771号