01-Oracle
一、Oracle介绍
ORACLE 数据库系统是美国ORACLE 公司(甲骨文)提供的以分布式数据库为核心的一组软件产品,是目前最流行的客户/服务器(CLIENT/SERVER)或 B/S体系结构的数据库之一。比如SilverStream 就是基于数据库的一种中间件。ORACLE数据库是目前世界上使用最为广泛的数据库管理系统,作为一个通用的数据库系统,它具有完整的数据管理功能;作为一个关系数据库,它是一个完备关系的产品;作为分布式数据库它实现了分布式处理功能
二、Oracle安装
三、Oracle体系结构
3.1、数据库
Oracle 数据库是数据的物理存储。这就包括(数据文件ORA或者 DBF、控制文件、联机日志、参数文件)。其实Oracle 数据库的概念和其它数据库不一样,这里的数据库是一个操作系统只有一个库。可以看作是Oracle 就只有一个大数据库。
3.2、实例
一个 Oracle 实例(Oracle Instance)有一系列的后台进程(Backguound Processes)和内存结构(Memory Structures)组成。一个数据库可以有 n 个实例。
3.3、用户
用户是在实例下建立的。不同实例可以建相同名字的用户。
3.4、表空间
表空间是 Oracle 对物理数据库上相关数据文件(ORA或者 DBF 文件)的逻辑映射。一个数据库在逻辑上被划分成一到若干个表空间,每个表空间包含了在逻辑上相关联的一组结构。每个数据库至少有一个表空间(称之为system表空间)。
每个表空间由同一磁盘上的一个或多个文件组成,这些文件叫数据文件(datafile)。一个数据文件只能属于一个表空间。
3.5、数据文件(dbf、ora)
数据文件是数据库的物理存储单位。数据库的数据是存储在表空间中的,真正是在某一个或者多个数据文件中。而一个表空间可以由一个或多个数据文件组成,一个数据文件只能属于一个表空间。一旦数据文件被加入到某个表空间后,就不能删除这个文件,如果要删除某个数据文件,只能删除其所属于的表空间才行。
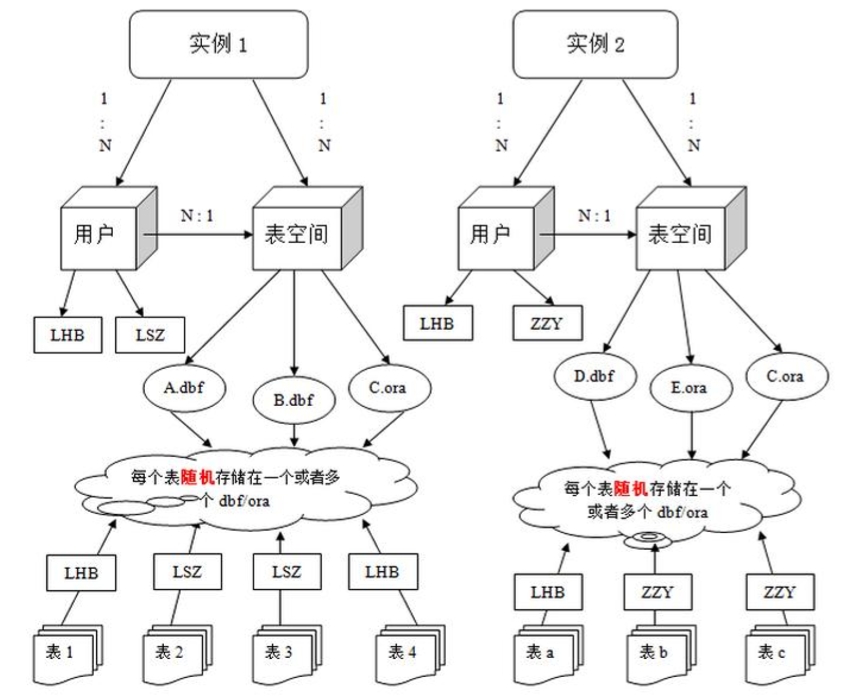
注:表的数据,是有用户放入某一个表空间的,而这个表空间会随机把这些表数据放到一个或者多个数据文件中。
由于 oracle 的数据库不是普通的概念,oracle 是有用户和表空间对数据进行管理和存放的。但是表不是有表空间去查询的,而是由用户去查的。因为不同用户可以在同一个表空间建立同一个名字的表!这里区分就是用户了!
--->用户是oracle中管理表的基本单位。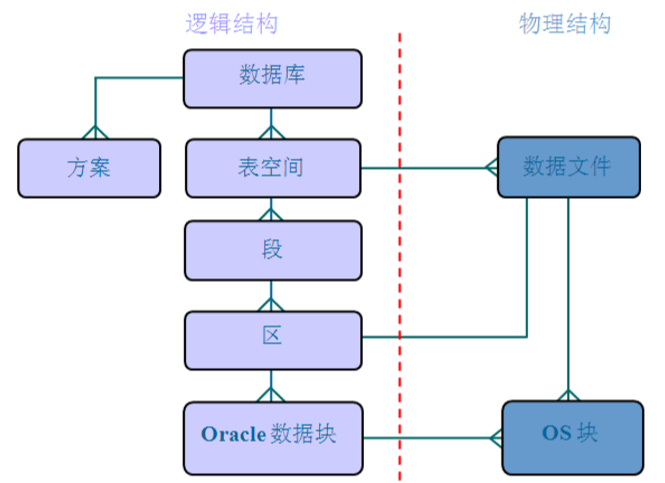
四、创建表空间
表空间? ORACLE数据库的逻辑单元。 数据库---表空间 一个表空间可以与多个数据文件(物理结构)关联
一个数据库下可以建立多个表空间,一个表空间可以建立多个用户、一个用户下可以建立多个表。


-- 创建表空间 create tablespace itheima datafile 'c:\SOFTWARE\oracle_data\itheima.dbf' size 100m autoextend on next 10m -- 删除表空间 drop tablespace itheima; -- 创建用户 登陆用户名 create user itheima identified by itheima default tablespace itheima; -- 给用户授权 -- oracle数据库中常用角色 connect --链接角色,基本角色 resource -- 开发者角色 dba --超级管理员角色 -- 给itheima用户授予dba角色 grant dba to itheima; -- 切换到itheima用户下
itheima:为表空间名称
datafile:指定表空间对应的数据文件
size:后定义的是表空间的初始大小
autoextend on:自动增长 ,当表空间存储都占满时,自动增长
next:后指定的是一次自动增长的大小。
五、用户
5.1、创建用户
identified by:后边是用户的密码
default tablespace:后边是表空间名称
oracle数据库与其它数据库产品的区别在于,表和其它的数据库对象都是存储在用户下的
5.2、用户赋权限
新创建的用户没有任何权限,登陆后会提示。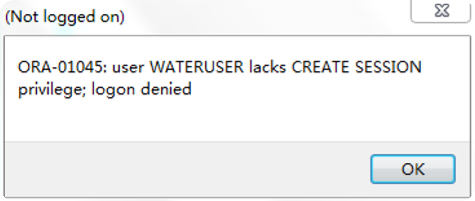
Oracle 中已存在三个重要的角色:
connect 角色
resource 角色
dba 角色
CONNECT 角色: --是授予最终用户的典型权利,最基本的
ALTER SESSION --修改会话
CREATE CLUSTER --建立聚簇
CREATE DATABASE LINK --建立数据库链接
CREATE SEQUENCE --建立序列
CREATE SESSION --建立会话
CREATE SYNONYM --建立同义词
CREATE VIEW --建立视图
RESOURCE 角色: --是授予开发人员的
CREATE CLUSTER --建立聚簇
CREATE PROCEDURE --建立过程
CREATE SEQUENCE --建立序列
CREATE TABLE --建表
CREATE TRIGGER --建立触发器
CREATE TYPE --建立类型
DBA角色:
拥有全部特权,是系统最高权限,只有DBA才可以创建数据库结构,并且系统权限也需要DBA授出,且 DBA用户可以操作全体用户的任意基表,包括删除。
grant dba to itcastuser
进入 system 用户下给用户赋予 dba 权限,否则无法正常登陆
六、Oracle数据类型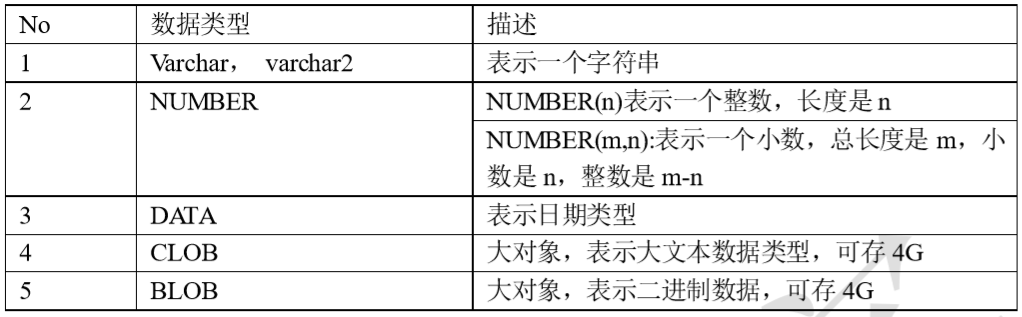
七、表的管理
7.1、建表
语法:
Create table 表名(
字段 1 数据类型 [default 默认值],
字段 2 数据类型 [default 默认值],
...
字段 n 数据类型 [default 默认值]
);
7.2、表删除
语法:
DROP TABLE 表名
7.3、表的修改
在 sql中使用 alter 可以修改表。
添加语法:
ALTER TABLE 表名称 ADD(列名1 类型 [DEFAULT 默认值],列名1 类型 [DEFAULT 默认值]...)
修改语法:
ALTER TABLE 表名称 MODIFY(列名1 类型 [DEFAULT 默认值],列名1 类型 [DEFAULT 默认值]...)
修改列名:
ALTER TABLE 表名称 RENAME 列名1 TO 列名2
7.4、数据库表数据的更新
7.4.1、INSERT
标准写法:
INSERT INTO 表名[(列名 1,列名 2,...)] VALUES (值 1,值 2,...)
简单写法(不建议)
INSERT INTO 表名 VALUES(值 1,值 2,...)
注意:使用简单的写法必须按照表中的字段的顺序来插入值,而且如果有为空的字段使用 null 。
insert into person values(2,'李四',1,null,'北京育新');
7.4.2、UPDATE
全部修改:
UPDATE 表名 SET 列名 1=值 1,列名 2=值 2,....
局部修改:
UPDATE 表名 SET 列名 1=值 1,列名 2=值 2,....WHERE 修改条件;
7.4.3、DELETE
语法 : DELETE FROM 表名 WHERE 删除条件;
在删除语句中如果不指定删除条件的话就会删除所有的数据。
因为 oracle 的事务对数据库的变更的处理,我们必须做提交事务才能让数据真正的插入到数据库中,在同样在执行完数据库变更的操作后还可以把事务进行回滚,这样就不会插入到数据库。如果事务提交后则不可以再回滚。
提交:commit
回滚:rollback
7.5、序列
-----序列不真正的属于任何一张表,但是可以逻和表做绑定 -----序列:默认从1开始,一次递增,主要用来给主键赋值使用 ----dual:虚表,指示为了补全语法,没有任何意义。 create sequence s_person; select s_person.nextval from dual; -- 添加一条记录 insert into person (pid,pname) values (s_person.nextval,'mia'); commit; select * from person;
在很多数据库中都存在一个自动增长的列,如果现在要想在 oracle 中完成自动增长的功能, 则只能依靠序列完成,所有的自动增长操作,需要用户手工完成处理。
语法:
CREATE SEQUENCE 序列名
[INCREMENT BY n]
[START WITH n]
[{MAXVALUE/ MINVALUE n|NOMAXVALUE}]
[{CYCLE|NOCYCLE}]
[{CACHE n|NOCACHE}];
范例:创建一个 seqpersonid的序列,验证自动增长的操作
create sequence s_person;
序列创建完成之后,所有的自动增长应该由用户自己处理,所以在序列中提供了以下的两种操作:
nextval:取得序列的下一个内容
currval:取得序列的当前内容
select s_person.nextval from dual;
select s_person.currval from dual;
在插入数据是需要子增长的主键可以这么使用:
insert into person (pid,pname) values (s_person.nextval,'mia');
在实际项目中每一张表会配一个序列,但是表和序列是没有必然的联系的,一个序列被哪一张表使用都可以,但是我们一般都是一张表用一个序列。
序列的管理一般使用工具来管理。
八、Scott用户下的表结构
九、单行函数
9.1、字符函数
接收字符输入返回字符或者数值,dual是伪表
9.1.1、把小写的字符转换成大小的字符
UPPER("yes")
9.1.2、把大写字符变成小写字符
LOWER("YES")
9.2、数值函数
9.2.1、四舍五入函数:ROUND()
select round(56.16, -2) from dual;---四舍五入,后面的参数表示保留的位数
select trunc(56.16, -1) from dual;---直接截取,不在看后面位数的数字是否大于5。
9.2.2、取余函数:MOD()
select mod(10, 3) from dual;---求余数
9.3、日期函数
Oracle 中提供了很多和日期相关的函数,包括日期的加减,在日期加减时有一些规律 。
日期 – 数字 = 日期
日期 + 数字 = 日期
日期 – 日期 = 数字
9.4、转换函数
9.4.1、TO_CHAR:字符串转换函数 (日期-->字符串)
范例:查询所有的雇员将将年月日分开,此时可以使用TO_CHAR 函数来拆分 拆分时需要使用通配符
年:y, 年是四位使用 yyyy
月:m, 月是两位使用 mm
日:d, 日是两位使用 dd
select to_char(sysdate, 'fm yyyy-mm-dd hh24:mi:ss') from dual;
9.4.2、TO_DATE:日期转换函数 (字符串-->日期)
TO_DATE可以把字符串的数据转换成日期类型
select to_date('2018-6-7 16:39:50', 'fm yyyy-mm-dd hh24:mi:ss') from dual;
9.5、通用函数
9.5.1、空值处理nvl()
如果null值和任意数字做算术运算,结果都是null。
select e.sal*12+nvl(e.comm, 0) from emp e;
9.5.2、Decode函数
该函数类似 if....else if...esle
语法:
DECODE(col/expression, [search1,result1],[search2, result2]....[default])
----oracle中除了起别名,都用单引号。
----oracle专用条件表达式
select e.ename,
decode(e.ename,
'SMITH', '曹贼',
'ALLEN', '大耳贼',
'WARD', '诸葛小儿',
'无名') "中文名"
from emp e;
9.5.3、case when
CASE expr WHEN comparison_expr1 THEN return_expr1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
END
---条件表达式
---条件表达式的通用写法,mysql和oracle通用
---给emp表中员工起中文名
select e.ename,
case e.ename
when 'SMITH' then '曹贼'
when 'ALLEN' then '大耳贼'
when 'WARD' then '诸葛小儿'
--else '无名'
end
from emp e;
---判断emp表中员工工资,如果高于3000显示高收入,如果高于1500低于3000显示中等收入,
-----其余显示低收入
select e.sal,
case
when e.sal>3000 then '高收入'
when e.sal>1500 then '中等收入'
else '低收入'
end
from emp e;
解决中文乱码问题:
中文乱码问题解决
1.查看服务器端编码
select userenv('language') from dual;
我实际查到的结果为:AMERICAN_AMERICA.ZHS16GBK
2.执行语句 select * from V$NLS_PARAMETERS
查看第一行中PARAMETER项中为NLS_LANGUAGE 对应的VALUE项中是否和第一步得到的值一样。
如果不是,需要设置环境变量.
否则PLSQL客户端使用的编码和服务器端编码不一致,插入中文时就会出现乱码.
3.设置环境变量
计算机->属性->高级系统设置->环境变量->新建
设置变量名:NLS_LANG,变量值:第1步查到的值, 我的是 AMERICAN_AMERICA.ZHS16GBK
4.重新启动PLSQL,插入数据正常
十、多行函数(聚合函数)
10.1、统计记录数: count()
10.2、最小值查询:min()
10.3、最大值查询:max()
10.4、查询平均值:avg()
10.5、求和函数:sum()
十一、分组统计
分组统计需要使用 GROUP BY来分组
语法:
SELECT * |列名 FROM 表名 {WEHRE 查询条件} {GROUP BY 分组字段} ORDER BY 列名1 ASC|DESC,列名2...ASC|DESC
---分组查询 ---查询出每个部门的平均工资 ---分组查询中,出现在group by后面的原始列,才能出现在select后面 ---没有出现在group by后面的列,想在select后面,必须加上聚合函数。 ---聚合函数有一个特性,可以把多行记录变成一个值。 select e.deptno, avg(e.sal)--, e.ename from emp e group by e.deptno; ---查询出平均工资高于2000的部门信息 select e.deptno, avg(e.sal) asal from emp e group by e.deptno having avg(e.sal)>2000; ---所有条件都不能使用别名来判断。 --比如下面的条件语句也不能使用别名当条件 select ename, sal s from emp where sal>1500; ---查询出每个部门工资高于800的员工的平均工资 select e.deptno, avg(e.sal) asal from emp e where e.sal>800 group by e.deptno; ----where是过滤分组前的数据,having是过滤分组后的数据。 ---表现形式:where必须在group by之前,having是在group by之后。 ---查询出每个部门工资高于800的员工的平均工资 ---然后再查询出平均工资高于2000的部门 select e.deptno, avg(e.sal) asal from emp e where e.sal>800 group by e.deptno having avg(e.sal)>2000;
注意:
1. 如果使用分组函数,SQL 只可以把 GOURP BY 分组条件字段和分组函数查询出来,不能有其他字段。
2. 如果使用分组函数,不使用 GROUP BY 只可以查询出来分组函数的值 。
十二、多表查询
12.1、多表连接基本查询
语法:
SELECT {DISTINCT} *|列名.. FROM 表名 别名,表名1 别名 {WHERE 限制条件 ORDER BY 排序字段 ASC|DESC...}
笛卡尔积:
如果多张表进行一起查询而且每张表的数据很大的话笛卡尔积就会变得非常大,对性能造成影响,想要去掉笛卡尔积我们需要关联查询。
12.2、外连接(左右链接)
oracle专用方式:
使用(+)表示左连接或者右连接,当(+)在左边表的关联条件字段上时是左连接,如果是在右边表的关联条件字段上就是右连接。
十三、子查询
子查询:在一个查询的内部还包括另一个查询,则此查询称为子查询。 Sql的任何位置都可以加入子查询。
子查询在操作中有三类:
单列子查询:返回的结果是一列的一个内容
单行子查询:返回多个列,有可能是一个完整的记录
多行子查询:返回多条记录
十四、Rownum与分页查询
ROWNUM:表示行号,实际上此是一个列,但是这个列是一个伪列,此列可以在每张表中出现。
----oracle中的分页 ---rownum行号:当我们做select操作的时候, --每查询出一行记录,就会在该行上加上一个行号, --行号从1开始,依次递增,不能跳着走。 ----排序操作会影响rownum的顺序 select rownum, e.* from emp e order by e.sal desc ----如果涉及到排序,但是还要使用rownum的话,我们可以再次嵌套查询。 select rownum, t.* from( select rownum, e.* from emp e order by e.sal desc) t; ----emp表工资倒叙排列后,每页五条记录,查询第二页。 ----rownum行号不能写上大于一个正数。 select * from( select rownum rn, tt.* from( select * from emp order by sal desc ) tt where rownum<11 ) where rn>5
sql示例:
--创建表空间 create tablespace itheima datafile 'c:\itheima.dbf' size 100m autoextend on next 10m; --删除表空间 drop tablespace itheima; --创建用户 create user itheima identified by itheima default tablespace itheima; --给用户授权 --oracle数据库中常用角色 connect--连接角色,基本角色 resource--开发者角色 dba--超级管理员角色 --给itheima用户授予dba角色 grant dba to itheima; ---切换到itheima用户下 ---创建一个person表 create table person( pid number(20), pname varchar2(10) ); ---修改表结构 ---添加一列 alter table person add (gender number(1)); ---修改列类型 alter table person modify gender char(1); ---修改列名称 alter table person rename column gender to sex; ---删除一列 alter table person drop column sex; ---查询表中记录 select * from person; ----添加一条记录 insert into person (pid, pname) values (1, '小明'); commit; ----修改一条记录 update person set pname = '小马' where pid = 1; commit; ----三个删除 --删除表中全部记录 delete from person; --删除表结构 drop table person; --先删除表,再次创建表。效果等同于删除表中全部记录。 --在数据量大的情况下,尤其在表中带有索引的情况下,该操作效率高。 --索引可以提供查询效率,但是会影响增删改效率。 truncate table person; ----序列不真的属于任何一张表,但是可以逻辑和表做绑定。 ----序列:默认从1开始,依次递增,主要用来给主键赋值使用。 ----dual:虚表,只是为了补全语法,没有任何意义。 create sequence s_person; select s_person.nextval from dual; ----添加一条记录 insert into person (pid, pname) values (s_person.nextval, '小明'); commit; select * from person; ----scott用户,密码tiger。 --解锁scott用户 alter user scott account unlock; --解锁scott用户的密码【此句也可以用来重置密码】 alter user scott identified by tiger; --切换到scott用户下 --单行函数:作用于一行,返回一个值。 ---字符函数 select upper('yes') from dual;--YES select lower('YES') from dual;--yes ----数值函数 select round(56.16, -2) from dual;---四舍五入,后面的参数表示保留的位数 select trunc(56.16, -1) from dual;---直接截取,不在看后面位数的数字是否大于5. select mod(10, 3) from dual;---求余数 ----日期函数 ----查询出emp表中所有员工入职距离现在几天。 select sysdate-e.hiredate from emp e; ----算出明天此刻 select sysdate+1 from dual; ----查询出emp表中所有员工入职距离现在几月。 select months_between(sysdate,e.hiredate) from emp e; ----查询出emp表中所有员工入职距离现在几年。 select months_between(sysdate,e.hiredate)/12 from emp e; ----查询出emp表中所有员工入职距离现在几周。 select round((sysdate-e.hiredate)/7) from emp e; ----转换函数 ---日期转字符串 select to_char(sysdate, 'fm yyyy-mm-dd hh24:mi:ss') from dual; ---字符串转日期 select to_date('2018-6-7 16:39:50', 'fm yyyy-mm-dd hh24:mi:ss') from dual; ----通用函数 ---算出emp表中所有员工的年薪 ----奖金里面有null值,如果null值和任意数字做算术运算,结果都是null。 select e.sal*12+nvl(e.comm, 0) from emp e; ---条件表达式 ---条件表达式的通用写法,mysql和oracle通用 ---给emp表中员工起中文名 select e.ename, case e.ename when 'SMITH' then '曹贼' when 'ALLEN' then '大耳贼' when 'WARD' then '诸葛小儿' --else '无名' end from emp e; ---判断emp表中员工工资,如果高于3000显示高收入,如果高于1500低于3000显示中等收入, -----其余显示低收入 select e.sal, case when e.sal>3000 then '高收入' when e.sal>1500 then '中等收入' else '低收入' end from emp e; ----oracle中除了起别名,都用单引号。 ----oracle专用条件表达式 select e.ename, decode(e.ename, 'SMITH', '曹贼', 'ALLEN', '大耳贼', 'WARD', '诸葛小儿', '无名') "中文名" from emp e; --多行函数【聚合函数】:作用于多行,返回一个值。 select count(1) from emp;---查询总数量 select sum(sal) from emp;---工资总和 select max(sal) from emp;---最大工资 select min(sal) from emp;---最低工资 select avg(sal) from emp;---平均工资 ---分组查询 ---查询出每个部门的平均工资 ---分组查询中,出现在group by后面的原始列,才能出现在select后面 ---没有出现在group by后面的列,想在select后面,必须加上聚合函数。 ---聚合函数有一个特性,可以把多行记录变成一个值。 select e.deptno, avg(e.sal)--, e.ename from emp e group by e.deptno; ---查询出平均工资高于2000的部门信息 select e.deptno, avg(e.sal) asal from emp e group by e.deptno having avg(e.sal)>2000; ---所有条件都不能使用别名来判断。 --比如下面的条件语句也不能使用别名当条件 select ename, sal s from emp where sal>1500; ---查询出每个部门工资高于800的员工的平均工资 select e.deptno, avg(e.sal) asal from emp e where e.sal>800 group by e.deptno; ----where是过滤分组前的数据,having是过滤分组后的数据。 ---表现形式:where必须在group by之前,having是在group by之后。 ---查询出每个部门工资高于800的员工的平均工资 ---然后再查询出平均工资高于2000的部门 select e.deptno, avg(e.sal) asal from emp e where e.sal>800 group by e.deptno having avg(e.sal)>2000; ---多表查询中的一些概念 ---笛卡尔积 select * from emp e, dept d; ---等值连接 select * from emp e, dept d where e.deptno=d.deptno; ---内连接 select * from emp e inner join dept d on e.deptno = d.deptno; ---查询出所有部门,以及部门下的员工信息。【外连接】 select * from emp e right join dept d on e.deptno=d.deptno; ---查询所有员工信息,以及员工所属部门 select * from emp e left join dept d on e.deptno=d.deptno; ---oracle中专用外连接 select * from emp e, dept d where e.deptno(+) = d.deptno; select * from emp; ---查询出员工姓名,员工领导姓名 ---自连接:自连接其实就是站在不同的角度把一张表看成多张表。 select e1.ename, e2.ename from emp e1, emp e2 where e1.mgr = e2.empno; ------查询出员工姓名,员工部门名称,员工领导姓名,员工领导部门名称 select e1.ename, d1.dname, e2.ename, d2.dname from emp e1, emp e2, dept d1, dept d2 where e1.mgr = e2.empno and e1.deptno=d1.deptno and e2.deptno=d2.deptno; ---子查询 ---子查询返回一个值 ---查询出工资和SCOTT一样的员工信息 select * from emp where sal = (select sal from emp where ename = 'SCOTT') ---子查询返回一个集合 ---查询出工资和10号部门任意员工一样的员工信息 select * from emp where sal in (select sal from emp where deptno = 10); ---子查询返回一张表 ---查询出每个部门最低工资,和最低工资员工姓名,和该员工所在部门名称 ---1,先查询出每个部门最低工资 select deptno, min(sal) msal from emp group by deptno; ---2,三表联查,得到最终结果。 select t.deptno, t.msal, e.ename, d.dname from (select deptno, min(sal) msal from emp group by deptno) t, emp e, dept d where t.deptno = e.deptno and t.msal = e.sal and e.deptno = d.deptno; ----oracle中的分页 ---rownum行号:当我们做select操作的时候, --每查询出一行记录,就会在该行上加上一个行号, --行号从1开始,依次递增,不能跳着走。 ----排序操作会影响rownum的顺序 select rownum, e.* from emp e order by e.sal desc ----如果涉及到排序,但是还要使用rownum的话,我们可以再次嵌套查询。 select rownum, t.* from( select rownum, e.* from emp e order by e.sal desc) t; ----emp表工资倒叙排列后,每页五条记录,查询第二页。 ----rownum行号不能写上大于一个正数。 select * from( select rownum rn, tt.* from( select * from emp order by sal desc ) tt where rownum<11 ) where rn>5
一些细节:
在oracle函数中不能使用双引号。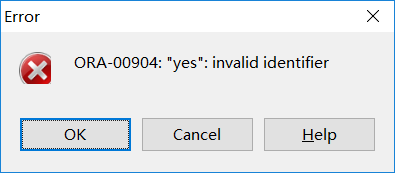
无效的标识符。
invalid (n. 无效的) valid (n.有效的) identifier (n. 标识符)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号