缓存设计中的热点问题讨论
缓存穿透
缓存穿透是指缓存没有起到作用,应用程序的请求大量到达了后端数据库的情况。因为查询时如果所需数据在缓存中不存在,便会到数据库中进行再次查询,当这样的数据量太大时,说明我们的缓存系统根本没有其他应有的作用。造成这样情况的有两个原因:
- 数据本身就不存在,我们通常用命中率用来衡量缓存系统设计的好坏,一般来说命中率能够达到80%以上说明就不错了。当对一些系统中不存在的数据进行查询时,这部分请求就会直接转发到数据库中,如竞争对手可能使用爬虫进行恶意遍历查询,导致数据库的压力增大。
- 数据的生产需要经过大量的计算,耗时较长,这种情况常见于电商系统,如在商品列的分页时,商品数据很庞大,且筛选的规则很多,要根据不同条件生成结果需要一定的时间,如果在大并发的情况下,瞬间的流量可能回拖垮数据库。
解决方案
1.采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
2.简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存雪崩
缓存雪崩是指我们设置缓存时采用了相同的过期时间,导致缓存失效后系统性能急剧下降的情况。缓存失效后,要重新生成缓存可能需要一定量的计算,这个过程无疑要耗费时间,对于高并发的系统来说,同一时间内大量的线程都查询到缓存失效了,因此都在重新计算生成缓存,这时大量的计算可能会给服务器带来很大的压力,导致系统性能下降。
解决方案
缓存失效时的雪崩效应对底层系统的冲击非常可怕。
要解决这种情况通常有三种方式:
1.更新锁
更新缓存时使用锁机制,保证同一时间内只能有一个线程进行更新,其余线程要么等待要么返回空值或者默认值等;
2.后台更新
对于缓存数据统一使用一个后台线程进行更新,这个线程对于一些设定过期时间的数据,定时查询,发现如果接近过期时,便将其更新;
3.随机更新
简单方案就是让缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
缓存击穿(热点key)
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
造成问题的原因:
(1) 这个key是一个热点key(例如一个重要的新闻,一个热门的八卦新闻等等),所以这种key访问量可能非常大。
(2) 缓存的构建是需要一定时间的。(可能是一个复杂计算,例如复杂的sql、多次IO、多个依赖(各种接口)等等)
于是就会出现一个致命问题:在缓存失效的瞬间,有大量线程来构建缓存(见下图),造成后端负载加大,甚至可能会让系统崩溃 。
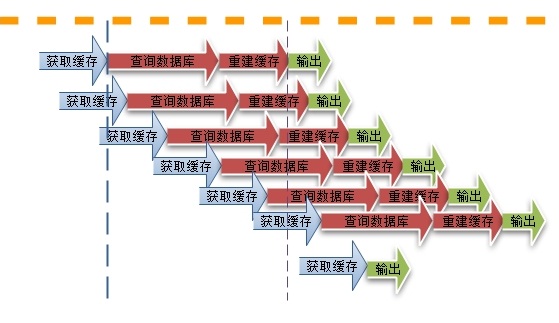
解决方案
缓存系列文章--8.热点key问题(mutex key)
缓存热点
虽然缓存系统本身性能较高,但是针对一些高热点的数据,同一时间内并发访问的请求太多时,也会出现瓶颈,此时可以将这些热点数据库保存多个副本,以减轻对同一服务器的读取压力。如热点微博,可能存多分副本,存放在不同的缓存服务器中,用户访问时根据不同的地理位置或用户特征访问不同的服务器,以减轻单点压力。再就是对于缓存系统,一般都会有个预热环节,就是在正式上线前,使用预发布的模式,先让其生成一些常用的缓存数据,然后再切换到全站,这样可以避免刚上线时瞬间的高流量对缓存系统进行冲击。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号