OO第四次总结性作业与课程总结
OO第四次总结性作业与课程总结
一、UML类图
三次作业迭代开发的思路都是相同的,这里就直接用最后一次作业的类图了。
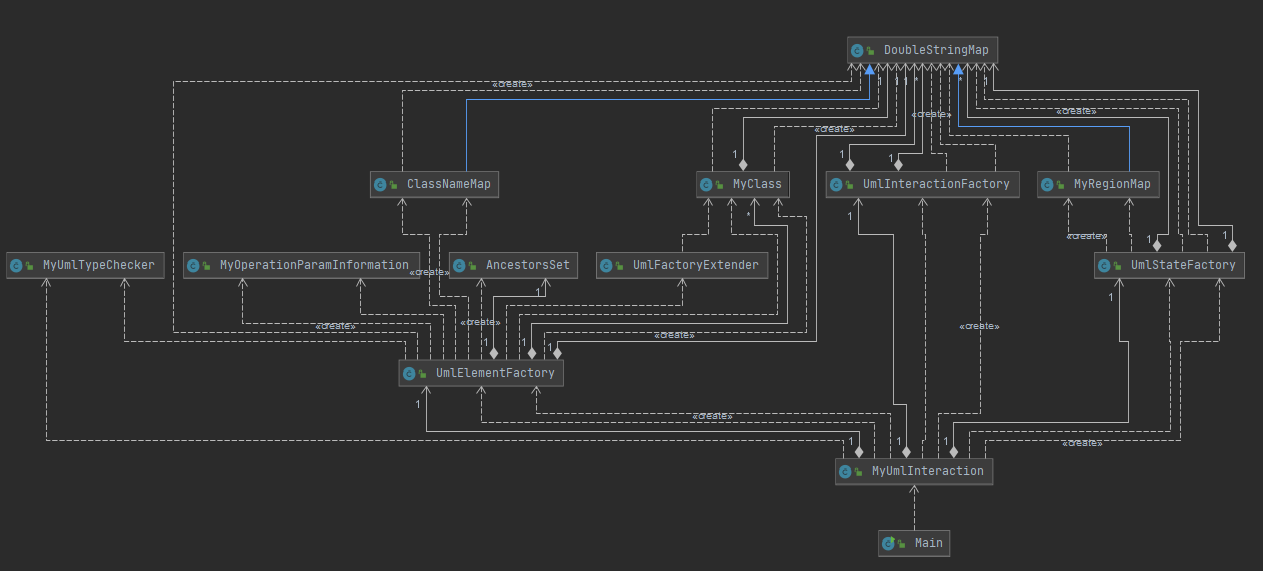
基本的思路从第一次作业开始就没有改变:将各种图中的各种元素以及他们之间的继承、实现等关系都看作是没有区别的描述UML的元素,即 UMLElement。在读入进来的时候我们不建立明显的树形关系,在有查询要求的时候,从对应的容器中取出所需要的信息验证。
在三次迭代开发之后,通过和同学的交流,我认为这种方式有利有弊(也许从OO的角度上来说弊大于利?)。利在于,其不依赖于读入顺序,同时相较于建树来管理相关关系不容易因为错误的输入导致空指针等一系列异常。除此之外,在三次迭代开发中基本上就是对已经建好的容器及其管理方式的复用(由于这个容器有两个字符串关键字,用两个Map套着实现,我把它叫做DoubleStringMap);缺点也是十分明显的,这种方式只是能够复用较为通用的元素容器,并不能兼顾不同元素所需要的不同操作,因此存容器的类还要兼顾各种元素的各种操作,没有很好的将复杂度分到各个部分(甚至为了压进500行还写了个类来扩展功能,可以说是很不面向对象了)。
其中 DoubleStringMap 分别支持了返回容器中所有元素和返回满足第一关键字的所有元素的操作。
public ArrayList<UmlElement> getElement(String first) {
ArrayList<UmlElement> ans = new ArrayList<>();
HashMap<String, UmlElement> secondMap = doubleStringMap.get(first);
if (secondMap == null) {
return ans;
}
for (String second : secondMap.keySet()) {
ans.add(secondMap.get(second));
}
return ans;
}
public ArrayList<UmlElement> getElement() {
ArrayList<UmlElement> ans = new ArrayList<>();
for (String first : doubleStringMap.keySet()) {
HashMap<String, UmlElement> secondMap = doubleStringMap.get(first);
if (secondMap == null) {
continue;
}
for (String second : secondMap.keySet()) {
ans.add(secondMap.get(second));
}
}
return ans;
}
而 AncestorSet 则通过 BFS 的方式支持了找到所有的继承或是实现关系。
public ArrayList<String> getAncestors(String id) {
ArrayList<String> ans = new ArrayList<>();
LinkedList<String> queue = new LinkedList<>();
HashSet<String> vst = new HashSet<>();
queue.add(id);
vst.add(id);
while (!queue.isEmpty()) {
String now = queue.getFirst();
queue.removeFirst();
ans.add(now);
ArrayList<String> ancestorSet = ancestors.get(now);
if (ancestorSet == null) {
continue;
}
for (String ancestorId : ancestorSet) {
if (!vst.contains(ancestorId)) {
queue.add(ancestorId);
vst.add(ancestorId);
}
}
}
return ans;
}
二、四个单元中架构设计及OO方法理解的演进
第一单元
第一单元是表达式求导。由于以前在算法竞赛中使用过表达式树,并且在和同学交流中了解过递归下降,因此在数据读入的处理上可以说是使用了比较好的架构。但是在对表达式的存储方面,为了方便对表达式进行简化,并没有采取老师所说的工厂模式等一系列设计模式,以至于在第三次作业中出现了严重的循环依赖问题,对于每个类都要单独处理也导致了难以通过简单测试测出的bug。
第二单元
第二单元是电梯。在第二单元中我充分吸取了第一单元的教训,在开始编写前搜索了老师在课上提到的设计模式并完成了实验作业,将观察者模式和单例模式等。因此第二单元的作业在第一次作业完成之后基本就没有改动,遵循了开闭原则。第二单元的作业主要难点在于多线程的各种冲突情况,但是只要在实现过程中对临界区变量做好保护,并且注意破除死锁的条件,就不容易出问题唯一一次出问题是因为分配任务的函数加漏一项导致 TLE。除此之外,第二单元第三次作业对于换乘的实现和结束条件的判断极大地加深了我对多线程的理解。
第三单元
第三单元是 JML。主要涉及到对 JML 的阅读,在实现上难度不大。通过这一次作业,我可以说是深刻理解到了这种设计模式的优势所在:在实现每个函数时能够专注于前置条件的检验以及具体的实现,而不用从整体的角度去思考,可以说是能够将复杂的问题极大的简化。在这一次的作业中我也能够更好地分出心思来尝试用继承关系和类的重写来对问题进行分解和简化。
第四单元
第四单元在架构上没有什么特殊的,基本上就是用 Map 在维护,重要的是通过这种方式理解各个元素的含义以及其在 UML 图中的作用。
三、四个单元中测试理解与实践的演进
第一单元
主要是通过自身编的一些边缘数据和随机数据进行测试,也正因如此在一些情况下考虑不周导致了读入和化简得错误。
第二单元
由于涉及到多线程的情景,因此将自己写的几个版本和从同学那里收集过来的代码同时运行大量随机数据并对答案进行验证并同时检测正确性和运行时间,由于测试数据更多地考虑到了互测的使用,导致第二次作业在范围更大的强测中运行超时。
第三单元
第三单元在进行随机测试的同时,也通过 JUnit 进行了一定覆盖程度的单元测试,其中断言等的使用方式能够很好地检验 JML 前置条件等约束。
第四单元
第四单元的测试主要是以多人对拍为主,在极限情况或是有争论的情况手动构造测试样例来进行测试。同时也手动构造极限范围的数据来测试代码效率。由于每种操作都互相独立,同样可以采取单元测试的方法进行测试。
四、课程收获
预习阶段
主要是了解了 java 的各种语法以及熟练使用了一系列比较常用的容器
第一单元
1、学会递归下降的方法。
2、了解了工厂模式的使用。
3、了解了依赖倒置原则和开闭原则。
4、了解了对于层次的分析以及继承、接口的使用。
第二单元
1、了解了单例模式、观察者模式、生产者-消费者模式等一系列设计模式。
2、学习了多线程相关的知识(线程安全、死锁等)。
3、熟练掌握了 wait - notifyAll 以及 synchronized 的使用。
第三单元
1、熟练掌握了 JML 的阅读和使用。
2、第一单元学到的一些设计方法在这一单元得到了实践。
第四单元
主要是了解了 UML 相关的阅读和理解。
给课程提三个具体改进建议
一、第一单元的性能分也许可以更换为评判代码架构或是复杂度的模式。因为从目的上来说,第一单元不是为了让同学把表达式简化地多么精简,而是为了让同学们能够接触到工厂模式以及能够进行层次和接口、继承相关的分析。
二、第二单元建议增加强制需要换乘的场景。因为如果采取不换乘的实现,那么第二次作业和第三次作业本质上没有大的差别,只需要对电梯可到达楼层做一些限制。强制换乘能够明显增加线程冲突的场景,能够加深同学们对于多线程的理解和使用。
三、预习作业建议不仅仅是通过 java 编程来解决问题,还可以加入一些设计方法的内容。仅仅是通过编程来解决问题,只能起到让同学们熟悉 java 使用,而如果在这个时候就渗透一些设计思路、方法在其中,或者说更进一步给前两次难度较高的作业打个基础,都能够让同学们的学习过程更加顺畅。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号