第一单元总结博客
第一次总结性博客作业
第一次作业
(一)基于度量来分析自己的结构
下表是基于度量对每个类进行的分析,其中,CogC 为 Cognitive Complexity(认知复杂度,即代码可读性)
ev(G) 为 Essential Cyclomatic Complexity (基本复杂度)
iv(G) 为 Module Design Complexity (模块设计复杂度)
v(G) 为 Cyclomatic Complexity (圈复杂度)
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Item.Item(BigInteger,BigInteger) | 0 | 1 | 1 | 1 |
| Item.Item(int,int) | 0 | 1 | 1 | 1 |
| Item.addNumber(Item) | 0 | 1 | 1 | 1 |
| Item.compareTo(Object) | 0 | 1 | 1 | 1 |
| Item.diff(boolean) | 7 | 1 | 7 | 10 |
| Item.getNumber() | 0 | 1 | 1 | 1 |
| Item.getPower() | 0 | 1 | 1 | 1 |
| Item.isZero() | 0 | 1 | 1 | 1 |
| Item.mul(Item) | 0 | 1 | 1 | 1 |
| Item.setPower(BigInteger) | 0 | 1 | 1 | 1 |
| Main.main(String[]) | 0 | 1 | 1 | 1 |
| Poly.Poly(String) | 0 | 1 | 1 | 1 |
| Poly.diff() | 5 | 3 | 4 | 5 |
| Poly.getItem(int) | 3 | 1 | 3 | 3 |
| Poly.getPoly() | 1 | 1 | 2 | 2 |
| Stringhandler.Stringhandler(String) | 0 | 1 | 1 | 1 |
| Stringhandler.getCharactor() | 1 | 1 | 1 | 3 |
| Stringhandler.getFactor() | 5 | 1 | 4 | 4 |
| Stringhandler.getNext(int) | 1 | 1 | 1 | 2 |
| Stringhandler.isEnd() | 0 | 1 | 1 | 1 |
| Stringhandler.isMul() | 1 | 2 | 1 | 2 |
| Stringhandler.whitespace() | 5 | 4 | 3 | 5 |
可以看到,由于第一次的需求较为简单,大部分的方法的复杂度都较低,主要复杂度集中在求导方法上,处理字符串的方法由于在处理项和表达式时都有使用,类的内聚性较强,但是耦合性也较强,存在明显的相互依赖。
类图如下:
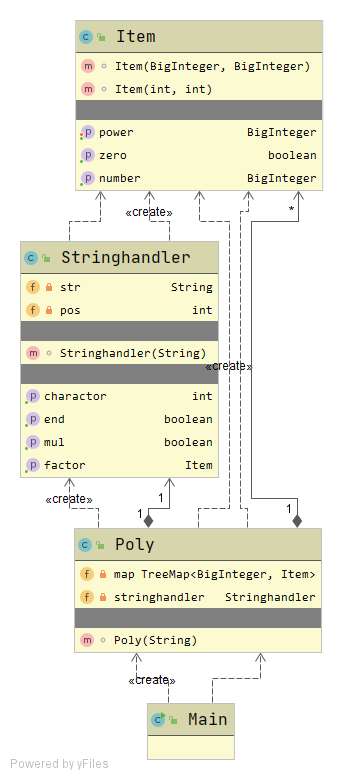
从类图来看,第一次作业的优点和缺点都是较为清晰的。采取“表达式--项--因子” 这种模式的优势就在于结构较为清晰,求导的方法好写,并且和递归下降的思路接近,能够很好的对读入字符串进行解析。除此之外,还采用了map的方式对项进行维护,在重载equals方法后能够起到自动合并同类项的效果,能够拿到不错的性能分。但是,缺点也是十分明显的:在这种固定的面向过程的思路下,这种模板的可扩展性极弱,没有用统一的工厂类对所有新生成的类进行管理,而是在字符串处理类里面完成了这一工作,所有的类并没有相互继承的关系,没有统一的求导方法等。。。这些都直接导致了第二次作业的重构。
(二)分析自己程序的bug
由于采用的结构较为清晰,求导方法也较为简单,并没有出现bug。不过同房间中另一人的bug比较有参考价值:他没有使用系统的排序,而是使用了自己 ”造轮子“ 的方式来进行排序,结果导致在2的次幂的特殊情况下排序无法比较两个元素的大小抛出异常,被人hack。这也就是助教反复提示我们的:不要自己造轮子。自己完成某些操作或许能够带来更好的性能,但没有经过验证的基础部分无疑是代码中的隐患。
(三)分析自己发现别人bug所采用的策略
第一次发现bug主要还是基于随机数据的生成和结合python的结果进行自动评测,重点针对了无法处理数据大小在biginteger范围的同学,以及无法对 ”+-+0“ 等一系列符合要求的较为极端的输入情况进行处理的同学,由于时间紧迫并没有一个个去阅读他人的代码进行hack。
第二次作业
(一)基于度量来分析自己的结构
下表是基于度量对每个类进行的分析:
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Cos.Cos() | 0 | 1 | 1 | 1 |
| Cos.Cos(BigInteger) | 0 | 1 | 1 | 1 |
| Cos.Cos(String) | 0 | 1 | 1 | 1 |
| Cos.clone() | 0 | 1 | 1 | 1 |
| Cos.diff() | 0 | 1 | 1 | 1 |
| Cos.equals(Object) | 0 | 1 | 1 | 1 |
| Cos.hashCode() | 0 | 1 | 1 | 1 |
| Cos.isZero() | 0 | 1 | 1 | 1 |
| Cos.mul(Cos) | 0 | 1 | 1 | 1 |
| Cos.toString() | 2 | 3 | 1 | 3 |
| Item.Item() | 0 | 1 | 1 | 1 |
| Item.Item(Number,Power,Sin,Cos,LinkedHashMap<Poly, Integer>) | 0 | 1 | 1 | 1 |
| Item.Item(Stringhandler,int) | 1 | 1 | 2 | 2 |
| Item.add(Item) | 0 | 1 | 1 | 1 |
| Item.clone() | 1 | 1 | 2 | 2 |
| Item.diff() | 11 | 1 | 8 | 8 |
| Item.diffcos() | 2 | 2 | 2 | 3 |
| Item.diffpow() | 2 | 2 | 2 | 3 |
| Item.diffsin() | 2 | 2 | 2 | 3 |
| Item.equals(Object) | 8 | 5 | 7 | 9 |
| Item.getFactor(Stringhandler) | 4 | 1 | 2 | 7 |
| Item.getString(String,boolean,int) | 35 | 5 | 8 | 18 |
| Item.hashCode() | 3 | 1 | 3 | 3 |
| Item.isZero() | 0 | 1 | 1 | 1 |
| Item.lowcnt() | 5 | 1 | 2 | 6 |
| Item.mergeable(Item) | 8 | 5 | 7 | 9 |
| Item.toString() | 10 | 3 | 2 | 8 |
| Item.tolower() | 5 | 6 | 1 | 6 |
| Item.toupper() | 2 | 1 | 3 | 3 |
| Item.upcnt() | 3 | 3 | 2 | 3 |
| Main.main(String[]) | 0 | 1 | 1 | 1 |
| Number.Number() | 0 | 1 | 1 | 1 |
| Number.Number(BigInteger) | 0 | 1 | 1 | 1 |
| Number.Number(String) | 0 | 1 | 1 | 1 |
| Number.add(Number) | 0 | 1 | 1 | 1 |
| Number.clone() | 0 | 1 | 1 | 1 |
| Number.diff() | 0 | 1 | 1 | 1 |
| Number.equals(Object) | 0 | 1 | 1 | 1 |
| Number.hashCode() | 0 | 1 | 1 | 1 |
| Number.isNormal() | 1 | 1 | 2 | 2 |
| Number.isZero() | 0 | 1 | 1 | 1 |
| Number.mul(Number) | 0 | 1 | 1 | 1 |
| Number.toString() | 0 | 1 | 1 | 1 |
| Poly.Poly() | 0 | 1 | 1 | 1 |
| Poly.Poly(String) | 0 | 1 | 1 | 1 |
| Poly.clone() | 1 | 1 | 2 | 2 |
| Poly.diff() | 3 | 1 | 3 | 3 |
| Poly.equals(Object) | 6 | 5 | 3 | 5 |
| Poly.getItem() | 1 | 1 | 2 | 2 |
| Poly.getPoly(Stringhandler) | 11 | 1 | 6 | 6 |
| Poly.hashCode() | 1 | 1 | 2 | 2 |
| Poly.insert(Item) | 3 | 3 | 3 | 3 |
| Poly.toString() | 9 | 4 | 4 | 7 |
| Poly.tolower() | 5 | 4 | 3 | 4 |
| Power.Power() | 0 | 1 | 1 | 1 |
| Power.Power(BigInteger) | 0 | 1 | 1 | 1 |
| Power.Power(String) | 0 | 1 | 1 | 1 |
| Power.clone() | 0 | 1 | 1 | 1 |
| Power.diff() | 0 | 1 | 1 | 1 |
| Power.equals(Object) | 0 | 1 | 1 | 1 |
| Power.hashCode() | 0 | 1 | 1 | 1 |
| Power.isZero() | 0 | 1 | 1 | 1 |
| Power.mul(Power) | 0 | 1 | 1 | 1 |
| Power.toString() | 3 | 4 | 1 | 4 |
| Sin.Sin() | 0 | 1 | 1 | 1 |
| Sin.Sin(BigInteger) | 0 | 1 | 1 | 1 |
| Sin.Sin(String) | 0 | 1 | 1 | 1 |
| Sin.clone() | 0 | 1 | 1 | 1 |
| Sin.diff() | 0 | 1 | 1 | 1 |
| Sin.equals(Object) | 0 | 1 | 1 | 1 |
| Sin.hashCode() | 0 | 1 | 1 | 1 |
| Sin.isZero() | 0 | 1 | 1 | 1 |
| Sin.mul(Sin) | 0 | 1 | 1 | 1 |
| Sin.toString() | 2 | 3 | 1 | 3 |
| Stringhandler.Stringhandler(String) | 0 | 1 | 1 | 1 |
| Stringhandler.getCharactor() | 1 | 1 | 1 | 3 |
| Stringhandler.getCos() | 3 | 2 | 3 | 3 |
| Stringhandler.getFactor() | 1 | 5 | 5 | 5 |
| Stringhandler.getNext(int) | 1 | 1 | 1 | 2 |
| Stringhandler.getNumber() | 0 | 1 | 1 | 1 |
| Stringhandler.getPoly() | 7 | 3 | 2 | 5 |
| Stringhandler.getPower() | 3 | 2 | 3 | 3 |
| Stringhandler.getSin() | 3 | 2 | 3 | 3 |
| Stringhandler.isEnd() | 0 | 1 | 1 | 1 |
| Stringhandler.isMul() | 1 | 2 | 1 | 2 |
| Stringhandler.whitespace() | 5 | 4 | 3 | 5 |
可以看到,第二次的作业相较第一次的作业,复杂度明显上升,并且采用了 ”表达式--项--表达式“ 这种类似于树形的结构对表达式进行维护、合并和求导,采用了统一的父类 Node 并且对子类的 equals、hashCode、toString 均进行了重写。但是,这种结构并没有充分利用继承的特性,在Item(项)中依旧对每个类进行不同的处理,没有采用统一的求导,toString 方法等,导致所有处理的复杂度集中在了 Item 类中,getString() 等一系列方法的复杂度和理解难度大大增加。
类图如下:
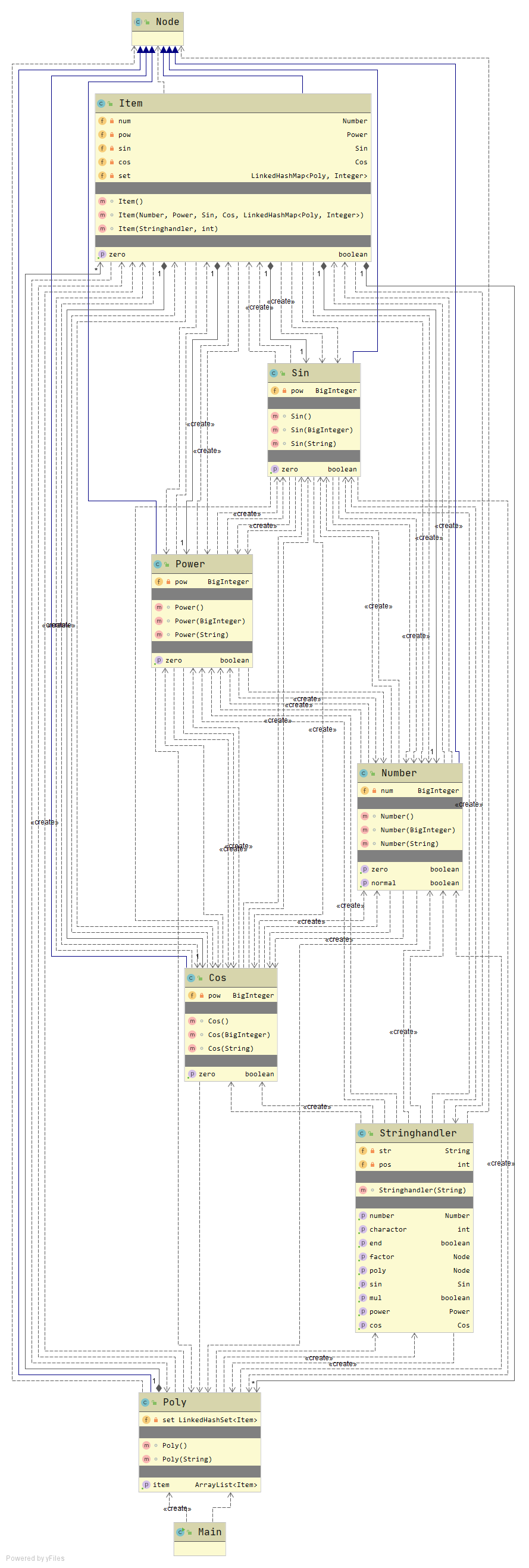
可以看到,Cos, Sin, Power, Number 几个较简单的类基本只对其内部存的BigInteger进行处理和维护,而Item 类和 Poly 类为了支持 ”表达式--项--表达式“ 这种树形结构,方便处理,有着十分明显的循环依赖问题,同时也使得Node类形同虚设,各个子类都被严格限定了类型,除了在字符串处理类返回类型的时候可以统一的进行管理,别的时候基本上只有明确知道类的类型才能够进行具体的操作,可拓展性较差。并且这种循环依赖的结构也面临着较大的复杂度的问题,特别是在遇到括号嵌套的过程中,树的深度迅速增长,导致输出和求导的复杂度以一个极快的速度上升,对我的优化提出了极高的限制:必须在建树的过程中完成去括号等一系列优化。显然,这种写法是极其面向过程,可拓展性极差的。
(二) 分析自己程序的bug
第二次作业在大量进行随机测试的基础上,也没有出现 bug。这里就不再赘述。
(三)分析自己发现别人bug所采用的策略
从这一次开始,进行优化的代价开始增大,分析别人bug的策略也从一开始的抓数据范围、抓字符串解析逐渐转到对各种优化进行针对性的测试。像是通过连续的括号嵌套,在去括号中塞入0,sin(0) 等一系列可能会被优化错误的值,具体读代码的时候还会发现有的同学自作聪明将正确的形式判定为 WrongFormat。当然,对于 sin() , cos() 之间的空格,也是这次作业针对没有认真读题的同学的重点。
(四)重构经历总结
这一次作业,为了支持表达式的嵌套,做了大量的重构,首先是所有的因子有关的类都统一继承了Node,来方便某些具有共性的处理(虽然并没有很好地去运用),其次就是为了使用 map 对同类项进行合并,对 equals 和 hashCode 等方法进行了重写。当然,这些准备工作是十分必要的。在完成这些操作后同时也完成了对求导方法的重写。虽然利用了继承的一些性质,但整体来说,整个的求导方法和字符串的生成,都是十分面向过程的,对每个类都进行了单独、特殊的特判处理,没有很好地去利用他们的共性。
第三次作业
(一)基于度量分析自己的结构
基于度量对每个类进行分析:
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Cos.Cos(String,int) | 0 | 1 | 1 | 1 |
| Item.Item() | 0 | 1 | 1 | 1 |
| Item.Item(Number,Power,LinkedHashMap<Poly, Long>,LinkedHashMap<Poly, Long>,LinkedHashMap<Poly, Long>) | 0 | 1 | 1 | 1 |
| Item.Item(Stringhandler,int) | 2 | 1 | 2 | 3 |
| Item.add(Item) | 0 | 1 | 1 | 1 |
| Item.clone() | 3 | 1 | 4 | 4 |
| Item.cmpmap(LinkedHashMap<Poly, Long>,LinkedHashMap<Poly, Long>) | 8 | 5 | 7 | 9 |
| Item.diff() | 1 | 1 | 2 | 2 |
| Item.diffcos(ArrayList |
11 | 1 | 6 | 6 |
| Item.diffpoly(ArrayList |
8 | 1 | 5 | 5 |
| Item.diffpow() | 4 | 2 | 4 | 5 |
| Item.diffsin(ArrayList |
11 | 1 | 6 | 6 |
| Item.equals(Object) | 0 | 1 | 1 | 1 |
| Item.factornum() | 0 | 1 | 1 | 1 |
| Item.getFactor(Stringhandler) | 27 | 1 | 7 | 15 |
| Item.getString(String,boolean,int) | 35 | 5 | 8 | 18 |
| Item.hashCode() | 9 | 1 | 7 | 7 |
| Item.isZero() | 0 | 1 | 1 | 1 |
| Item.lowcnt() | 5 | 1 | 2 | 6 |
| Item.mergeable(Item) | 0 | 1 | 1 | 1 |
| Item.single() | 9 | 2 | 3 | 8 |
| Item.toString() | 30 | 9 | 6 | 17 |
| Item.tolower() | 5 | 6 | 3 | 6 |
| Item.toupper() | 14 | 1 | 7 | 7 |
| Item.upcnt() | 10 | 3 | 4 | 8 |
| Main.main(String[]) | 1 | 1 | 2 | 2 |
| Number.Number() | 0 | 1 | 1 | 1 |
| Number.Number(BigInteger) | 0 | 1 | 1 | 1 |
| Number.Number(String) | 0 | 1 | 1 | 1 |
| Number.add(Number) | 0 | 1 | 1 | 1 |
| Number.clone() | 0 | 1 | 1 | 1 |
| Number.equals(Object) | 0 | 1 | 1 | 1 |
| Number.hashCode() | 0 | 1 | 1 | 1 |
| Number.isNormal() | 1 | 1 | 2 | 2 |
| Number.isZero() | 0 | 1 | 1 | 1 |
| Number.mul(Number) | 0 | 1 | 1 | 1 |
| Number.toString() | 0 | 1 | 1 | 1 |
| Poly.Poly() | 0 | 1 | 1 | 1 |
| Poly.Poly(String,int) | 0 | 1 | 1 | 1 |
| Poly.clone() | 1 | 1 | 2 | 2 |
| Poly.diff() | 3 | 1 | 3 | 3 |
| Poly.equals(Object) | 6 | 5 | 3 | 5 |
| Poly.factornum() | 1 | 2 | 1 | 2 |
| Poly.getItem() | 1 | 1 | 2 | 2 |
| Poly.getPoly(Stringhandler) | 18 | 4 | 6 | 11 |
| Poly.hashCode() | 1 | 1 | 2 | 2 |
| Poly.insert(Item) | 3 | 3 | 3 | 3 |
| Poly.isFactor() | 2 | 3 | 2 | 3 |
| Poly.single() | 0 | 1 | 1 | 1 |
| Poly.toString() | 9 | 4 | 4 | 7 |
| Poly.tolower() | 5 | 4 | 3 | 4 |
| Power.Power() | 0 | 1 | 1 | 1 |
| Power.Power(BigInteger) | 0 | 1 | 1 | 1 |
| Power.Power(String) | 0 | 1 | 1 | 1 |
| Power.clone() | 0 | 1 | 1 | 1 |
| Power.diff() | 0 | 1 | 1 | 1 |
| Power.equals(Object) | 0 | 1 | 1 | 1 |
| Power.hashCode() | 0 | 1 | 1 | 1 |
| Power.isZero() | 0 | 1 | 1 | 1 |
| Power.mul(Power) | 0 | 1 | 1 | 1 |
| Power.toString() | 2 | 3 | 1 | 3 |
| Sin.Sin(String,int) | 0 | 1 | 1 | 1 |
| Stringhandler.Stringhandler(String,int) | 0 | 1 | 1 | 1 |
| Stringhandler.getCharactor() | 2 | 2 | 1 | 4 |
| Stringhandler.getCos() | 23 | 10 | 7 | 18 |
| Stringhandler.getFactor() | 2 | 6 | 5 | 6 |
| Stringhandler.getNext(int) | 1 | 1 | 1 | 2 |
| Stringhandler.getNumber() | 2 | 2 | 2 | 3 |
| Stringhandler.getP() | 6 | 3 | 4 | 5 |
| Stringhandler.getPoly() | 9 | 4 | 2 | 6 |
| Stringhandler.getPower() | 2 | 2 | 1 | 2 |
| Stringhandler.getSin() | 23 | 10 | 7 | 18 |
| Stringhandler.isEnd() | 0 | 1 | 1 | 1 |
| Stringhandler.isMul() | 1 | 2 | 1 | 2 |
| Stringhandler.whitespace() | 5 | 4 | 3 | 5 |
| Trip.Trip(Node,Long,boolean) | 0 | 1 | 1 | 1 |
| Trip.getPower() | 0 | 1 | 1 | 1 |
| Trip.getTriangle() | 0 | 1 | 1 | 1 |
| Trip.issin() | 0 | 1 | 1 | 1 |
从度量上不难看出,第三次作业在第二次作业上没有进行过大的改动,根据 Sin 和 Cos 能够包含表达式的特性,直接将其改成了 Poly 类的子类,并采用和 Poly 类几乎一样的方法来进行维护。同时,为了对能够带指数的三角函数进行去括号的优化,新增了 Trip 类来进行维护,Sin 类和 Cos 类的复杂度和 Poly 类几乎一样,是读入处理复杂度的主要来源。
类图如下:
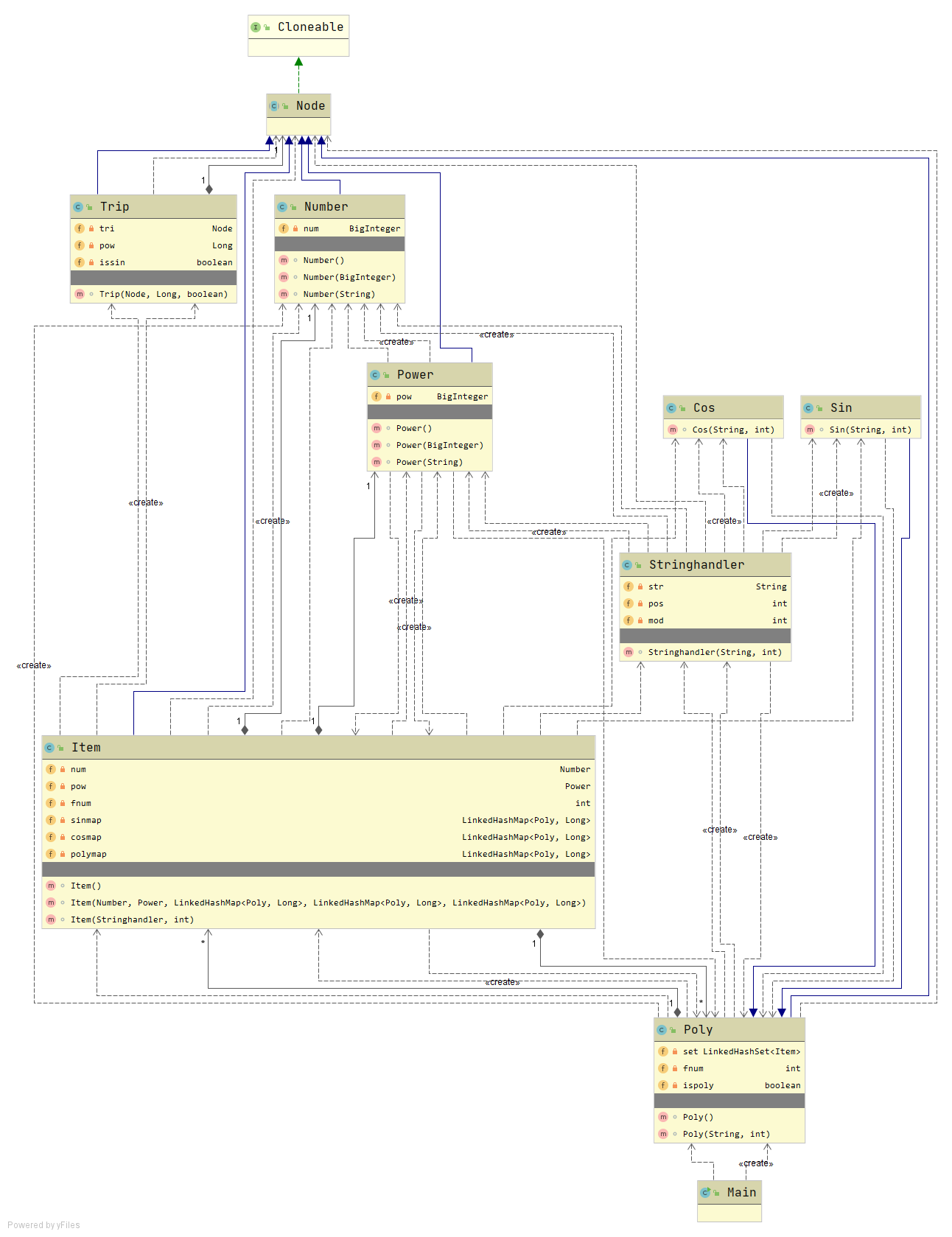
不难看出,Power,Number 等类几乎没有打的改动,Sin 和 Cos类基本上也是直接继承 Poly 类得到的, 由于不想再次进行大范围的重构,Item 依然对各个类分别进行了特别的处理,这也导致代码的整个体量变大,可读性变差,内聚性差,类和类的依赖性较强,从面向对象的角度来说,可以说是很失败的设计。
(二)分析自己程序的bug
这一次作业在强测中出了两个bug,下面分别进行分析:
(1)第一个 bug 本应该避免,由于对题目的阅读不够仔细,认为输入的值用 Long 就可以存下,却忽略了 WrongFormat,改为 BigInteger 就可以解决这个问题.
(2)第二个 bug 源自于设计的缺陷。由于并没有把所有因子用统一的类来管理,Cos 和 Sin 类是 Poly 的子类,也就是说,我们无法通过解析直接判断其中是否是单独的因子,只能先将其作为表达式因子读入。在表达式因子要求必须多一层括号的情况下,就很难对 WrongFormat进行判断。虽然通过特判的方法能够判断其中的因子数量,但形如 (+‘ ’123)这种被空格所隔开的表达式因子就能够轻易的绕过特判被判成常数因子,导致错误。
(三)分析自己发现别人bug 所采用的策略
这次 hack 的要点还是集中在优化上,除此之外,还需要对 Wrong Format 进行一定的针对。我们可以采取对各种可能出现空格的地方加入空格,对指数进行设计来尝试让别人的 Wrong Format出错。除此之外,将 ”x**2“ 输出成为 ”x*x“ 的优化也是我们可以针对的重点,由于表达式因子必须多带一层括号,这种优化配合上检测到不是表达式因子便少一层括号的优化就会输出错误的形式,实际上也有不少人在这里出问题。当然之前的在表达式因子中放入 0 等一系列思路依然适用于 Sin 和 Cos 。
(四)重构经历总结
这一次的作业我并没有进行大范围的重构,其原因不是在于我第二次的作业的架构有多强的扩展性,而是第二次作业时我已经大致了解了第三次作业的内容并尝试向这方面做出设计。尽管如此,在增量开发的过程中,还是能明显感觉到之前的设计给增量开发带来的困难,对同一个处理仍然会使用大量的复制来复用。可以说,这一次可以说是较为失败的经验让我充分理解了面向对象的思路的重要性。
心得体会
本次作业是面向对象的第一次作业,虽然我没有亲自写出可拓展性较好的、面向对象的代码,但在两次实验课和两次研讨课同学的分享、自己的实践中,我逐渐开始理解到了面向对象编程的特点和优势所在,开始理解了工厂类、抽象类、接口类等机制的使用原理和思路,理解了一个好的架构的重要性。除此之外,为了实现优化,我还顺道学习了递归下降等一系列方法,也对我有很大的帮助。希望在下一次的作业中能够更好地运用面向对象的特性,写出鲁棒性强、可扩展性强的代码。

