笔记:树链剖分 之 轻重链剖分
Step 0-介绍
在之前线段树的学习中,我们知道了如何对一个区间进行快速修改。
同样我们可以在树上进行快速修改(什么脑回路),完成以下几个操作:
-
修改树上两点之间的路径上所有点的值。
-
查询树上两点之间的路径上节点权值的和/极值/其它(在序列上可以用数据结构维护,便于合并的信息)。
-
此外,树剖还可以用来 \(O(\log n)\)(且常数较小)地求 \(LCA\)。在某些题目中,还可以利用其性质来灵活地运用树剖。
Q:那么在一棵树上要如何进行修改呢?
没错!就是树链剖分
Q:要怎么做呢?
就是把一颗树 分尸(大雾 分成几条链,再拼成一个线段树...
那么接下来要解决的就是如何不重不漏的分尸了。
Step 1-几种分尸方法
- 重链剖分
- 长链剖分(
不会) - 用于 Link/cut Tree 的剖分(有时被称作“实链剖分”)(
不会)
ps:大多数情况下(没有特别说明时), “树链剖分” 都指 “重链剖分” 。
Step 2-详解
1.重链剖分
(1)一些定义:
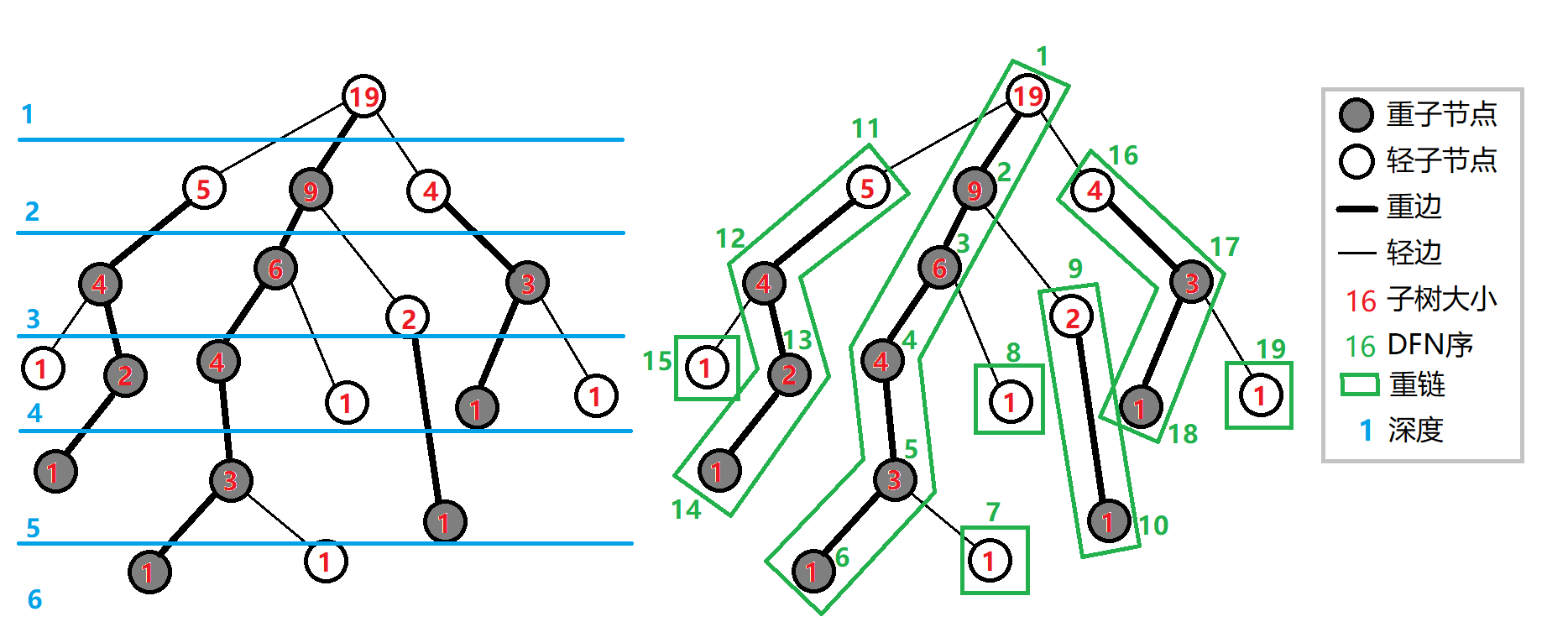
定义 重子节点 表示其子节点中子树最大的子结点。如果有多个子树最大的子结点,取其一。如果没有子节点,就无重子节点。
定义 轻子节点 表示剩余的所有子结点。
从这个结点到重子节点的边为 重边 。
到其他轻子节点的边为 轻边 。
若干条首尾衔接的重边构成 重链 。
把落单的结点也当作重链,那么整棵树就被剖分成若干条重链。
如图:
(2)重链剖分的性质
-
树上每个节点都属于且仅属于一条重链 。
-
重链开头的结点不一定是重子节点。
-
所有的重链将整棵树 完全剖分 。
-
在剖分时 优先遍历重儿子 ,最后重链的 DFS 序就会是连续的。
-
在剖分时 重边优先遍历 ,最后树的 DFN 序上,重链内的 DFN 序是连续的。按 DFN 排序后的序列即为剖分后的链。
-
一颗子树内的 DFN 序是连续的。
-
可以发现,当我们向下经过一条 轻边 时,所在子树的大小至少会除以二。
-
对于树上的任意一条路径,把它拆分成从 \(lca\) 分别向两边往下走,分别最多走 \(O(\log n)\) 次,因此,树上的每条路径都可以被拆分成不超过 \(O(\log n)\) 条重链。
(3)实现思路
树剖的实现分两个 DFS 的过程。伪代码如下:
第一个 DFS 记录每个结点的父节点(father)、深度(deep)、子树大小(size)、重子节点(hson)。
第二个 DFS 记录所在链的链顶(top,应初始化为结点本身)、重边优先遍历时的 DFS 序(dfn)、DFS 序对应的节点编号(rank)。
(4)代码实现
定义几个数组:
- \(fa(x)\) 表示节点 \(x\) 在树上的父亲。
- \(dep(x)\) 表示节点 \(x\) 在树上的深度。
- \(siz(x)\) 表示节点 \(x\) 的子树的节点个数。
- \(son(x)\) 表示节点 \(x\) 的 重儿子 。
- \(top(x)\) 表示节点 \(x\) 所在 重链 的顶部节点(深度最小)。
- \(dfn(x)\) 表示节点 \(x\) 的 DFS 序 ,也是其在线段树中的编号。
- \(rnk(x)\) 表示 DFS 序所对应的节点编号,有 \(rnk(dfn(x))=x\) 。
我们进行两遍 DFS 预处理出这些值,其中第一次 DFS 求出 \(fa(x)\) , \(dep(x)\) , \(siz(x)\) , \(son(x)\) ,第二次 DFS 求出 \(top(x)\) , \(dfn(x)\) , \(rnk(x)\) 。
void dfs1(int u) //第一次 DFS 求出 fa(x), dep(x), siz(x), son(x);
{
siz[u]=1;
for(int i=head[u];i;i=next[i])
{
int v=to[i];
if(v==fa[u]) continue;
dep[v]=dep[u]+1;
fa[v]=u;
dfs1(v);
siz[u]+=siz[v];
if(siz[v]>siz[son[u]]) son[u]=v;
}
}
void dfs2(int u, int tt) //第二次 DFS 求出 top(x), dfn(x), rank(x);
{
top[u]=tt;
dfn[u]=++cnt;
rank[cnt]=u;
if(!son[u]) return;
dfs2(son[u],tt); //优先对重儿子进行 DFS,可以保证同一条重链上的点 DFS 序连续
for(int i=head[u];i;i=next[i])
{
int v=to[i];
if(v!=son[u]&&v!=fa[u])
dfs2(v,v);
}
}
Q:具体操作呢?
请进-->新人食用之树剖
2.长链剖分
请进-->树链剖分
3.用于 Link/cut Tree 的剖分
Step 3-常见应用
1.路径上维护
用树链剖分求树上两点路径权值和,伪代码如下:
链上的 DFS 序是连续的,可以使用线段树、树状数组维护。
每次选择深度较大的链往上跳,直到两点在同一条链上。
同样的跳链结构适用于维护、统计路径上的其他信息。
2.子树维护
有时会要求,维护子树上的信息,譬如将以 \(x\) 为根的子树的所有结点的权值增加 \(v\) 。
在 DFS 搜索的时候,子树中的结点的 DFS 序是连续的。
每一个结点记录 bottom 表示所在子树连续区间末端的结点。
这样就把子树信息转化为连续的一段区间信息。
3.求最近公共祖先
不断向上跳重链,当跳到同一条重链上时,深度较小的结点即为 LCA。
向上跳重链时需要先跳所在重链顶端深度较大的那个。
参考代码:
int lca(int u, int v) {
while (top[u] != top[v]) {
if (dep[top[u]] > dep[top[v]])
u = fa[top[u]];
else
v = fa[top[v]];
}
return dep[u] > dep[v] ? v : u;
}
Step 4-例题
1.P2590「ZJOI2008」树的统计
My Code
//「ZJOI2008」树的统计
#include <iostream>
#include <cstdio>
#define INF 10000005
using namespace std;
const int N=1e5+10;
struct TREE{
int l,r,v,maxx;
}t[N*4];
int n,q,a[N];
int head[N*2],to[N*2],next[N*2],tot;
int fa[N],siz[N],dfn[N],rank[N],son[N],top[N],dep[N],cnt;
void add(int u,int v)
{
next[++tot]=head[u];
head[u]=tot;
to[tot]=v;
}
void dfs1(int u)
{
siz[u]=1;
for(int i=head[u];i;i=next[i])
{
int v=to[i];
if(v==fa[u]) continue;
dep[v]=dep[u]+1;
fa[v]=u;
dfs1(v);
siz[u]+=siz[v];
if(siz[v]>siz[son[u]]) son[u]=v;
}
}
void dfs2(int u,int tt)
{
top[u]=tt;
dfn[u]=++cnt;
rank[cnt]=u;
if(!son[u]) return ;
dfs2(son[u],tt);
for(int i=head[u];i;i=next[i])
{
int v=to[i];
if(v!=son[u]&&v!=fa[u])
dfs2(v,v);
}
}
void build(int k,int l,int r)
{
t[k].l=l,t[k].r=r;
if(l==r)
{
t[k].v=t[k].maxx=a[rank[l]];
return ;
}
int mid=(l+r)>>1;
build(k<<1,l,mid);
build(k<<1|1,mid+1,r);
t[k].v=t[k<<1].v+t[k<<1|1].v;
t[k].maxx=max(t[k<<1].maxx,t[k<<1|1].maxx);
}
void change(int k,int x,int w)
{
int l=t[k].l,r=t[k].r;
if(r<x||l>x) return ;
if(l==r&&l==x)
{
t[k].v=t[k].maxx=w;
return ;
}
int mid=(l+r)>>1;
if(x<=mid) change(k<<1,x,w);
else change(k<<1|1,x,w);
t[k].v=t[k<<1].v+t[k<<1|1].v;
t[k].maxx=max(t[k<<1].maxx,t[k<<1|1].maxx);
}
int qmax(int k,int x,int y)
{
int l=t[k].l,r=t[k].r;
if(l>=x&&r<=y) return t[k].maxx;
int mid=(l+r)>>1;
int maxx=-INF;
if(x<=mid) maxx=max(maxx,qmax(k<<1,x,y));
if(y>mid) maxx=max(maxx,qmax(k<<1|1,x,y));
return maxx;
}
int qsum(int k,int x,int y)
{
int l=t[k].l,r=t[k].r;
if(l>=x&&r<=y) return t[k].v;
int mid=(l+r)>>1;
int res=0;
if(x<=mid) res+=qsum(k<<1,x,y);
if(y>mid) res+=qsum(k<<1|1,x,y);
return res;
}
int QSUM(int x,int y)
{
int res=0;
while(top[x]!=top[y])
{
if(dep[top[x]]<dep[top[y]]) swap(x,y);
res+=qsum(1,dfn[top[x]],dfn[x]);
x=fa[top[x]];
}
if(dep[x]>dep[y]) swap(x,y);
return res+=qsum(1,dfn[x],dfn[y]);
}
int QMAX(int x,int y)
{
int res=-INF;
while(top[x]!=top[y])
{
if(dep[top[x]]<dep[top[y]]) swap(x,y);
res=max(res,qmax(1,dfn[top[x]],dfn[x]));
x=fa[top[x]];
}
if(dep[x]>dep[y]) swap(x,y);
return res=max(res,qmax(1,dfn[x],dfn[y]));
}
int main()
{
scanf("%d",&n);
int x,y;
for(int i=1;i<n;i++)
{
scanf("%d%d",&x,&y);
add(x,y),add(y,x);
}
for(int i=1;i<=n;i++) scanf("%d",&a[i]);
dfs1(1);
dfs2(1,1);
build(1,1,n);
scanf("%d",&q);
char k[8];
while(q--)
{
cin>>k;
scanf("%d%d",&x,&y);
if(k[0]=='C') change(1,dfn[x],y);
else if(k[1]=='M') printf("%d\n",QMAX(x,y));
else printf("%d\n",QSUM(x,y));
}
return 0;
}
2.P3384 【模板】轻重链剖分
My Code
//P3384 【模板】轻重链剖分
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
const int N=1e6+100;
struct TREE{
int v,l,r,add;
}t[N];
int n,m,p,root;
int cnt,tot,head[N],to[N],next[N];
int a[N];
int fa[N],dep[N],siz[N],son[N],top[N],dfn[N],rank[N];
inline int read()
{
char ch=getchar();int x=0,f=1;
while(ch<'0'||ch>'9')
{
if(ch=='-') f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9')
x=(x<<1)+(x<<3)+(ch^48),ch=getchar();
return x*f;
}
inline void add(int u,int v)
{
next[++tot]=head[u];
head[u]=tot;
to[tot]=v;
}
/*
我们先给出一些定义:
1.fa(x) 表示节点 x 在树上的父亲;
2.dep(x) 表示节点 x 在树上的深度;
3.siz(x) 表示节点 x 的子树的节点个数;
4.son(x) 表示节点 x 的重儿子 ;
5.top(x) 表示节点 x 所在重链的顶部节点(深度最小);
6.dfn(x) 表示节点 x 的 DFS 序 ,也是其在线段树中的编号;
7.rank(x) 表示 DFS 序所对应的节点编号,有 rank(dfn(x))=x;
*/
void dfs1(int u) //第一次 DFS 求出 fa(x), dep(x), siz(x), son(x);
{
siz[u]=1;
for(int i=head[u];i;i=next[i])
{
int v=to[i];
if(v==fa[u]) continue;
dep[v]=dep[u]+1;
fa[v]=u;
dfs1(v);
siz[u]+=siz[v];
if(siz[v]>siz[son[u]]) son[u]=v;
}
}
void dfs2(int u, int tt) //第二次 DFS 求出 top(x), dfn(x), rank(x);
{
top[u]=tt;
dfn[u]=++cnt;
rank[cnt]=u;
if(!son[u]) return;
dfs2(son[u],tt); //优先对重儿子进行 DFS,可以保证同一条重链上的点 DFS 序连续
for(int i=head[u];i;i=next[i])
{
int v=to[i];
if(v!=son[u]&&v!=fa[u])
dfs2(v,v);
}
}
/*
性质:
1.树上每个节点都属于且仅属于一条重链 。
2.重链开头的结点不一定是重子节点(因为重边是对于每一个结点都有定义
的)。
3.所有的重链将整棵树 完全剖分 。
4.在剖分时 优先遍历重儿子 ,最后重链的 DFS 序就会是连续的。
5.在剖分时 重边优先遍历 ,最后树的 DFN 序上,重链内的 DFN 序是连续
的。按 DFN 排序后的序列即为剖分后的链。
6.一颗子树内的 DFN 序是连续的。
7.可以发现,当我们向下经过一条 轻边 时,所在子树的大小至少会除以二。
8.因此,对于树上的任意一条路径,把它拆分成从 lca 分别向两边往下走,
分别最多走 O(log n)次,因此,树上的每条路径都可以被拆分成不超过
O(log n)条重链。
*/
void build(int k,int l,int r)
{
t[k].l=l,t[k].r=r,t[k].add=0,t[k].v=0;
if(l==r)
{
t[k].v=a[rank[l]];
return ;
}
int mid=(l+r)>>1;
build(k<<1,l,mid);
build(k<<1|1,mid+1,r);
t[k].v=(t[k<<1].v+t[k<<1|1].v)%p;
}
void pushdown(int k)
{
if(t[k].add)
{
t[k<<1].add+=t[k].add;
t[k<<1|1].add+=t[k].add;
int l=t[k<<1].l,r=t[k<<1].r;
t[k<<1].v+=(r-l+1)*t[k].add;
t[k<<1].v%=p;
l=t[k<<1|1].l,r=t[k<<1|1].r;
t[k<<1|1].v+=(r-l+1)*t[k].add;
t[k<<1|1].v%=p;
t[k].add=0;
}
}
void qadd(int k,int x,int y,int v)
{
int l=t[k].l,r=t[k].r;
if(l>=x&&r<=y)
{
t[k].add+=v;
t[k].v+=(r-l+1)*v;
return ;
}
pushdown(k);
int mid=(l+r)>>1;
if(x<=mid) qadd(k<<1,x,y,v);
if(y>mid) qadd(k<<1|1,x,y,v);
t[k].v=(t[k<<1].v+t[k<<1|1].v)%p;
}
int query(int k,int x,int y)
{
int l=t[k].l,r=t[k].r;
if(l>=x&&r<=y) return t[k].v;
int mid=(l+r)>>1;
pushdown(k);
int res=0;
if(x<=mid) res+=query(k<<1,x,y);
if(y>mid) res+=query(k<<1|1,x,y);
return res;
}
void qsol(int x,int y,int v)
{
while(top[x]!=top[y])
{
if(dep[top[x]]<dep[top[y]]) swap(x,y);
qadd(1,dfn[top[x]],dfn[x],v);
x=fa[top[x]];
}
if(dep[x]>dep[y]) swap(x,y);
qadd(1,dfn[x],dfn[y],v);
return ;
}
int query2(int x,int y)
{
int sum=0;
while(top[x]!=top[y])
{
if(dep[top[x]]<dep[top[y]]) swap(x,y);
sum+=query(1,dfn[top[x]],dfn[x]);
sum%=p;
x=fa[top[x]];
}
if(dep[x]>dep[y]) swap(x,y);
sum+=query(1,dfn[x],dfn[y]);
sum%=p;
return sum;
}
int main()
{
int u,v,x,y,w,k;
n=read(),m=read(),root=read(),p=read();
for(int i=1;i<=n;i++) a[i]=read();
for(int i=1;i<n;i++)
{
u=read(),v=read();
add(u,v),add(v,u);
}
dfs1(root);
dfs2(root,root);
build(1,1,n);
while(m--)
{
k=read();
if(k==1)
{
x=read(),y=read(),w=read();
qsol(x,y,w%p);
}
if(k==2)
{
x=read(),y=read();
cout<<query2(x,y)<<endl;
}
if(k==3)
{
x=read(),w=read();
qadd(1,dfn[x],dfn[x]+siz[x]-1,w);
}
if(k==4)
{
x=read();
cout<<query(1,dfn[x],dfn[x]+siz[x]-1)%p<<endl;
}
}
return 0;
}
Step 5-写在后面
参考资料
都看到这里了,不打算点个赞嘛

 浙公网安备 33010602011771号
浙公网安备 33010602011771号