字符编码
因为计算机内只识别二进制,但是用户使用计算的时候可以看到各式各样的语言文符,字符编码就是人类字符与数字对应关系的数据
![image]()
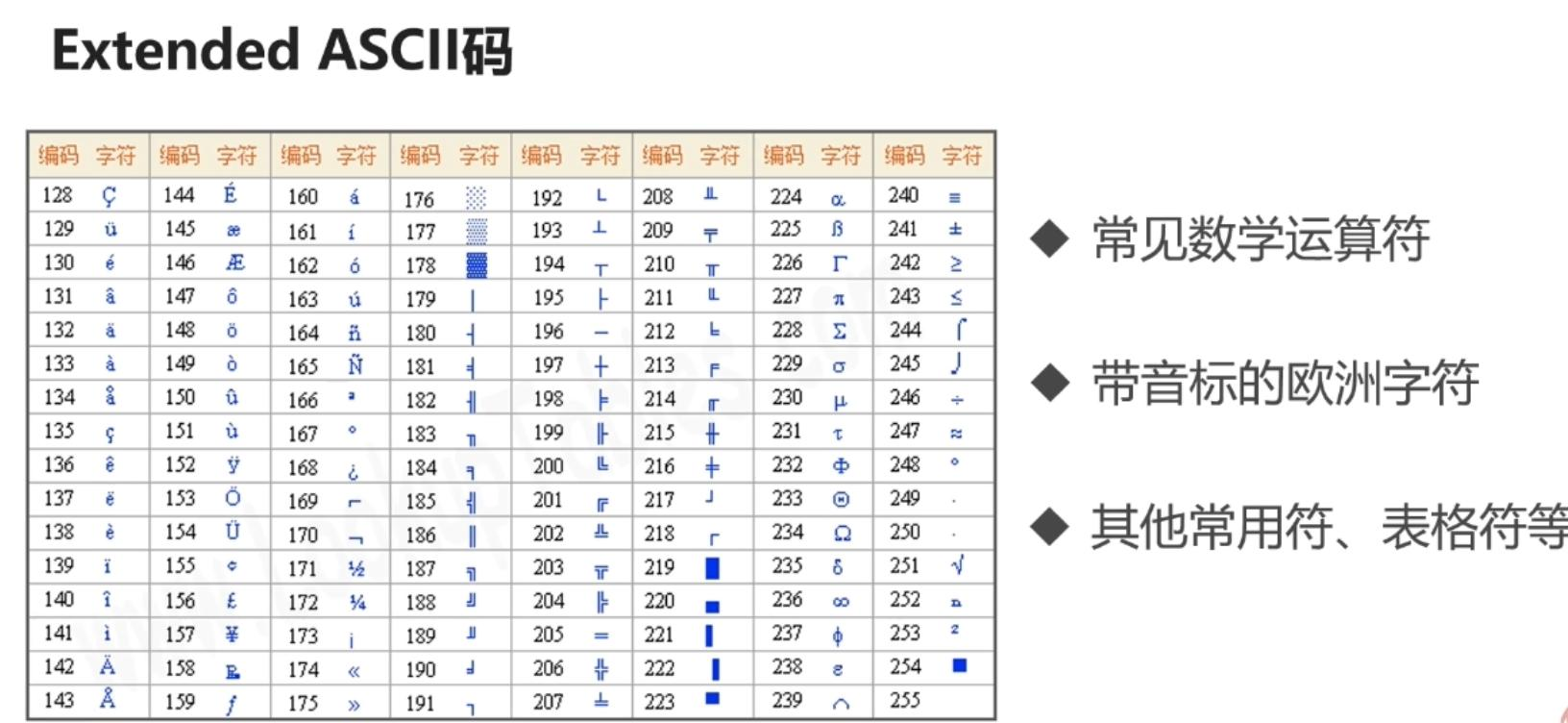
字符代码发展
由于计算机是由美国人发明的,所以刚开始只有一些字母、数字、符号被编进计算机内,用一个字节对应关系,被称为ASCII码。由于计算机的普及,各个国家开始研究自己的编码表。
例如中国的GB2312码,日本的shift_JIS码,韩国的Euc_kr码
中国GB2312编码表
![image]()
为了各个国家之间的文本数据可以无障碍交流需要编码统一,则出现了万国码
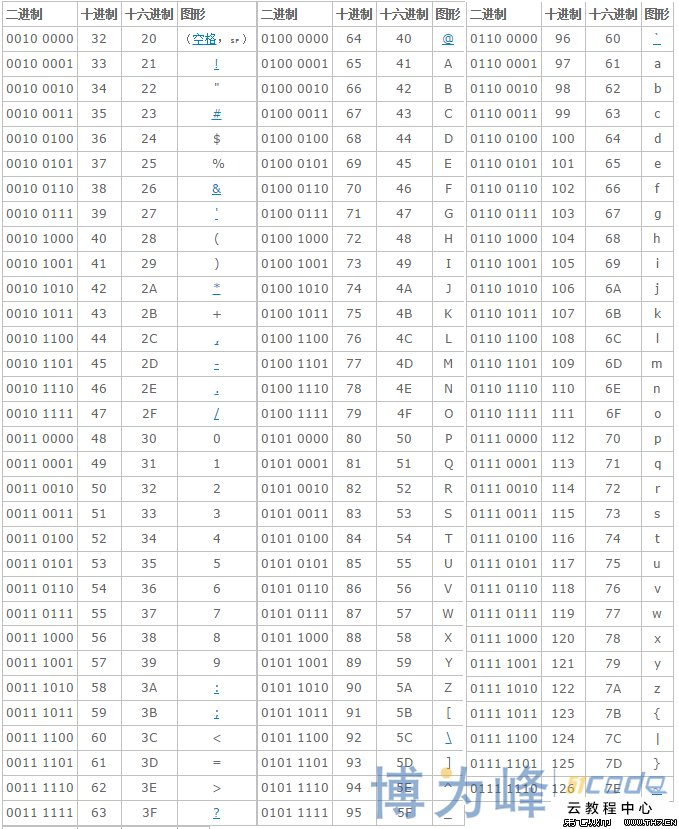
unicode(万国码)
统一使用两个及以上字符记录字符与数字的对应关系
![image]()
utf8(inicode的优化版)
英文一个字符储存,中文使用三个或以上储存
![image]()
文件乱码
文件用什么编码编的,就用什么编码解
![image]()
python解释器版本不同带来的编码差异
python2.x内部使用的编码默认是ASCII
可以使用文件头把ASCII转换成utf8
![image]()
可以自定义文件模板内容把文件头加到文件中
![image]()
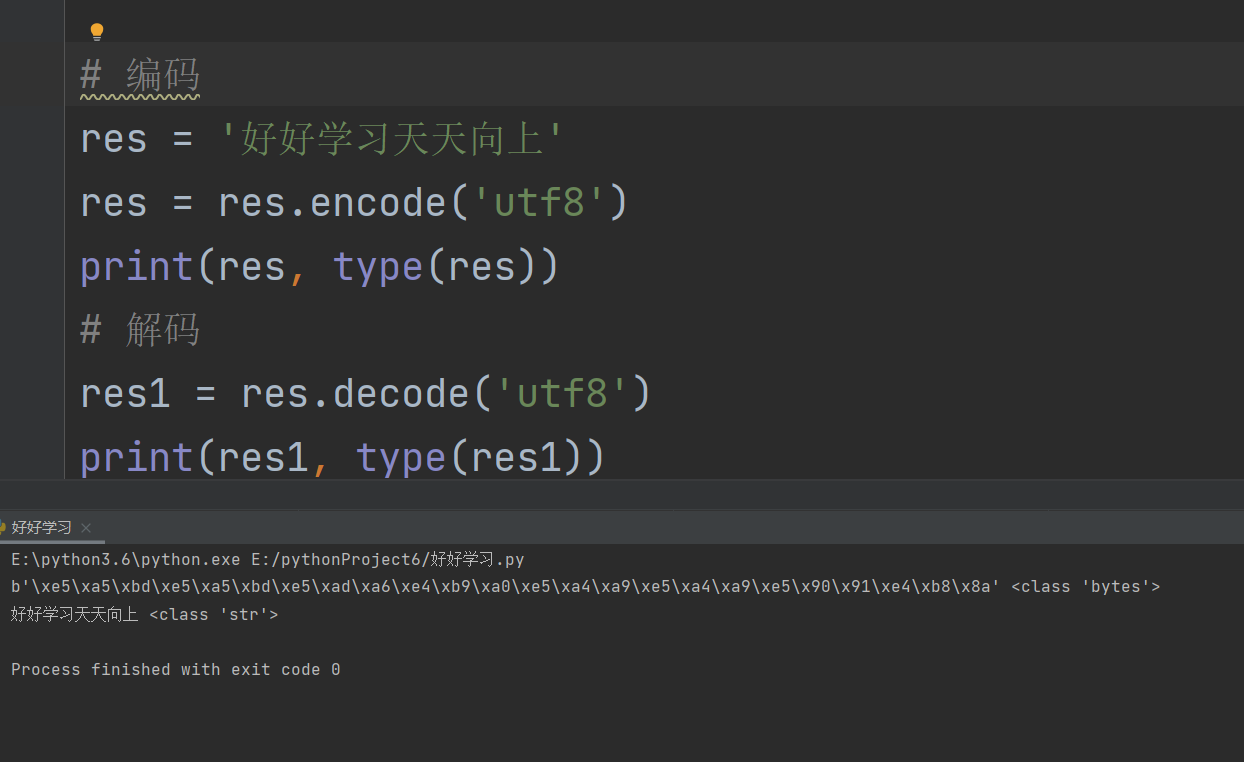
编码与解码
编码就是将人类看的懂的字符按照指定的编码转换成数字
解码就是将数字按照指定的编码转换成人类看得懂的字符
![image]()
文件操作
文件就是操作系统暴露给用户操作硬盘的快捷方式(接口)
代码操作文件 open
![image]()
open(文件路径,读写模式,字符编码)字符编码不是必须的(有些模式需要字符编码)
![image]()
with上下文管理(自动close)
![image]()
文件读写模式
r 只读模式(只能看,不能写)
文件路径不存在报错
![image]()
写内容就报错
![image]()
w 只写模式(只能写,不能看)
文件路径不存在就创建一个
![image]()
先清除内容,再写入
![image]()
a 只追加内容(只追加内容)
文件路径不存在就创建一个
![image]()
ps: r w a 都只能操纵文本文件
文件操作方法
读系列
![image]()
写系列
![image]()
文件优化操作
![image]()
文本操作模式
t 文本模式
1.默认的模式
r w a = rt wt at
2.该模式操作基本单位都是以字符串为基本单位(文本)
3.该模式必须指定encoding参数
4.该模式只能操作文本文件
![image]()
b 二进制模式
rb wb ab
1.该模式可以操作任意类型的文件
2.该模式所有操作都是以bytes类型(二进制)基本单位
二进制读写模式操作
![image]()
文件内光标的移动
![image]()
文件内内容修改
覆盖
一次性读完整个文件,文件过大占内存多
![image]()
新建
同一时间有两块地方存着相同的内容
![image]()
没啦
![image]()
posted @
2021-11-10 15:57
Zzy的Bk
阅读(
166)
评论()
收藏
举报























 浙公网安备 33010602011771号
浙公网安备 33010602011771号