【niubi-job——一个分布式的任务调度框架】----框架设计原理以及实现
引言
niubi-job的框架设计是非常简单实用的一套设计,去掉了很多其它调度框架中,锦上添花但并非必须的组件,例如MQ消息通讯组件(kafka等)。它的框架设计核心思想是,让每一个jar包可以相对之间独立的运行,并且由zk辅助进行集群中任务的调度。
接下来,咱们就一步一步的来看下niubi-job整个的框架设计与实现。
框架设计概述
讲解之前,让我们先来看一张niubi-job的框架设计图。如下。

可以看到,该图的结构非常简单,只有四个部分组成。
1、web控制台:负责发布任务,监控任务的状态信息,上传jar包到jar包仓库,将部分任务运行信息持久化到数据库。
2、zk集群:协调整个节点的运行,并且充当了帮web控制台和节点之间传递消息的角色。
3、cluster节点(node):负责任务的运行,日志的打印和搜集。
4、jar仓库:jar仓库默认是在web控制台的job目录下,cluster节点会先检查本地的job目录下有没有相应的jar包,没有的话会从jar仓库下载到本地。
整个框架的设计还是比较简单的,而且这里面也没有什么技术难点,准确的说,niubi-job是zk和quartz组装起来的一个更加方便使用的框架。
模块依赖关系
看完了上面的框架设计图,接下来咱们看一下niubi-job的各个模块之间的依赖关系,如下。
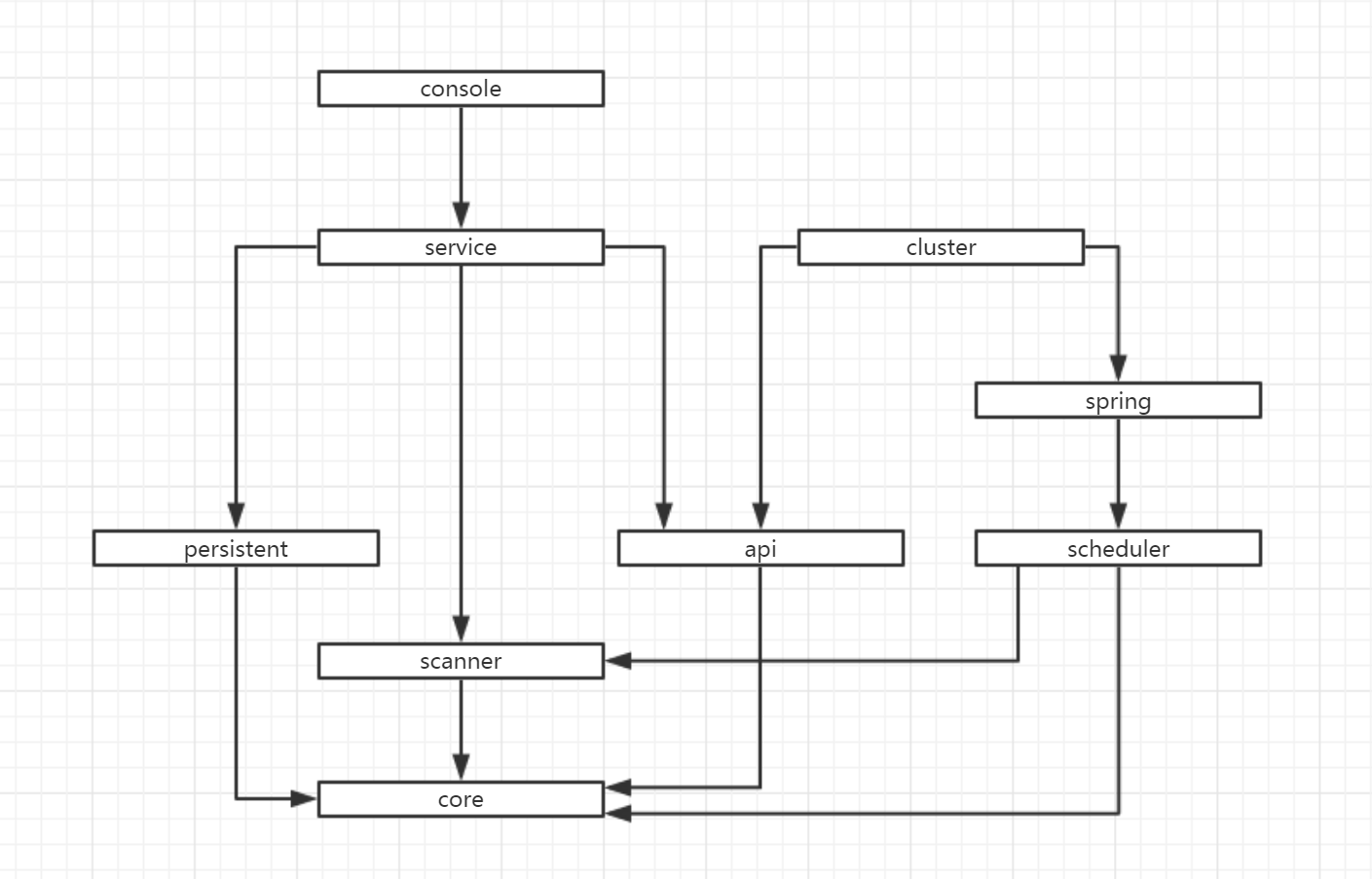
图还是比较简单的,可以看出,niubi-job整个依赖关系主要分成两条线,一条的顶端是console,另一条的顶端是cluster。下面LZ就分别介绍一下各个模块的作用。
core:主要包含一些工具类,异常类等。
scanner:非常核心的一个模块,包含了任务注解,jar包扫描,任务的抽象定义以及类加载器。
persistent:负责持久化的模块。
api:负责与zk交互的模块。
scheduler:封装了quartz。
spring:包含了任务在spring容器里运行所需要的类。
cluster:核心模块,是集群节点的启动程序,包含了集群调度策略。
service:console项目的service层,集成了持久化,zk监控以及jar包扫描任务入库。
console:后台web项目,提供简易的Web-UI给用户使用。用户可以在上面查看节点和任务等相关信息,也可以对任务进行启动、暂停、重启等操作。
Container与Node
以上的内容都是niubi-job框架的全貌俯瞰,接下来LZ带大家一起进到代码里看看细节。在这个过程中,大家可以体会到LZ设计框架时的一些想法。
看到本段的小标题,大家不难猜到,这一小段要讲的主要就是两个,一个是container,一个就是node。
container是LZ抽象出来用来容纳jar包运行环境的接口,而node接口则是代表一个独立运行的集群节点,二者的关系是一对多。也就是说,一个node里面可能会包含多个container,这样,一个节点就可以运行多个jar包中的任务。
我们来看看container接口和Node接口的源码。
package com.zuoxiaolong.niubi.job.scheduler.container; import com.zuoxiaolong.niubi.job.scheduler.SchedulerManager; /** * @author Xiaolong Zuo * @since 0.9.3 */ public interface Container { SchedulerManager schedulerManager(); }
package com.zuoxiaolong.niubi.job.scheduler.node; /** * @author Xiaolong Zuo * @since 0.9.3 */ public interface Node { void join(); void exit(); }
Container接口非常简单,每一个Container都会包含一个SchedulerManager接口,SchedulerManager接口其实就是quartz中Scheduler的升级版。每一个Container利用SchedulerManager就可以进行任务的调度。
当然,Container当中还有两个比较重要的角色,一个是JobScanner,一个是JobBeanFactory。这两个,其中JobScanner是用来扫描jar包的,而JobBeanFactory是用来实例化Job的,有了JobBeanFactory的机制,可以很容易与spring集成。
顶级的Node接口只有两个方法,join方法代表着加入集群和启动的含义,exit代表着退出集群或者关闭的含义。在Node的顶级接口中并没有体现出与container的关系,这是因为当模式为单机模式时,一个Node只有一个container,但是当为集群模式时(standby和master-slave模式),一个Node却对应了多个container。
在解释Node与Container的关系之前,咱们先来看一个类图。
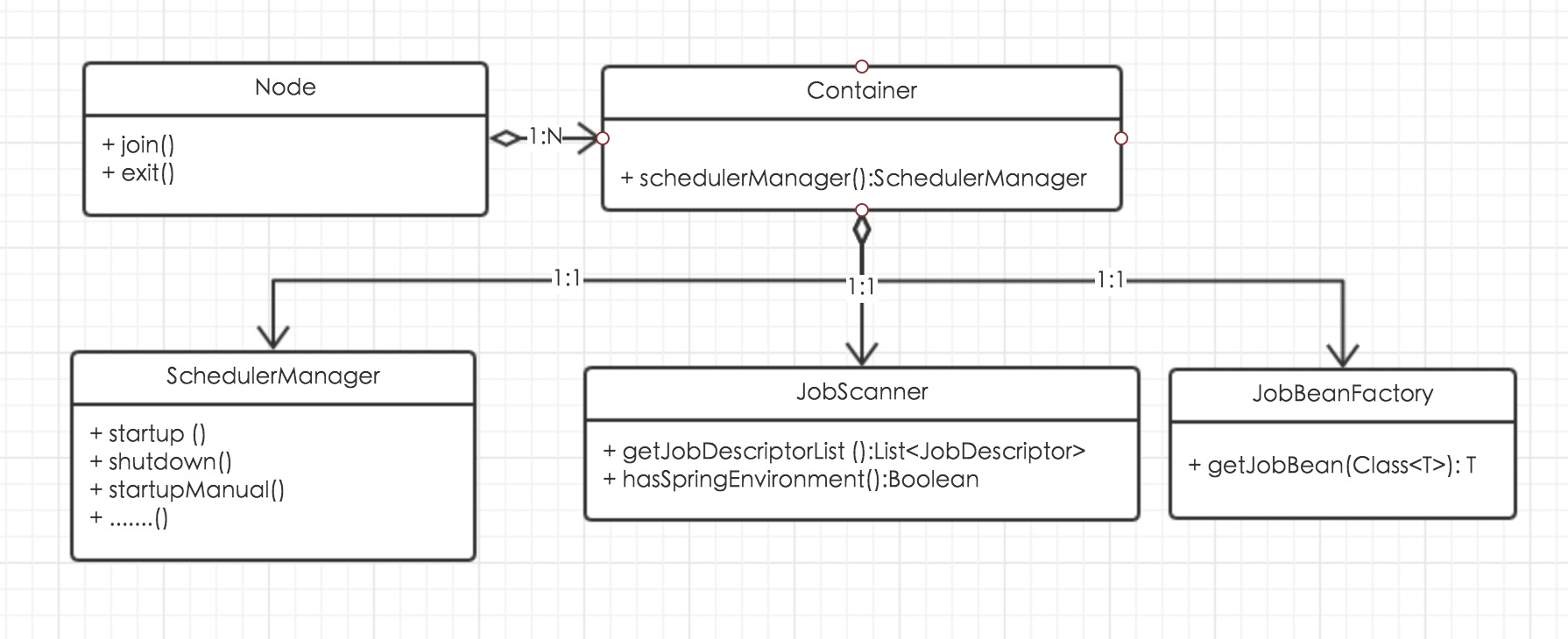
由于画图工具受限,LZ没有在类图中标注出Node接口的两个重要子接口,接下来咱们来看看这两个子接口的代码。
package com.zuoxiaolong.niubi.job.cluster.node; import com.zuoxiaolong.niubi.job.scheduler.container.Container; import com.zuoxiaolong.niubi.job.scheduler.node.Node; /** * @author Xiaolong Zuo * @since 0.9.3 */ public interface RemoteJobNode extends Node { Container getContainer(String jarFileName, String packagesToScan, boolean isSpring); }
package com.zuoxiaolong.niubi.job.scheduler.node; import com.zuoxiaolong.niubi.job.scheduler.container.Container; /** * @author Xiaolong Zuo * @since 0.9.3 */ public interface LocalJobNode extends Node { Container getContainer(); }
从这两个Node接口的方法定义可以看出,RemoteJobNode接口代表着Node与Container的关系为一对多,而LocalJobNode与Node则是一对一的关系。
这里LocalJobNode主要代表的就是单机模式的Node,在单机模式下,一个Node只对应一个运行环境,因此这种Node只有一个Container。
而RemoteJobNode则不同,它可以根据jarFileName取出不同的Container,这意味着RemoteJobNode的实现类应该包含一个Map<String,Container>,其中key是jar文件的名称,而value则是对应的Container。如此一来,不同的jar文件,将使用不同的Container。
我们来看下Node这个接口的继承树,如下图。
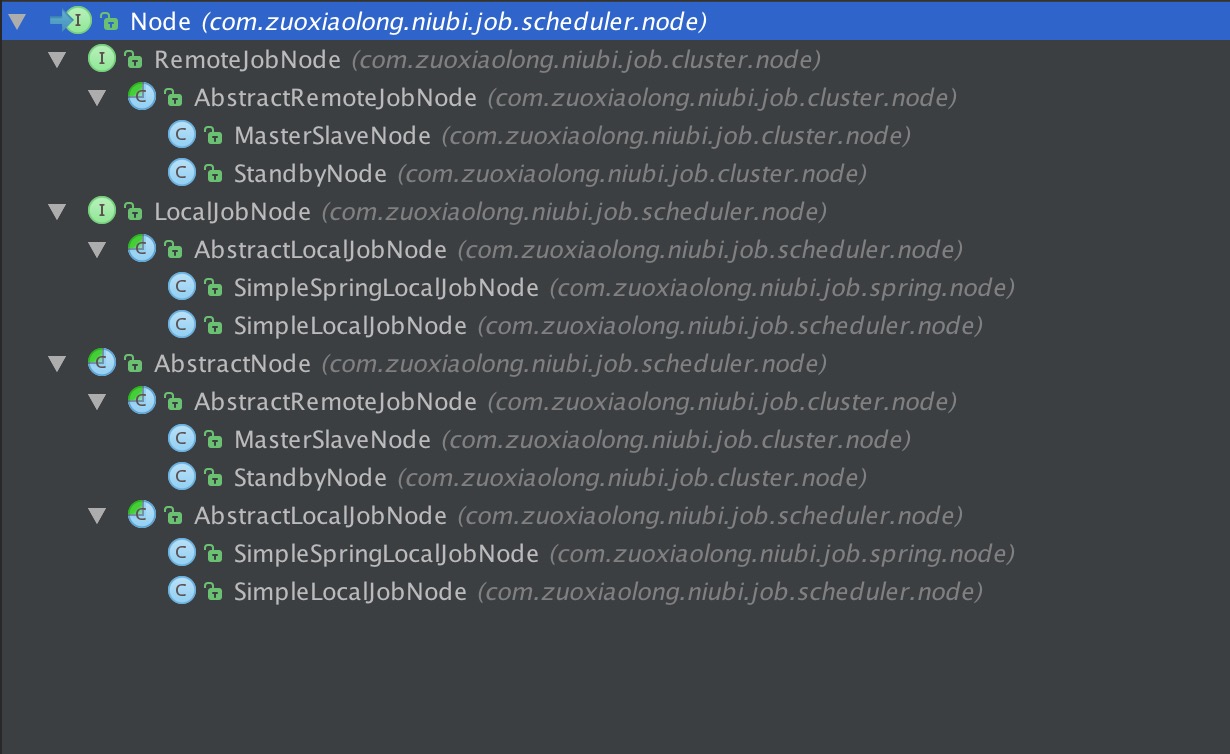
可以看到,Node的实现一共有四种。SimpleLocalJobNode是对应的单机版的非spring环境的实现,SimpleSpringJobNode是对应的单机版的spring环境的实现。
另外两种实现则都是集群模式的实现,其中StandbyNode代表的是主备模式,而MasterSlaveNode代表的是主从实现。StandbyNode和MasterSlaveNode这两个类的代码,是整个niubi-job集群实现的核心。
所以接下来,LZ就带大家来看看这两个类的代码,至于SimpleLocalJobNode和SimpleSpringJobNode,它们都是单机版的实现,实现相对简单,LZ这里就不详细介绍了,有兴趣的同学可以去看看这两个类的源码。
standby模式实现
standby模式(主备模式),顾名思义,在standby模式中,集群当中只有一个节点在运行任务。只有当这个节点挂掉的时候,其余节点才会接替它去运行需要启动的任务。
要保证这一点,借助zk可以很容易的做到,只需要让Master节点来运行任务,其它Backup节点都待命就可以了。接下来LZ就带大家来看下niubi-job的源码,看它是如何借助zk达到standby的效果的。
抛开其它代码,我们主要来看StandbyNode的代码中的两个listener,这两个listener是集群调度的核心。首先来看第一个listener。
1 private class StandbyLeadershipSelectorListener extends AbstractLeadershipSelectorListener { 2 3 @Override 4 public void acquireLeadership() throws Exception { 5 StandbyNodeData.Data nodeData = new StandbyNodeData.Data(getIp()); 6 int runningJobCount = startupJobs(); 7 nodeData.setRunningJobCount(runningJobCount); 8 nodeData.setState("Master"); 9 standbyApiFactory.nodeApi().updateNode(nodePath, nodeData); 10 LoggerHelper.info(getIp() + " has been updated. [" + nodeData + "]"); 11 jobCache.start(); 12 } 13 14 private Integer startupJobs() { 15 List<StandbyJobData> standbyJobDataList = standbyApiFactory.jobApi().getAllJobs(); 16 int runningJobCount = 0; 17 if (ListHelper.isEmpty(standbyJobDataList)) { 18 return runningJobCount; 19 } 20 for (StandbyJobData standbyJobData : standbyJobDataList) { 21 try { 22 StandbyJobData.Data data = standbyJobData.getData(); 23 if ("Startup".equals(data.getState())) { 24 Container container = getContainer(standbyJobData.getData().getJarFileName(), standbyJobData.getData().getPackagesToScan(), standbyJobData.getData().isSpring()); 25 container.schedulerManager().startupManual(data.getGroupName(), data.getJobName(), data.getCron(), data.getMisfirePolicy()); 26 runningJobCount++; 27 } 28 } catch (Exception e) { 29 LoggerHelper.error("start jar failed [" + standbyJobData.getPath() + "]", e); 30 } 31 } 32 return runningJobCount; 33 } 34 35 @Override 36 public void relinquishLeadership() { 37 try { 38 if (jobCache != null) { 39 jobCache.close(); 40 } 41 LoggerHelper.info("job cache has been closed."); 42 } catch (Throwable e) { 43 LoggerHelper.warn("job cache close failed.", e); 44 } 45 LoggerHelper.info("begin stop scheduler manager."); 46 shutdownAllScheduler(); 47 if (client.getState() == CuratorFrameworkState.STARTED) { 48 StandbyNodeData.Data data = new StandbyNodeData.Data(getIp()); 49 standbyApiFactory.nodeApi().updateNode(nodePath, data); 50 LoggerHelper.info(getIp() + " has been shutdown. [" + data + "]"); 51 } 52 LoggerHelper.info("clear node successfully."); 53 } 54 55 }
这个listener是当节点取得Master权限时需要做的事情。我们可以看到,acquireLeadership这个方法中,主要调用了startupJobs这个方法,然后更新了自己的节点信息。而startupJobs这个方法,它做的事情就是检查zk节点中现在正在运行的任务,如果发现的话,就把这些任务启动。
这就意味着,当其它节点挂掉的时候,任何一个节点得到Master的权限,都会检查当前正在运行的任务,并且把它们在自己的节点上启动,这就是standby模式的备份策略。而relinquishLeadership这个方法则是在节点失去Master权限时要做的事情,而我们做的,就是把它当下所有的任务都关闭。
接下来,我们再来看另外一个listener。代码如下。
1 private class JobCacheListener implements PathChildrenCacheListener { 2 3 @Override 4 public synchronized void childEvent(CuratorFramework curatorFramework, PathChildrenCacheEvent event) throws Exception { 5 AssertHelper.isTrue(isJoined(), "illegal state ."); 6 boolean hasLeadership = leaderSelector != null && leaderSelector.hasLeadership(); 7 if (!hasLeadership) { 8 return; 9 } 10 if (!EventHelper.isChildModifyEvent(event)) { 11 return; 12 } 13 StandbyJobData standbyJobData = new StandbyJobData(event.getData()); 14 if (StringHelper.isEmpty(standbyJobData.getData().getOperation())) { 15 return; 16 } 17 StandbyJobData.Data data = standbyJobData.getData(); 18 if (data.isUnknownOperation()) { 19 return; 20 } 21 StandbyNodeData.Data nodeData = standbyApiFactory.nodeApi().getNode(nodePath).getData(); 22 executeOperation(nodeData, data); 23 } 24 25 private void executeOperation(StandbyNodeData.Data nodeData, StandbyJobData.Data data) { 26 try { 27 if (data.isStart() || data.isRestart()) { 28 Container container = getContainer(data.getJarFileName(), data.getPackagesToScan(), data.isSpring()); 29 container.schedulerManager().startupManual(data.getGroupName(), data.getJobName(), data.getCron(), data.getMisfirePolicy()); 30 if (data.isStart()) { 31 nodeData.increment(); 32 } 33 data.setState("Startup"); 34 } else { 35 Container container = getContainer(data.getOriginalJarFileName(), data.getPackagesToScan(), data.isSpring()); 36 container.schedulerManager().shutdown(data.getGroupName(), data.getJobName()); 37 nodeData.decrement(); 38 data.setState("Pause"); 39 } 40 data.operateSuccess(); 41 standbyApiFactory.jobApi().updateJob(data.getGroupName(), data.getJobName(), data); 42 standbyApiFactory.nodeApi().updateNode(nodePath, nodeData); 43 } catch (Throwable e) { 44 LoggerHelper.error("handle operation failed. " + data, e); 45 data.operateFailed(ExceptionHelper.getStackTrace(e, true)); 46 standbyApiFactory.jobApi().updateJob(data.getGroupName(), data.getJobName(), data); 47 } 48 } 49 50 }
首先,这个listener是当Job的zk节点数据有更新时,才会触发。而zk节点数据有更新,一般都是控制台发来的启动、暂停或者重启的命令。这个时候,我们就需要进行一系列的检查,比如该节点是否是Master,事件是否是控制台发来的等等。
如果满足条件,就会执行executeOperation方法,这个时候会根据控制台发过来的动作进行任务的调度。由于我们这个listener只有Master节点才启动(在StandbyLeadershipSelectorListener的11行启动),因此这就意味着,只有Master节点才会响应控制台的任务调度。
如此一来,我们就能保证只有Master节点才会运行任务,并且集群的节点之间可以容灾。当Master挂掉时,其它节点会获取到Master权限,这个时候,获得Master权限的节点就会接替任务运行的责任。
好了,standby节点的实现就是这么简单,大家明白了吗?
这就是站在巨人的肩膀上,我们只用这么简单的代码就实现了一个简单的主备任务调度集群,是不是很酷呢?
master-slave模式实现
master-slave模式(主从模式)与standby模式(主备模式)有着本质上的不同,但它们相同的是,这两种任何一个模式下,一个Job都有且只有一个节点运行它。而不同的是,集群的调度策略会有不同。
standby模式只有一个节点运行任务,只有当Master节点挂掉的时候,其它节点才代替Master节点继续运行任务。
而在master-slave模式下,所有Job将会被均衡的分配到各个节点,如果集群中的一个节点挂掉,那么在这个节点上运行的任务将会再次均衡的分配给剩下的活着的节点。当有节点加入到集群时,master-slave集群并不会主动暂停正在运行的任务进行任务的重新分布,需要用户在控制台手动的暂停某任务,然后再启动它,这时候这个任务将会被自动路由到新增加的节点上。因为新增加的节点任务数是0,它将会被优先分配。
好了,master-slave模式的集群调度策略介绍的差不多了,接下来我们就来看看它的代码吧。它比standby模式下多了一个listener,并且在master-slave模式下,Master与Slave节点的责任也与standby模式有所不同。
我们先来看第一个listener。代码如下。
1 private class MasterSlaveLeadershipSelectorListener extends AbstractLeadershipSelectorListener { 2 3 @Override 4 public void acquireLeadership() throws Exception { 5 checkUnavailableNode(); 6 MasterSlaveNodeData masterSlaveNodeData = masterSlaveApiFactory.nodeApi().getNode(nodePath); 7 masterSlaveNodeData.getData().setState("Master"); 8 masterSlaveApiFactory.nodeApi().updateNode(nodePath, masterSlaveNodeData.getData()); 9 LoggerHelper.info(getIp() + " has been updated. [" + masterSlaveNodeData.getData() + "]"); 10 nodeCache.start(); 11 } 12 13 /** 14 * Check unavailable nodes , release jobs that is assigned on these nodes. 15 */ 16 private void checkUnavailableNode() { 17 List<MasterSlaveNodeData> masterSlaveNodeDataList = masterSlaveApiFactory.nodeApi().getAllNodes(); 18 List<String> availableNodes = new ArrayList<>(); 19 if (!ListHelper.isEmpty(masterSlaveNodeDataList)) { 20 availableNodes.addAll(masterSlaveNodeDataList.stream().map(MasterSlaveNodeData::getPath).collect(Collectors.toList())); 21 } 22 List<MasterSlaveJobData> masterSlaveJobDataList = masterSlaveApiFactory.jobApi().getAllJobs(); 23 if (!ListHelper.isEmpty(masterSlaveJobDataList)) { 24 for (MasterSlaveJobData masterSlaveJobData : masterSlaveJobDataList) { 25 MasterSlaveJobData.Data data = masterSlaveJobData.getData(); 26 if (!availableNodes.contains(data.getNodePath())) { 27 data.release(); 28 masterSlaveApiFactory.jobApi().updateJob(data.getGroupName(), data.getJobName(), data); 29 } 30 } 31 } 32 } 33 34 @Override 35 public void relinquishLeadership() { 36 try { 37 if (nodeCache != null) { 38 nodeCache.close(); 39 } 40 LoggerHelper.info("node cache has been closed."); 41 } catch (Throwable e) { 42 LoggerHelper.warn("node cache close failed.", e); 43 } 44 if (client.getState() == CuratorFrameworkState.STARTED) { 45 MasterSlaveNodeData.Data nodeData = new MasterSlaveNodeData.Data(getIp()); 46 releaseJobs(nodePath, nodeData); 47 nodeData.setState("Slave"); 48 masterSlaveApiFactory.nodeApi().updateNode(nodePath, nodeData); 49 } 50 LoggerHelper.info("clear node successfully."); 51 } 52 53 }
与standby模式相同,这个listener也是节点在获取到Master权限时要做的事情。我们可以看到,当取到Master权限时,节点不会做任何任务的调度,只是简单的更新了一下自己节点的信息,并且启动了一下nodeCache(代码第10行)。
那么nodeCache是做什么的呢?
接下来,我们来看第二个listener就知道了,代码如下。
1 private class NodeCacheListener implements PathChildrenCacheListener { 2 3 @Override 4 public synchronized void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception { 5 AssertHelper.isTrue(isJoined(), "illegal state ."); 6 //double check 7 if (!leaderSelector.hasLeadership()) { 8 return; 9 } 10 if (EventHelper.isChildRemoveEvent(event)) { 11 MasterSlaveNodeData masterSlaveNodeData = new MasterSlaveNodeData(event.getData().getPath(), event.getData().getData()); 12 releaseJobs(masterSlaveNodeData.getPath(), masterSlaveNodeData.getData()); 13 } 14 } 15 16 }
这个listener是在节点有变化时被触发,而且只有Master权限的节点才会去触发。可以看到,我们先是判断了当前节点是不是Master权限,然后判断了当前事件是不是有节点离开了集群,如果是的话,就把这个挂掉的节点下面的所有任务都释放掉,也就是releaseJobs方法所做的事情。
这就意味着,作为Master节点,它必须感知集群当中是否有节点挂掉,如果有的话,就必须把它下面的Job都释放掉,以便于其它节点继续执行这些任务,这就是master-slave模式下容灾的一种体现。
接下来,我们来看重头戏,也就是最后一个listener。它做的事情相对来说就要复杂的多了。代码如下。
1 private class JobCacheListener implements PathChildrenCacheListener { 2 3 @Override 4 public synchronized void childEvent(CuratorFramework clientInner, PathChildrenCacheEvent event) throws Exception { 5 AssertHelper.isTrue(isJoined(), "illegal state ."); 6 if (!EventHelper.isChildModifyEvent(event)) { 7 return; 8 } 9 MasterSlaveJobData jobData = new MasterSlaveJobData(event.getData()); 10 if (StringHelper.isEmpty(jobData.getData().getOperation())) { 11 return; 12 } 13 MasterSlaveJobData.Data data = jobData.getData(); 14 if (data.isUnknownOperation()) { 15 return; 16 } 17 boolean hasLeadership = leaderSelector != null && leaderSelector.hasLeadership(); 18 if (hasLeadership && StringHelper.isEmpty(data.getNodePath())) { 19 //if has operation, wait a moment. 20 if (checkNotExecuteOperation()) { 21 try { 22 Thread.sleep(3000); 23 } catch (Throwable e) { 24 //ignored 25 } 26 masterSlaveApiFactory.jobApi().updateJob(data.getGroupName(), data.getJobName(), data); 27 return; 28 } 29 List<MasterSlaveNodeData> masterSlaveNodeDataList = masterSlaveApiFactory.nodeApi().getAllNodes(); 30 if (ListHelper.isEmpty(masterSlaveNodeDataList)) { 31 data.operateFailed("there is not any one node live."); 32 masterSlaveApiFactory.jobApi().updateJob(data.getGroupName(), data.getJobName(), data); 33 return; 34 } 35 Collections.sort(masterSlaveNodeDataList); 36 data.setNodePath(masterSlaveNodeDataList.get(0).getPath()); 37 masterSlaveApiFactory.jobApi().updateJob(data.getGroupName(), data.getJobName(), data); 38 return; 39 } 40 if (hasLeadership) { 41 //check whether the node is available or not. 42 List<MasterSlaveNodeData> masterSlaveNodeDataList = masterSlaveApiFactory.nodeApi().getAllNodes(); 43 boolean nodeIsLive = false; 44 for (MasterSlaveNodeData masterSlaveNodeData : masterSlaveNodeDataList) { 45 if (masterSlaveNodeData.getPath().equals(data.getNodePath())) { 46 nodeIsLive = true; 47 break; 48 } 49 } 50 if (!nodeIsLive) { 51 data.clearNodePath(); 52 masterSlaveApiFactory.jobApi().updateJob(data.getGroupName(), data.getJobName(), data); 53 } 54 } 55 //if the job has been assigned to this node, then execute. 56 if (EventHelper.isChildUpdateEvent(event) && nodePath.equals(data.getNodePath())) { 57 MasterSlaveNodeData.Data nodeData; 58 try { 59 nodeData = masterSlaveApiFactory.nodeApi().getNode(nodePath).getData(); 60 } catch (Throwable e) { 61 LoggerHelper.error("node [" + nodePath + "] not exists."); 62 data.clearNodePath(); 63 masterSlaveApiFactory.jobApi().updateJob(data.getGroupName(), data.getJobName(), data); 64 return; 65 } 66 executeOperation(nodeData, jobData); 67 return; 68 } 69 } 70 71 private boolean checkNotExecuteOperation() { 72 List<MasterSlaveJobData> masterSlaveJobDataList = masterSlaveApiFactory.jobApi().getAllJobs(); 73 if (ListHelper.isEmpty(masterSlaveJobDataList)) { 74 return false; 75 } 76 for (MasterSlaveJobData masterSlaveJobData : masterSlaveJobDataList) { 77 boolean hasOperation = !StringHelper.isEmpty(masterSlaveJobData.getData().getOperation()); 78 boolean assigned = !StringHelper.isEmpty(masterSlaveJobData.getData().getNodePath()); 79 if (hasOperation && assigned) { 80 return true; 81 } 82 } 83 return false; 84 } 85 86 private void executeOperation(MasterSlaveNodeData.Data nodeData, MasterSlaveJobData jobData) { 87 MasterSlaveJobData.Data data = jobData.getData(); 88 try { 89 if (data.isStart() || data.isRestart()) { 90 Container container = getContainer(data.getJarFileName(), data.getPackagesToScan(), data.isSpring()); 91 container.schedulerManager().startupManual(data.getGroupName(), data.getJobName(), data.getCron(), data.getMisfirePolicy()); 92 if (data.isStart()) { 93 nodeData.addJobPath(jobData.getPath()); 94 } 95 data.setState("Startup"); 96 } else { 97 Container container = getContainer(data.getOriginalJarFileName(), data.getPackagesToScan(), data.isSpring()); 98 container.schedulerManager().shutdown(data.getGroupName(), data.getJobName()); 99 nodeData.removeJobPath(jobData.getPath()); 100 data.clearNodePath(); 101 data.setState("Pause"); 102 } 103 data.operateSuccess(); 104 masterSlaveApiFactory.jobApi().updateJob(data.getGroupName(), data.getJobName(), data); 105 masterSlaveApiFactory.nodeApi().updateNode(nodePath, nodeData); 106 } catch (Throwable e) { 107 LoggerHelper.error("handle operation failed. " + data, e); 108 data.operateFailed(ExceptionHelper.getStackTrace(e, true)); 109 masterSlaveApiFactory.jobApi().updateJob(data.getGroupName(), data.getJobName(), data); 110 } 111 } 112 113 }
这个listener是当任务节点信息有变化时,才会被触发。在代码的18行,我们判断了该任务是否被分配了节点,如果没被分配的话,并且当前节点是Master权限的话,就会进入If块。这个时候我们会采用轮询的方式给任务选择节点,具体的做法就是先将节点按照当前任务数排序,我们选择当前任务数最少的那个节点分配任务。
当任务被分配完节点时,我们需要把事件重新激活,然后让被分配了的节点去启动、暂停或者重启该任务。因此在第37行,我们直接将任务打回,继续发送一个Job更新的事件。
接下来,我们来到了40行,在这一行,LZ写了一个简单的注释(由于LZ英文水平有限,因此注释目前还不多,但是这个地方非常重要,所以就加了行注释),注释翻译过来意思就是说要检查一下当前被分配的节点是否可用。
一种可能的情况是,在Master节点给任务分配完节点后,被分配的节点挂掉了。这个时候如果不检查节点是否有效,当前任务的操作就会被忽略掉,因此我们让拥有Master权限的节点检查一下,如果发现节点已经挂掉,则把任务上分配的节点信息清除掉(代码51行),然后重新激活(代码52行)。
接下来就来到了56行,这一行判断的逻辑就比较简单了,判断一下如果任务有更新,并且被分配的节点就是自己的话,就把该任务进行相应的操作,比如启动、暂停或者重启。
好了,master-slave模式的实现到这里也就讲解的差不多了,还是那句话,站在巨人的肩膀上,事情将会变的非常简单。
这个类整个代码不超400行,我们就实现了一个可以自动容灾,负载均衡的任务调度集群,是不是很暴力呢?
niubi-job的类加载机制
好了,我们已经介绍完了集群策略的实现,那么重点来了,我们如何保证每个任务的jar包运行的时候互相不影响呢?
这就依靠于niubi-job内部的类加载机制,它基本上是套用的tomcat的类加载机制,这又是站在了巨人的肩膀上,0-0。
好吧,接下来,LZ就大言不惭的介绍一下niubi-job的类加载机制(其实基本上就是tomcat的,0-0)。首先,我们先来看一个图。如下。

如果看到过tomcat类加载机制的图的朋友,可能会觉得这个图似曾相识。你没有看错,这个图和tomcat的那个图是非常相似的,也就是换了下名字罢了。
在niubi-job的节点中,任何一个类的加载都会遵循以下的原则(具体的代码这里就不贴了,大家可以去看ApplicationClassLoader这个类的代码)。
1、从bootstrap类加载器加载,如果没有,进行下一步查找。
2、从ext类加载器加载,如果没有,进行下一步查找。
3、从job的jar文件中加载,如果没有,进行下一步查找。
4、从app类加载器加载,如果没有,进行下一步查找。
5、从node类加载器加载,如果没有,则抛出ClassNotFoundException。
大家可以发现,niubi-job的类加载查找顺序是违背了父委托机制,这样做的原因是为了保证jar包之间的绝对隔离,也就是说,除了ext和bootstrap当中的类,所有的类都优先加载jar包中的,这样可以保证jar包之间类的绝对隔离。但这样做的坏处就是,如果jar包中包含了cluster本身包含的类,那么就会产生类转换的异常。
因此大家切记,在打任务的jar包时,cluster的lib目录下的所有jar包都不能包含,如果非要使用自己的jar包,可以在部署cluster节点时,把lib包中的jar包替换成自己的(比如把log4j的jar包替换成自己想要使用的),但是不能直接把与lib目录下重复的jar包打到任务jar包当中。
结语
本文介绍了niubi-job中非常重要的集群策略实现和类加载机制,这基本上包含了niubi-job的代码中80%以上的精华,剩下的那20%,大家如果有时间的话,可以自己去研究,LZ非常欢迎。
最后,欢迎大家给niubi-job提交Issue和PR,LZ一定格尽职守的进行解答和Review。
下一篇文章,LZ将会介绍一下0.9.3版中,niubi-job中web控制台的更新内容,比0.9.2版更加炫酷,功能也更加齐全。
下次见!各位!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号