Ambari安装之部署3个节点的HA分布式集群
前期博客
Ambari安装之部署单节点集群
其实,按照这个步骤是一样的。只是按照好3个节点后,再做下HA即可。
部署3个节点的HA分布式集群
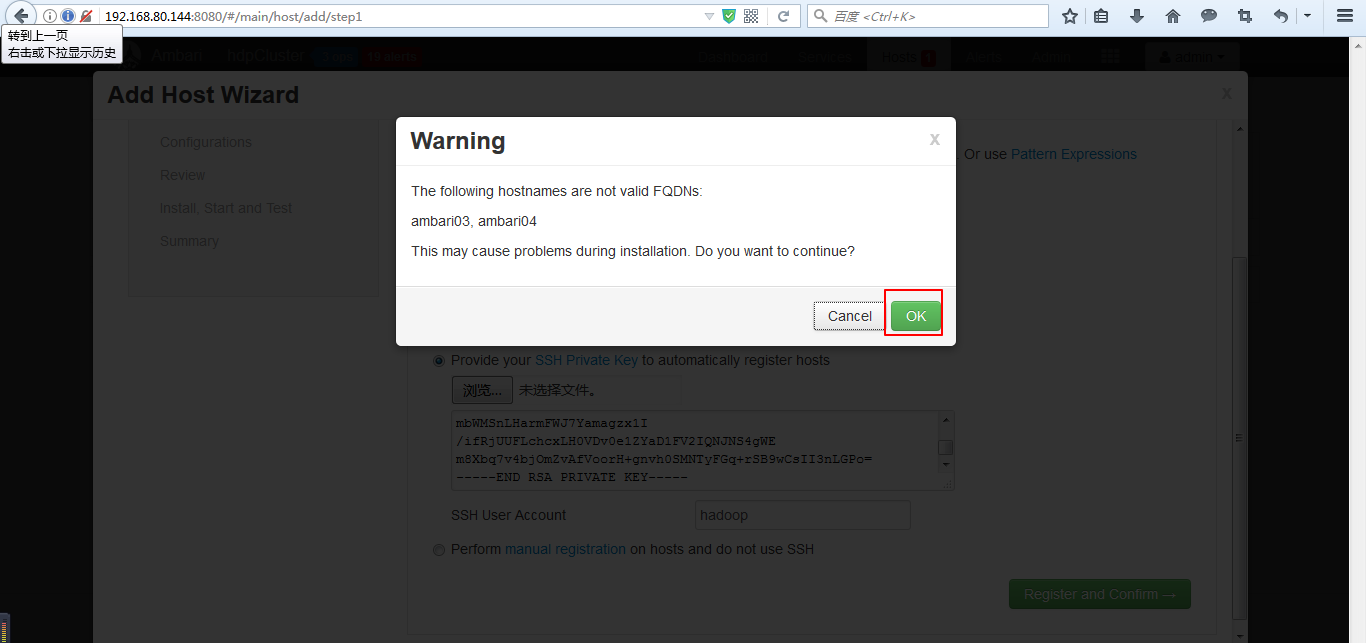
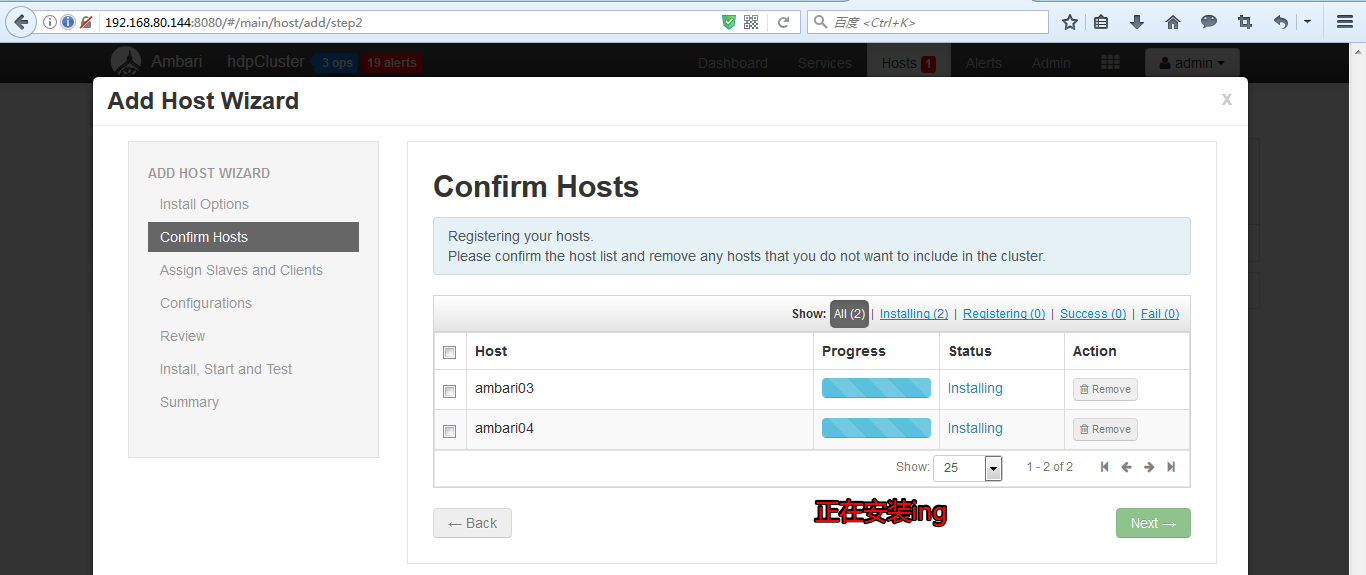
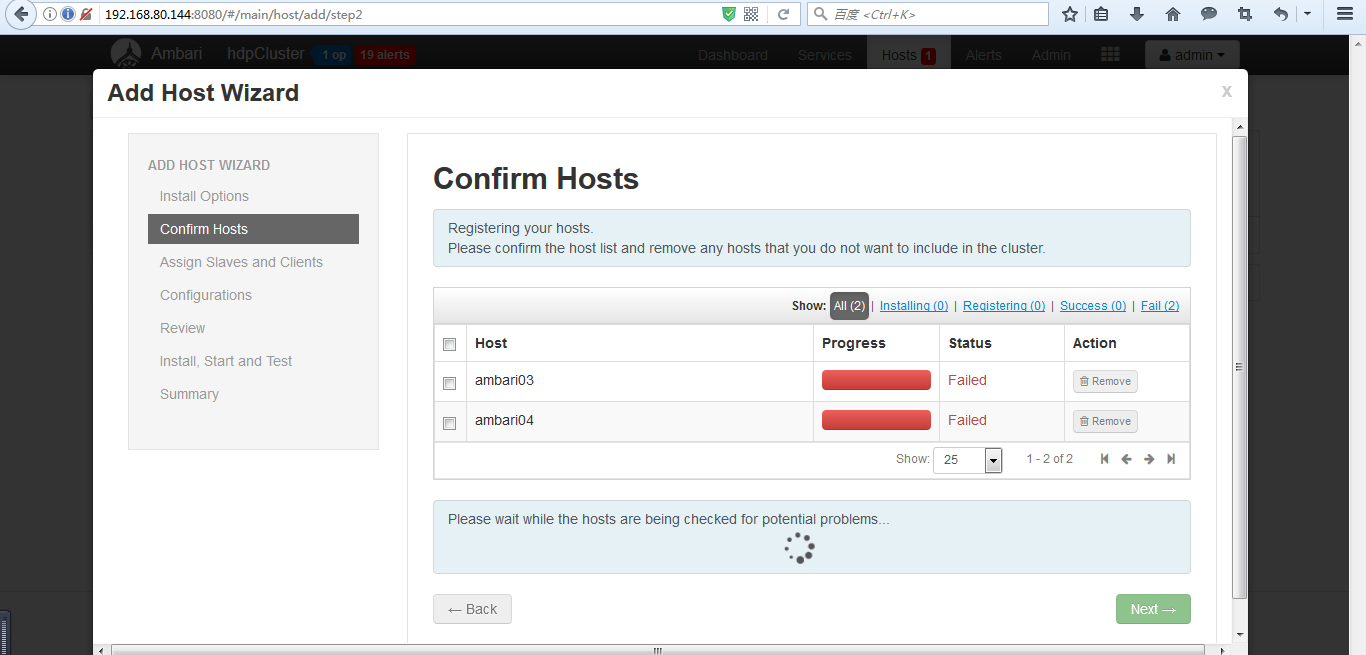
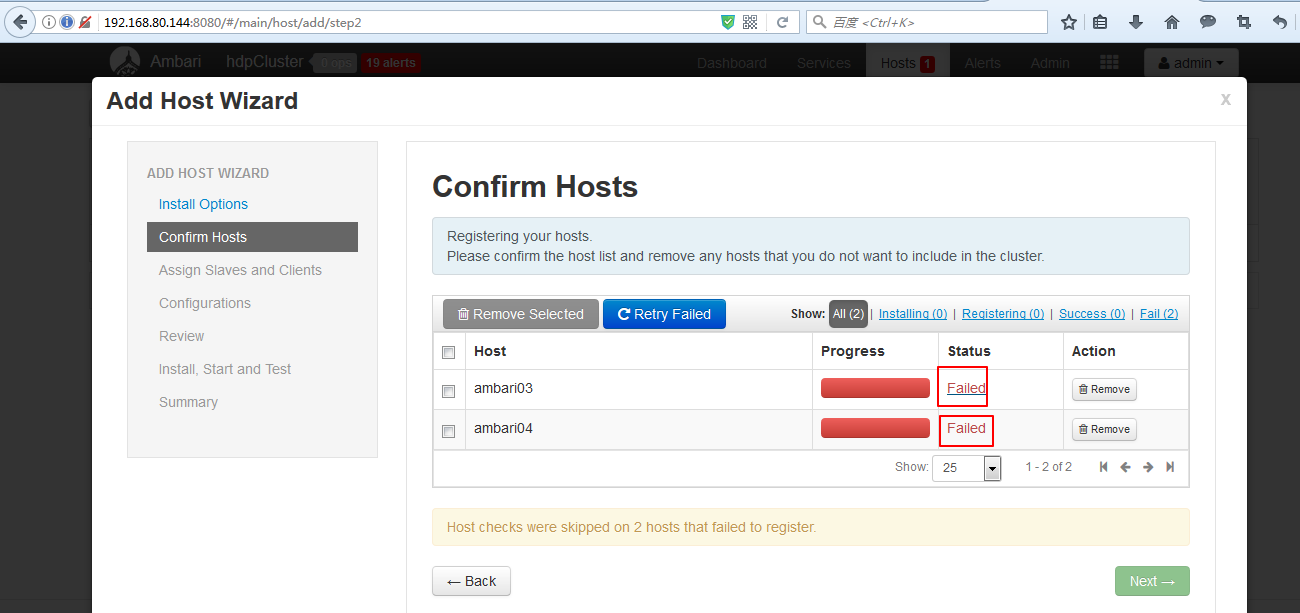
(1)添加机器
和添加服务的操作类似,如下图
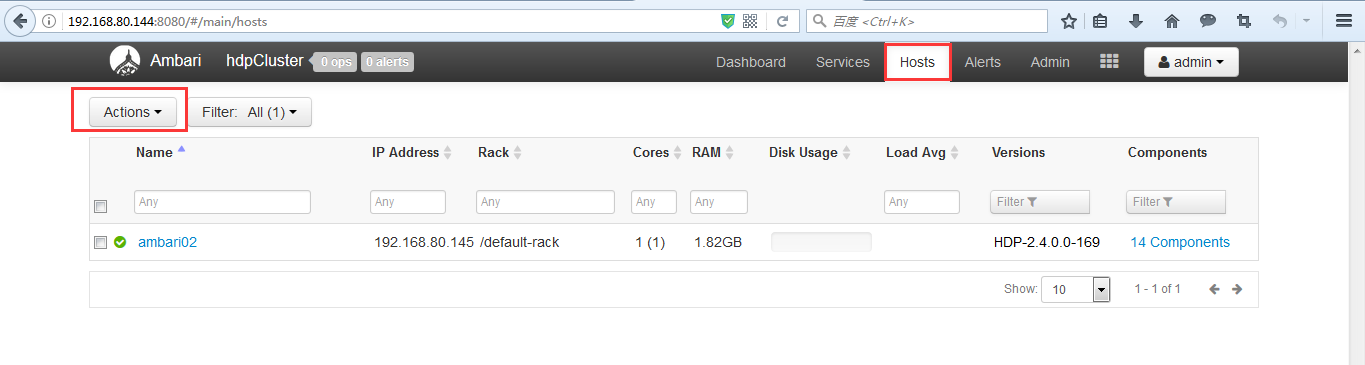
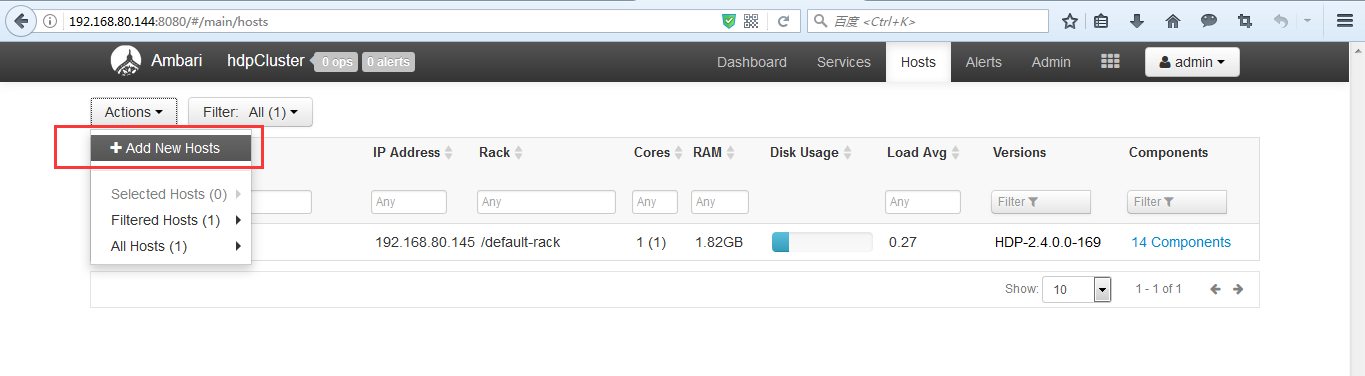
之后的添加ambari03、ambari04操作就和部署ambari02类似,可以参照前面的步骤。这里不多赘述。
Ambari安装之部署单节点集群


-----BEGIN RSA PRIVATE KEY-----
MIIEogIBAAKCAQEAvLAEPDRhnQUq4+6IRYTF6YKmMfvfGKKbkgEX5RrZ89BQbiOm
jqWrcb8yAi6zFY/uHCM6cBG/BzdmHPlTYZwAmt8qI4hs/5NvkjLUmlwFe2+fYofZ
6kRfuJh4eEyysiLhZBEkgb4UYtDQgvB12eFBgieHSkl2+nUVorgvbnIbcqoAz/fN
4d9iU5oa5pShjQkAL1NKUmLZAh1PcFSq1OGGGEtsWFp7ggt8ufahejyZeqstbWl0
vAxohuvYdW5YjIHJhLP7ld7arsv9f40RMNEdPuWOTWegM6p94oFRAIln9Wtcc271
jQoF3xjhqUpV17PU3ErZ6+wsVukZ3iMtP/PqPQIBIwKCAQB2moZRuoZ/9J6d5mRI
9F8lEEs1XH2adNbQzXy75P4G9/gKt1LAEF0i7TVgdSAcLpWrSVfurBGsw7yHPaIg
GOpv+f066An/u8J5J0POvX/J7mQvThPyVt0U8h/Wlpw1dQKz7YSpUug+HNrV9jtz
Ap40jeACzxeWHbXT/r66c5w5cRciB4eFQ14xO3FZyfCcD5AjAWYNyze7mI5i8396
VscwVCd2qUsMQnjR6RXQd/vK3KJ62S0rxKQ0UC5+H5OxVny9m9q+8Qy53iEMtX/n
GzDph2OGTGHBrR/+kOjdwx9kXy5FknL5Q1EITeERI0NcFmwN1UlEyaAGkDNf88ye
hzjDAoGBAO7yyfNTcQpy0ZdAhVDWDb+ohKt83ucrkiW87dXHPPo/QEJOZCl2SsVt
bB4p4gEUcpxy5rgkgB0JAuvnAv4JZ49I+NOASOnVpuhty0qGzRmvk1soGQn6TyfK
HwybRLXTHUiQfx0UQFTrbNdpubx0CKT0fBKBBviejyfSOE59pM//AoGBAMonCpo6
a+TvjNr0TgwbyzhPHdmRBnZDXkctQIo/YE704l+eoywbKGty9MlWJ1lGZTFlnZej
Xxe2Uhb0UGPo+VyCccBxc4slz1TaoQbRnpLV+s7+Mik/atG9kwB41Bd2/HjRWFAa
x1LyGN5ee2hocD4u5C/x0vrzulp+5wH0poXDAoGBAIG2/+p9wQWsC2C8oCSRdS2H
XfaxgFGbT1ZQnl4bs2NG6F6CU6F6uuA0Fh8AyyUoW3mANBrR/GeIjI6wmzly0dFw
wZdi5cDEcIzN42L4uHuodJCSHDid0zLbb/DmkwOefZxrsrgDreT01K9z6Hw+/WDc
fd4oyUUi3/+sojk85HDpAoGBALjTPOTHsxp0ngoD75YKyG3/MTvyTw0KZNNckseK
Zq6WwFdsd+3Pr+015x56p6IUecbDTkF/bOJ6zrXmr+ZRWQQfffHG0AoxMpa5QsRn
4XBOnCr3CUpInC16IABueMT/Erea1GZ+4h/zSe/hWuMdqHNeEnT6Wn8KuQJII6oE
QHpLAoGAYNNuiUgLrqRq8Klb4Fj0pbwWzrvNkON+j01mIEzPeNNto01GbLXKQwhe
mbWMSnLHarmFWJ7Yamagzx1I/ifRjUUFLchcxLH0VDv0e1ZYaD1FV2IQNJNS4gWE
m8Xbq7v4bjOmZvAfVoorH+gnvh0SMNTyFGq+rSB9wCsII3nLGPo=
-----END RSA PRIVATE KEY-----
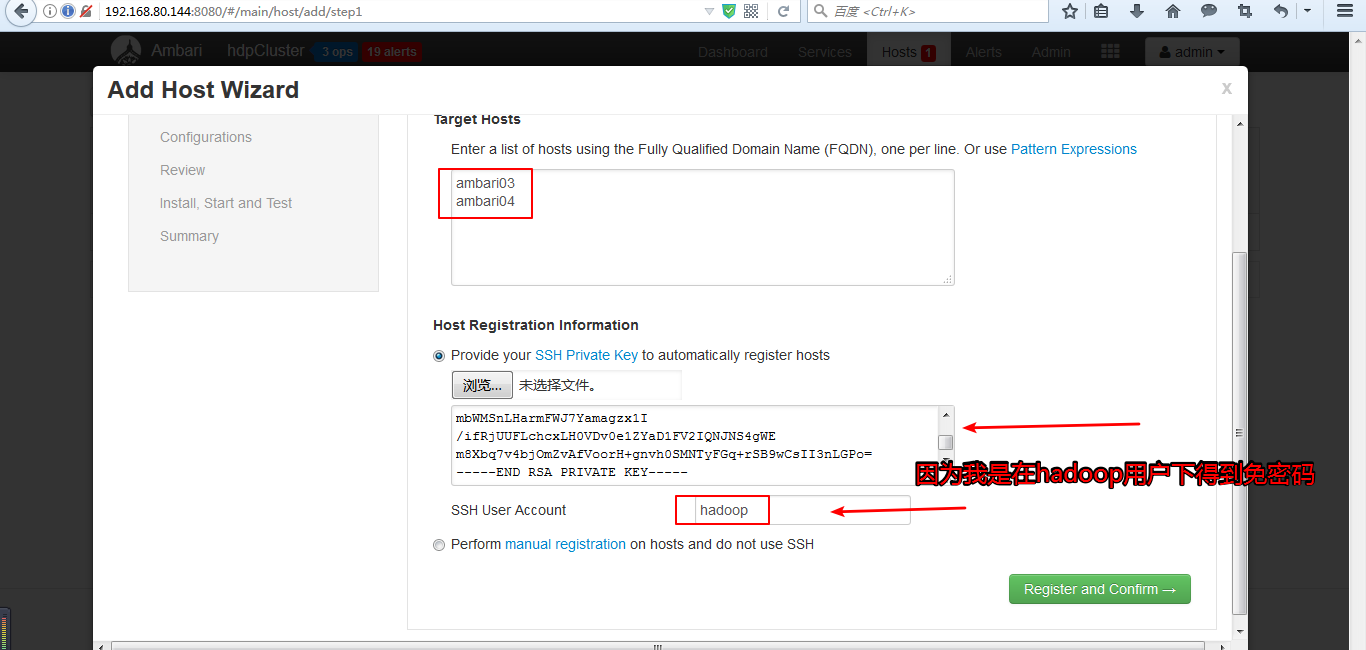
(2)添加服务
添加ambari03、ambari04的服务的操作和前面的ambari02类似,具体可以参照前面的步骤。这里不多赘述。
Ambari安装之部署单节点集群
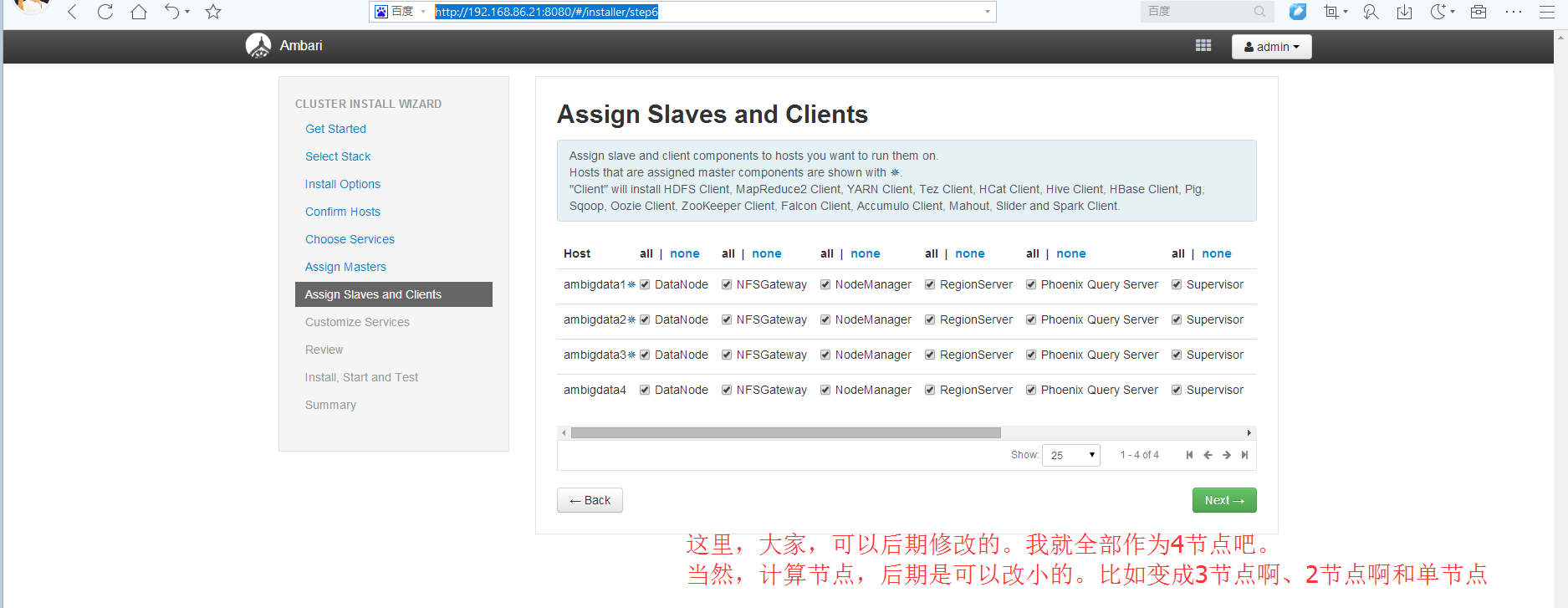
当然,我下面这里就是,ambigdata1、ambigdata2、ambigdata3和ambigdata4,组成的4节点的HA大数据集群。
我这里,就吧所有的服务都加进去。

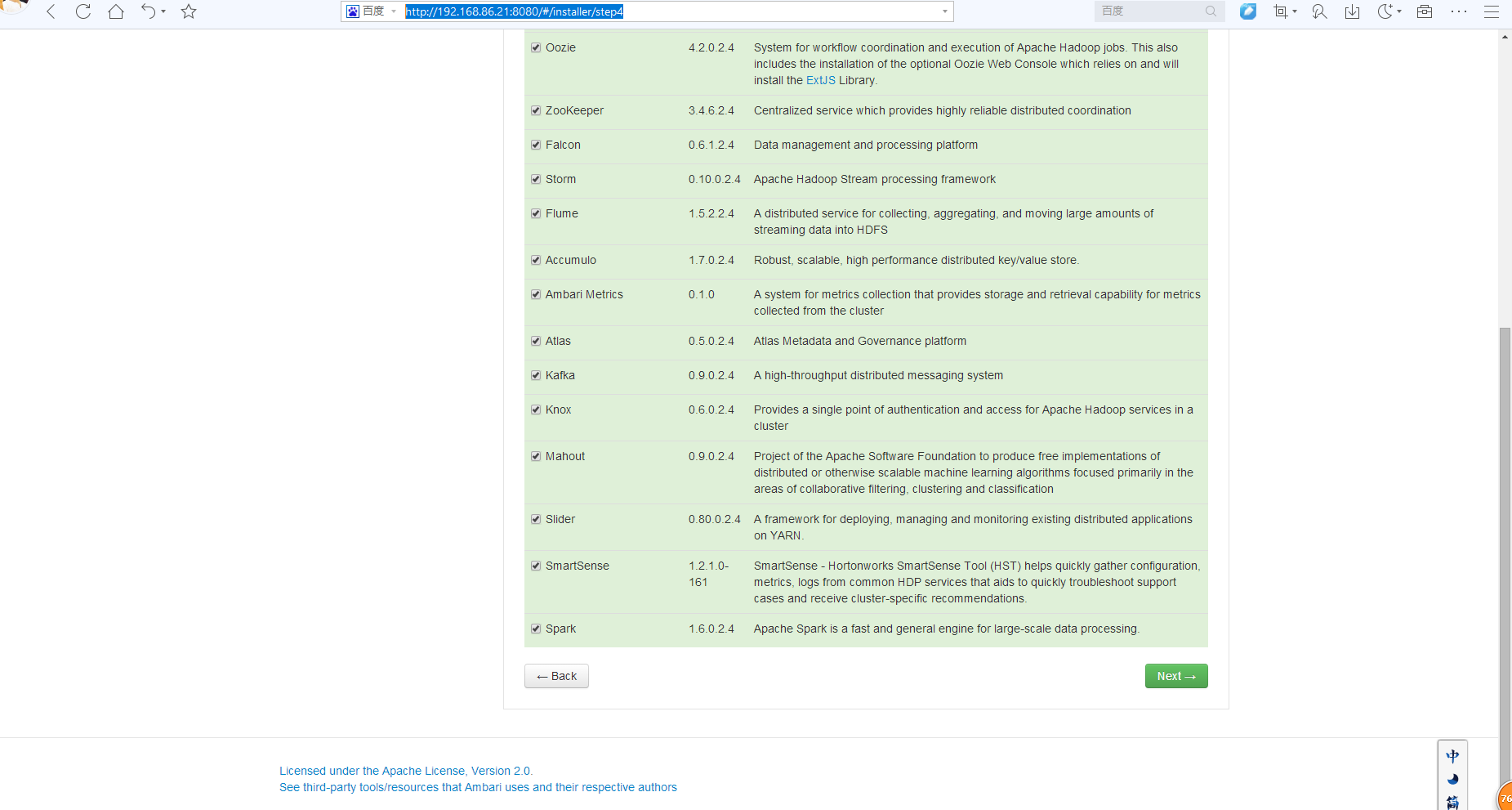
(3)配置HA
选择,HDFS -> services -> service actions -> enable namenode HA
YARN -> services -> service actions ->enable resourcemanager HA
以后再贴图。
接下来按照命令提示一步一步操作即可
这里,大家,如何控制下呢?
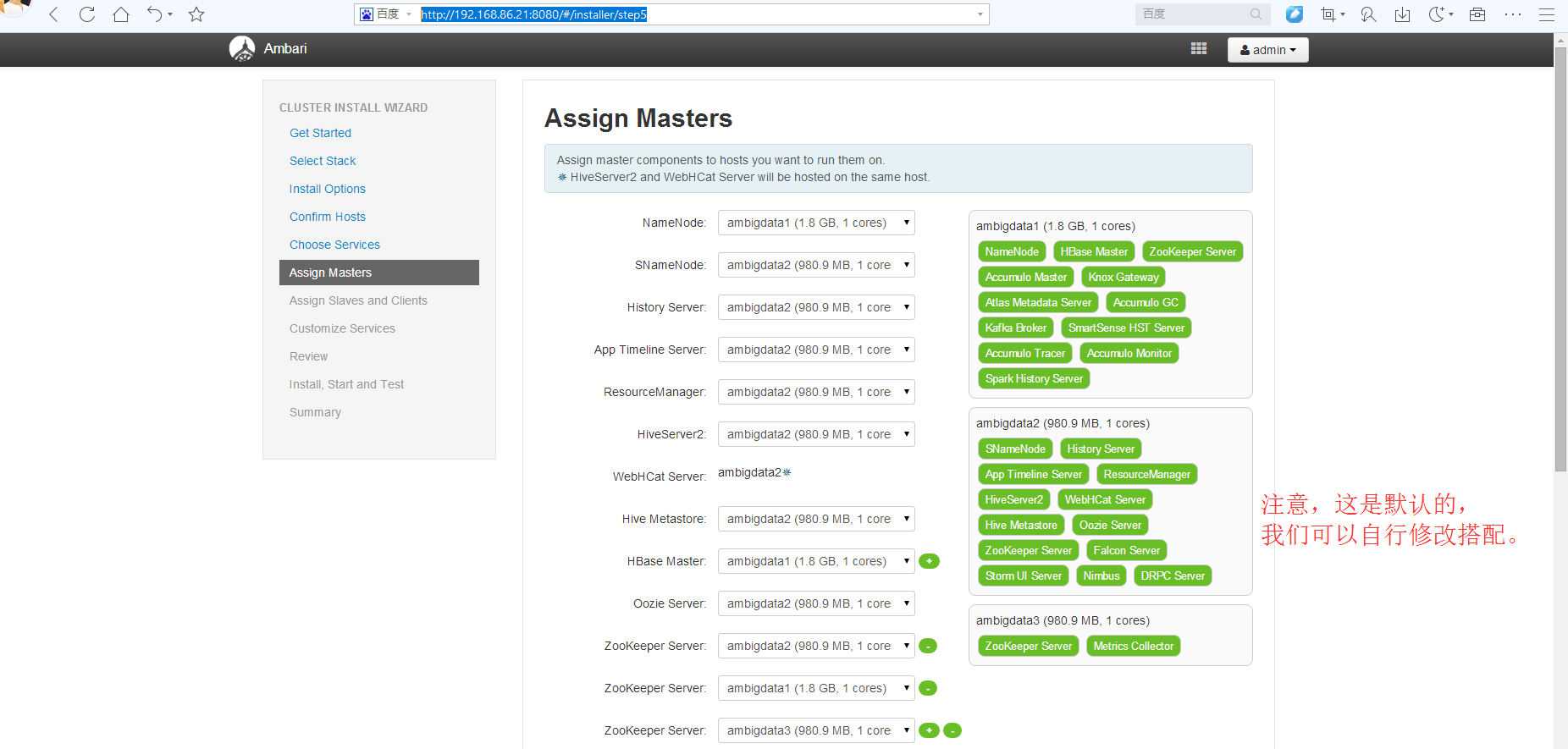
比如,这里,我参考这篇博客
完全分布式Hadoop集群的安装搭建和配置(4节点)
在这里,为了今年实验室环境所需。所以,将计算节点动态设置为4。来迎合论文里的4、3、2和1节点,对比加速比。
则最后得到,是如下


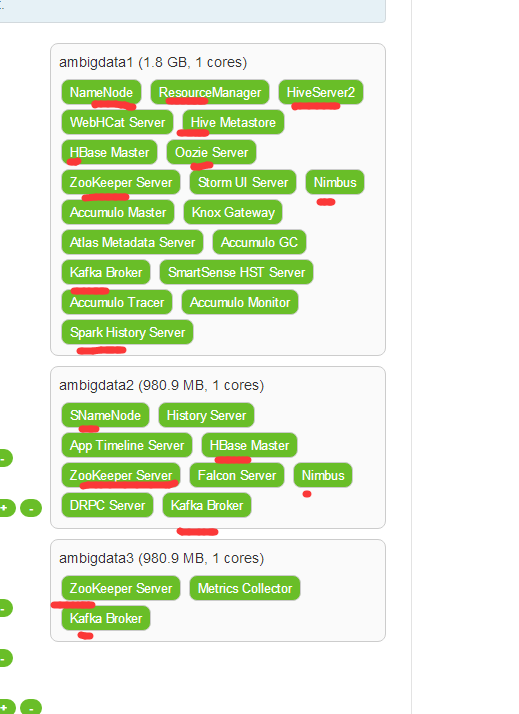


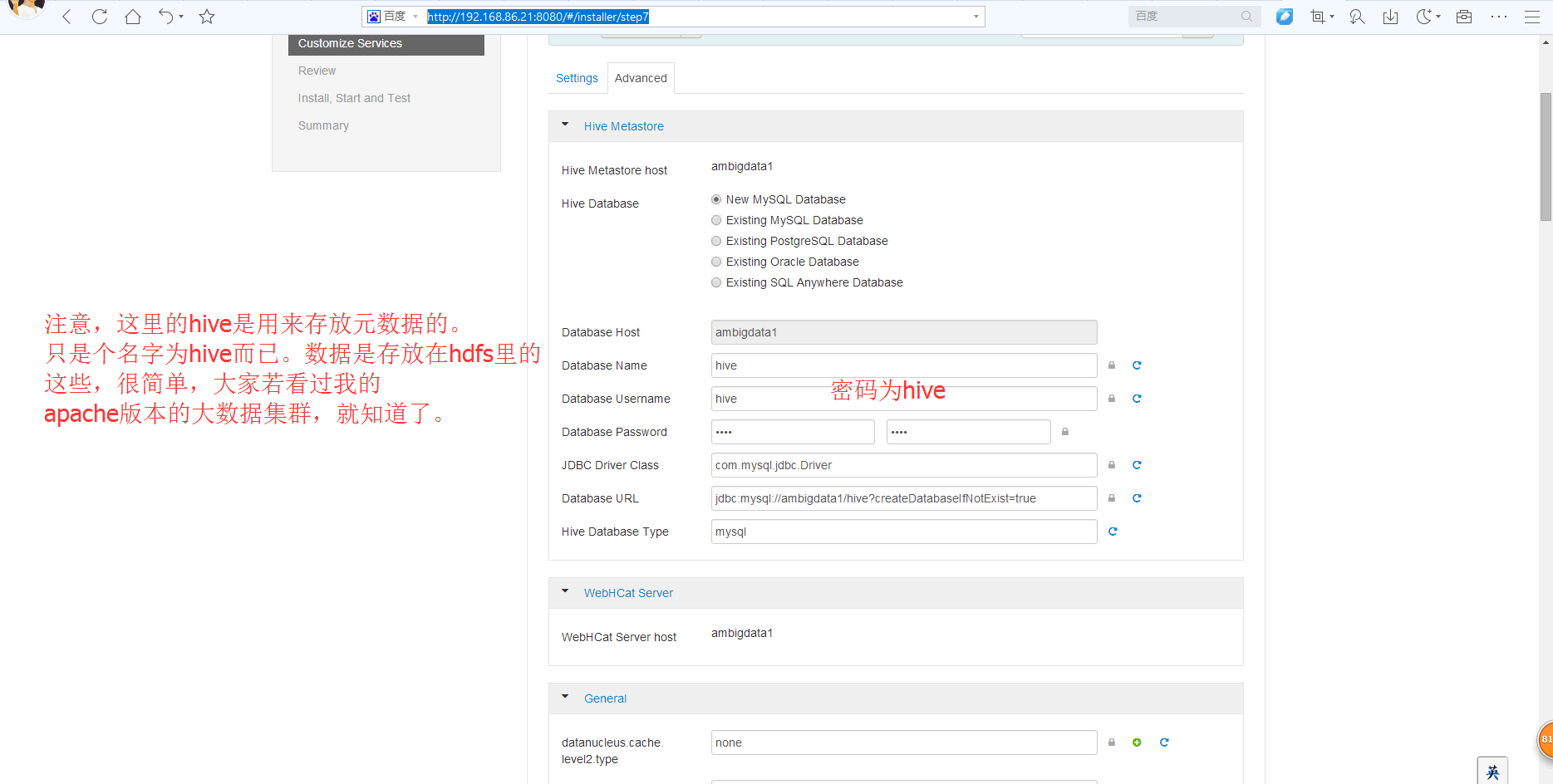
然后,下面就是,等同于apache版本的hive安装的配置文件hive-site.xml
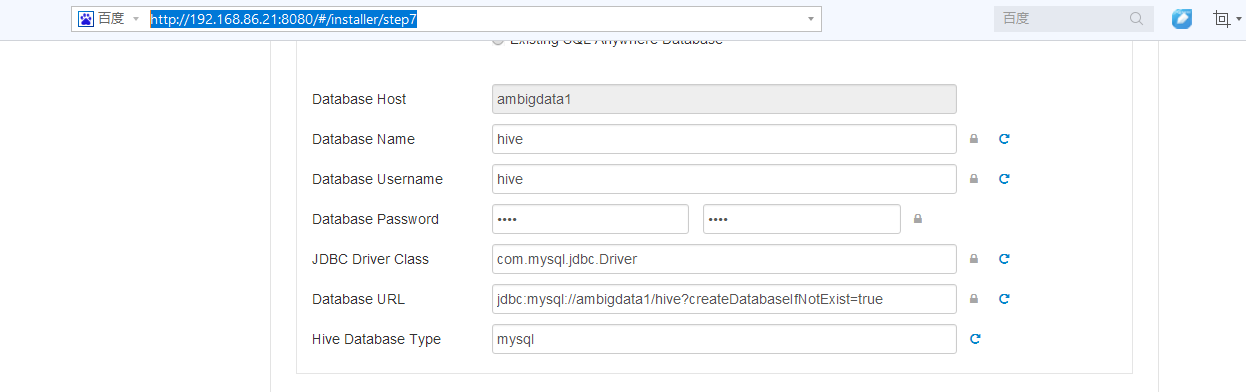
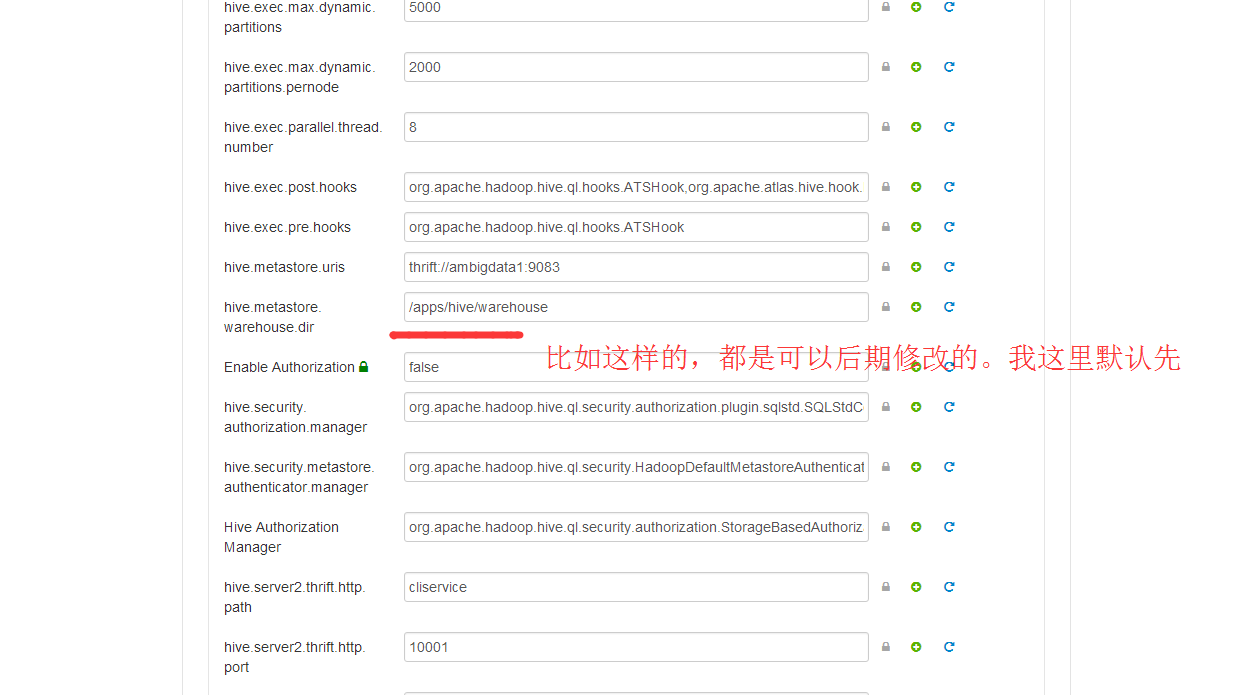

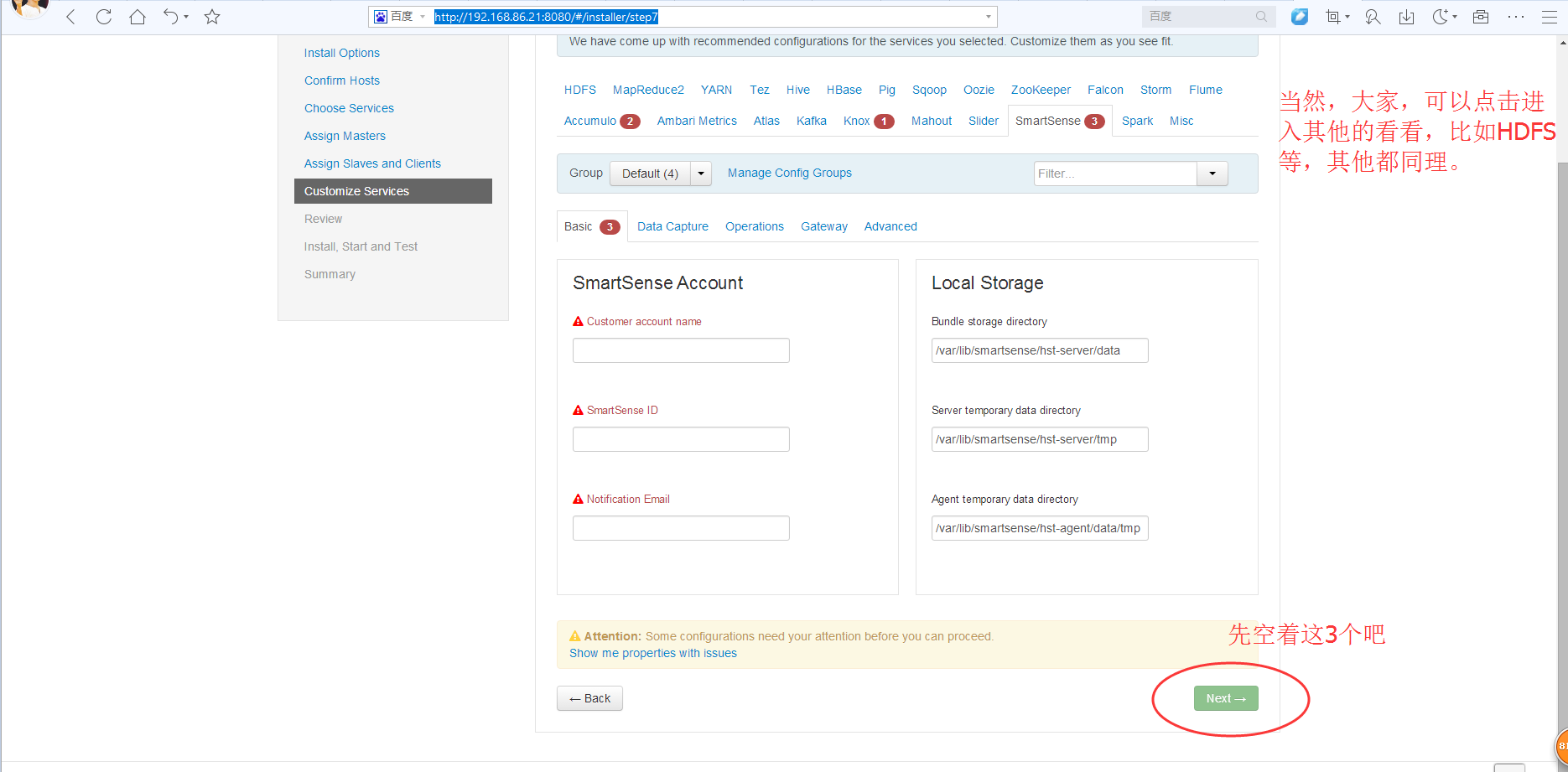
然后呢,相信大部分博友,跟我一样,在这里,对下面三个现在,都不知道怎么设置。没关系,大家,可以先跳过。
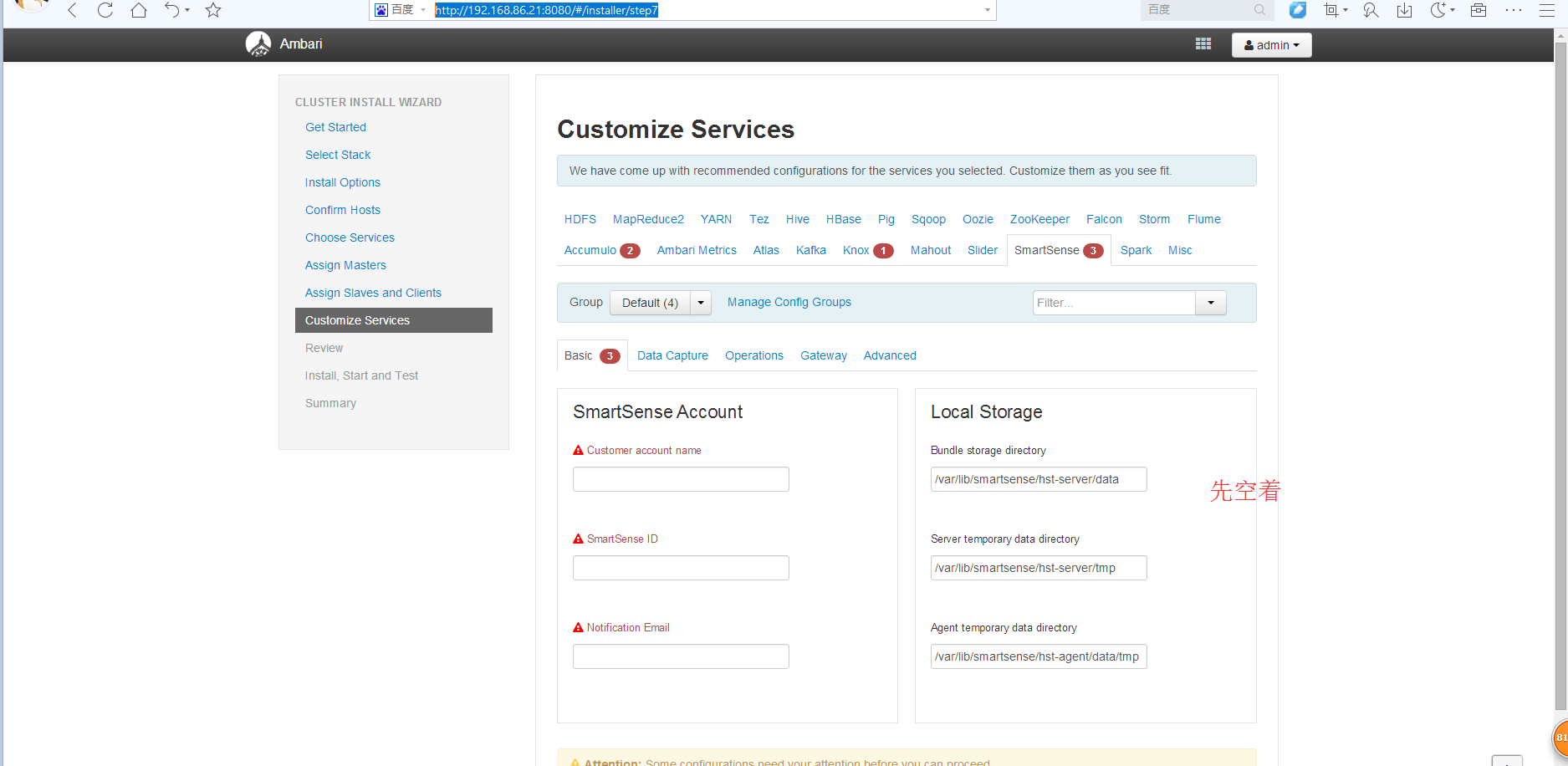

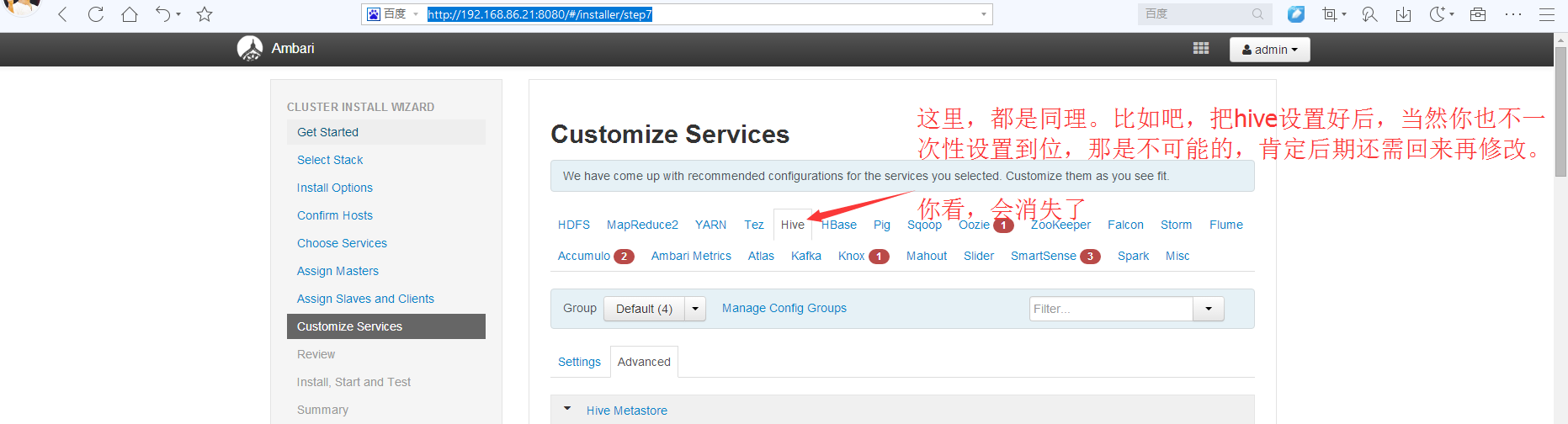
以后,再回来设置即可。这个不难。

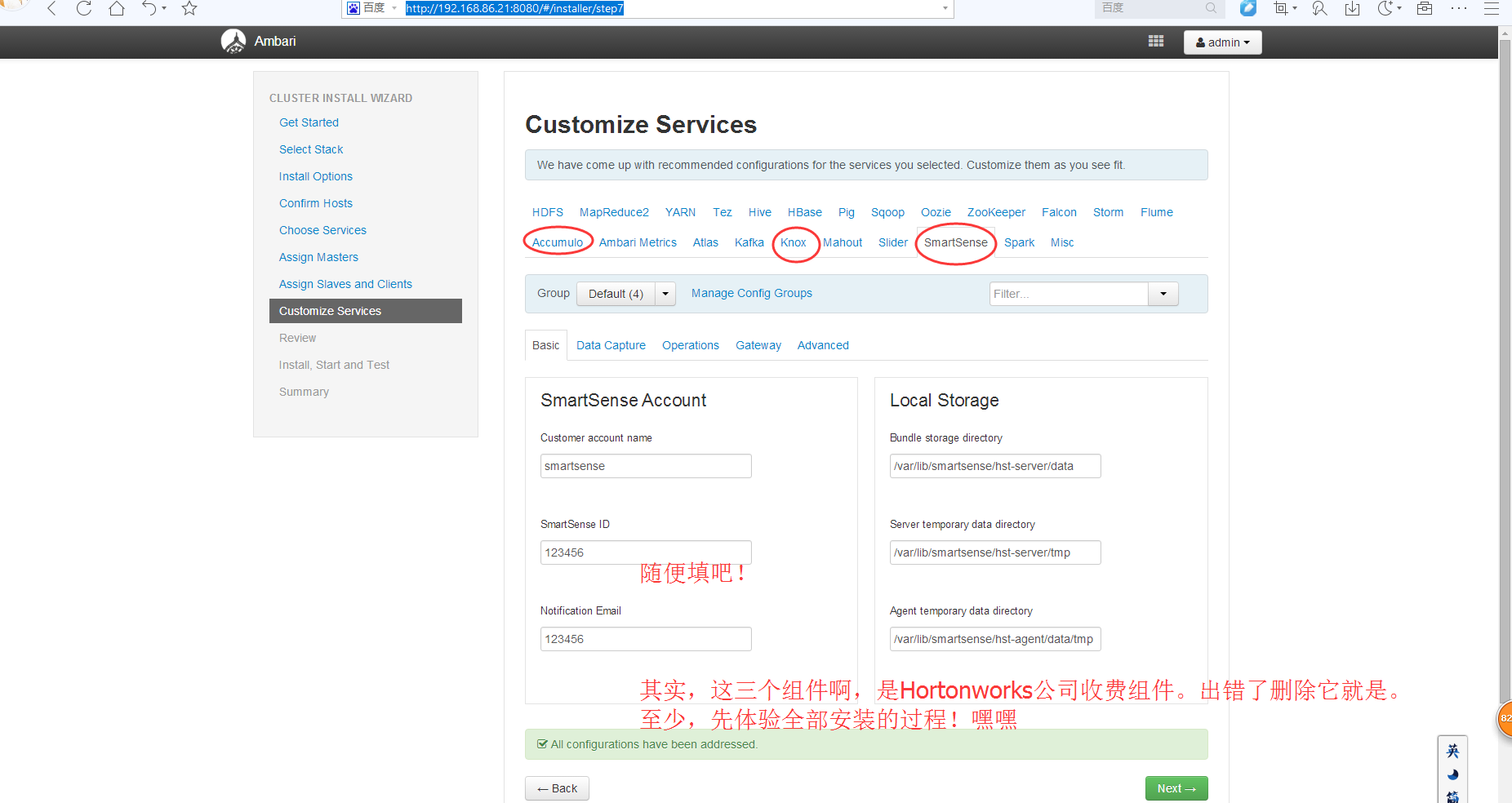
保证所有服务都正常启动之后,下面我们就可以上传文件到HDFS,并运行Mapreduce了

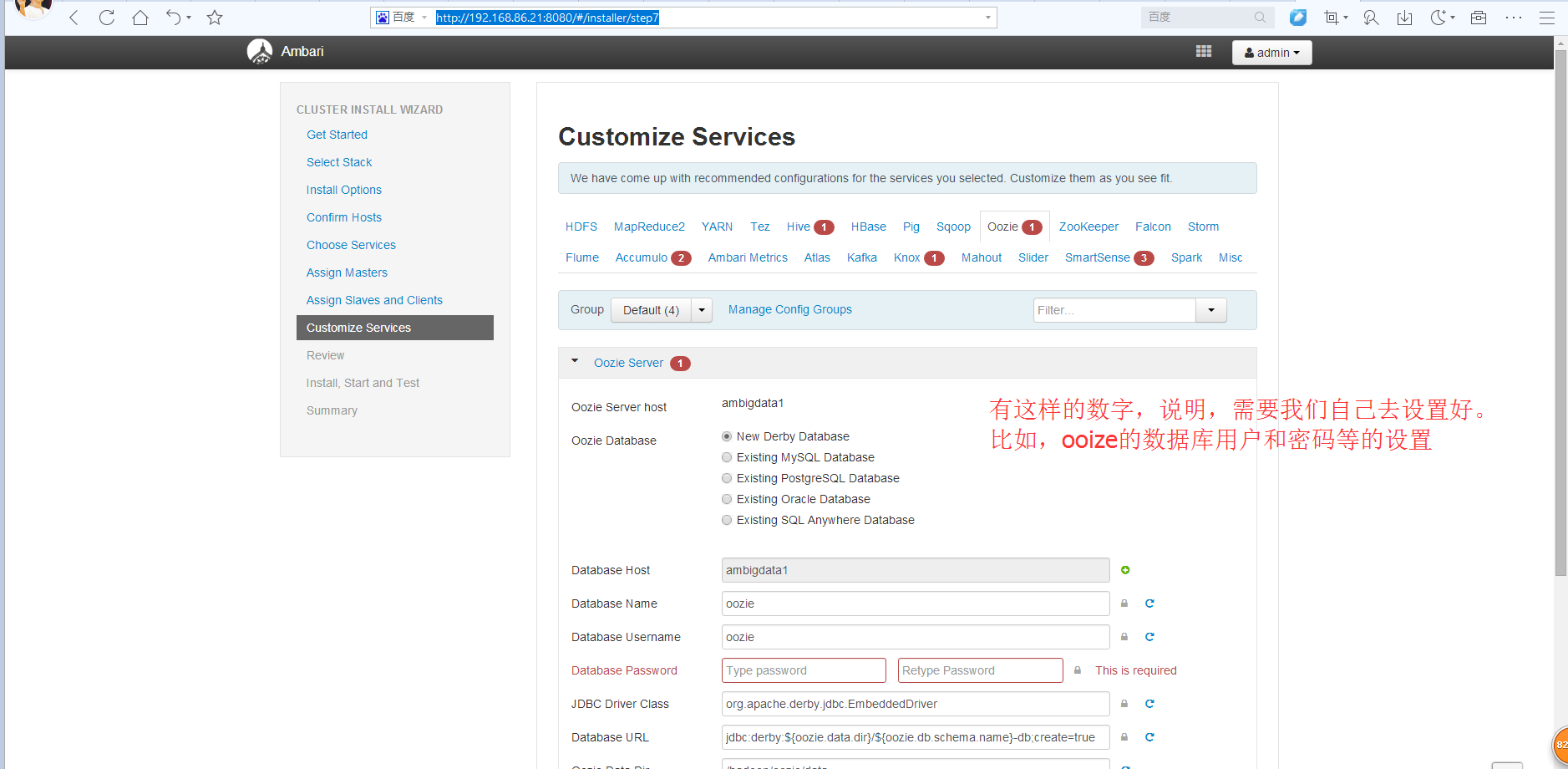
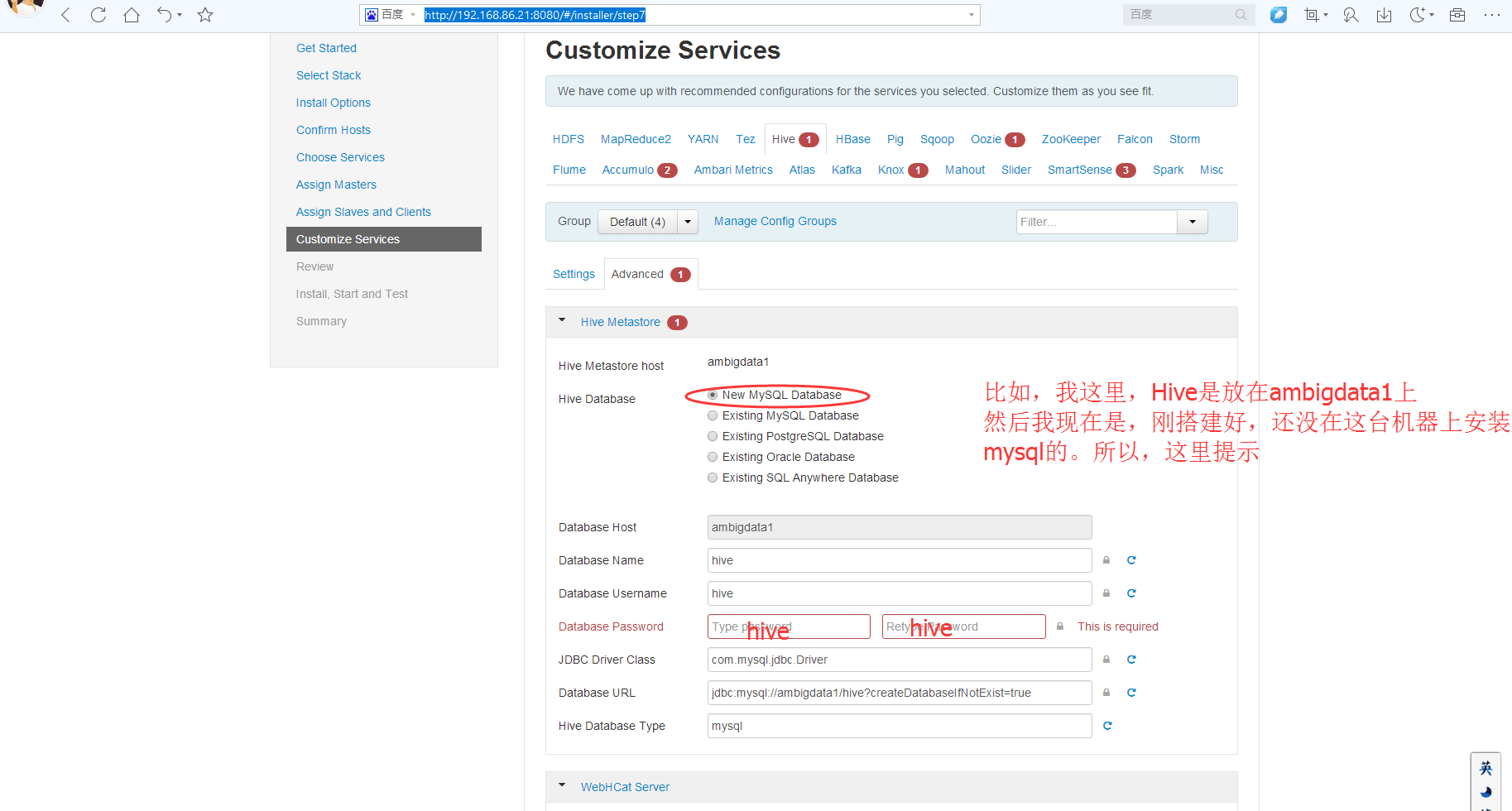
那就改成mysql数据库来吧
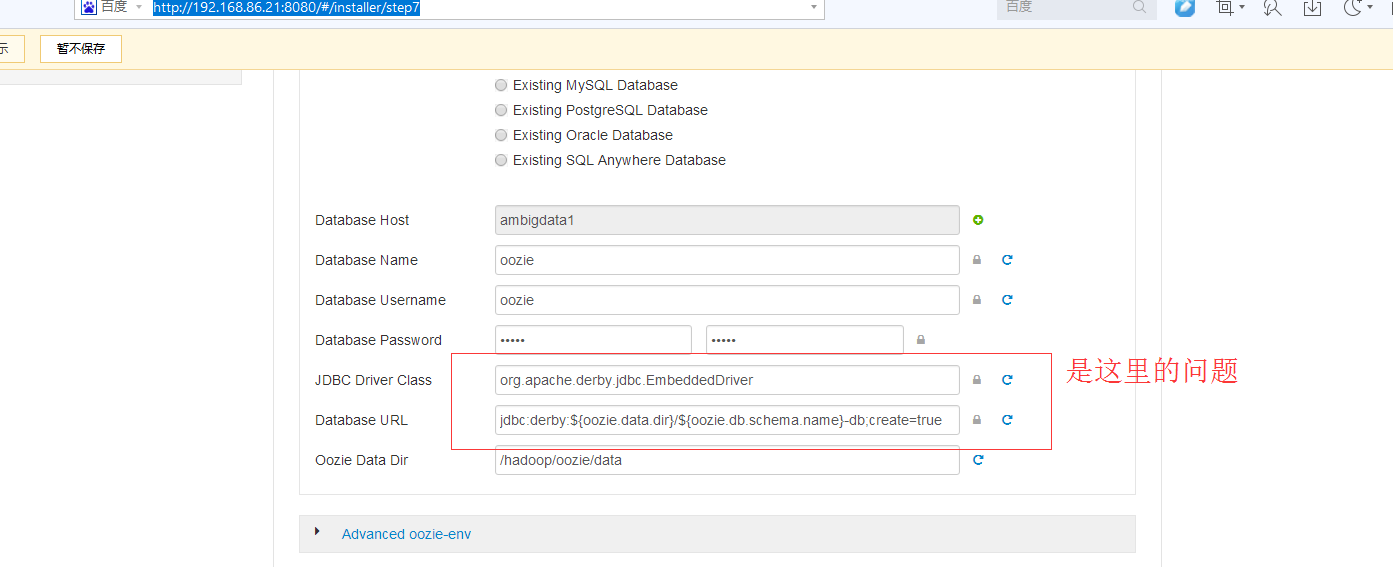
这里啊,我查了下资料
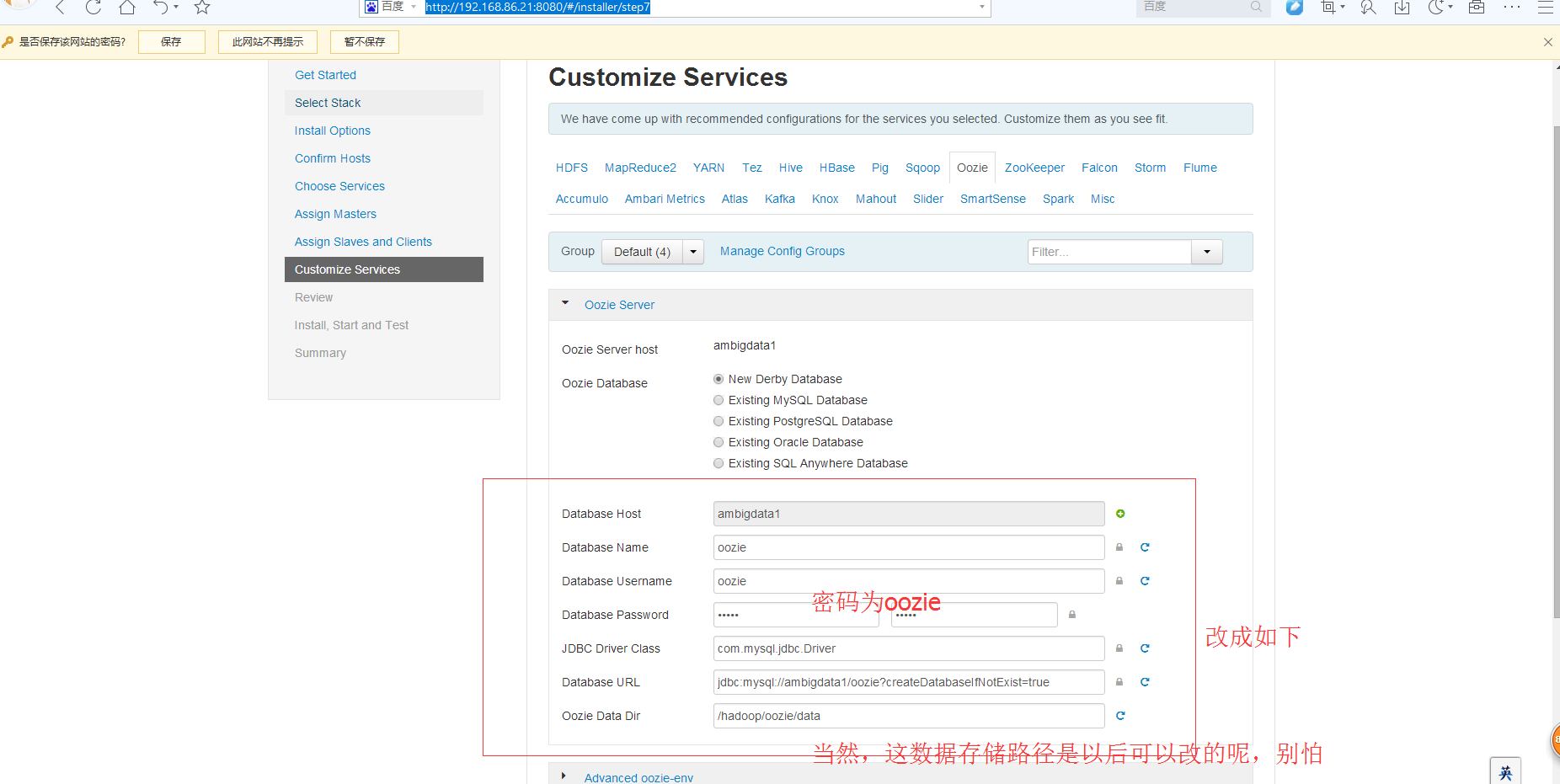
然后
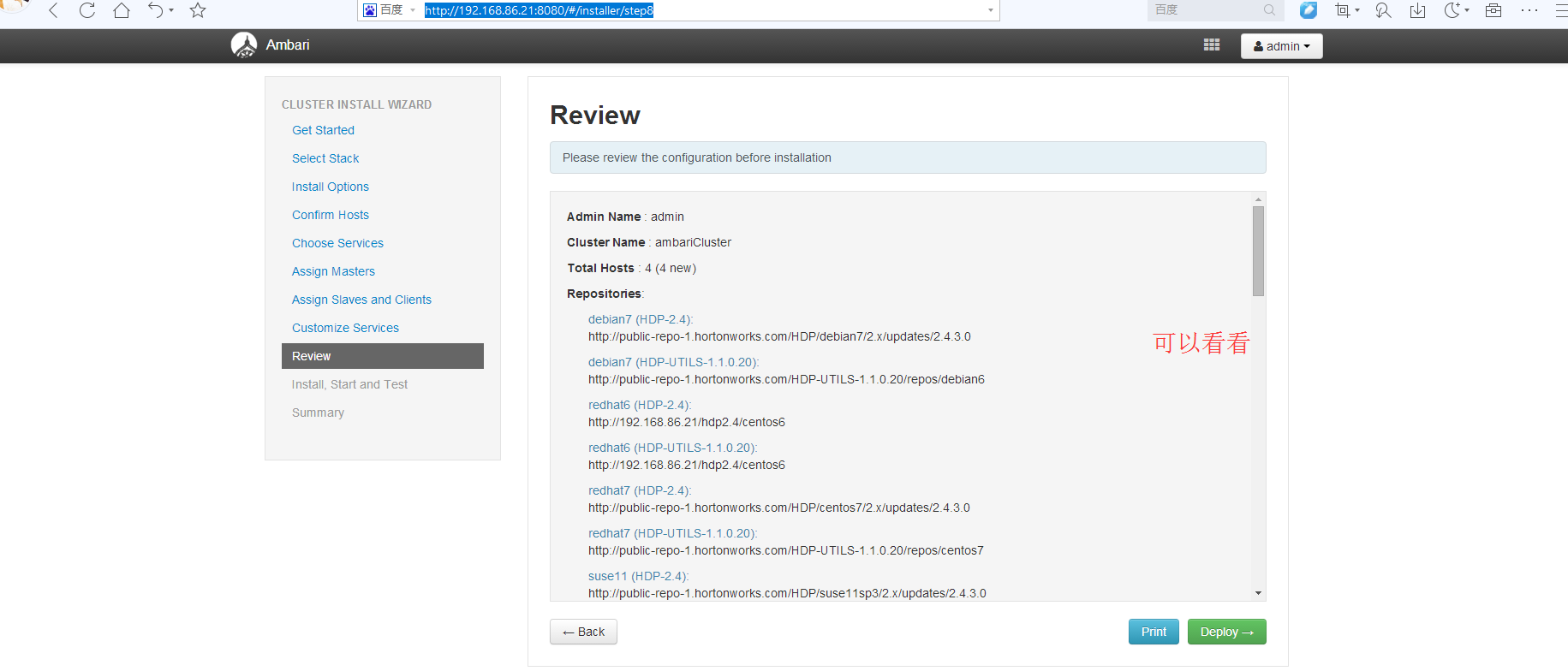

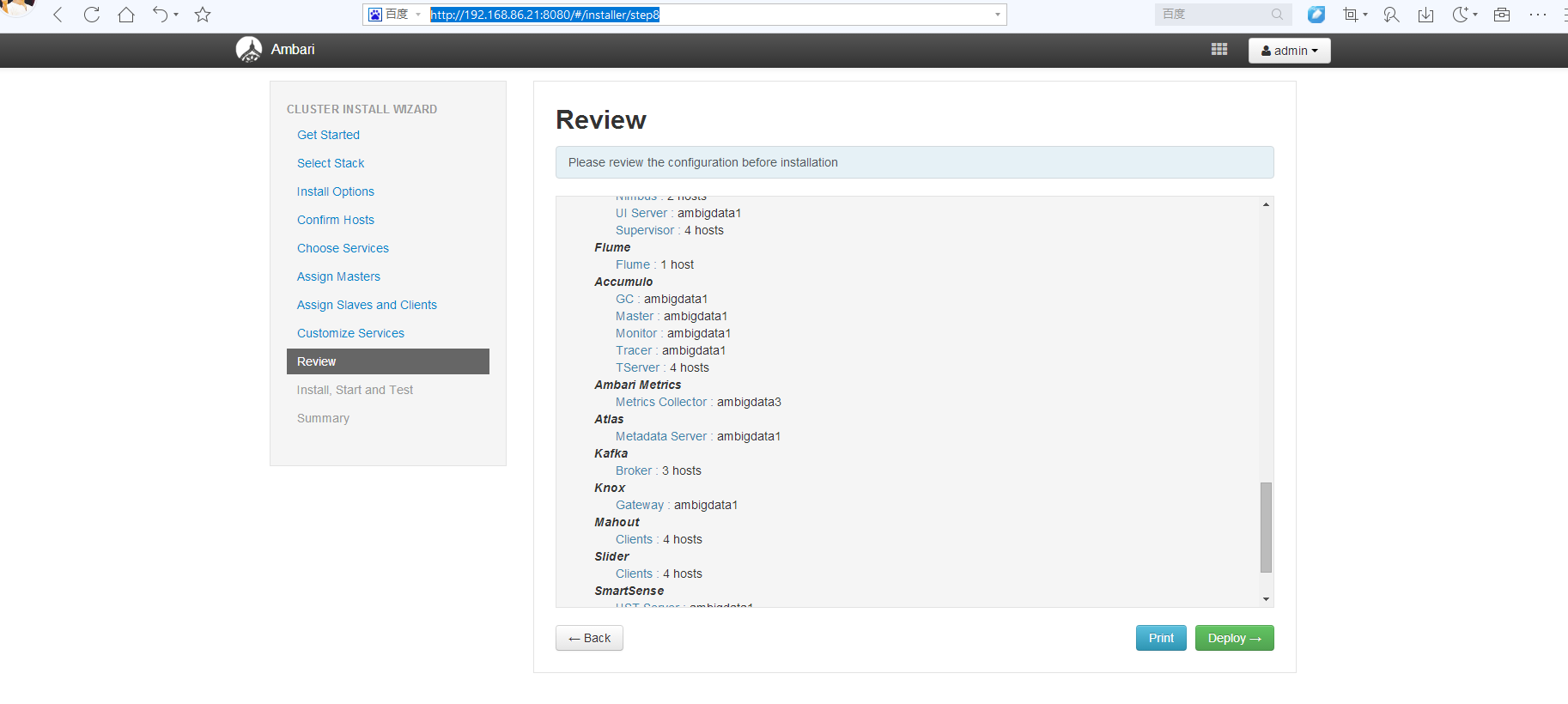
http://192.168.86.21:8080/#installer/step8
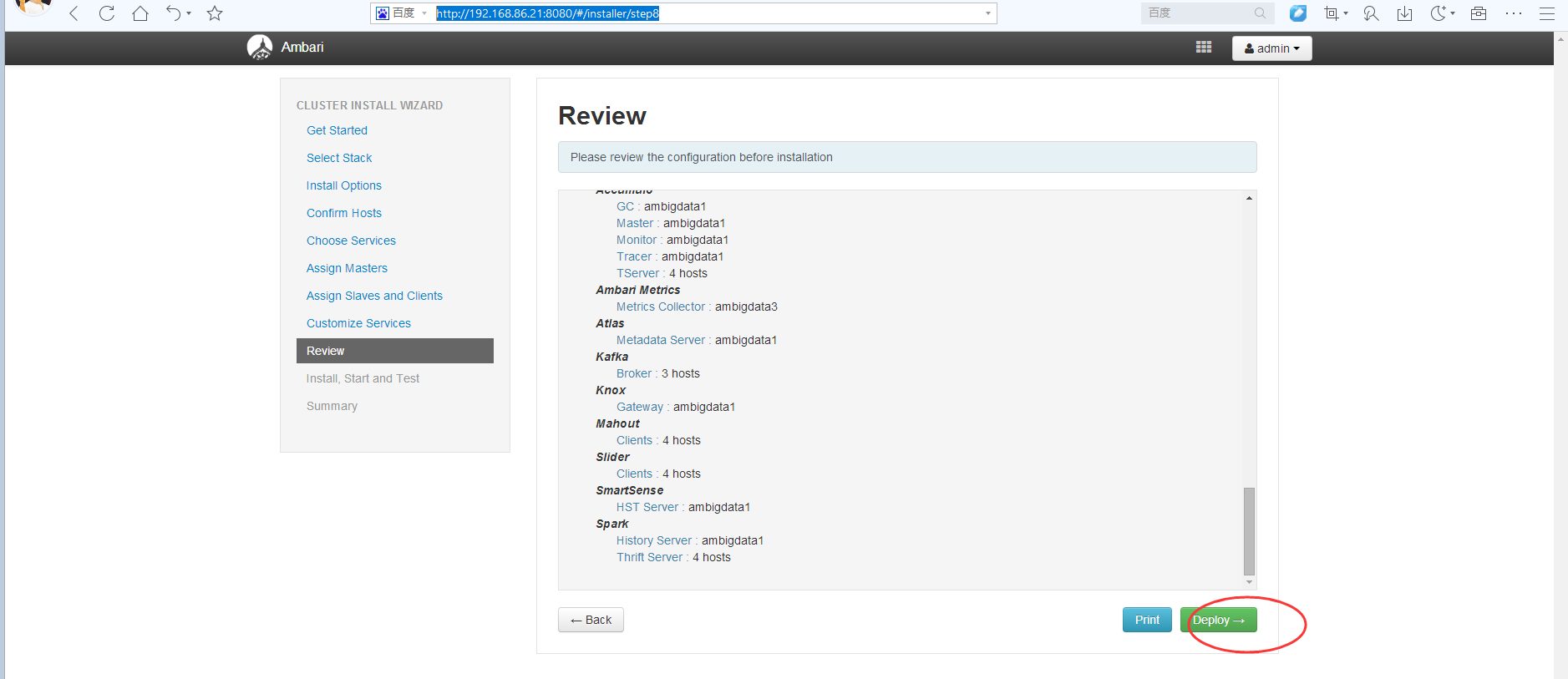
比如这不,有个什么Hcat client安装失败。多刷新,反复这里就是。(因为是网速原因)

最后,一定会成功,全部安装完全的!
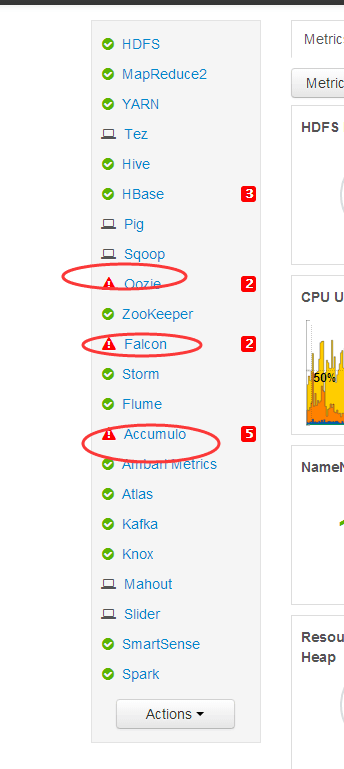
如下是我开启全部服务的过程:

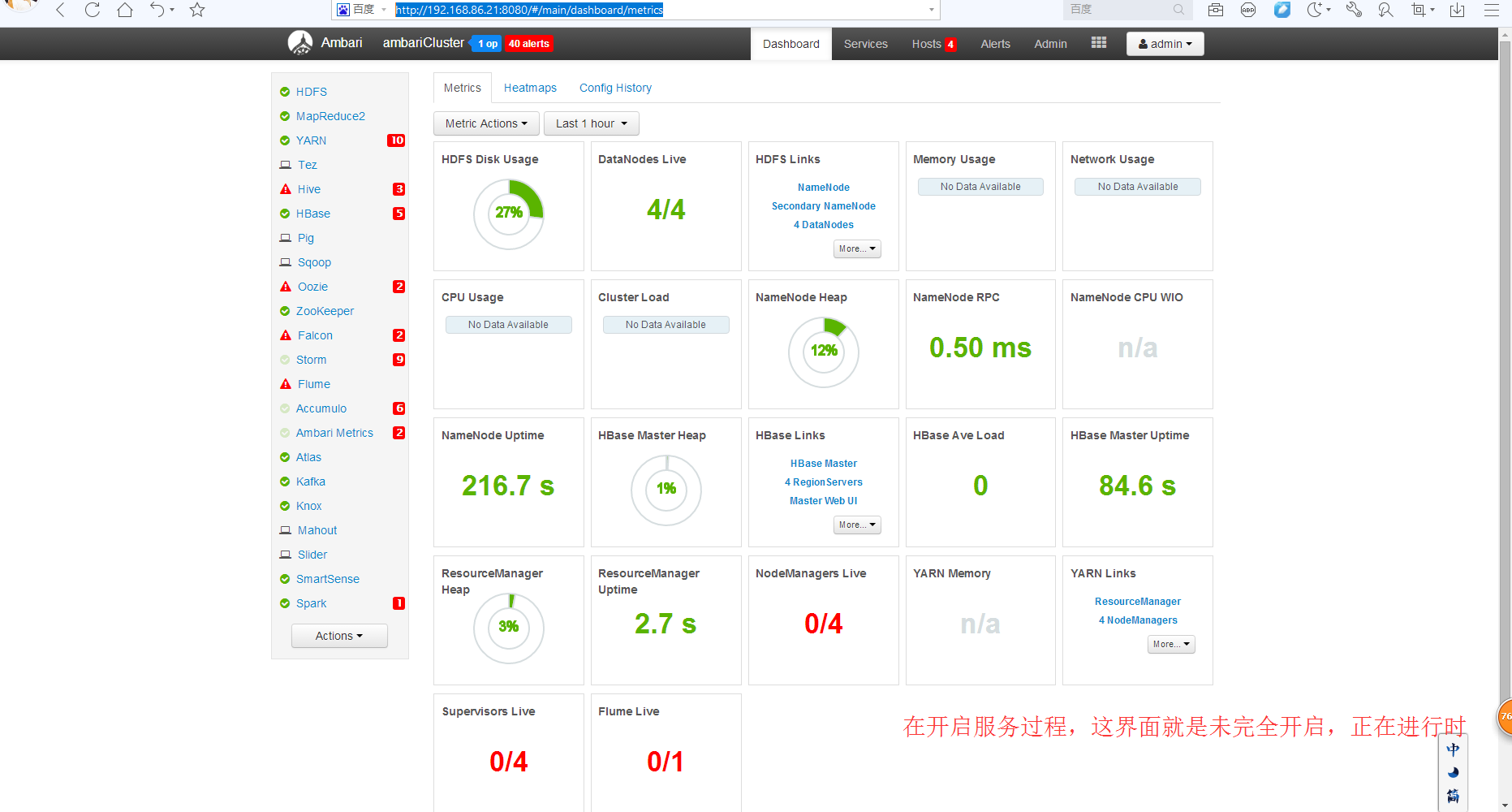





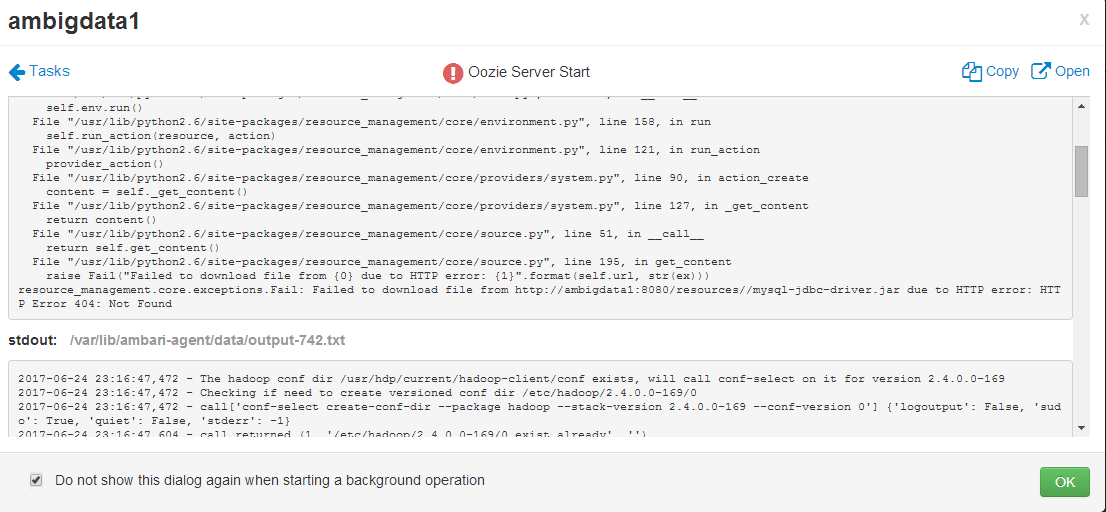
一般是怎么看的,请问

Oozie安装时放置Mysql驱动包的总结(网上最全)
现在,这里是ambari里安装oozie,一直不知道怎么放mysql-con**驱动jar包,
其实,很简单
[root@ambigdata1 ~]# yum install mysql-connector-java Is this ok [y/N]: y
即可
心得:一般在公司里,是,开启了服务,就不需再关闭。
(4)运行MapReduce程序
1)上传文件到HDFS
执行命令:cd /usr/hdp/current/hadoop-client/bin这个目录下创建vi wc.txt这个文件,然后输入相应的内容
执行命令:sudo -u hdfs hadoop fs -put wc.txt /hdpCluster
文件上传成功之后就可以执行命令运行mapreduce程序了,运行如下命令
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-mapeduce-examples-2.7.1.2.4.0-169.jar wordcount /hdpCluster/wc.txt /output
可能会报权限的问题,那么我们只需要修改一下对应的权限即可,例如使用下面的方法。
sudo -u hdfs hadoop fs -ls /
sudo -u hdfs hadoop fs -chown -R hadoop:hadoop /
sudo -u hdfs hadoop fs -ls /
Mapreduce执行成功之后通过如下命令查看程序运行结果
sudo -u hdfs hadoop fs -cat /output/part*
那么到此为止我们的ambari安装部署HA分布式集群就给大家演示完毕了!
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号