
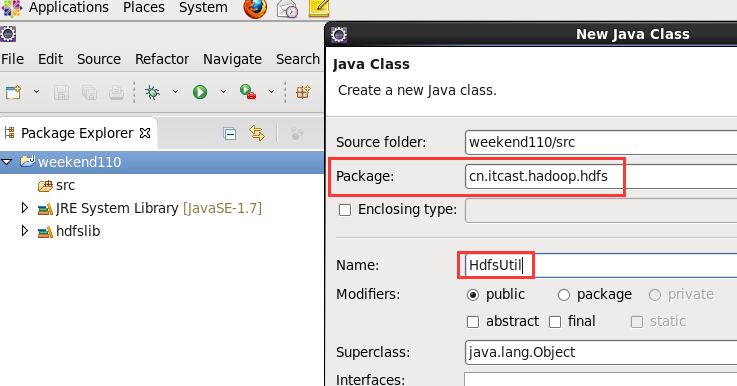
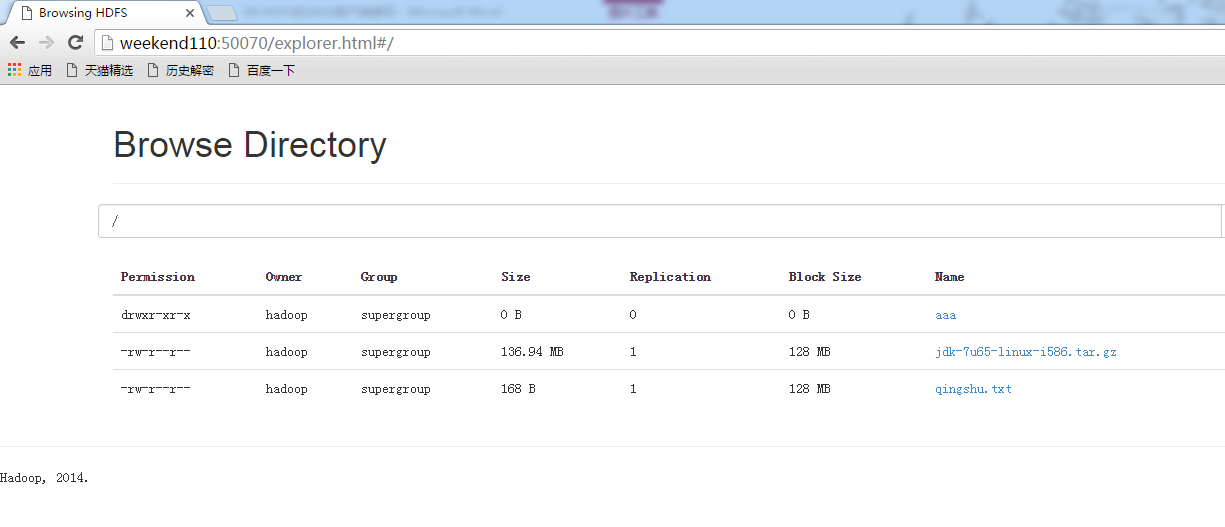
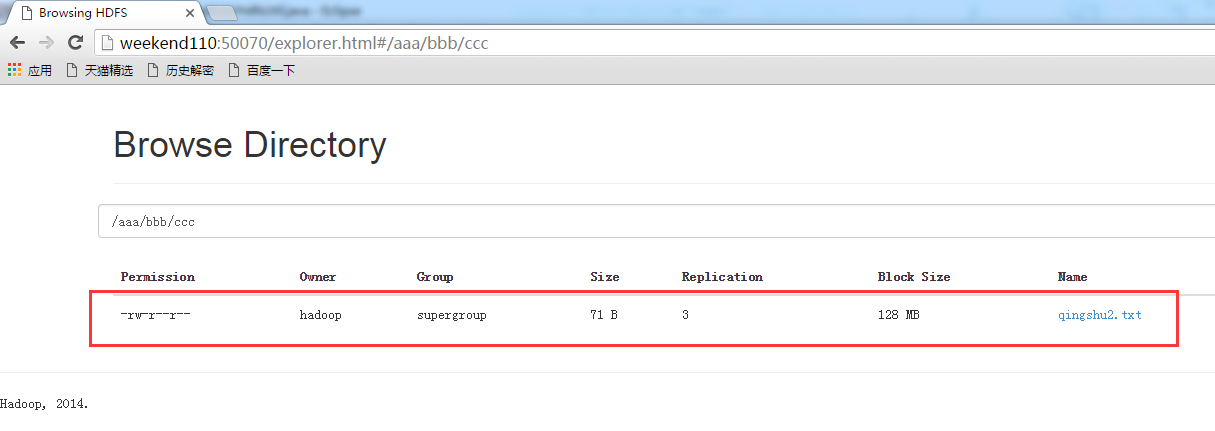
2 weekend110的HDFS的JAVA客户端编写 + filesystem设计思想总结
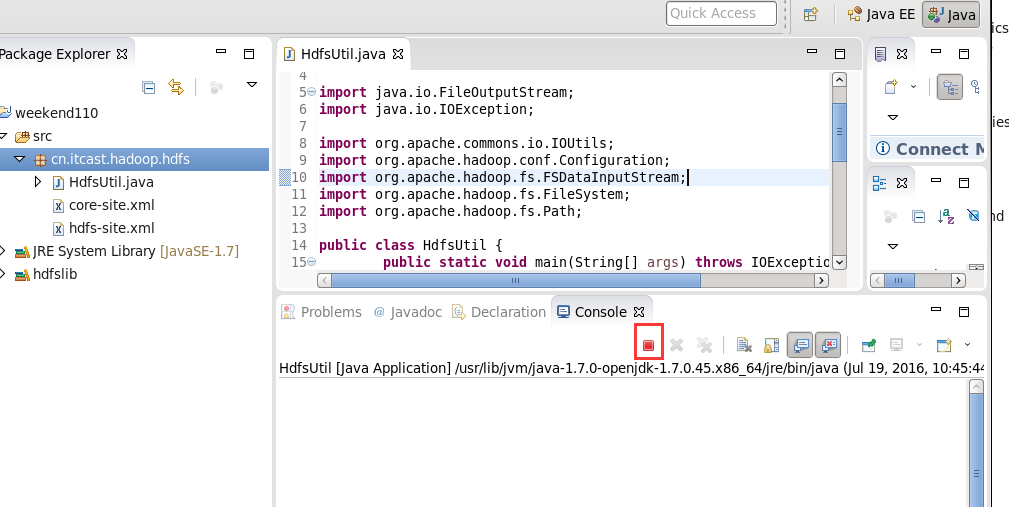
HDFS的JAVA客户端编写

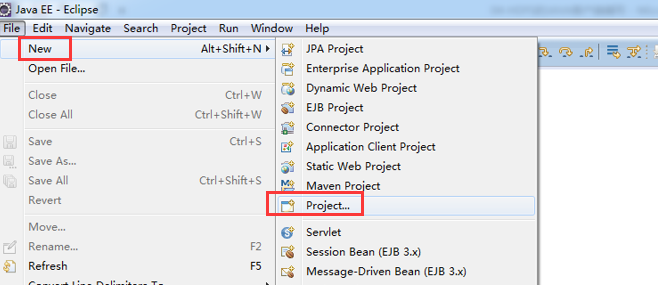
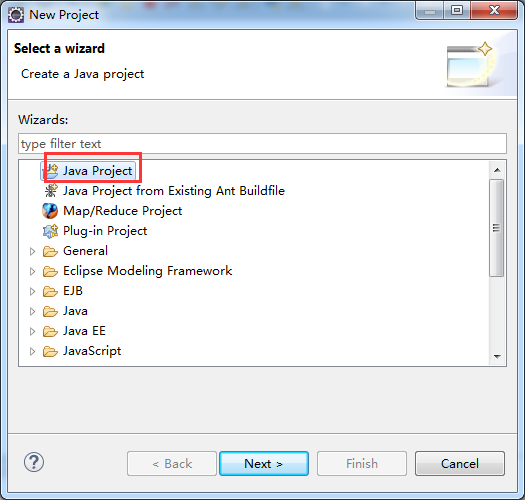

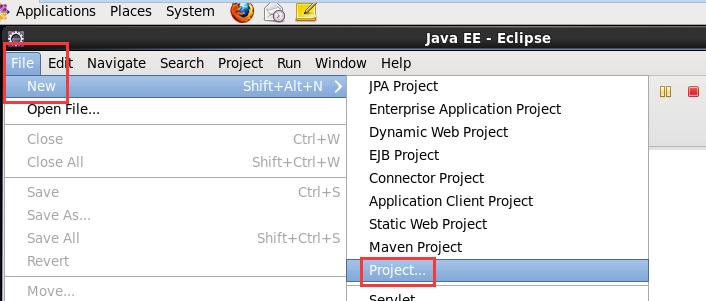
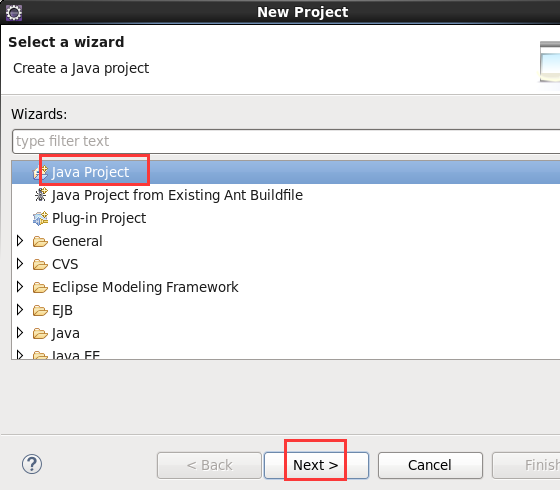
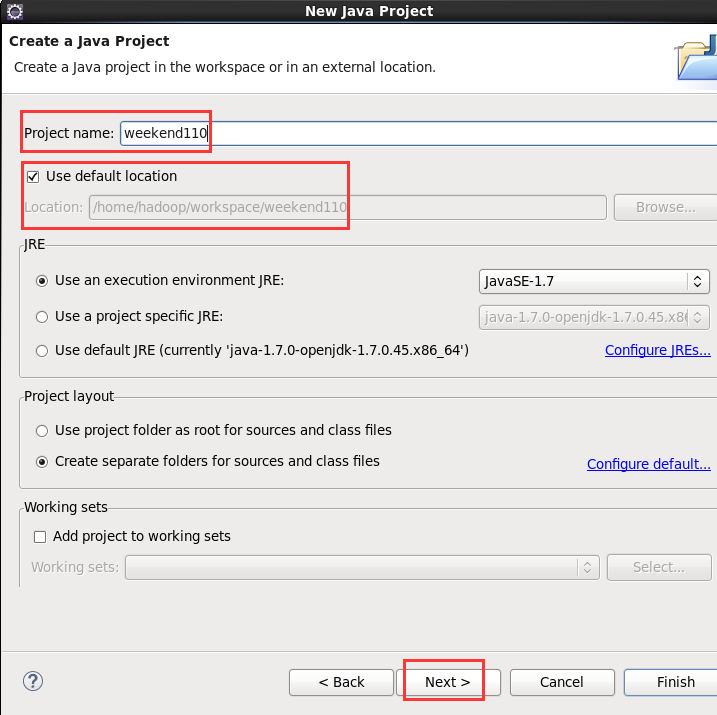
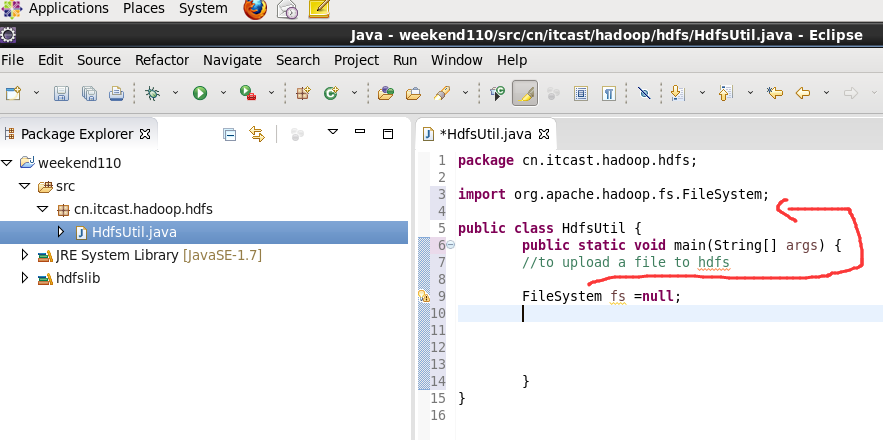
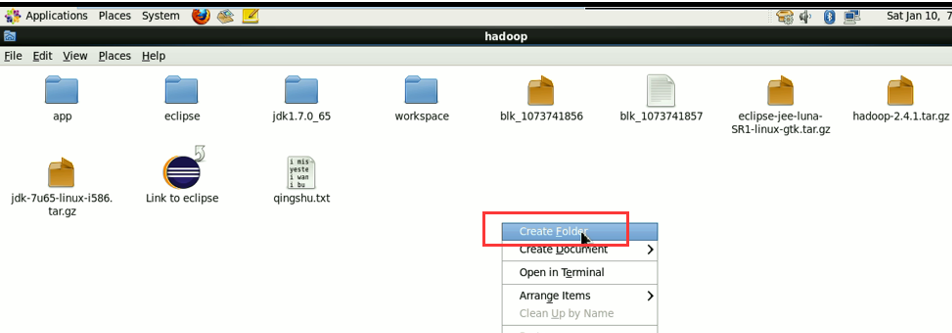
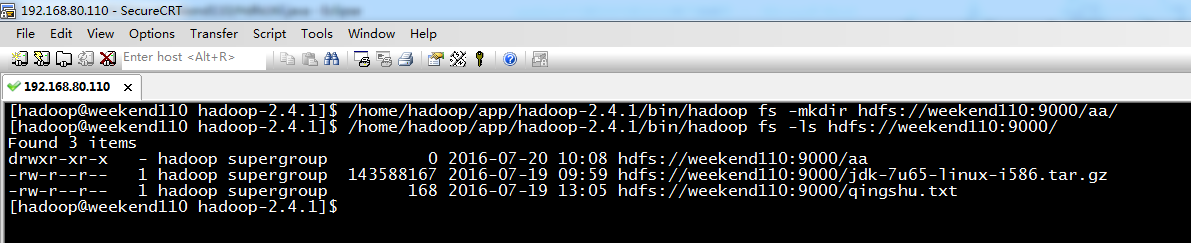
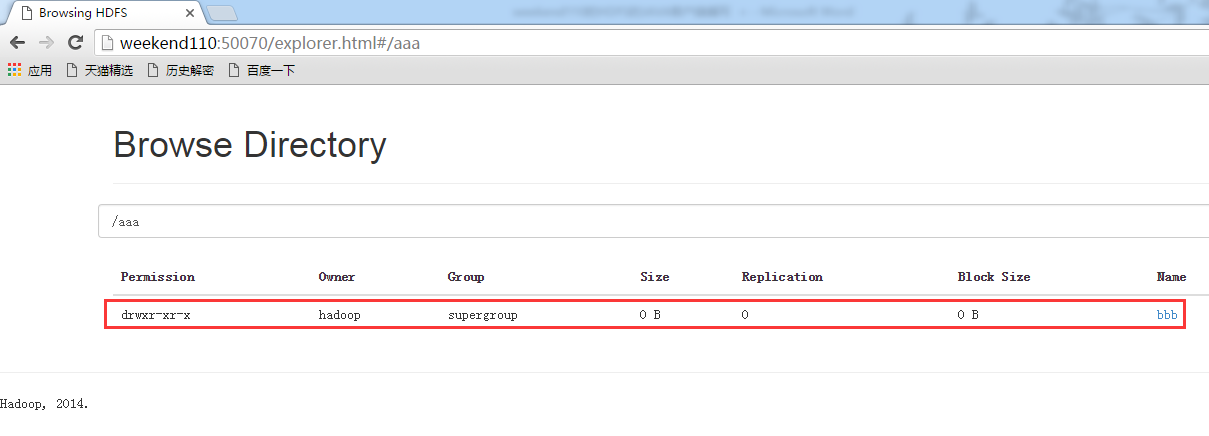
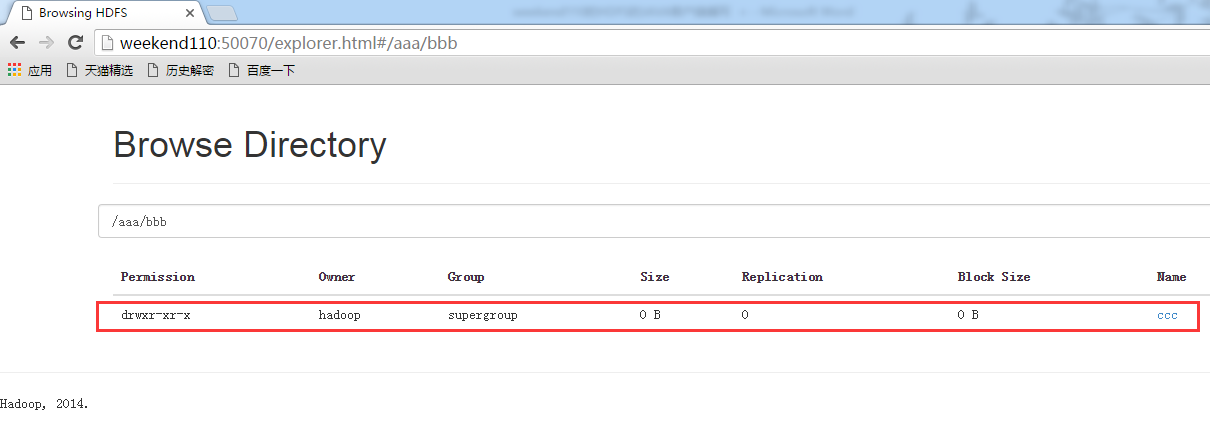
现在,我们来玩玩,在linux系统里,玩eclipse

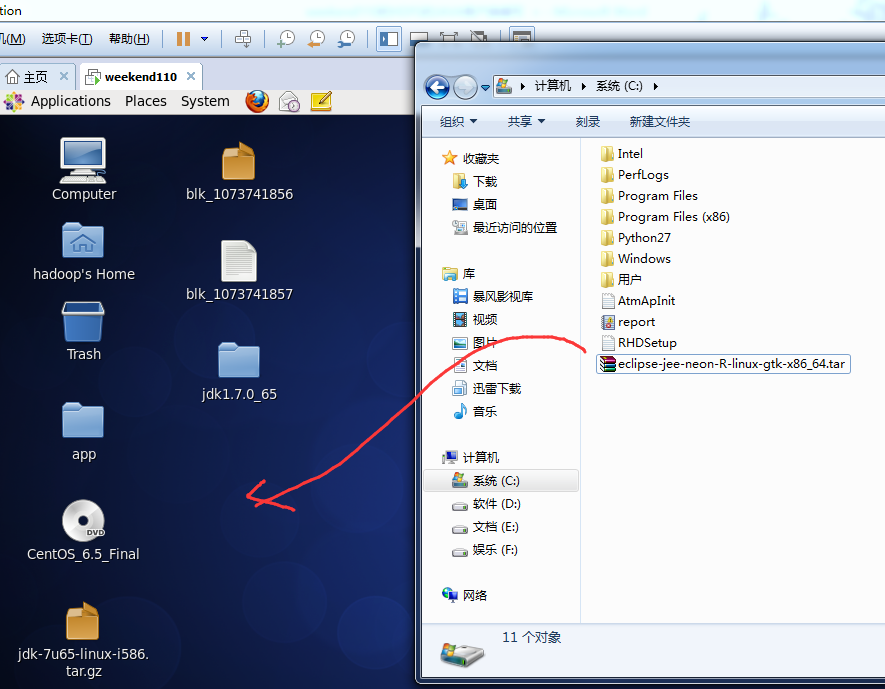
或者,
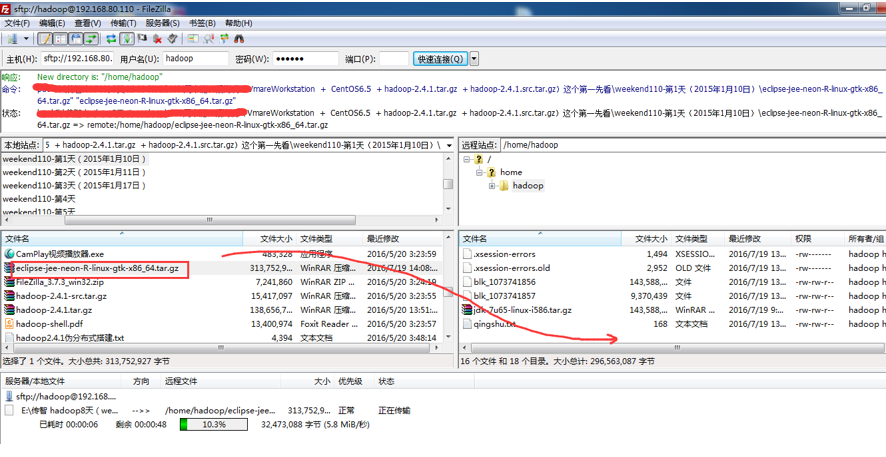
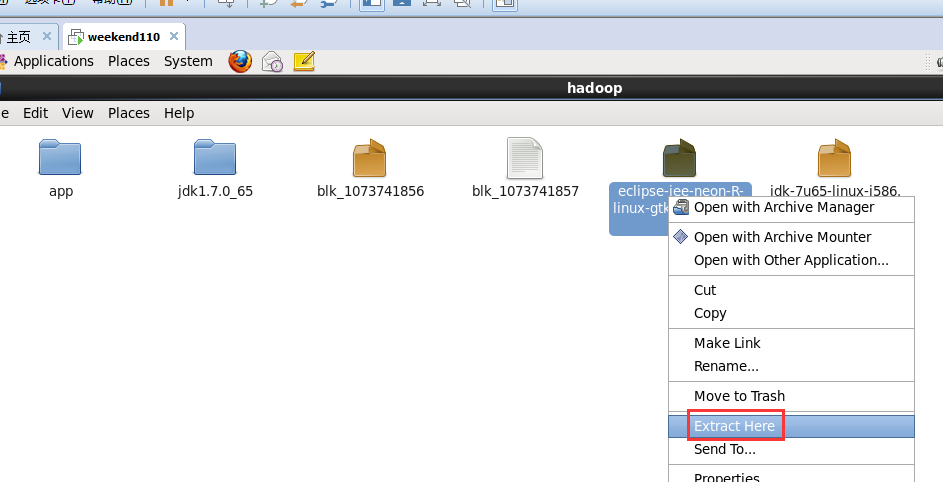

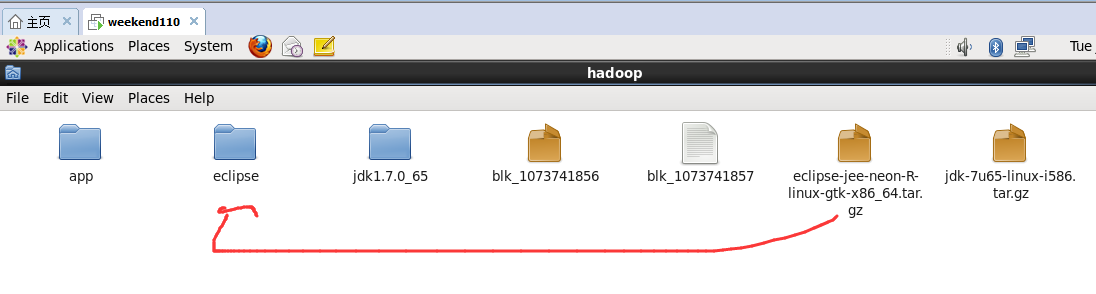

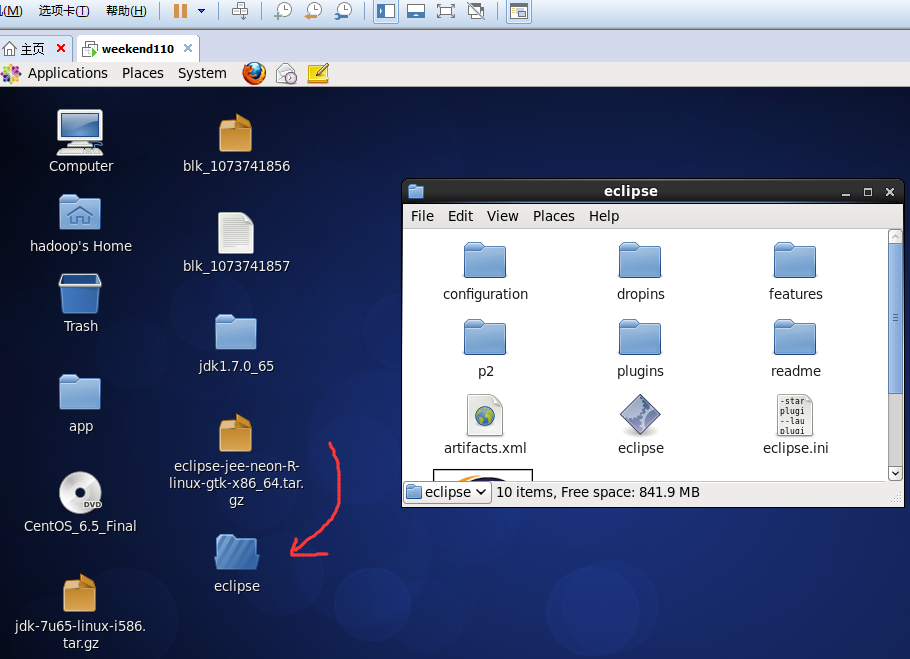
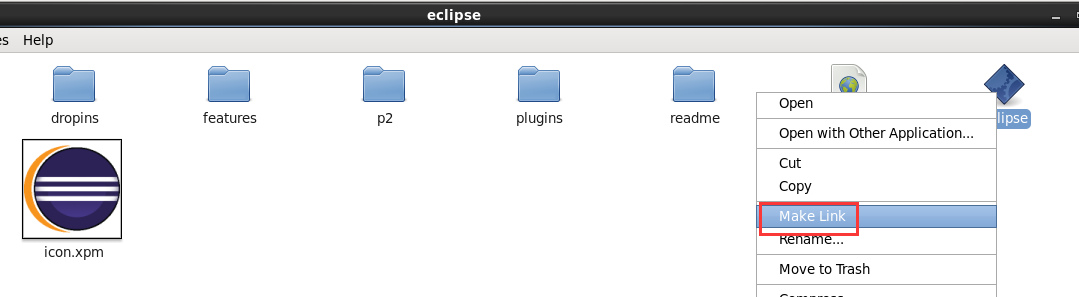
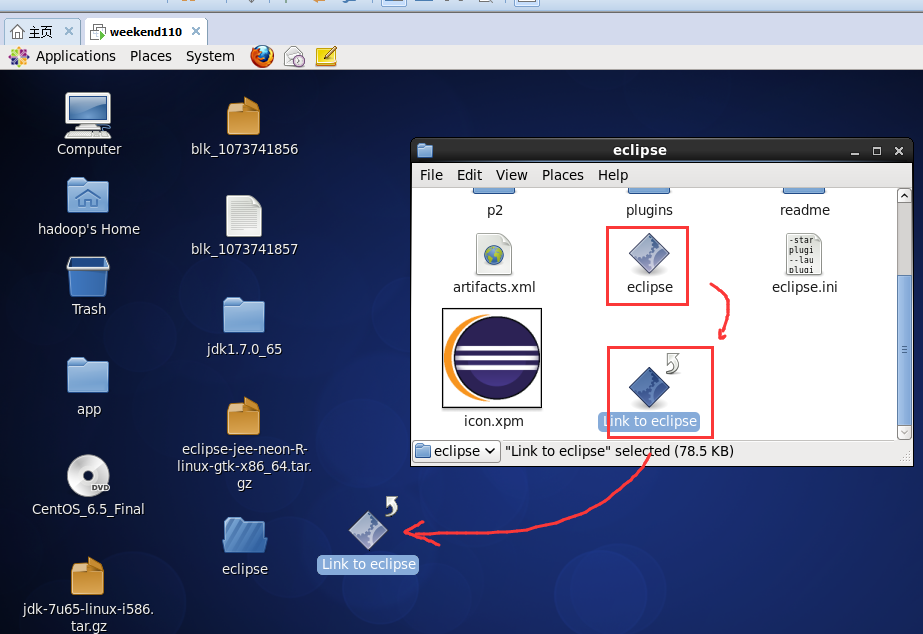
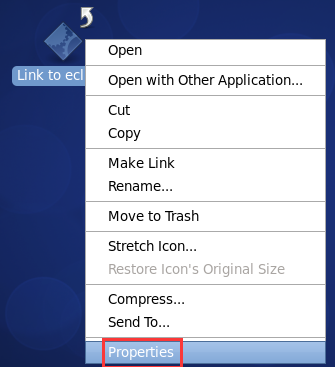
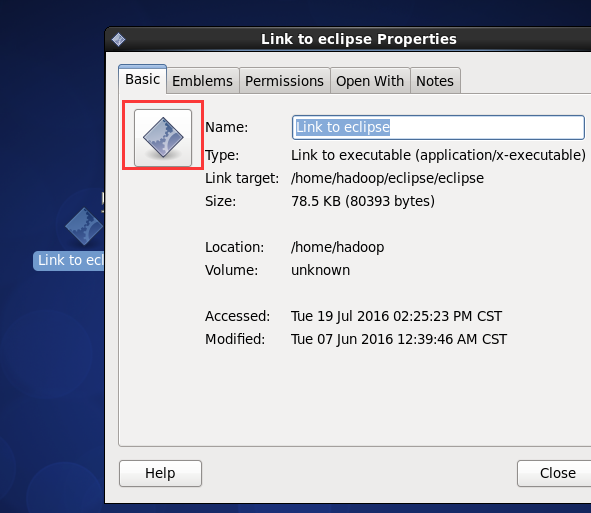

即,更改图标,成功


这个,别慌。重新换个版本就好,有错误出错是好事。
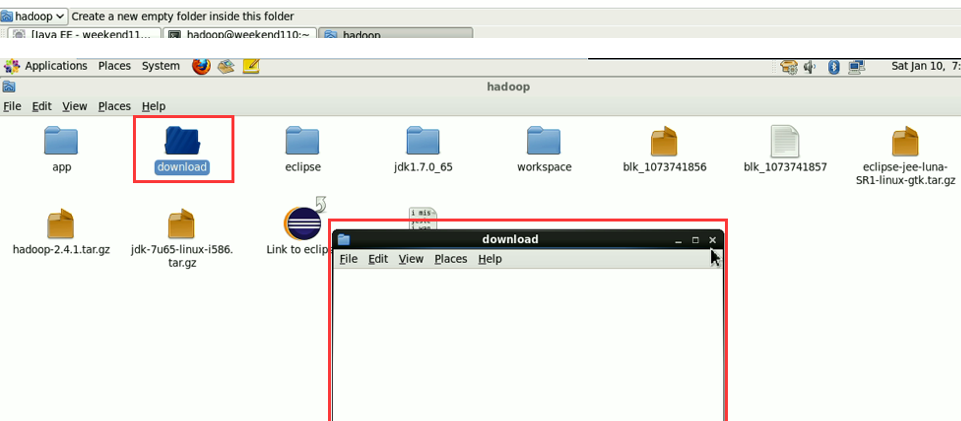
具体如何下载,我就省略了。直接继续



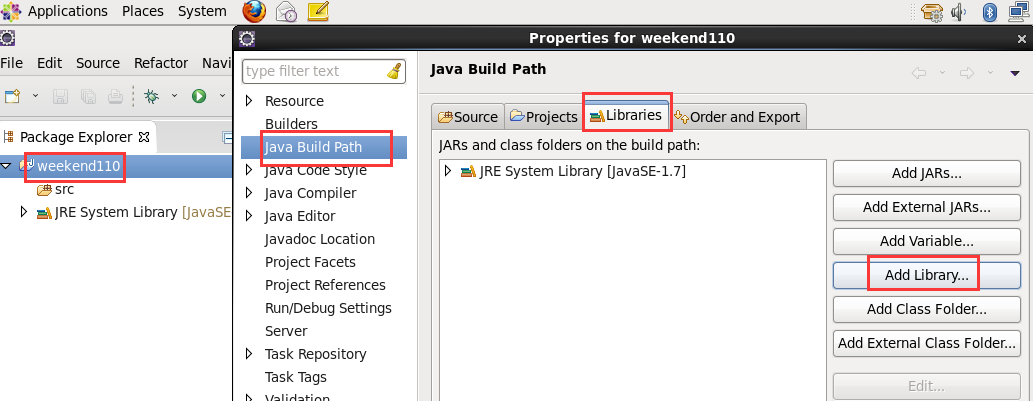

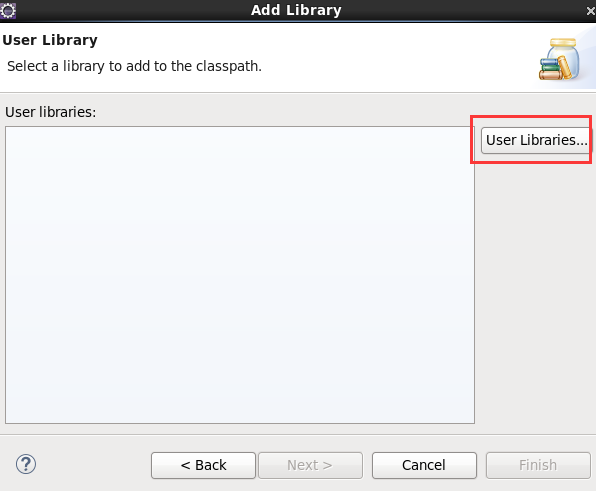
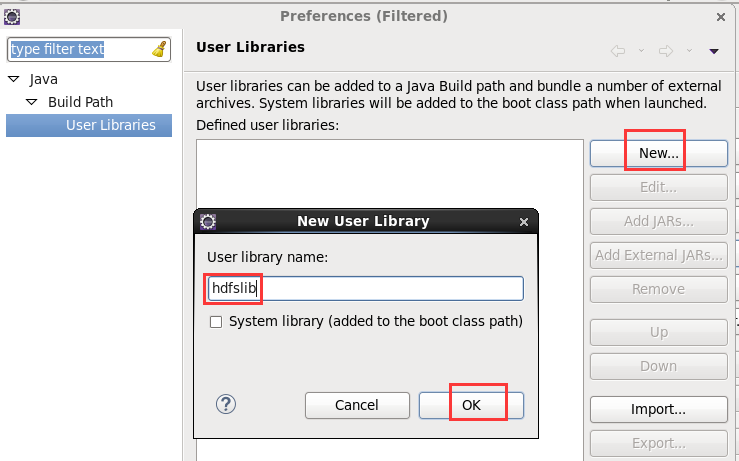
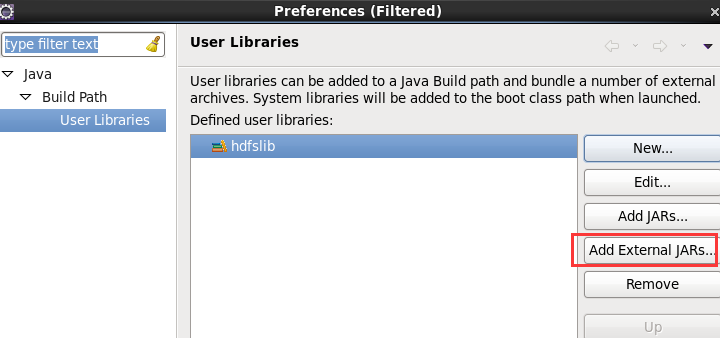


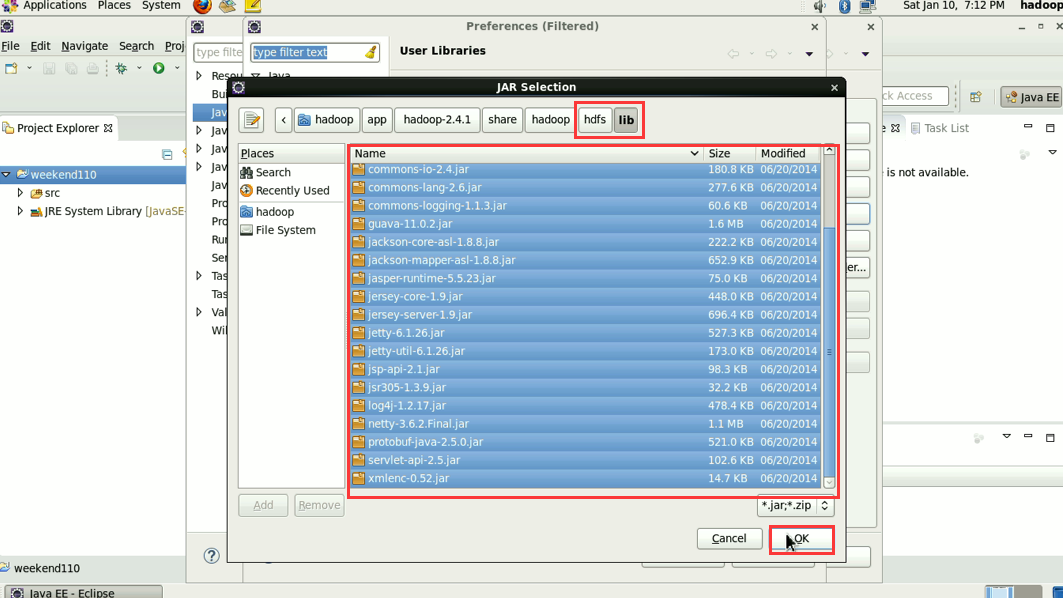
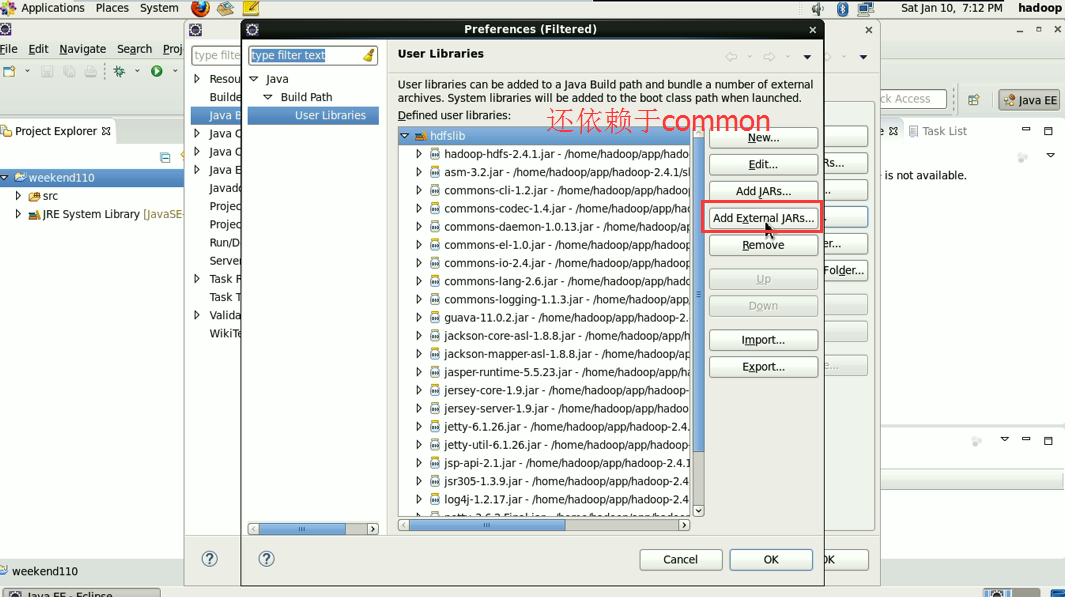
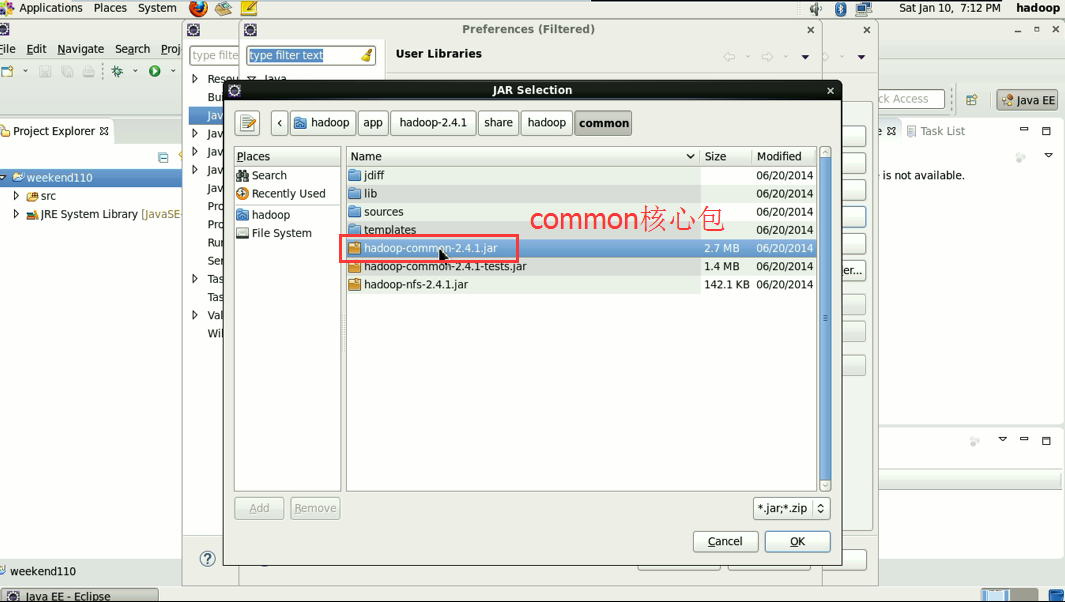
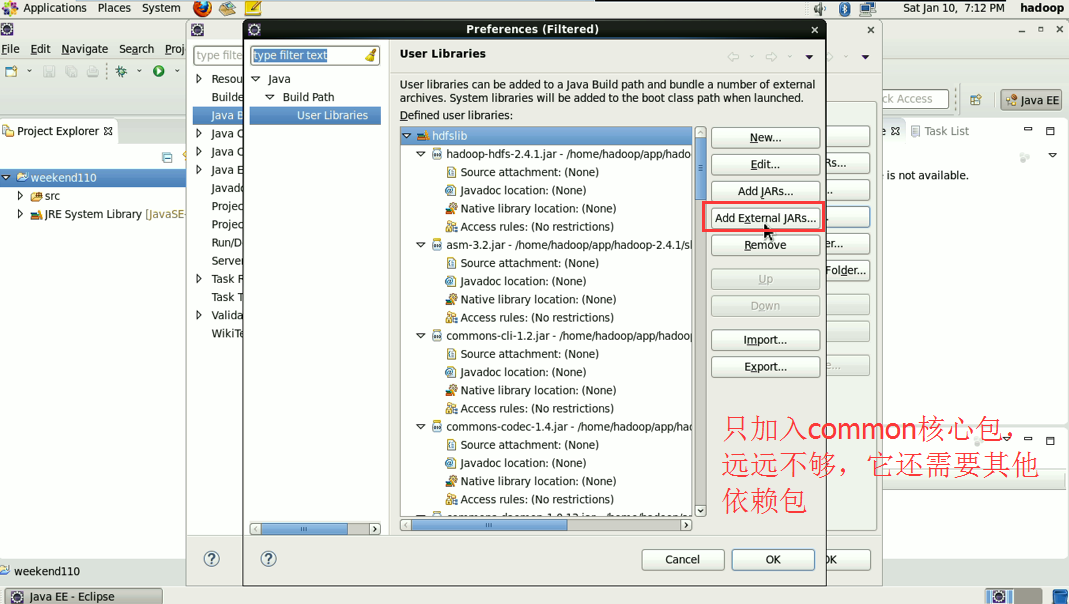

这个,肯定是与之前,有重复的,没关系,它会自行覆盖,
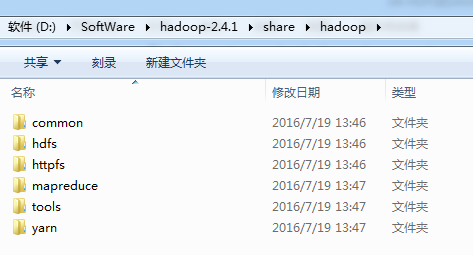
就是说,home/hadoop/app/hadoop-2.4.1/share/hadoop/common/lib
和,home/hadoop/app/hadoop-2.4.1/share/hadoop/hdfs/lib
有重复的,没关系,它会自行覆盖。
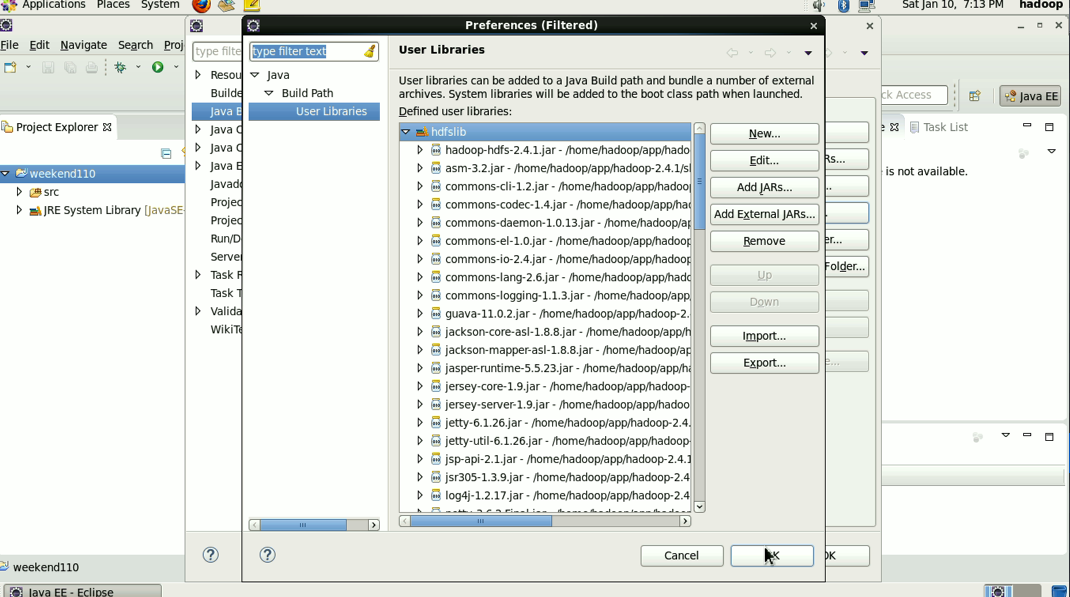
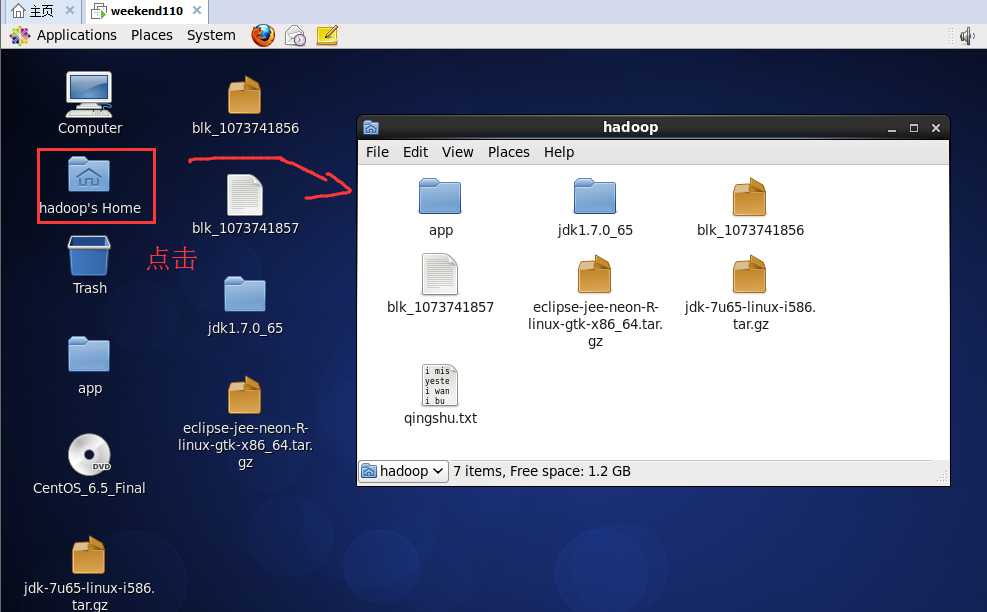
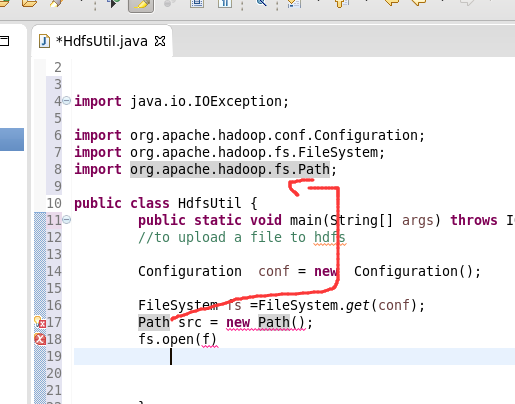
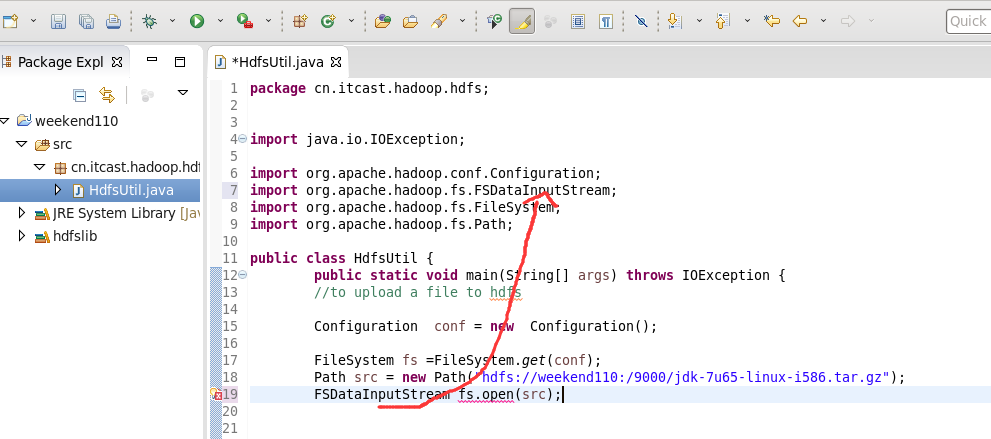
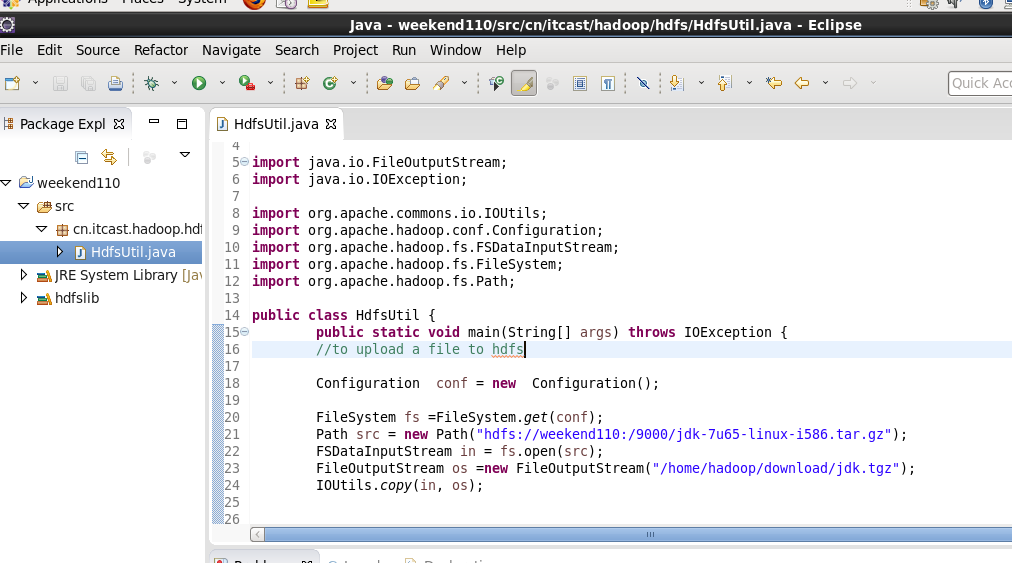
到此,hdfslib下的相关依赖jar包加载完毕。
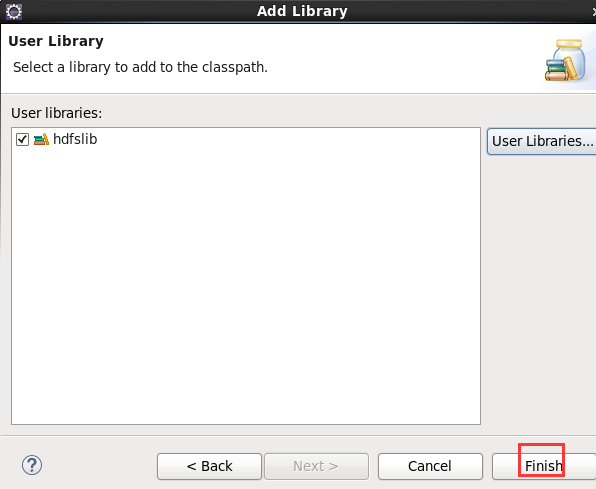
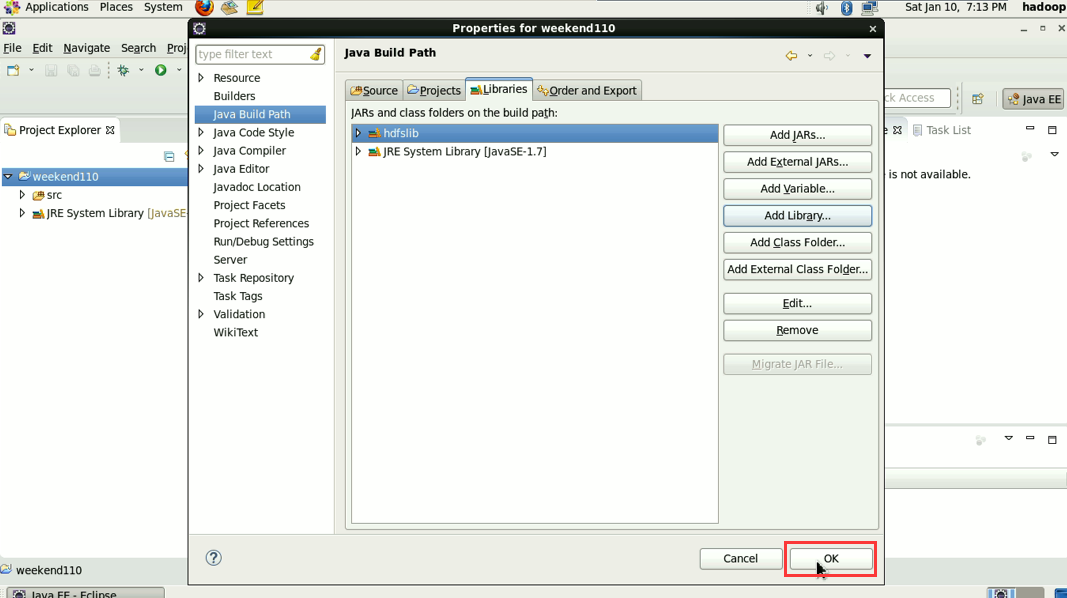
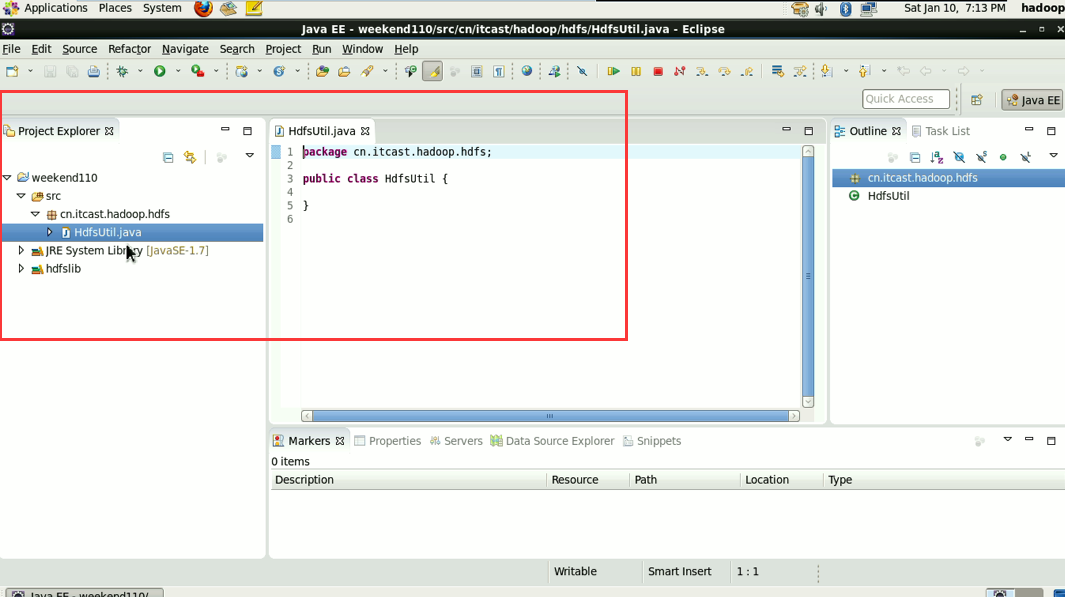



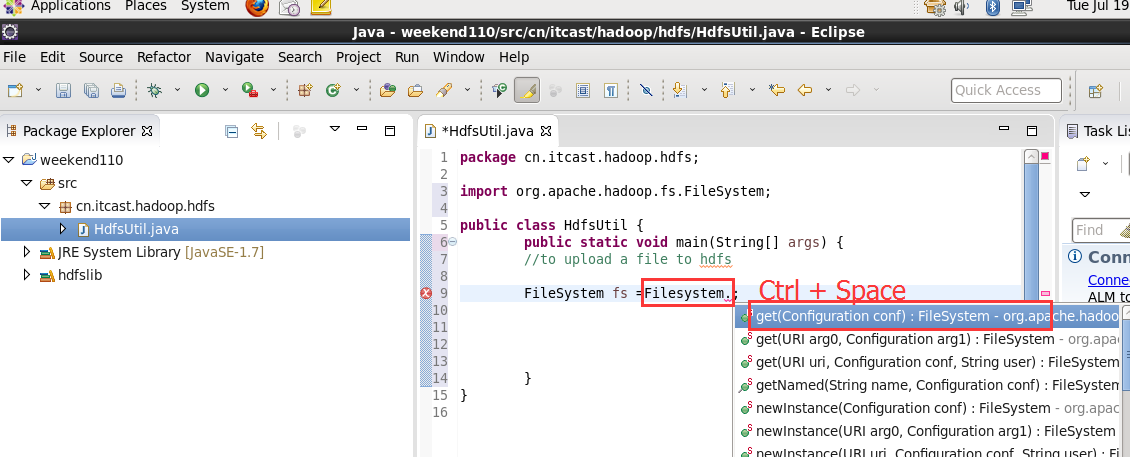
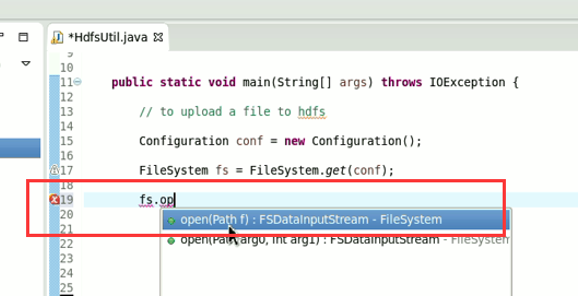
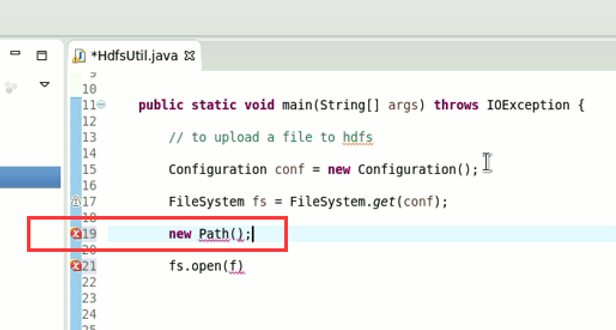
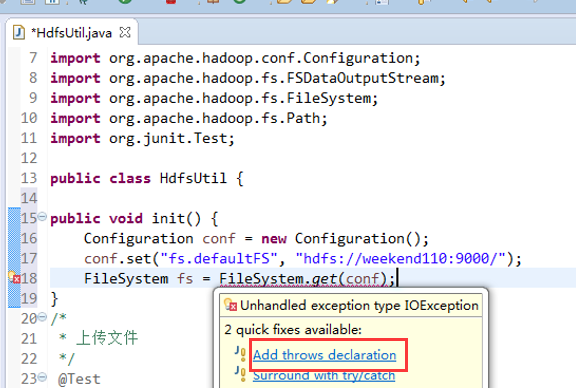
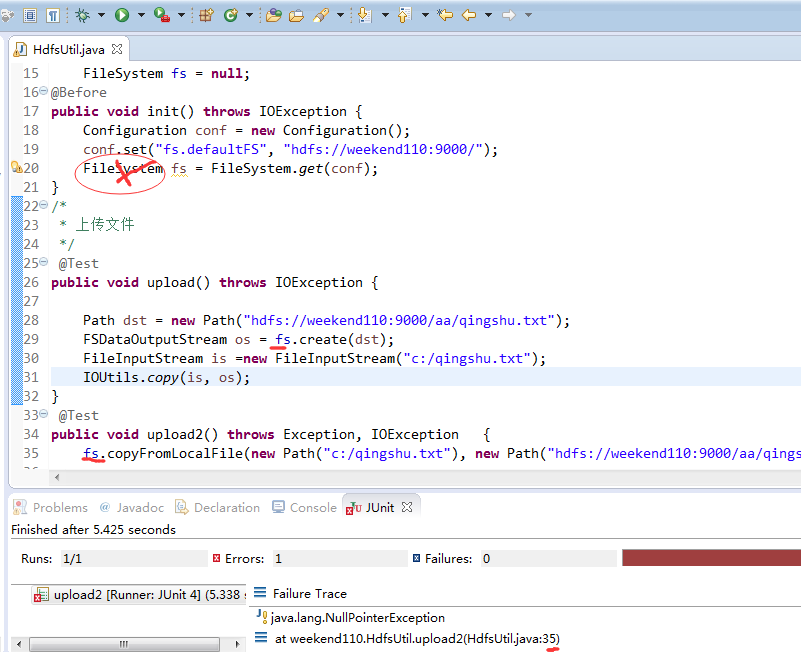
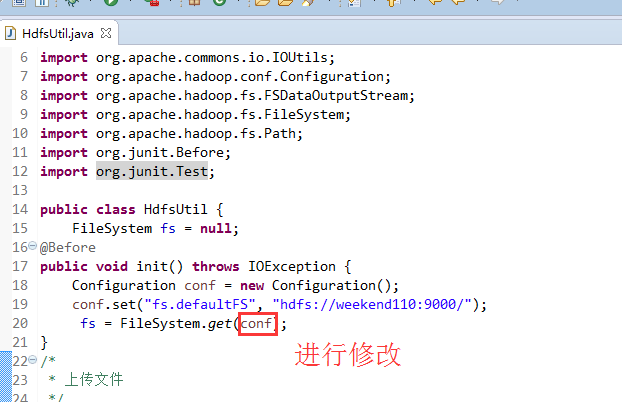
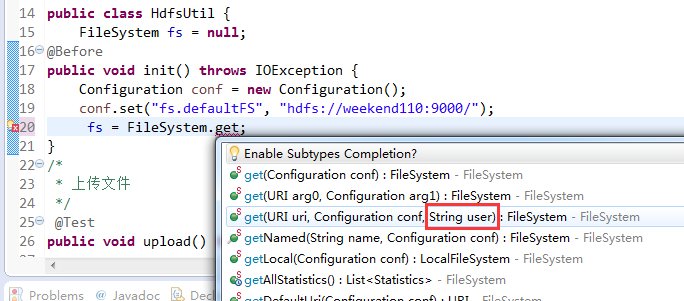
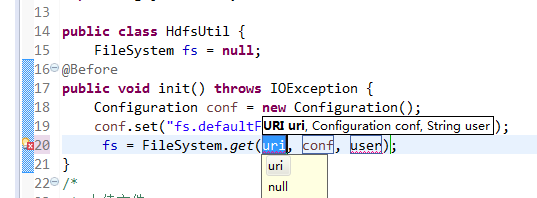
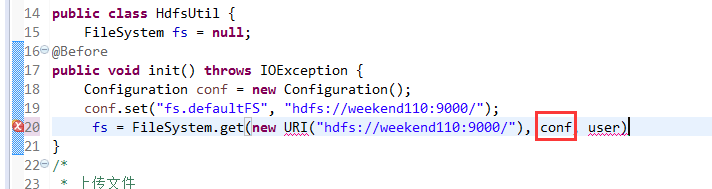
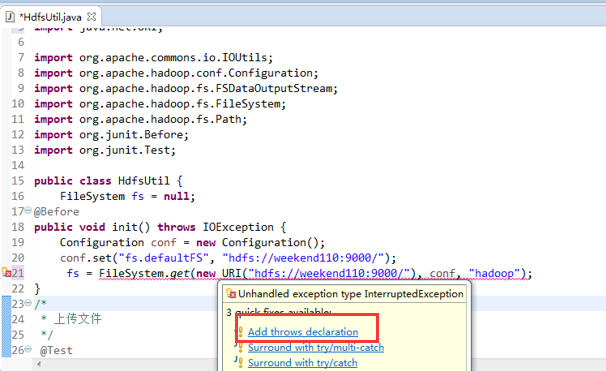
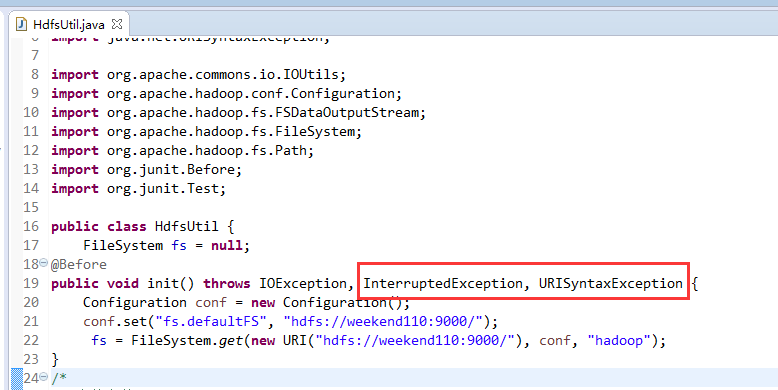
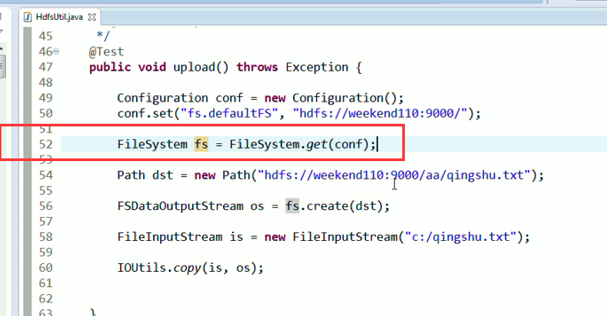
New是无法new的,只能get和set方法

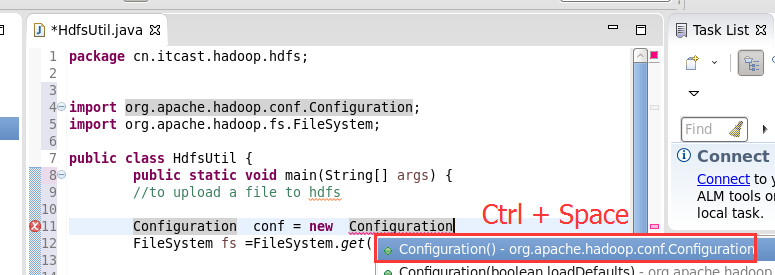
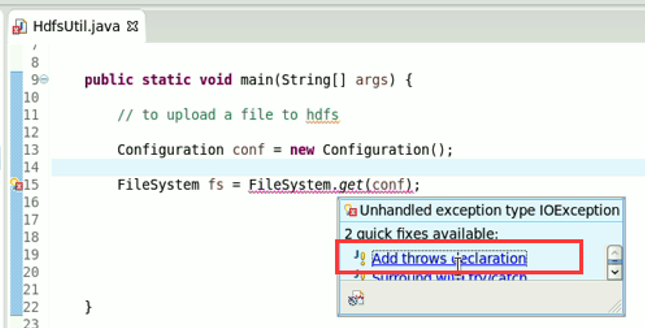
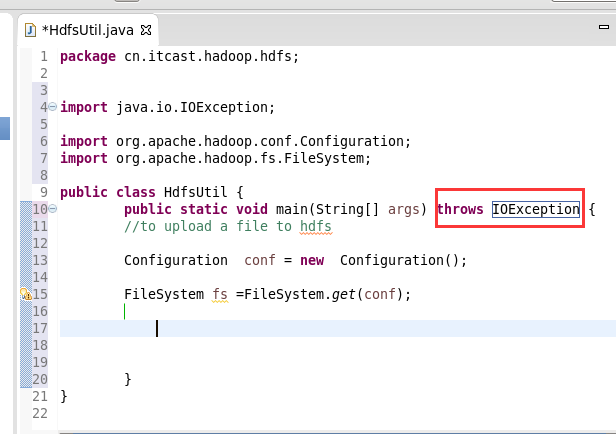
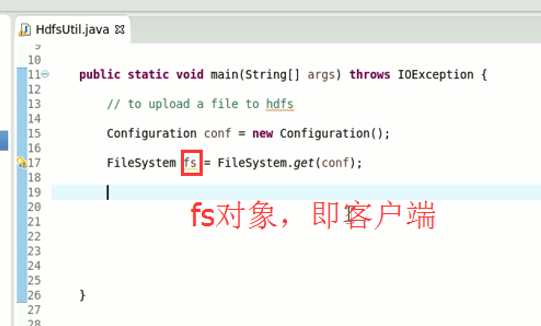



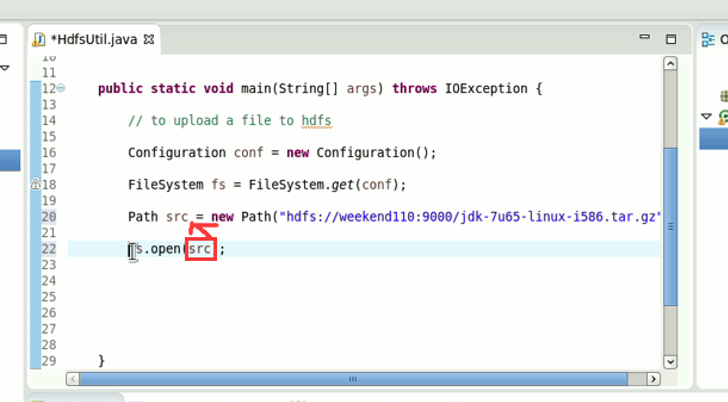
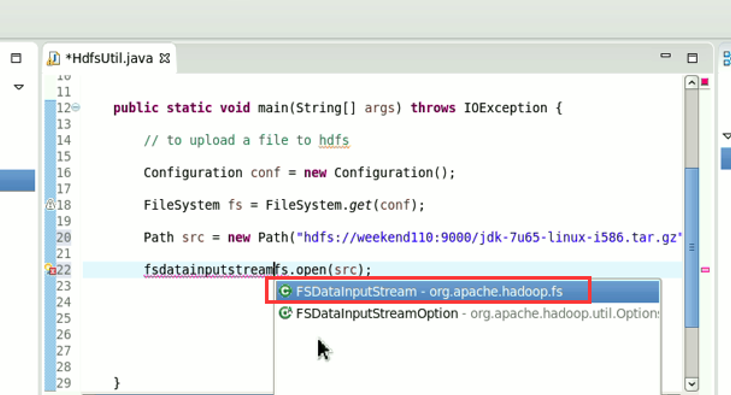
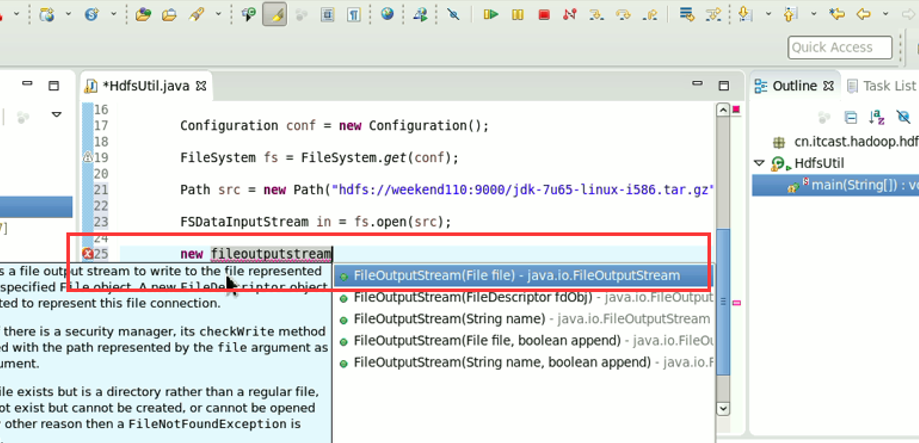
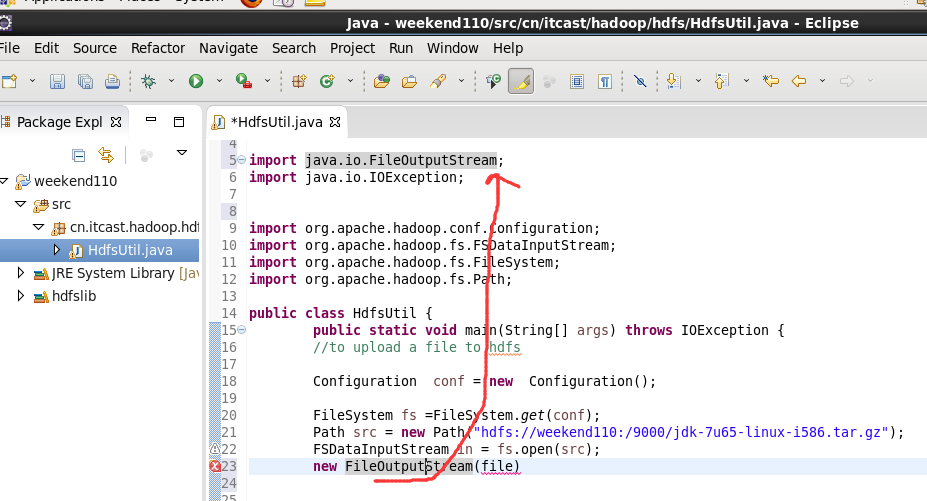
本地,java里的那个fileoutputstream。

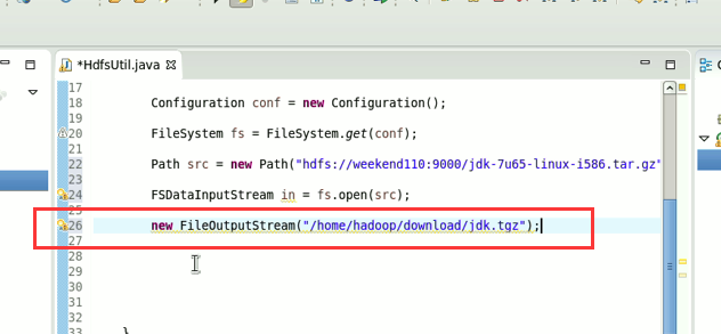


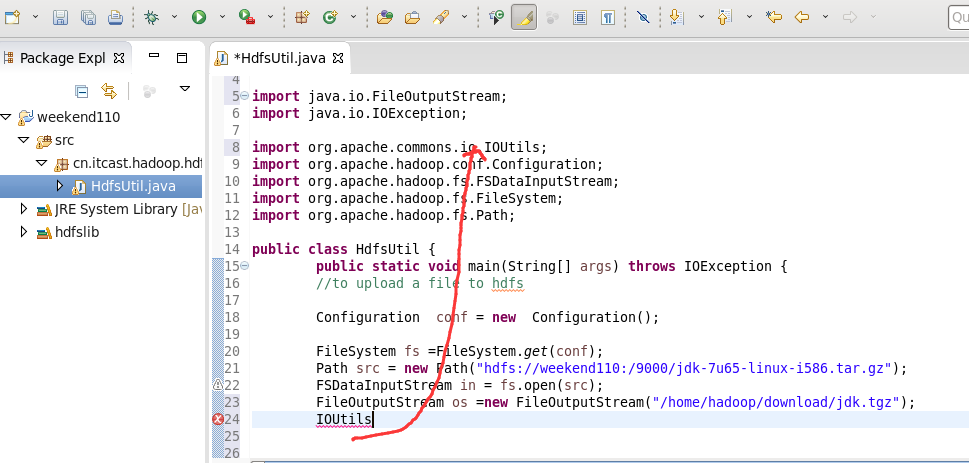
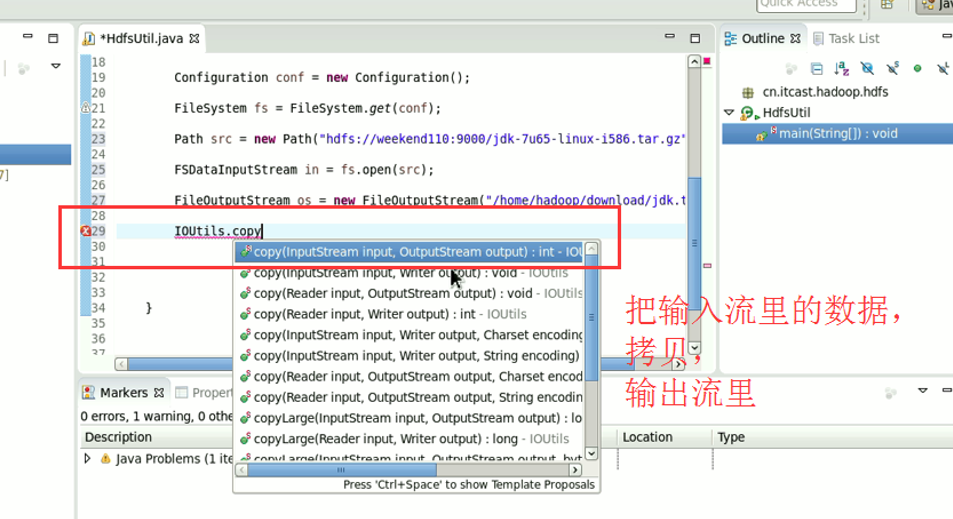
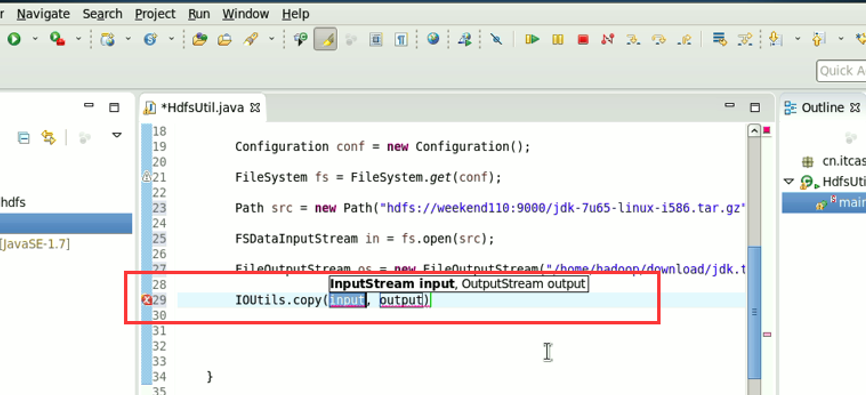




它不认识hdfs://
希望得到,这样的一个解析,file:///




玩windows下的eclipse去。
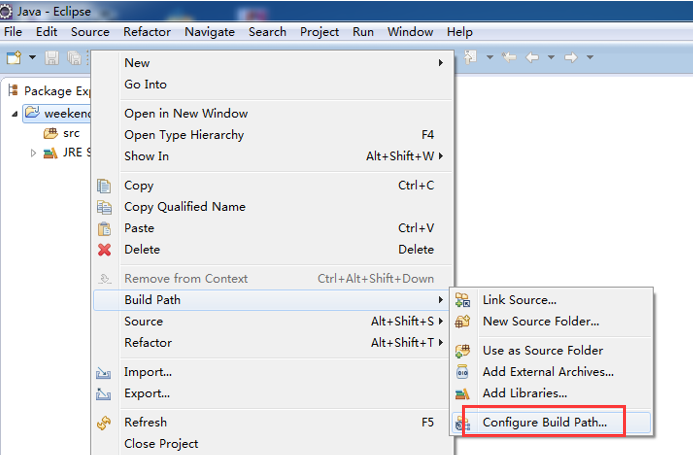
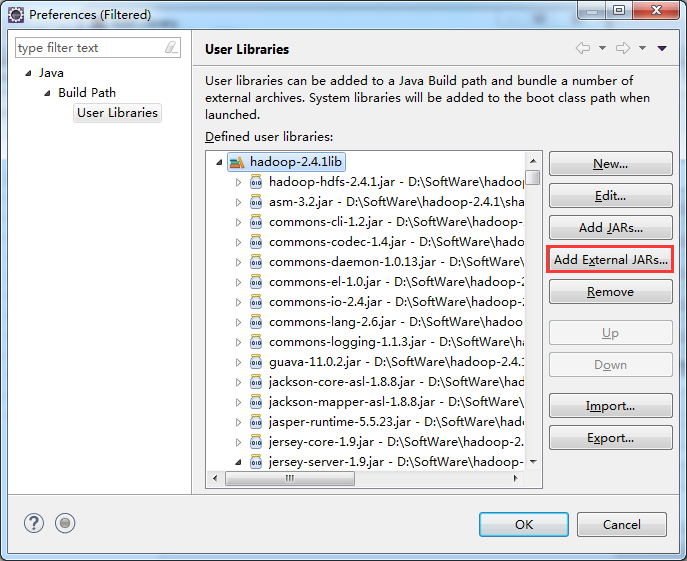
总结:其实,创建User Library,如hdfslib,mapreducelib,yarnlib。

如创建hdfs lib,则需要
/home/hadoop/app/hadoop-2.4.1/share/hadoop/hdfs/*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/hdfs/lib/*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/*
home/hadoop/app/hadoop-2.4.1/share/hadoop/common/lib/*
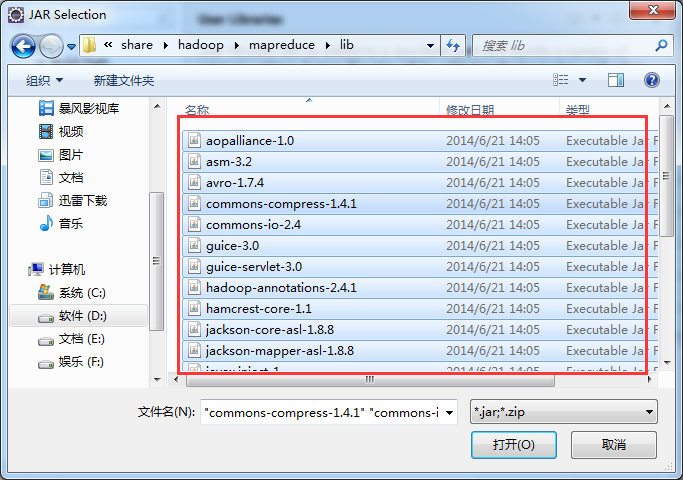
如创建mapreduce lib,则需要
/home/hadoop/app/hadoop-2.4.1/share/hadoop/mapreduce/*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/mapreduce/lib/*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/*
home/hadoop/app/hadoop-2.4.1/share/hadoop/common/lib/*
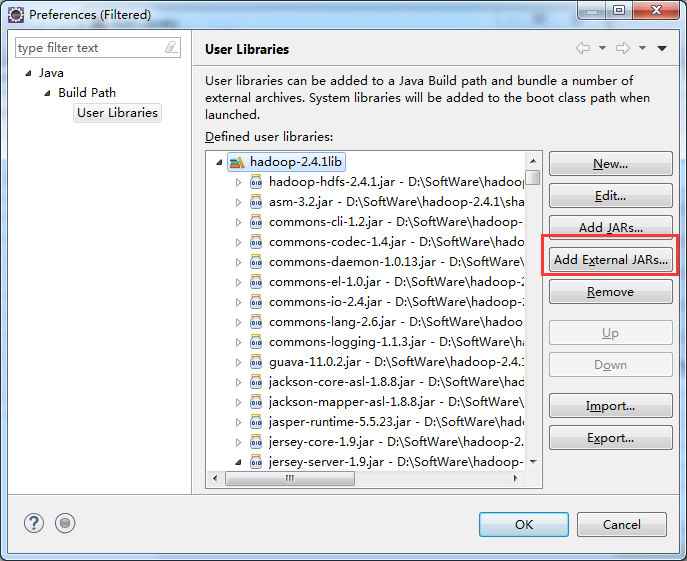
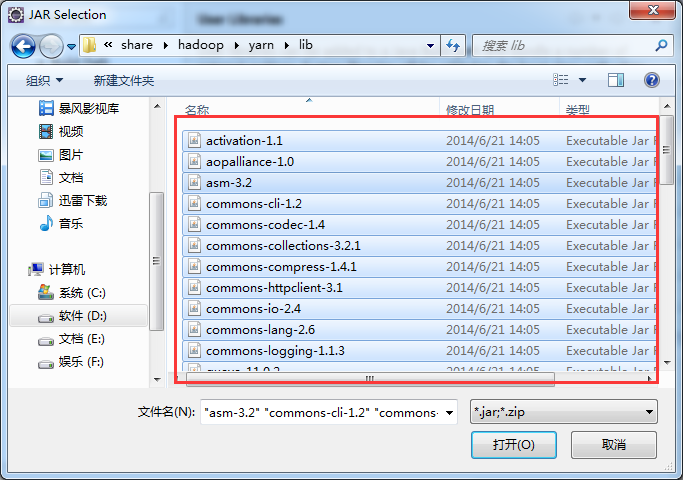
如创建yarn lib,则需要
/home/hadoop/app/hadoop-2.4.1/share/hadoop/yarn/*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/yarn/lib/*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/*
home/hadoop/app/hadoop-2.4.1/share/hadoop/common/lib/*
如创建httpfslib,则需要
/home/hadoop/app/hadoop-2.4.1/share/hadoop/httpfs/tomcat/lib*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/*
home/hadoop/app/hadoop-2.4.1/share/hadoop/common/lib/*
如创建toolslib,则需要
/home/hadoop/app/hadoop-2.4.1/share/hadoop/tools/lib*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/*
home/hadoop/app/hadoop-2.4.1/share/hadoop/common/lib/*
会有重复的,但是,没关系,自己会覆盖。!!!
当然,这只是为了具体分析,在生产中,都是直接导入总包。


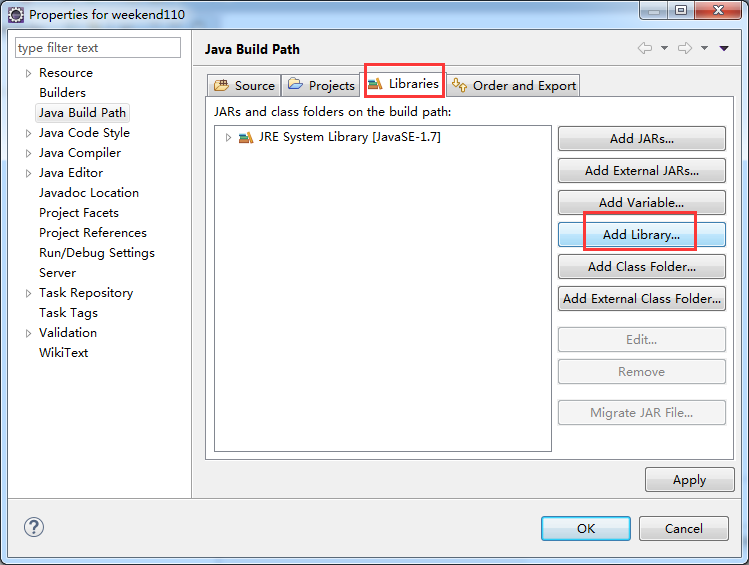

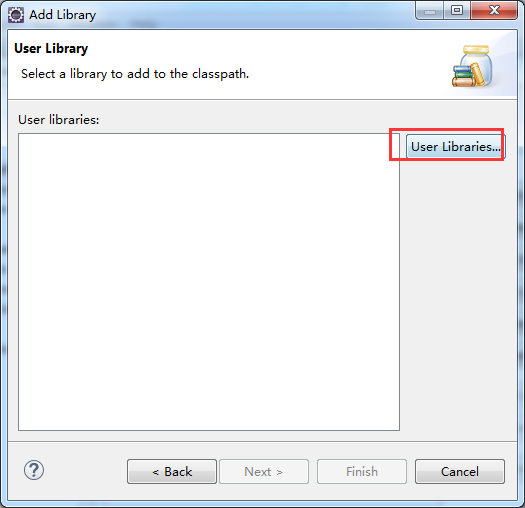
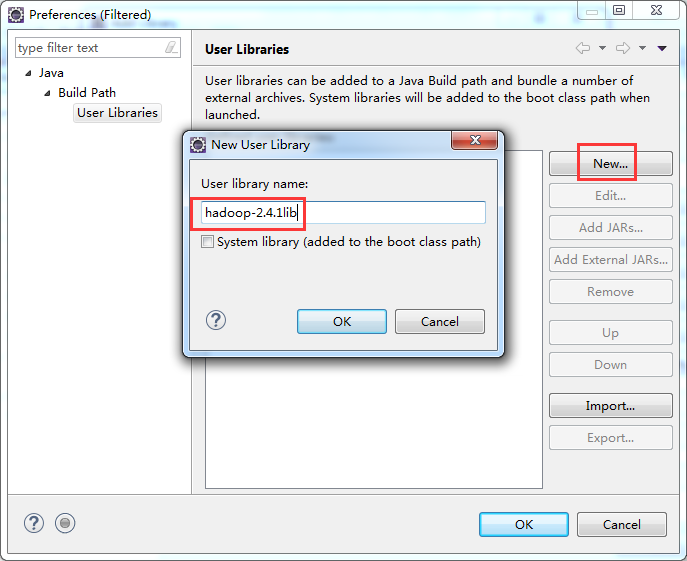
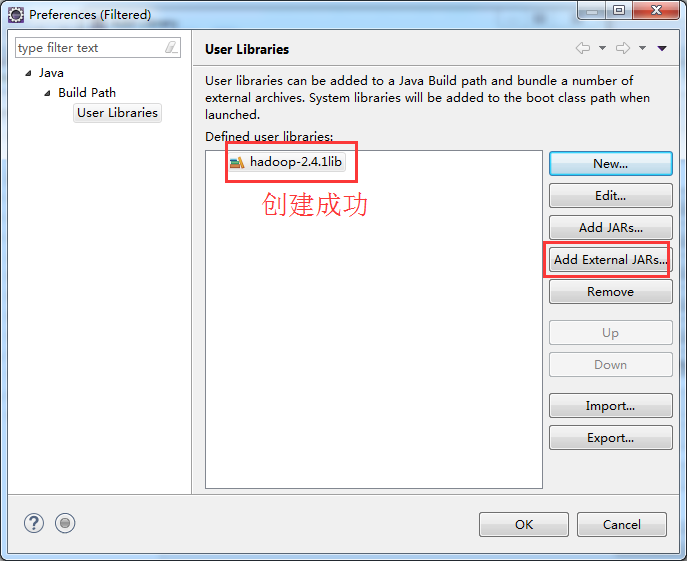



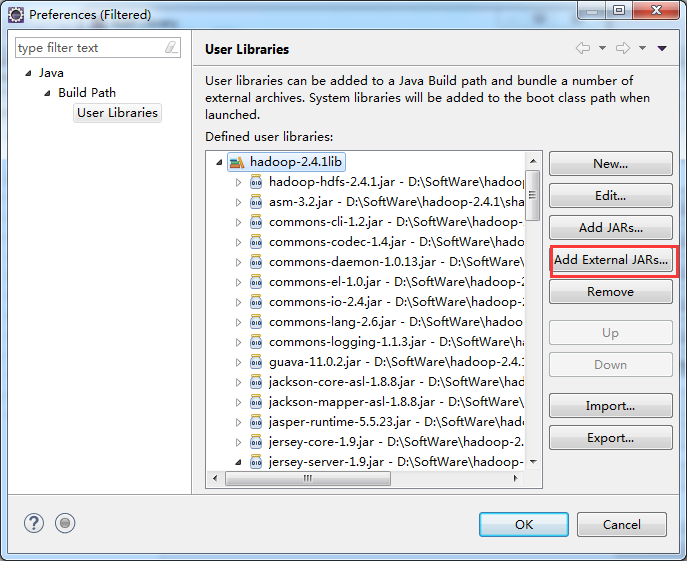

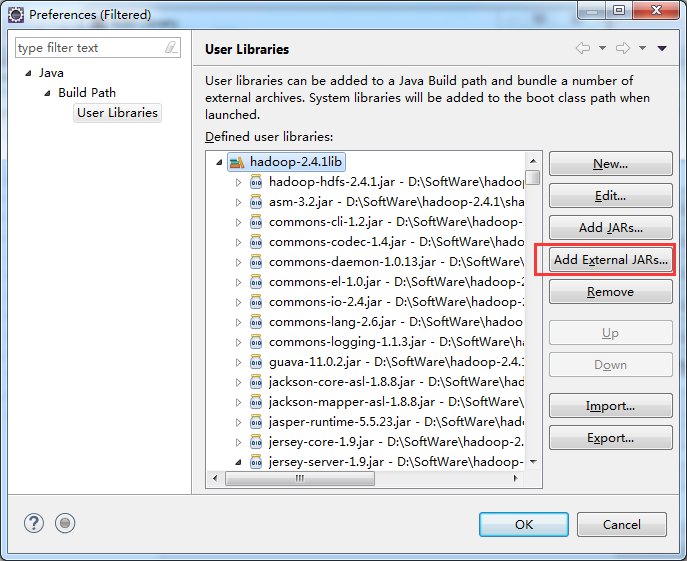
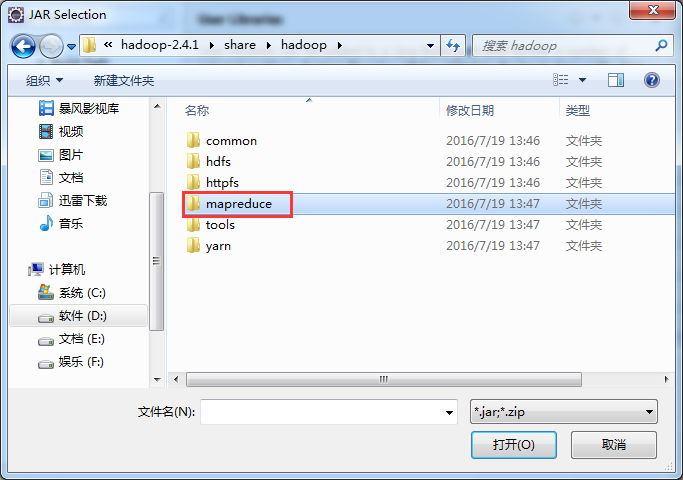
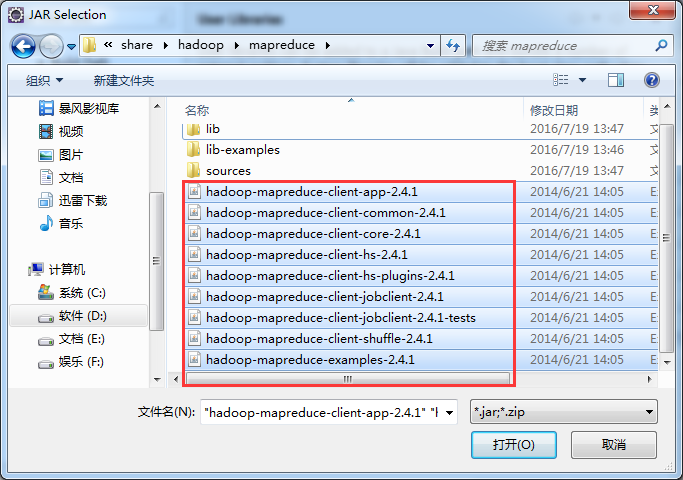



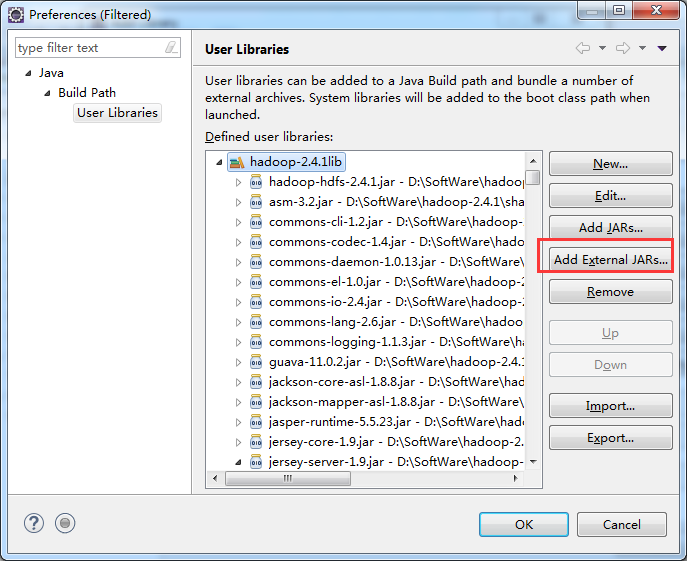
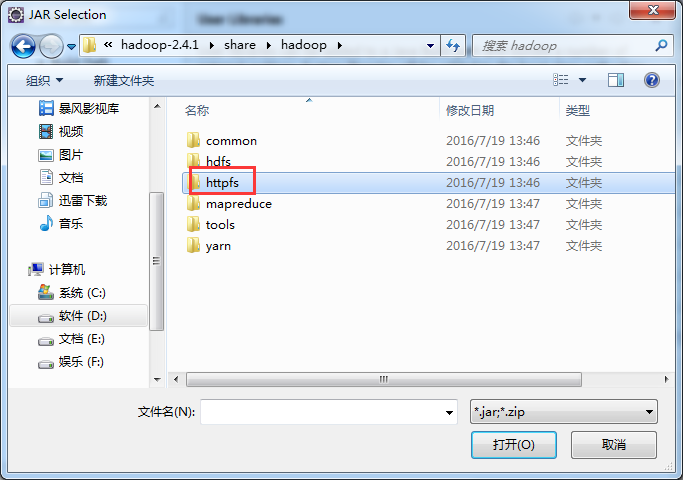
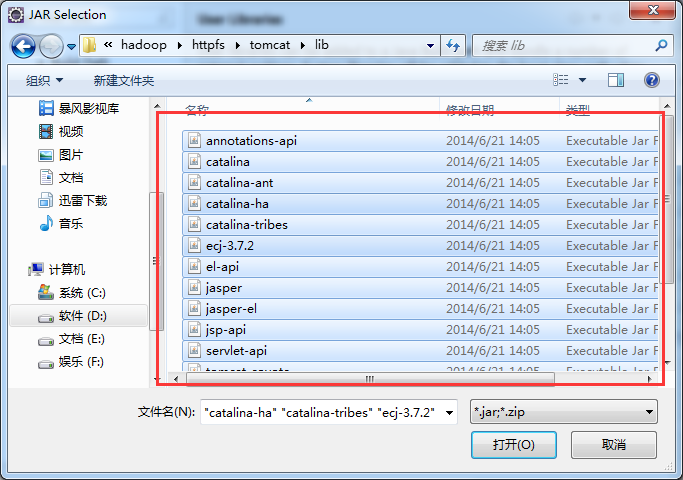

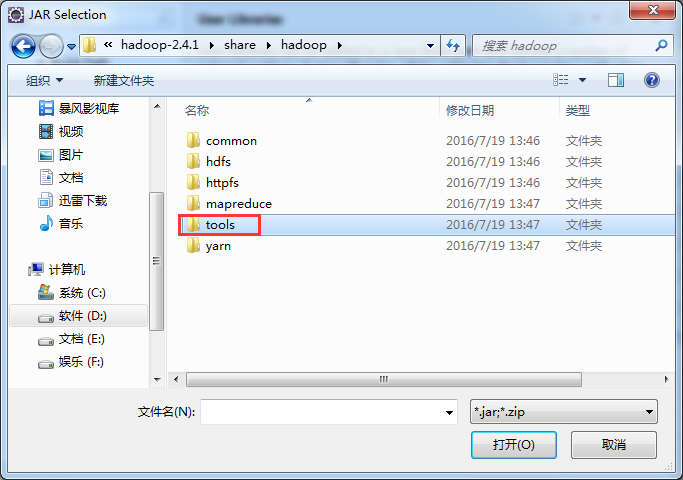
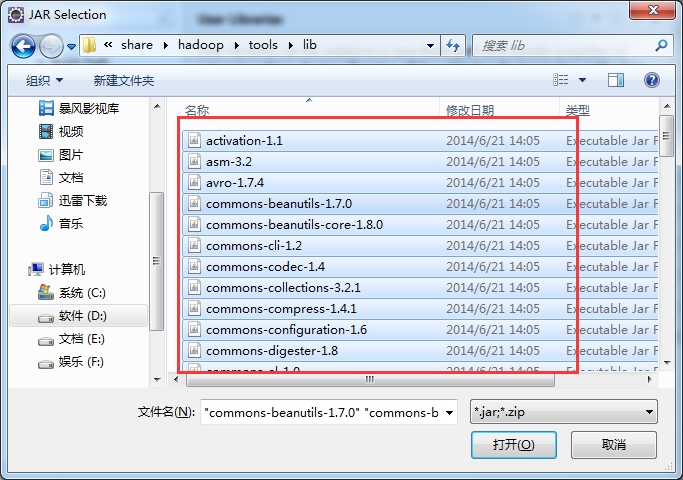
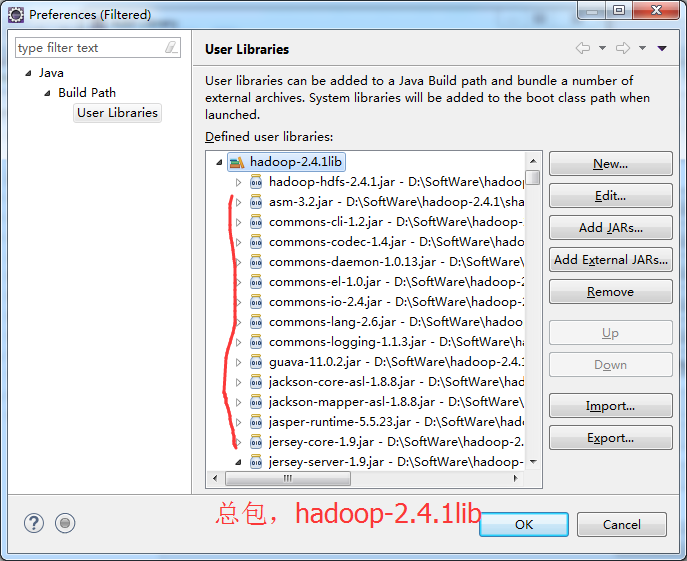
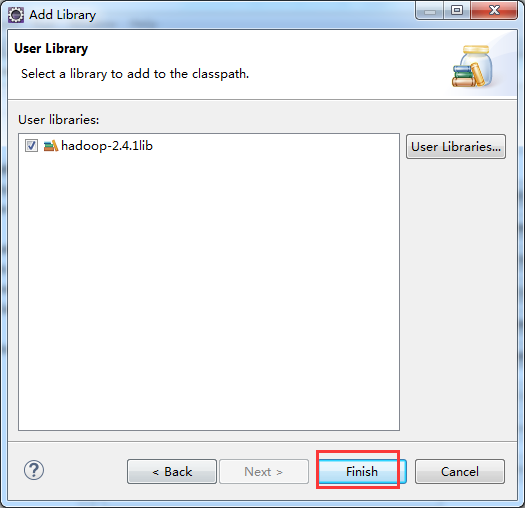


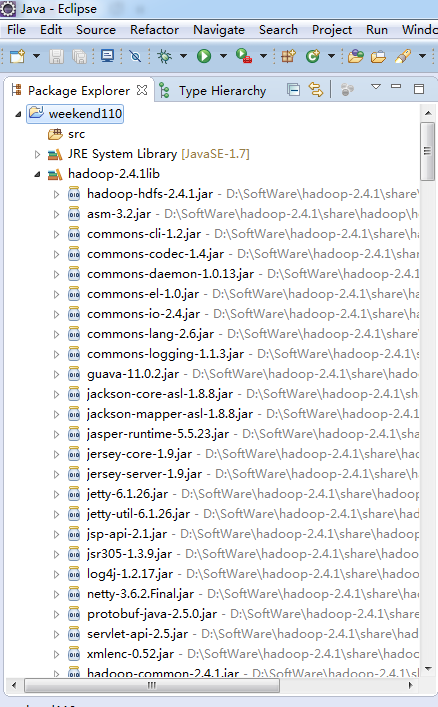
如创建hdfslib,则需要
/home/hadoop/app/hadoop-2.4.1/share/hadoop/hdfs/*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/hdfs/lib/*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/*
home/hadoop/app/hadoop-2.4.1/share/hadoop/common/lib/*
如创建mapreducelib,则需要
/home/hadoop/app/hadoop-2.4.1/share/hadoop/mapreduce/*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/mapreduce/lib/*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/lib/*
如创建yarnlib,则需要
/home/hadoop/app/hadoop-2.4.1/share/hadoop/yarn/*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/yarn/lib/*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/*
home/hadoop/app/hadoop-2.4.1/share/hadoop/common/lib/*
如创建httpfslib,则需要
/home/hadoop/app/hadoop-2.4.1/share/hadoop/httpfs/tomcat/lib*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/*
home/hadoop/app/hadoop-2.4.1/share/hadoop/common/lib/*
如创建toolslib,则需要
/home/hadoop/app/hadoop-2.4.1/share/hadoop/tools/lib*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/*
/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/lib/*
会有重复的,但是,没关系,自己会覆盖。
当然,这只是为了具体分析,在生产中,都是直接导入总包。



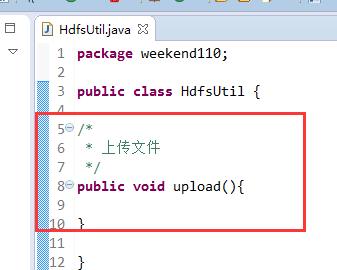
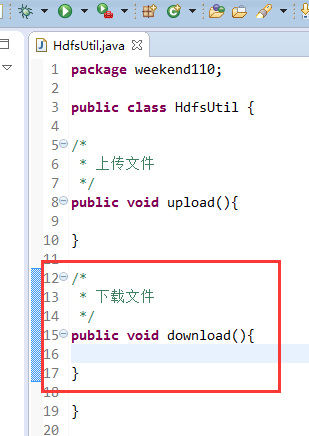
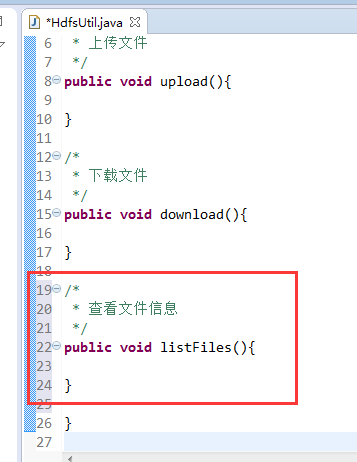

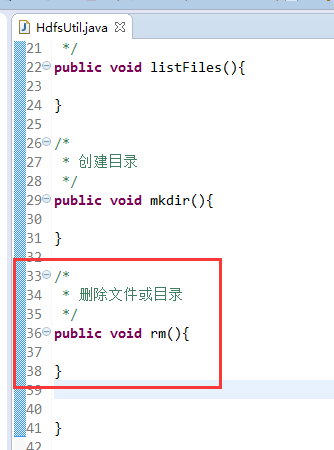
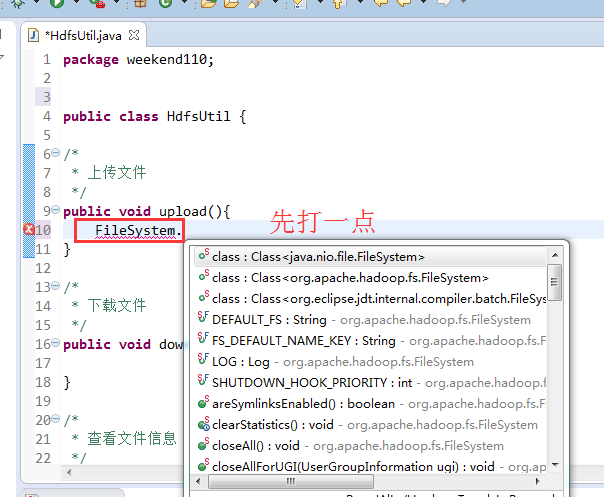
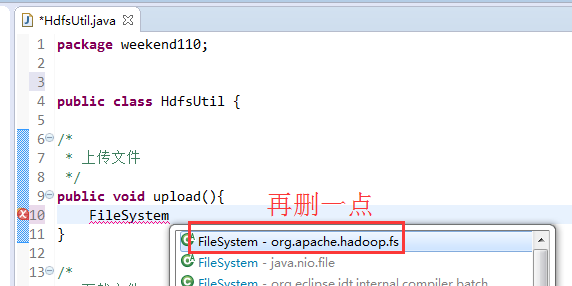
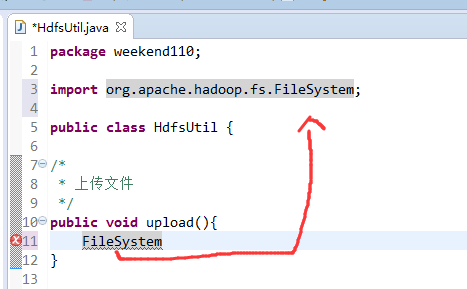
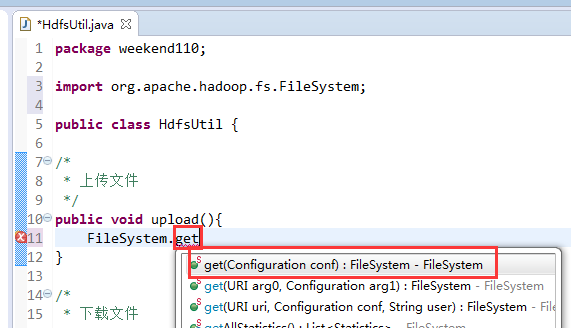

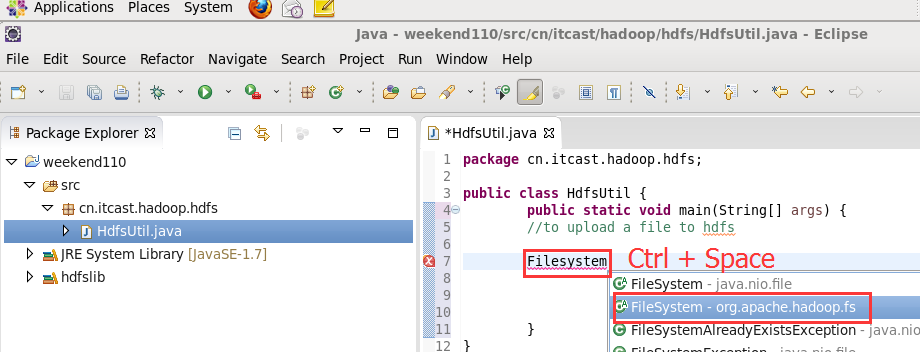
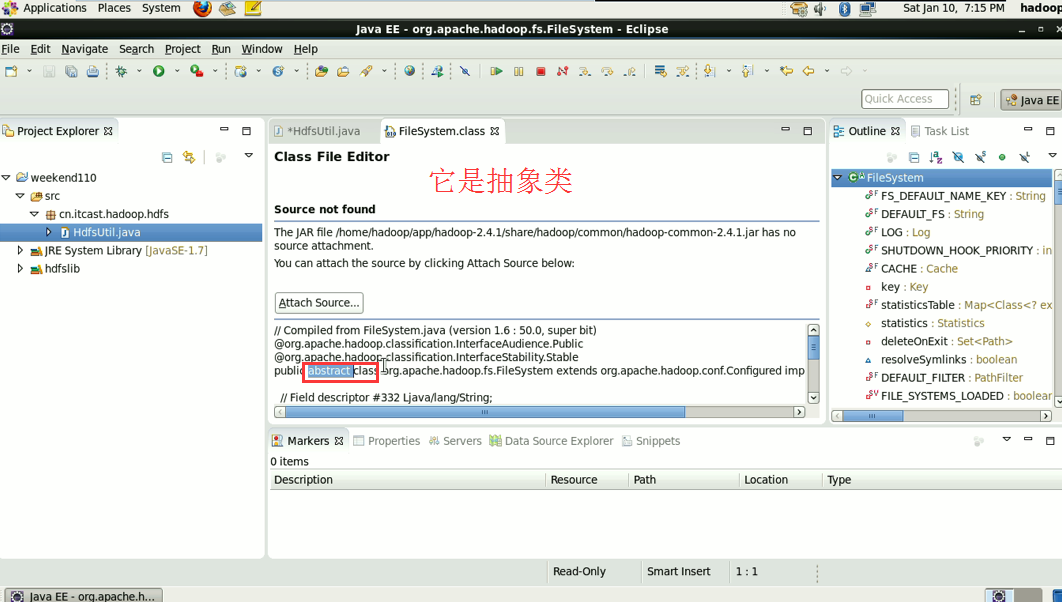
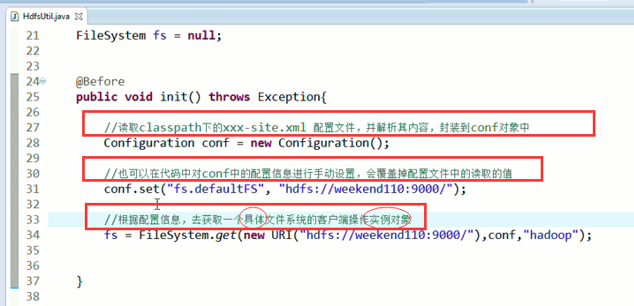
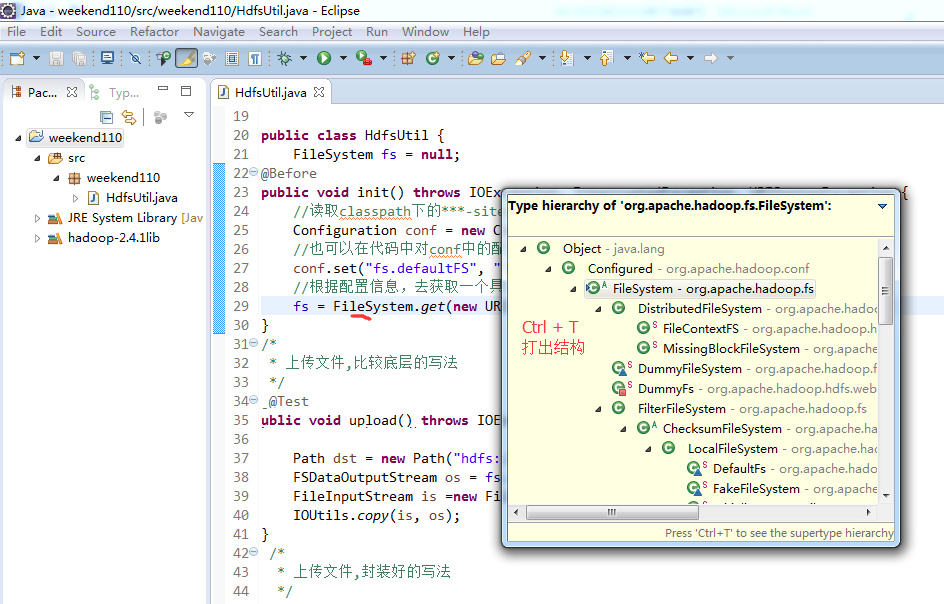
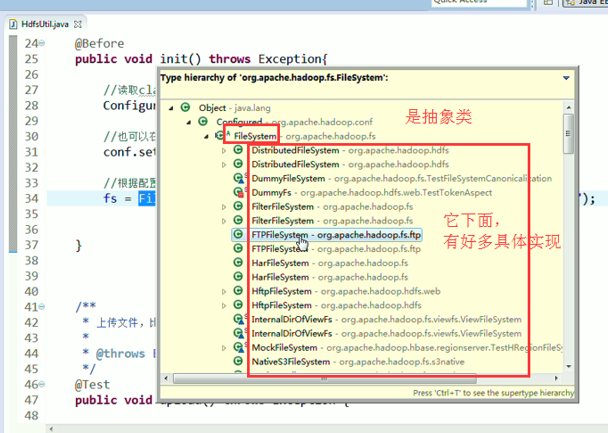
FileSystem是一个抽象类,New是无法new的,只能get和set方法
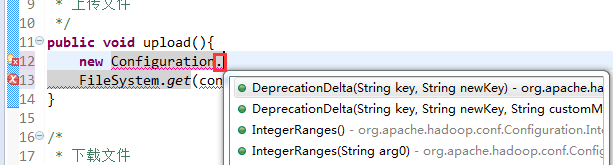
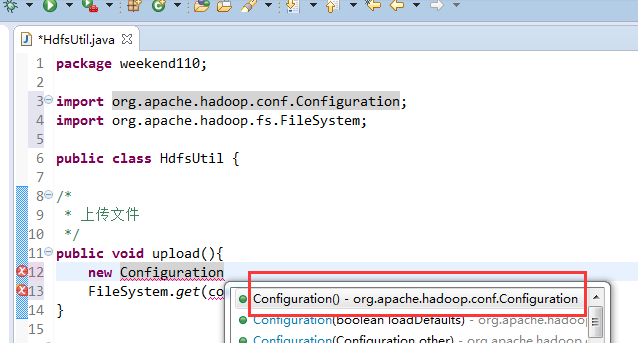
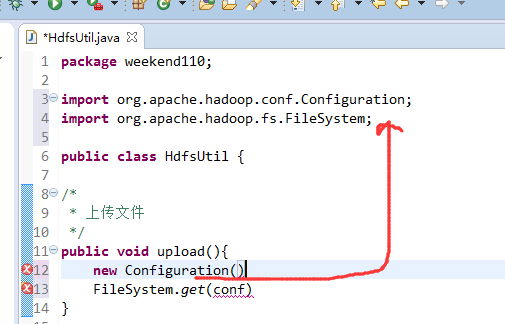

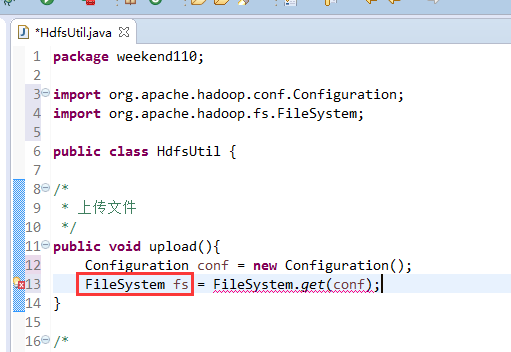

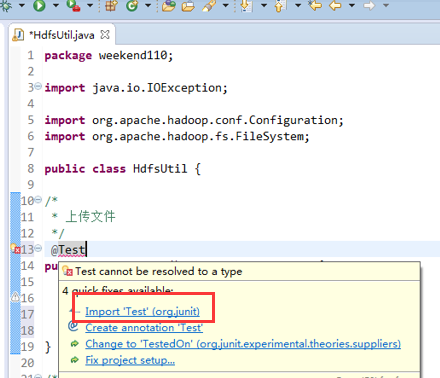
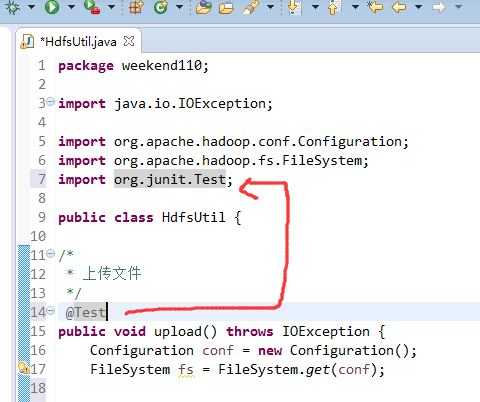

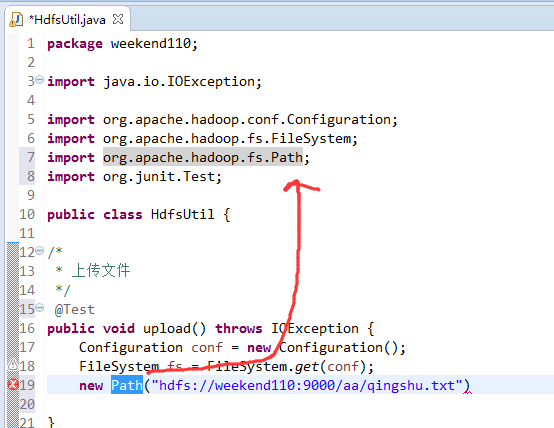
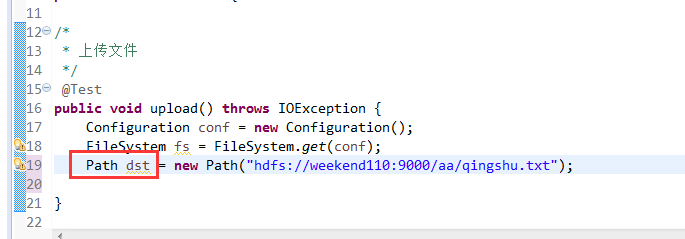
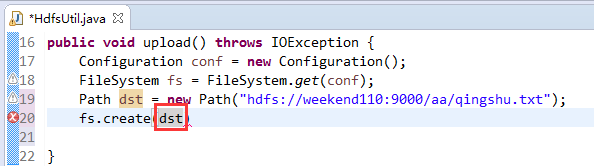
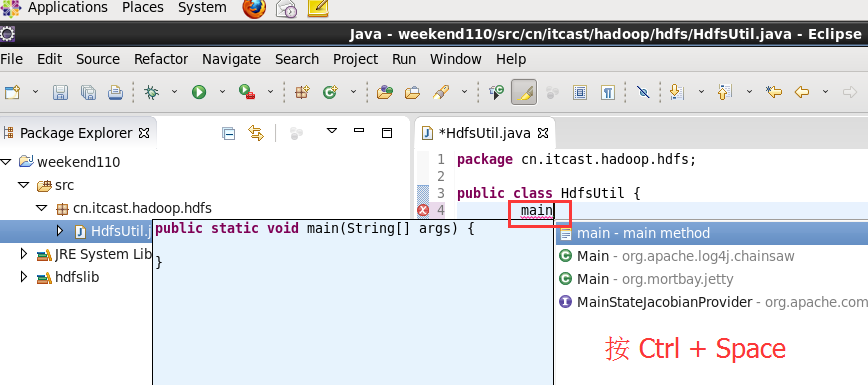
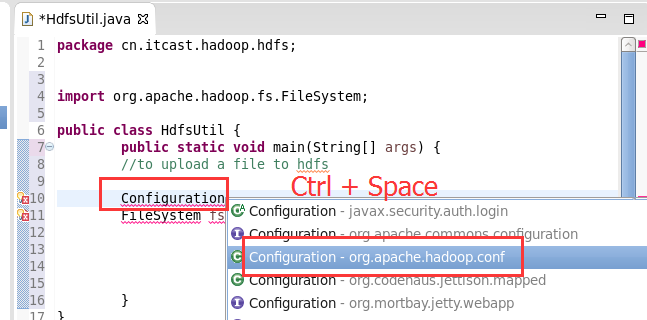
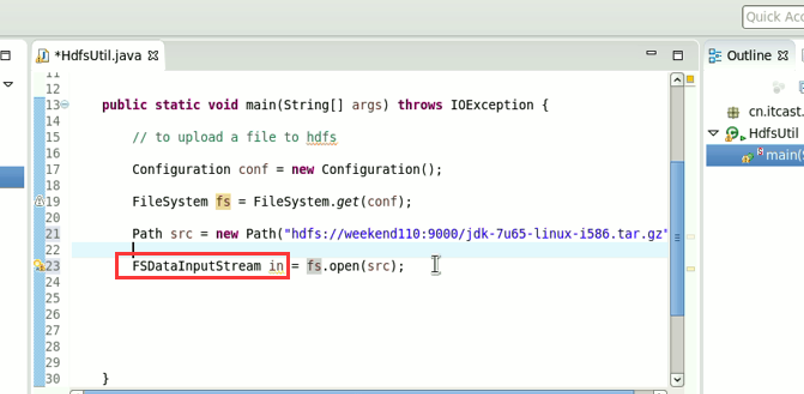
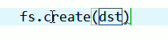
这里,有个非常实用的快捷键,
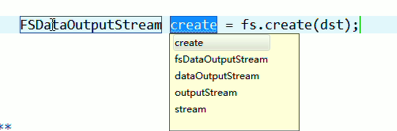
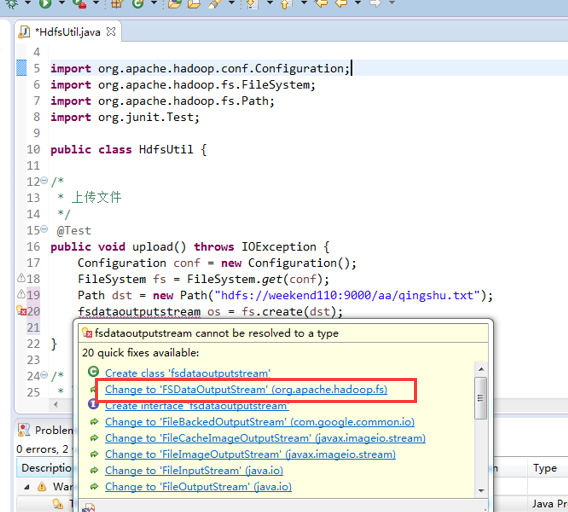


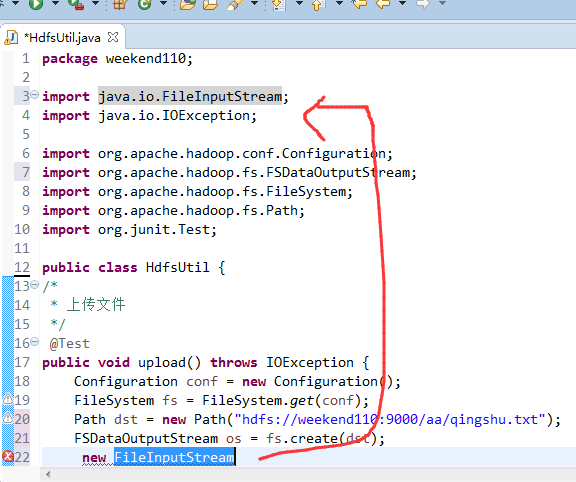
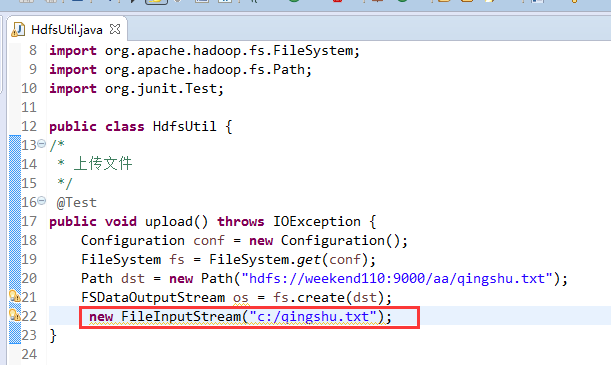

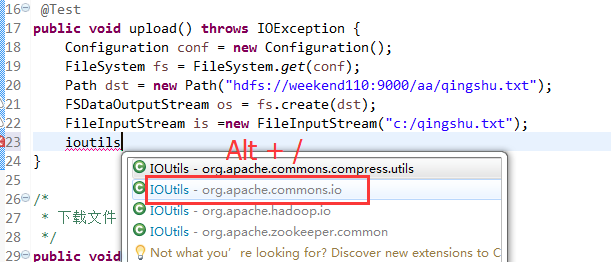
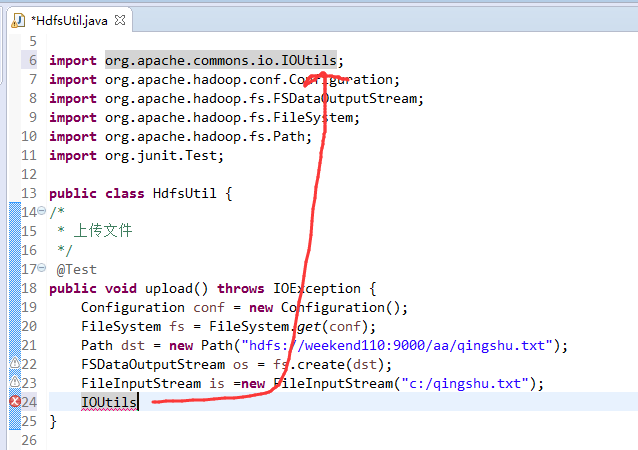
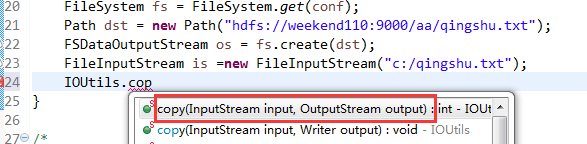
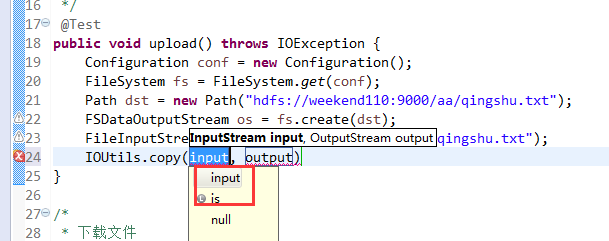
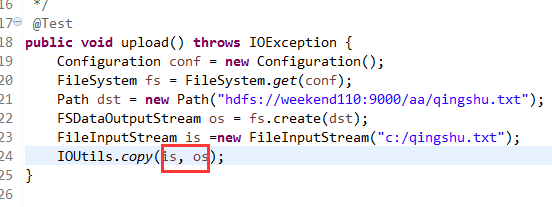

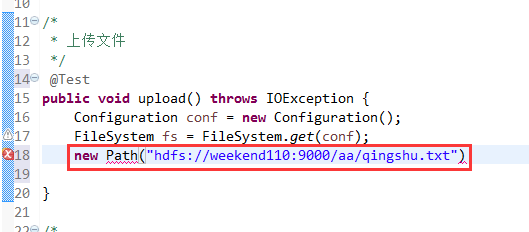
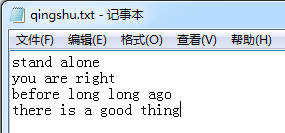
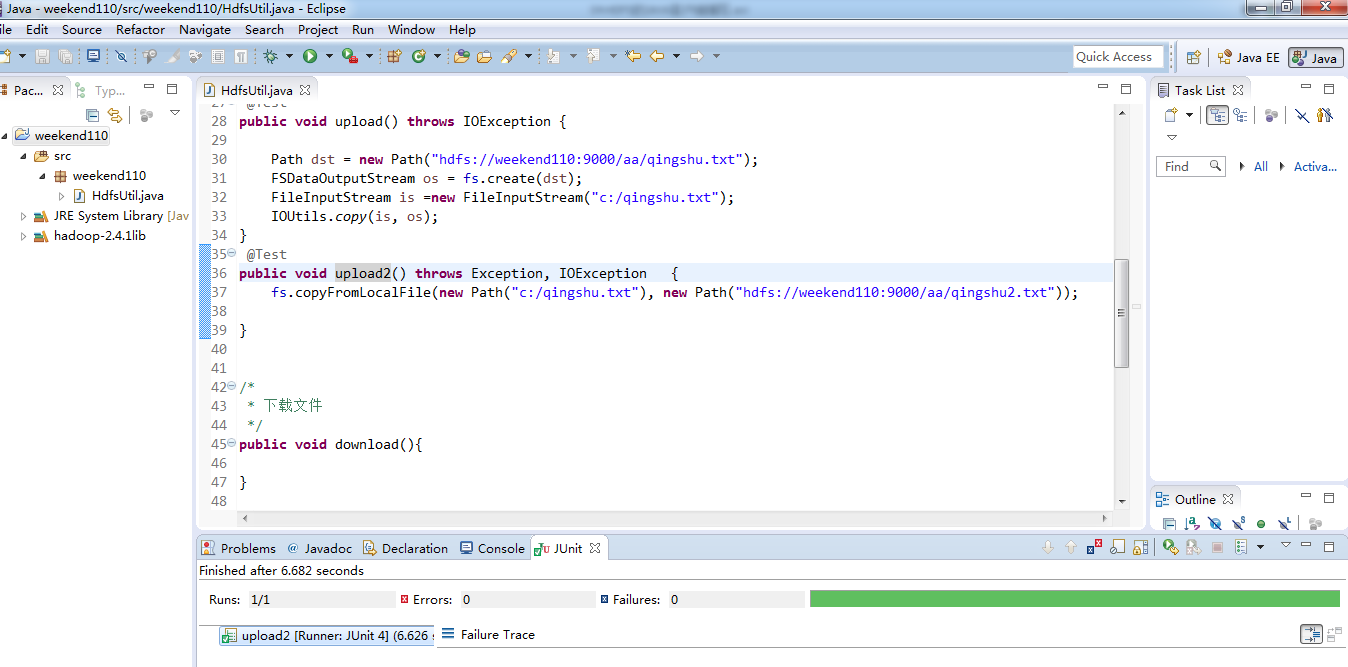
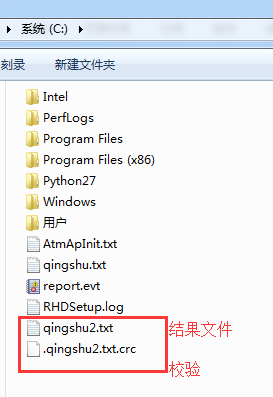
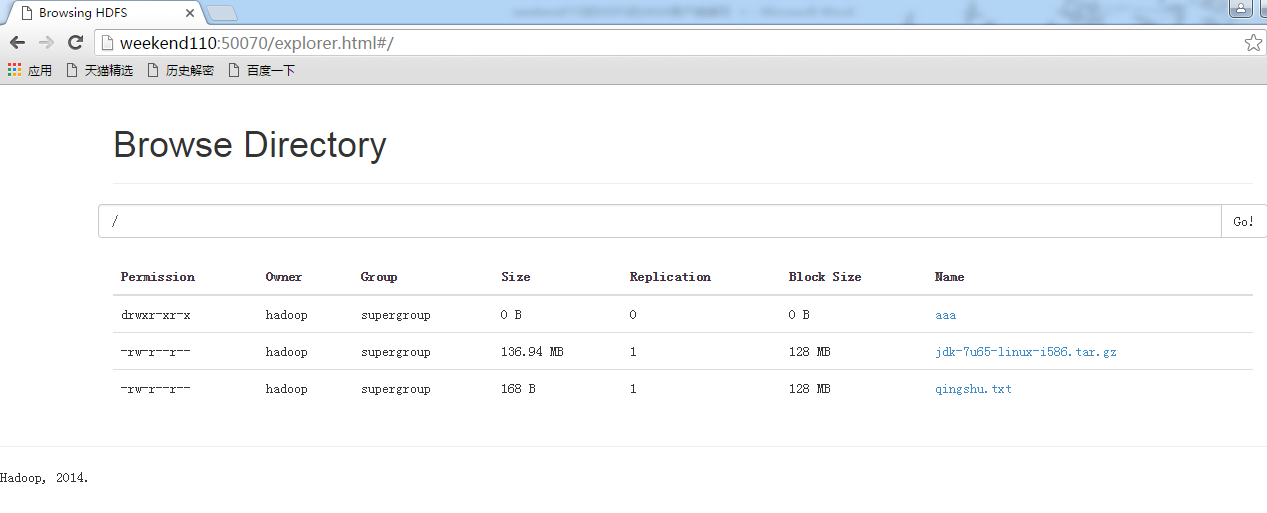
在C盘,新建qingshu.txt


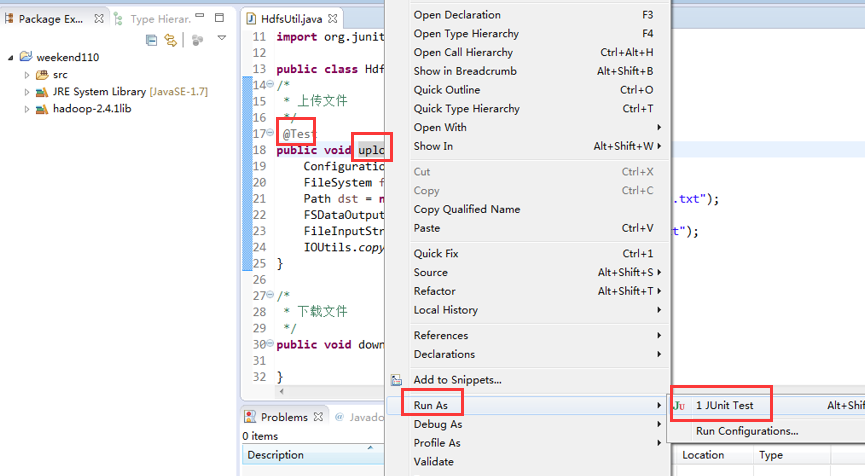

出现错误是好事,
原来是这里,
后经查找资料,是少了个 winutils.exe

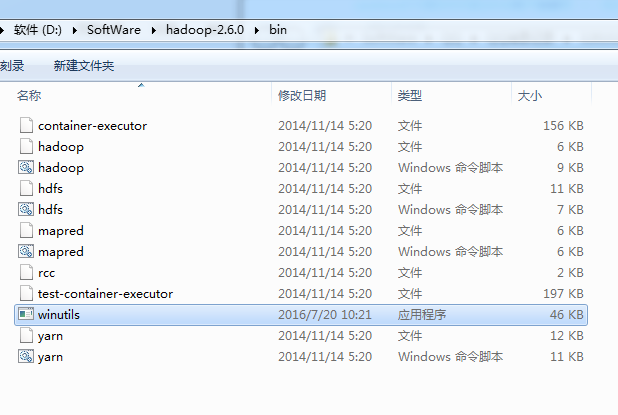
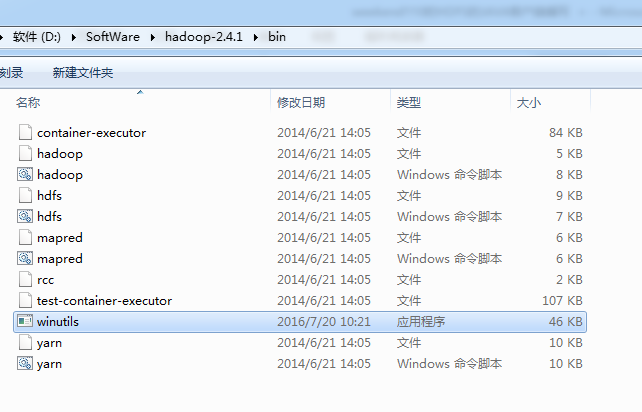

这只是个WARN警告而已,不影响运行。

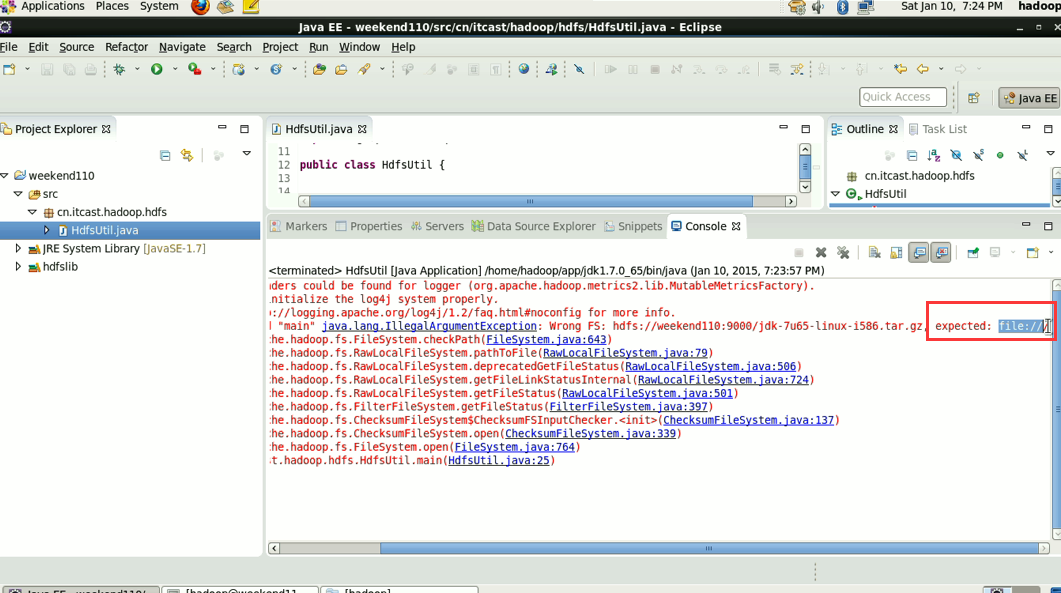
错误是:
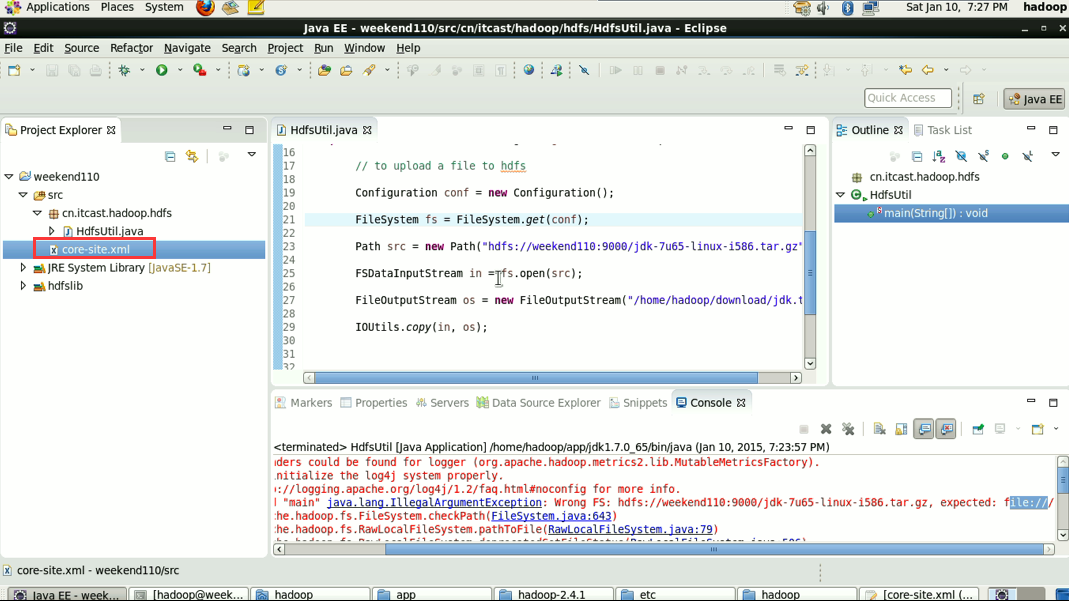
java.lang.IllegalArgumentException:Wrong FS:hdfs://weekend110:9000/aa,expected:file:///
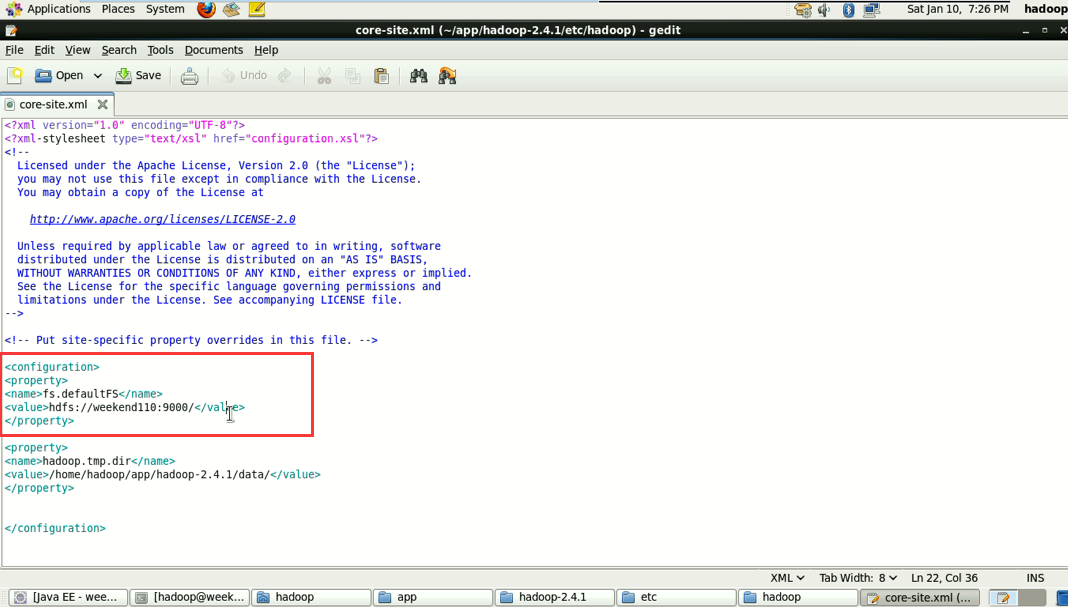
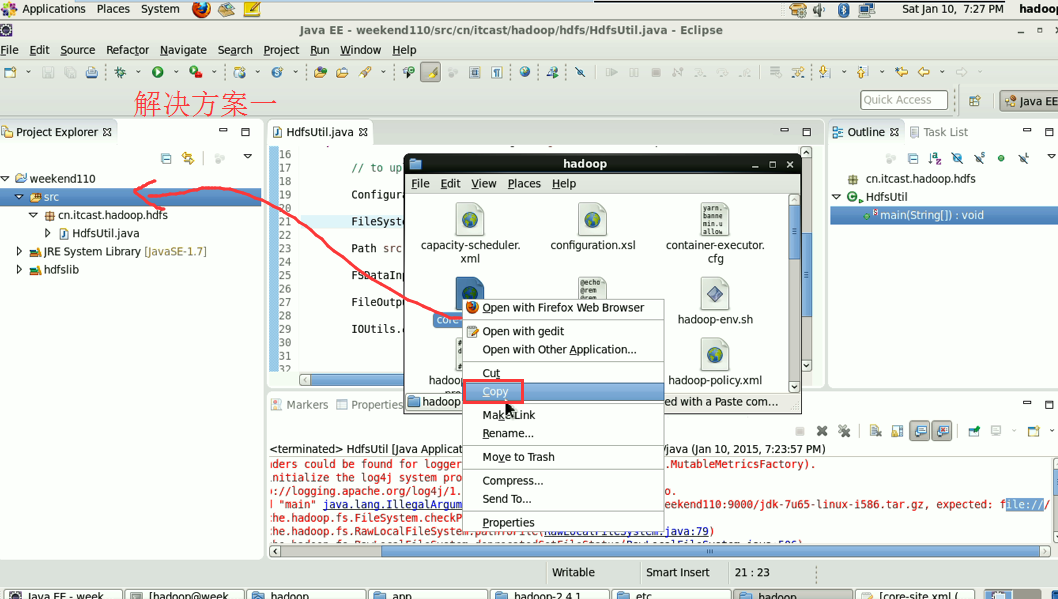
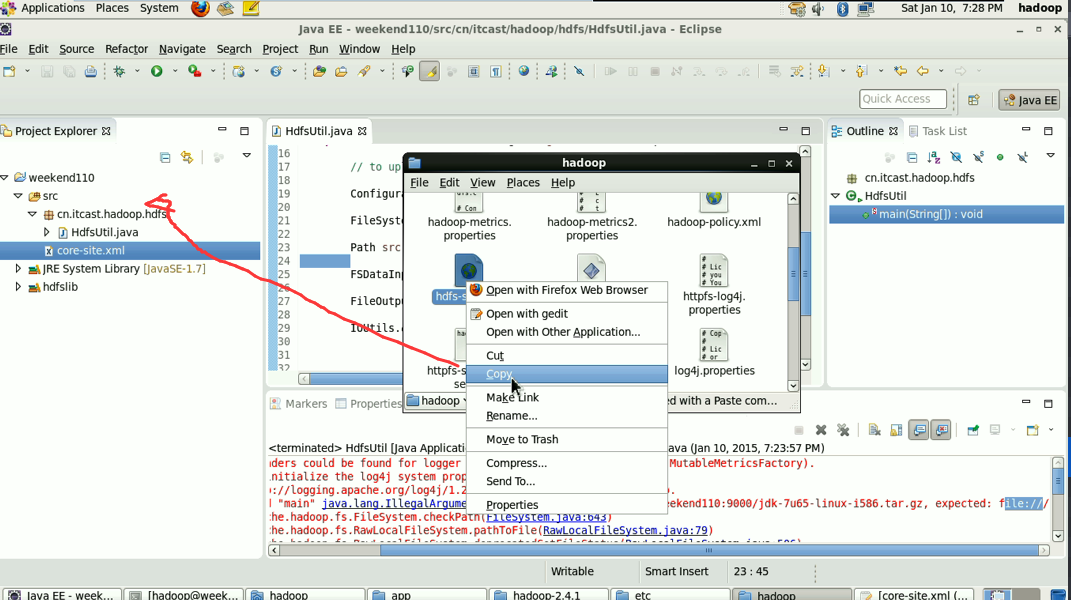
解决方案一:就不再写了,是上面的在Linux里解决的那种方法。
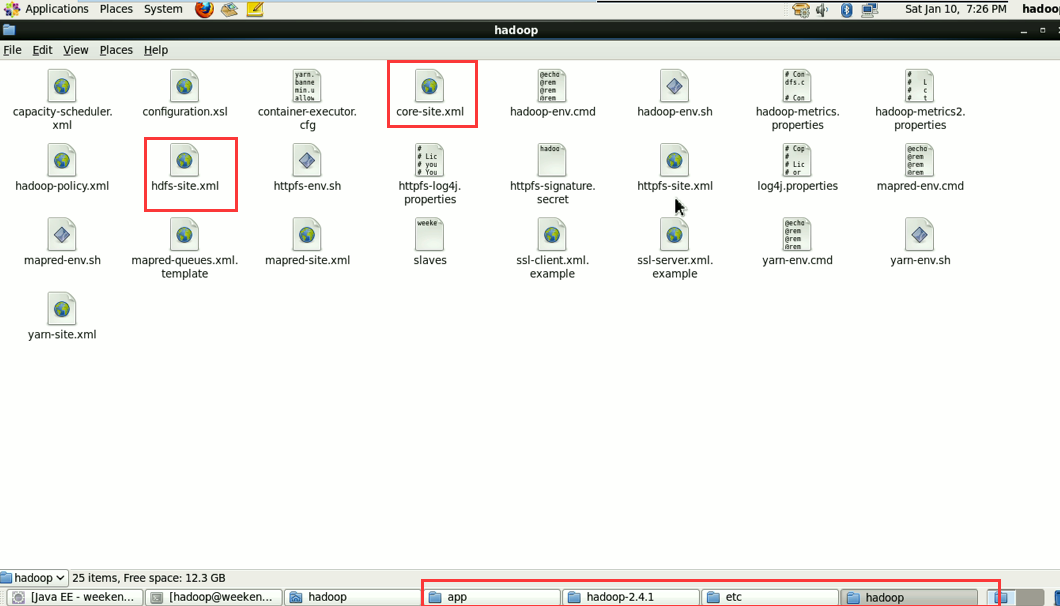
将/home/hadoop/app/hadoop-2.4.1/etc/hadoop/core-site.xml
和/home/hadoop/app/hadoop-2.4.1/etc/hadoop/hdfs-site.xml
放到,
解决方案二:
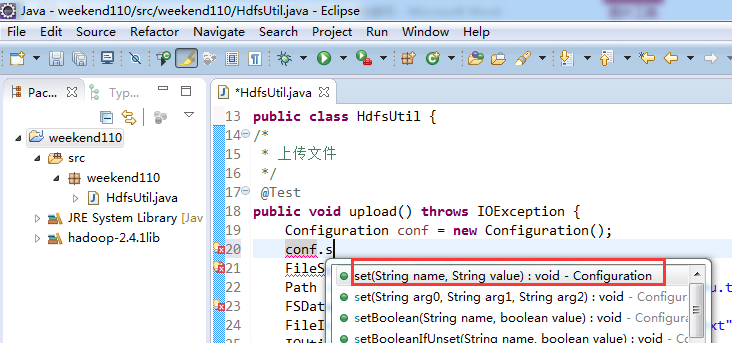


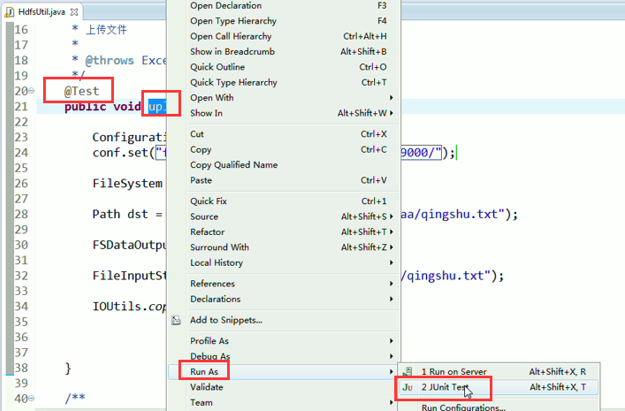
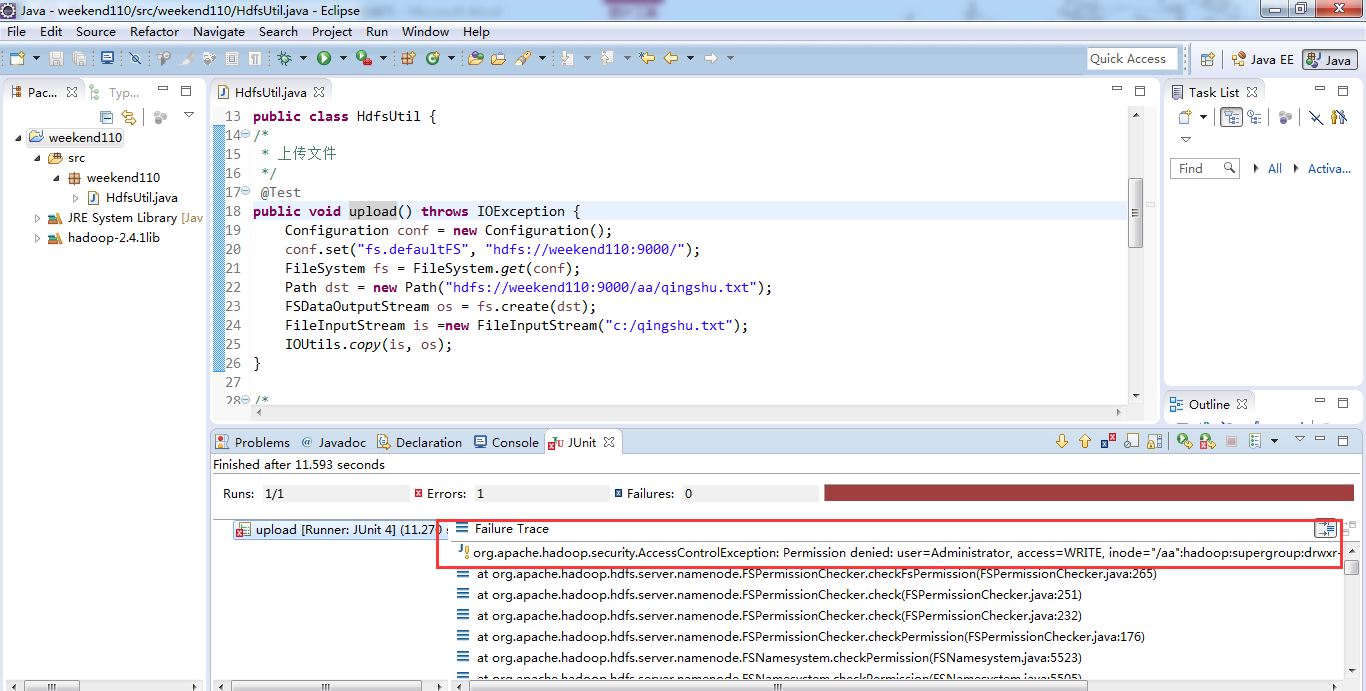
身份报错,windows是administrator,hadoop集群那边是hadoop ,supergroup。
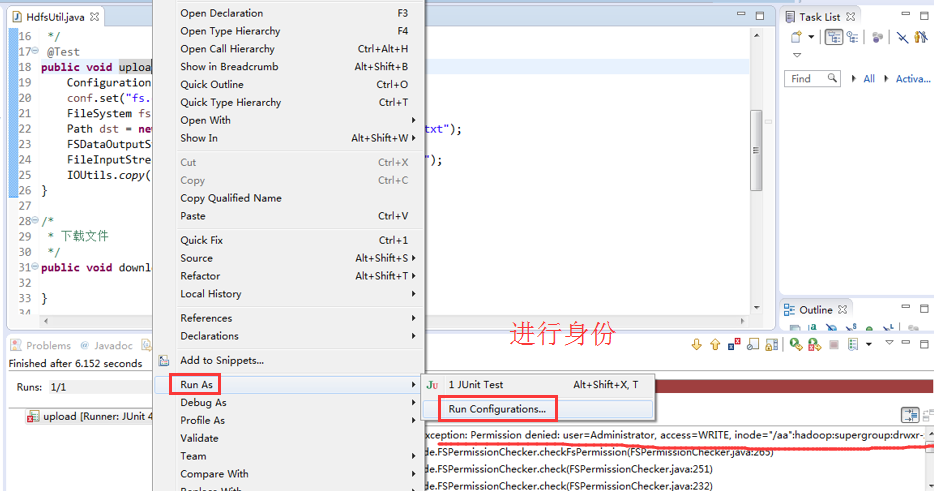

-DHADOOP_USER_NAME=Hadoop

问题在:d:\test.txt这个文件。此文件没有扩展名
解决方法:电脑工具栏-文件夹选项-查看-高级设置:-隐藏已知文件类型的扩展名(勾选去掉-应用-确定)


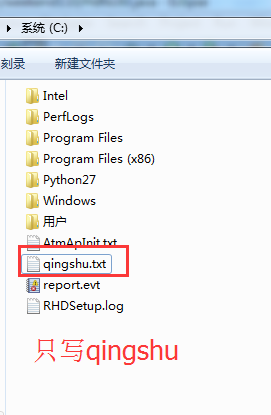
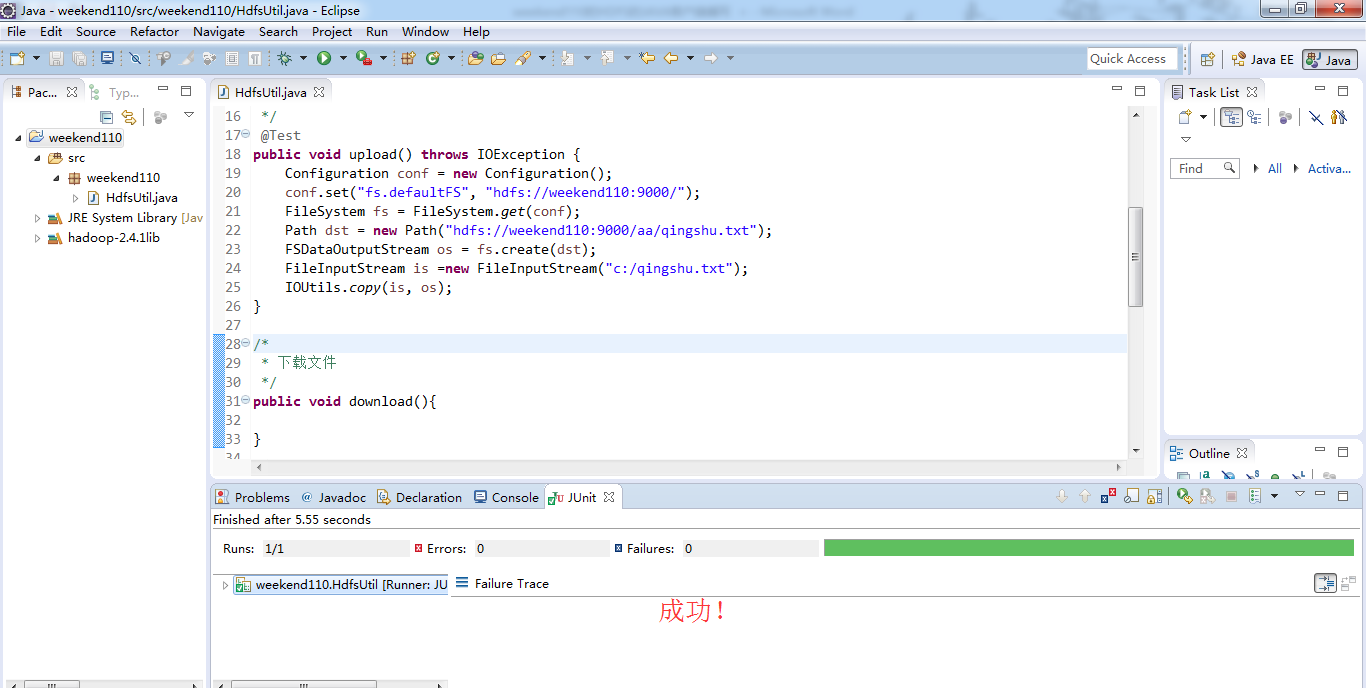
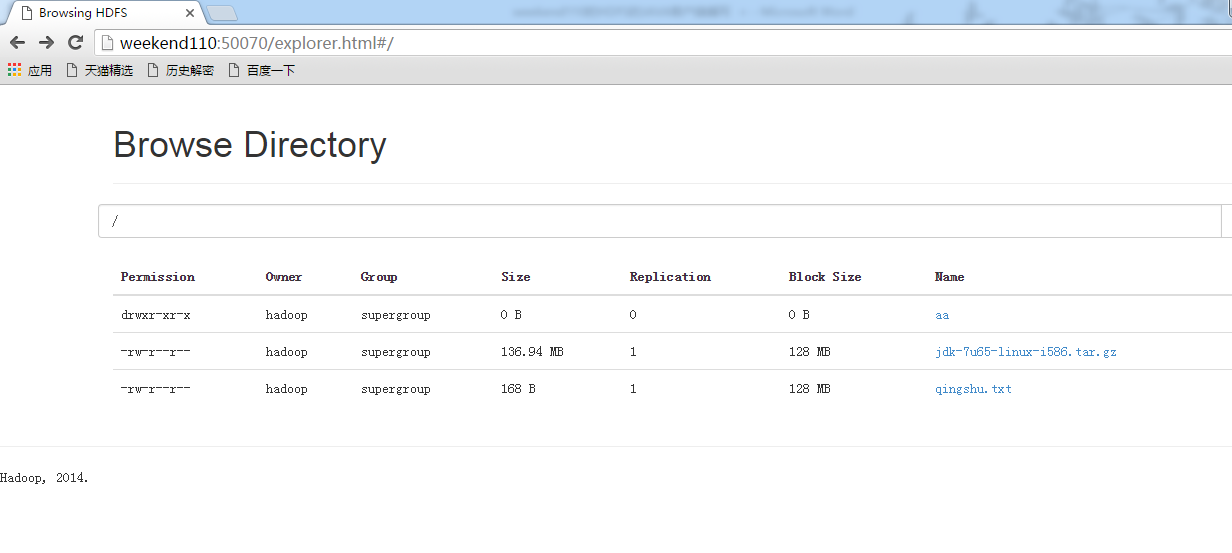
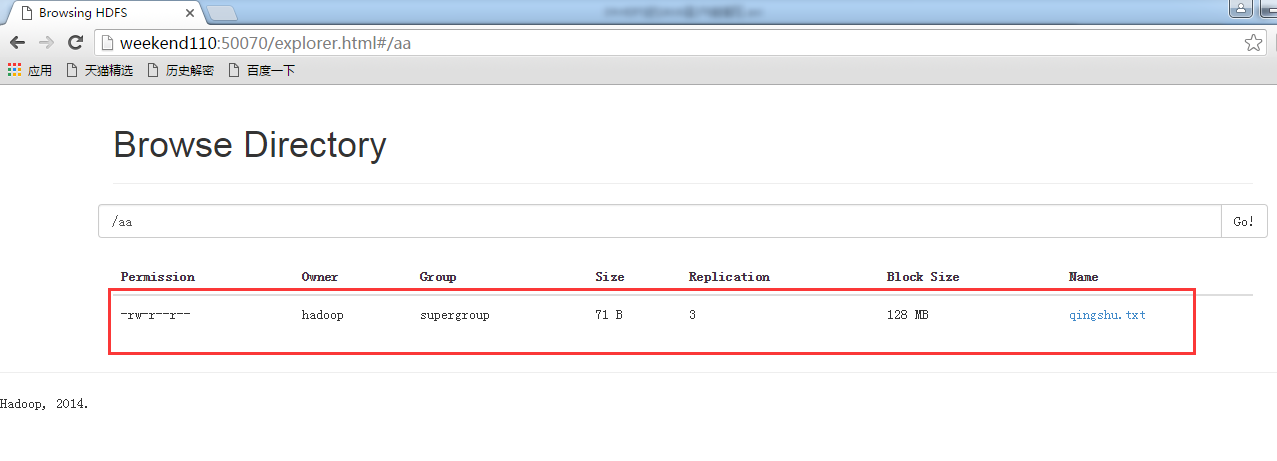


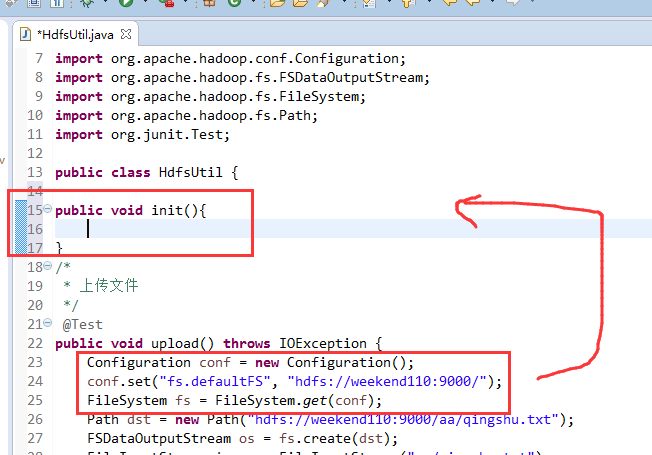
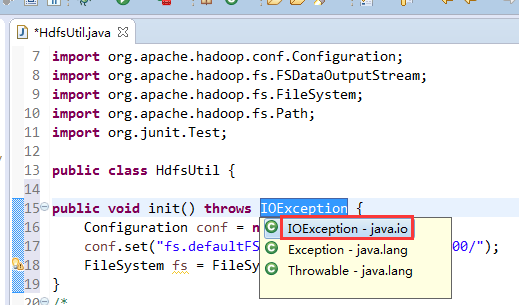




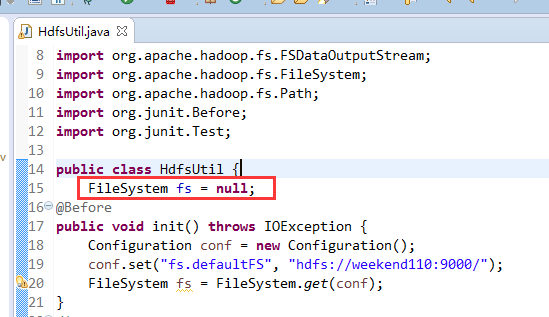

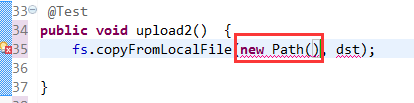


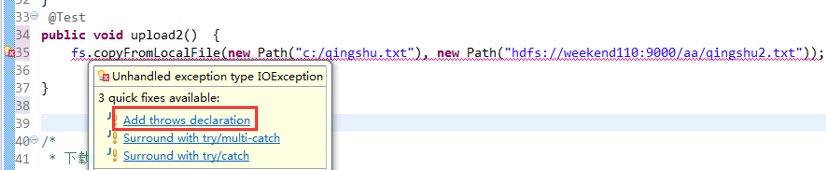



解决方案:

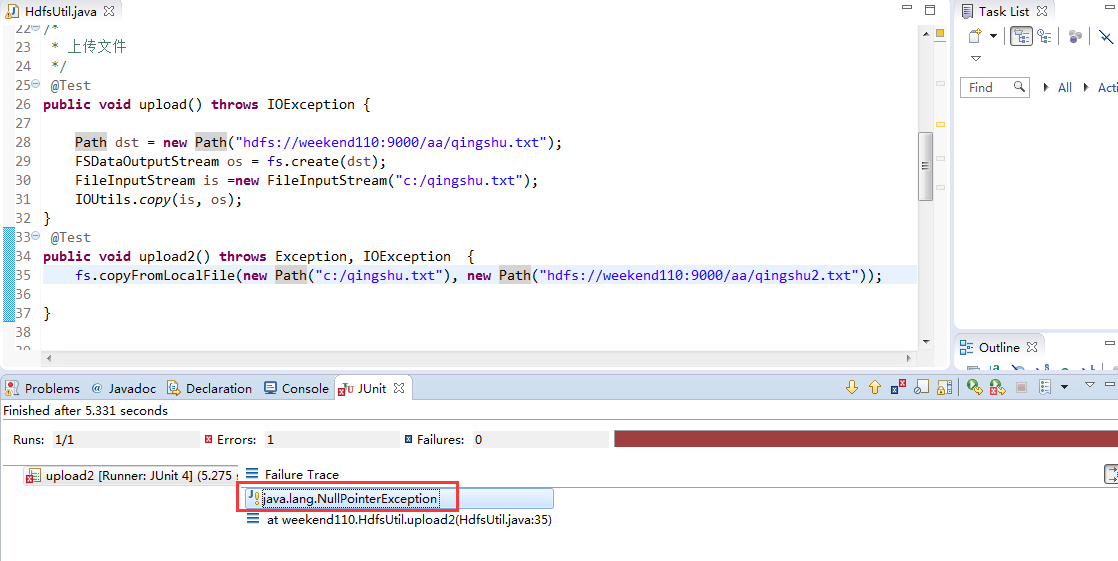
解决方案:




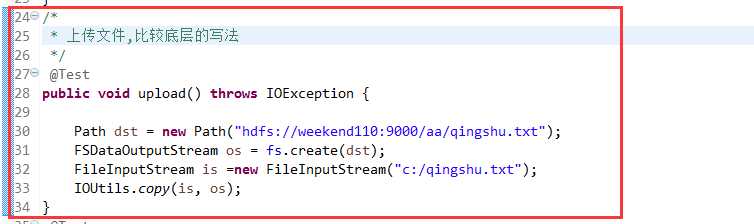

比较底层的写法,适合懂原理。
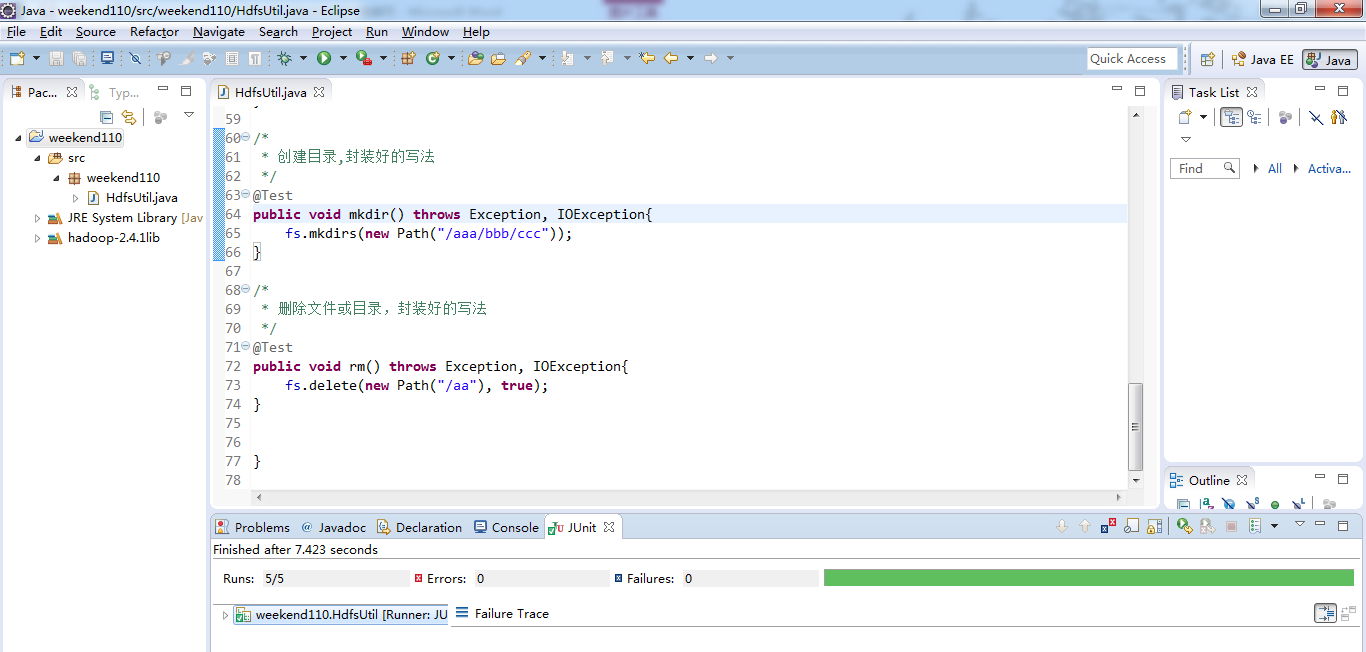
封装好的写法,适合开发。
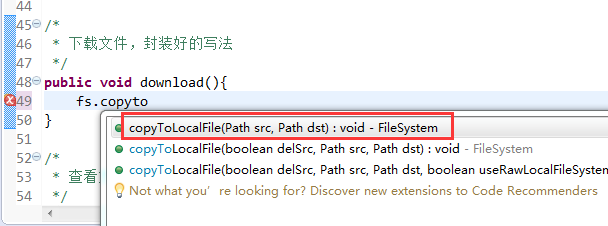



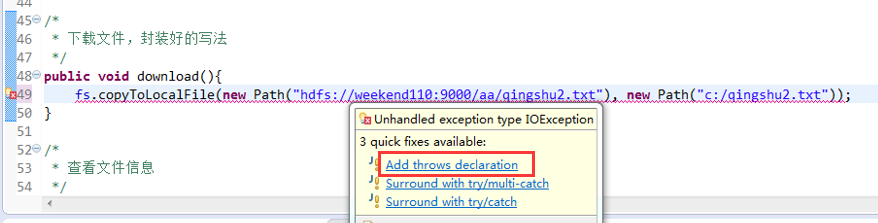
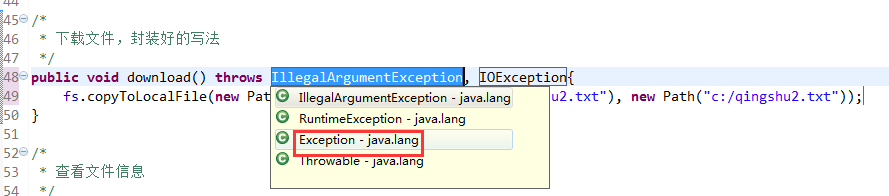

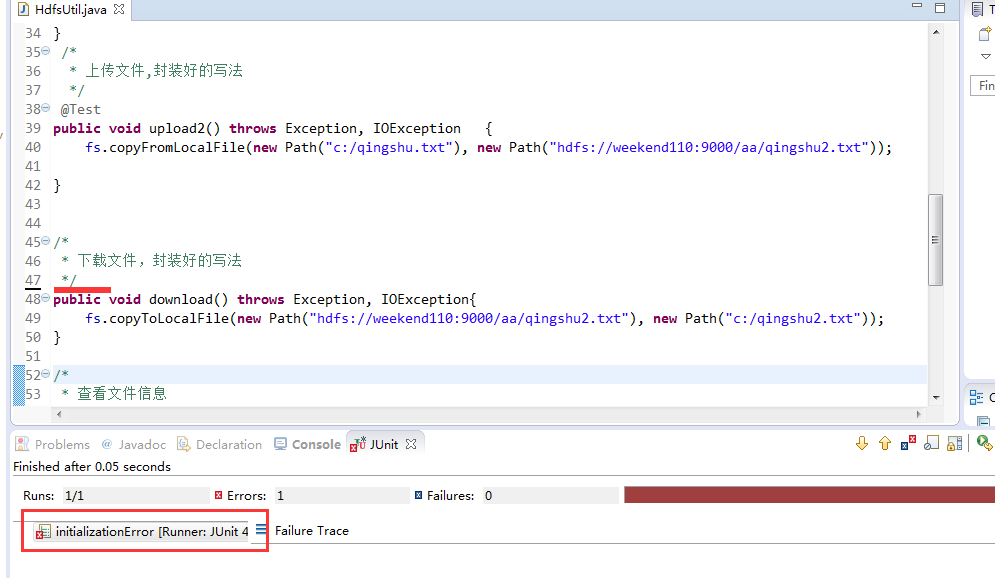
解决方案:
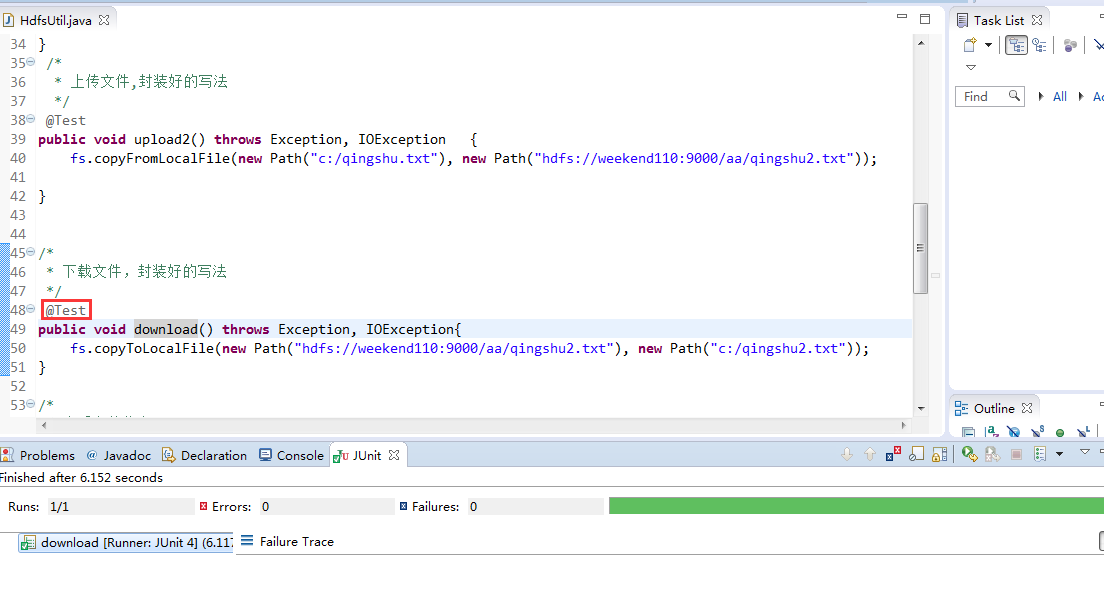









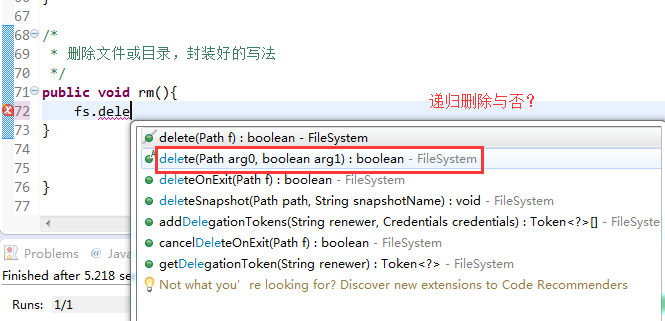
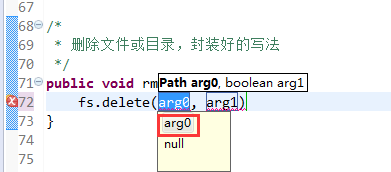


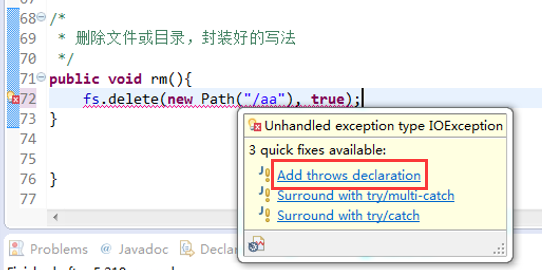
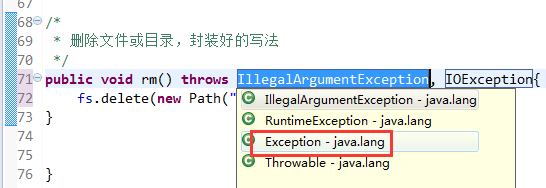


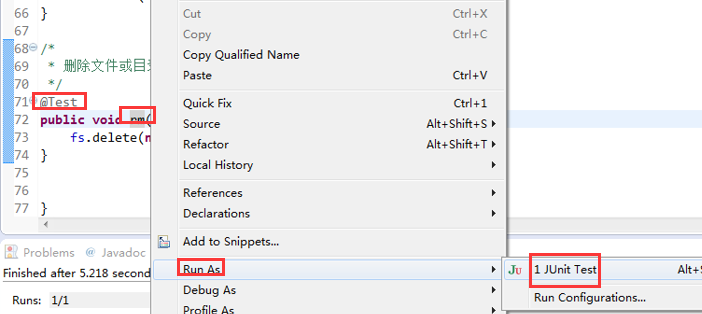
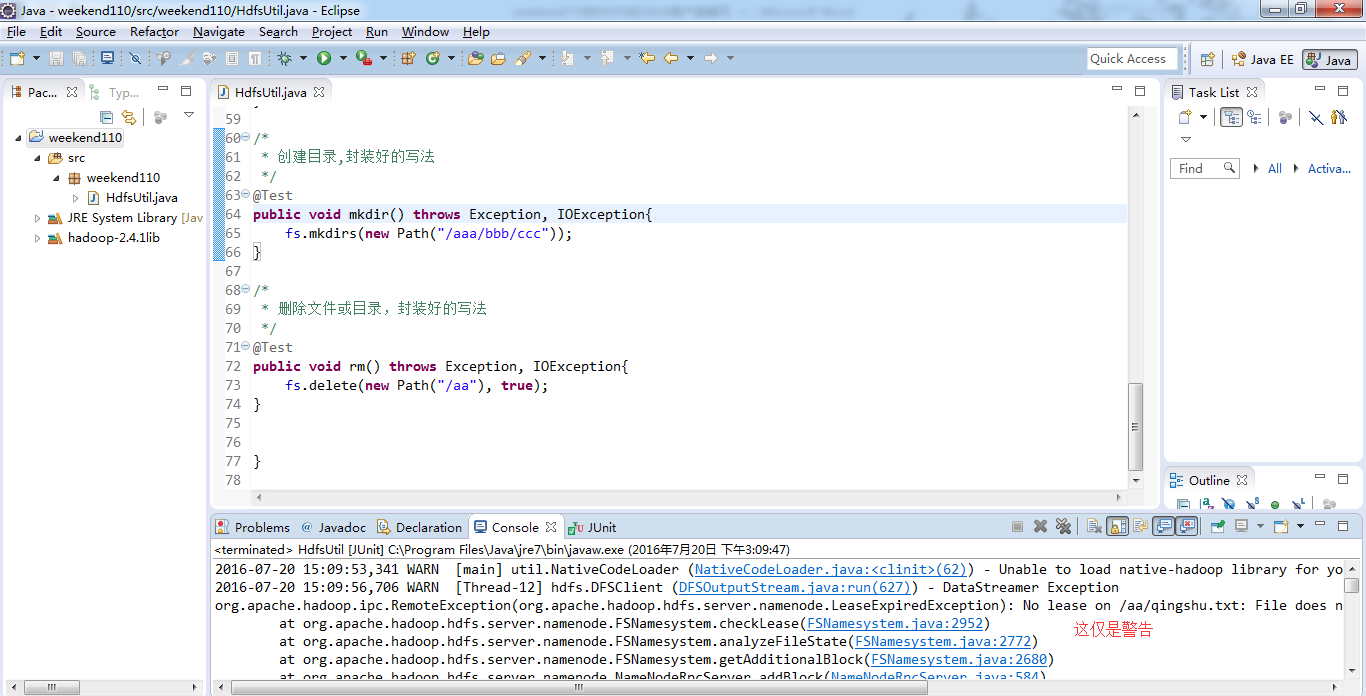
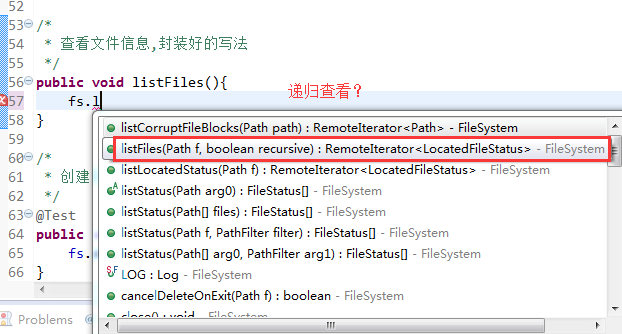

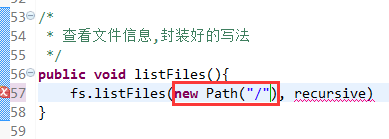
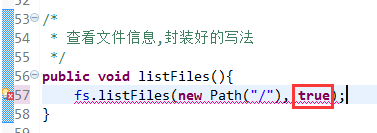
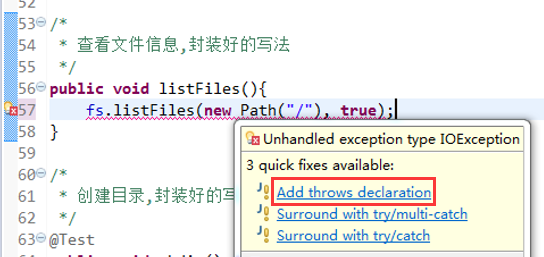
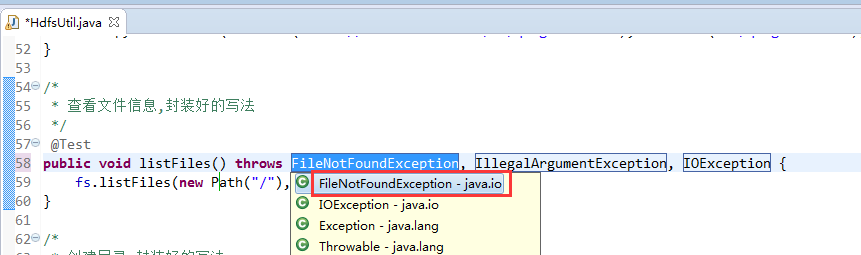


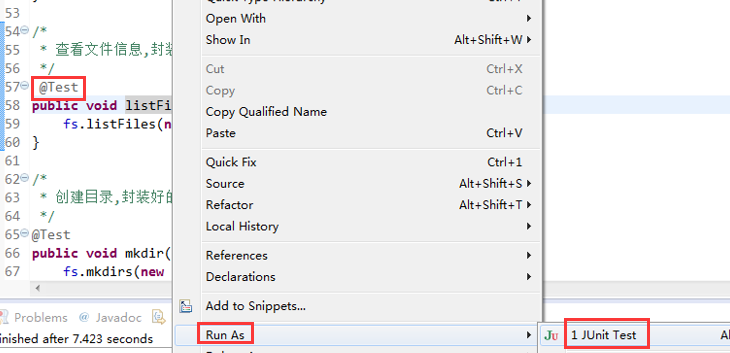
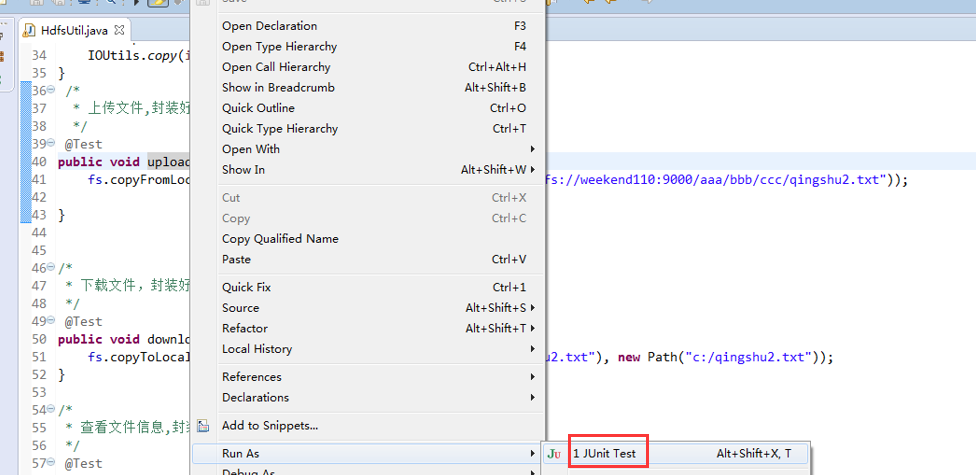
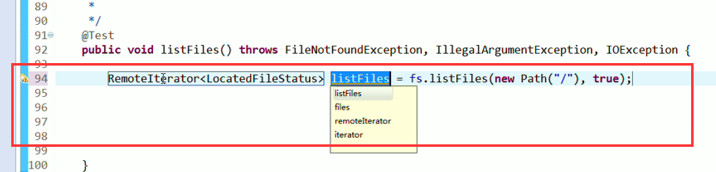
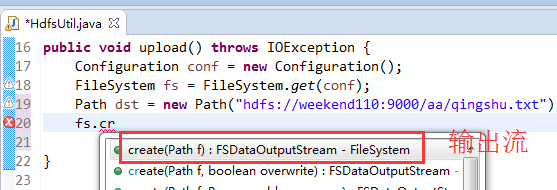
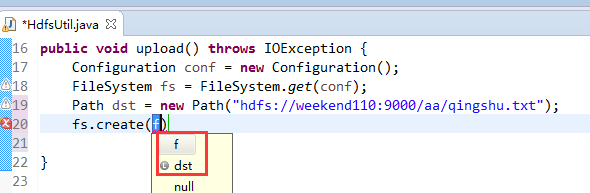
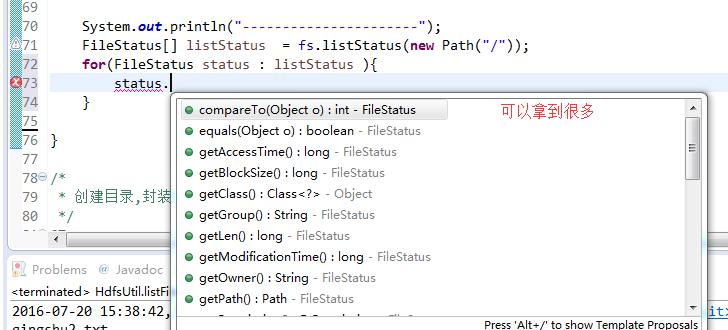
快捷键是什么?

我的只能这样
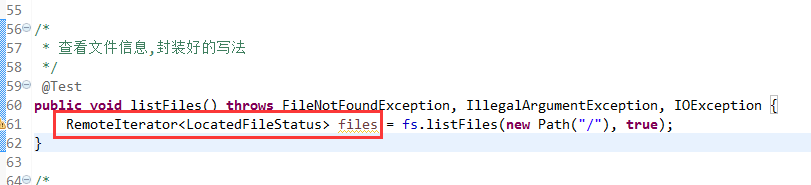

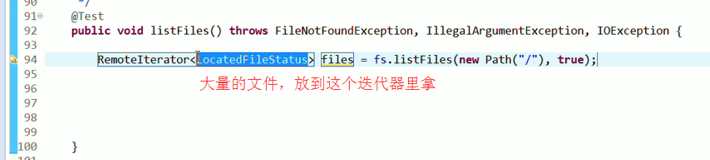
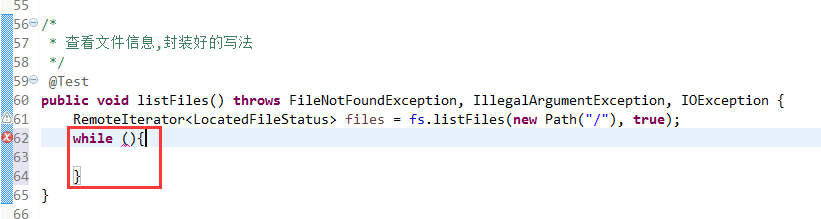

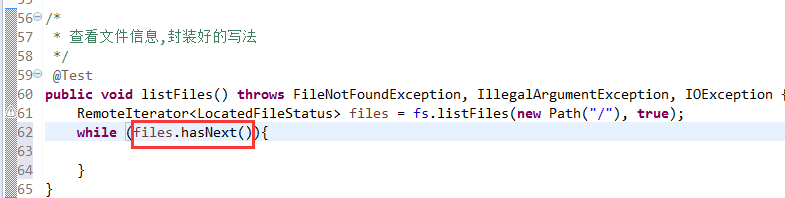

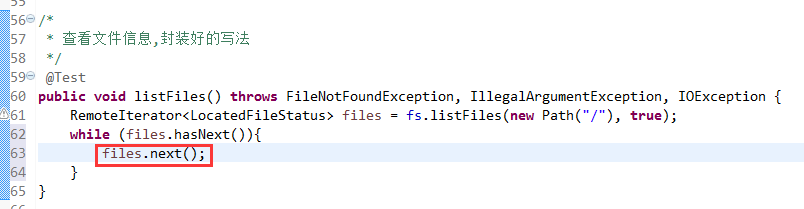
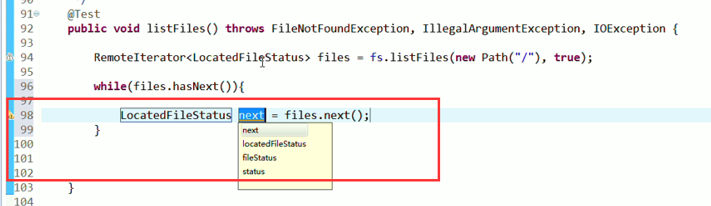
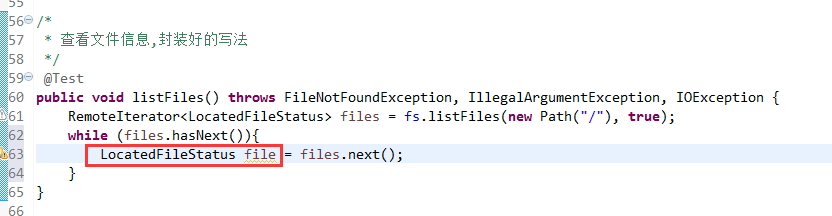


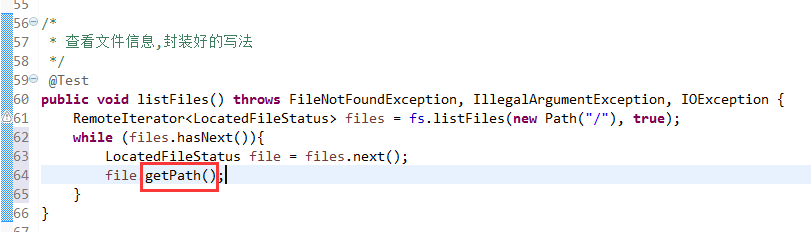

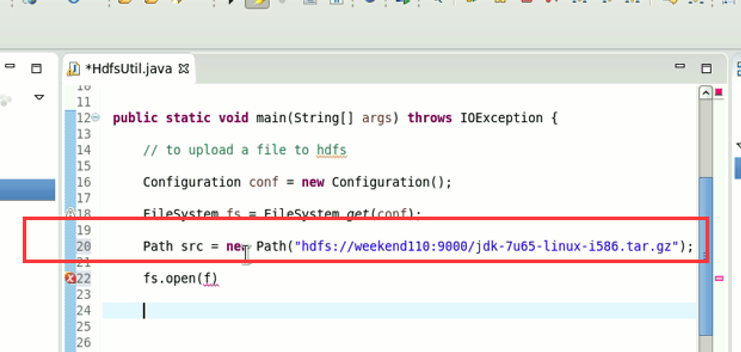
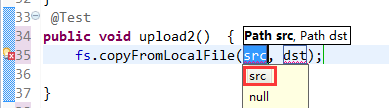
默认是path,养成业务习惯。





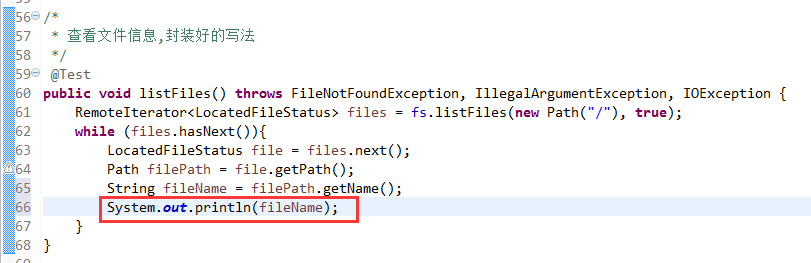

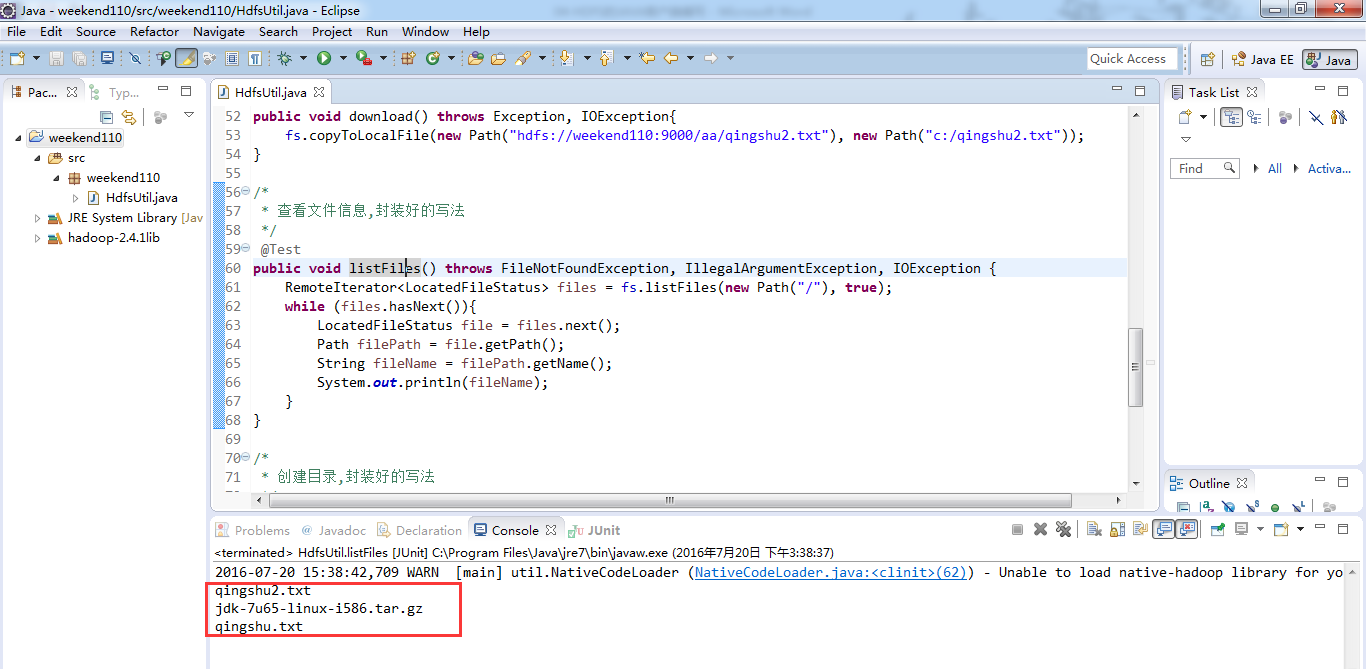
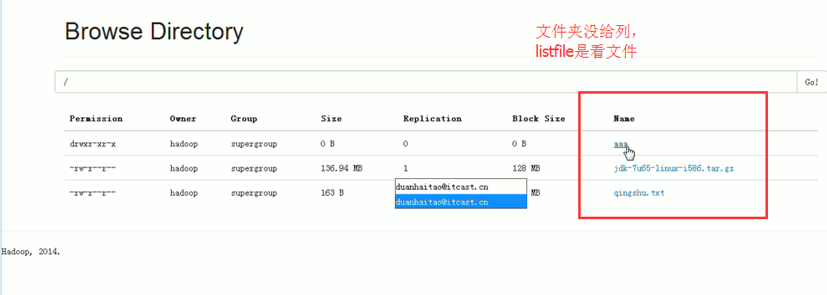

等价于,下面
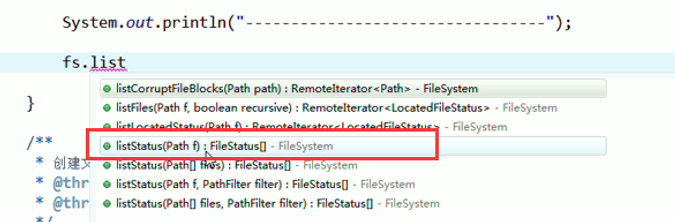


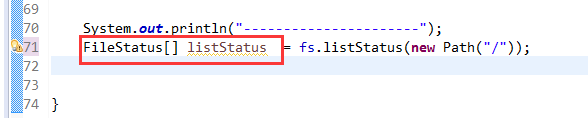
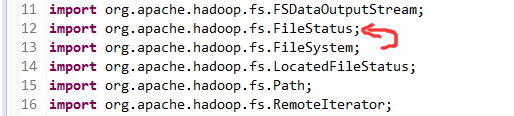

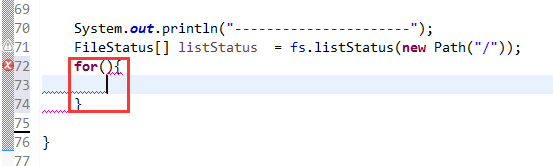
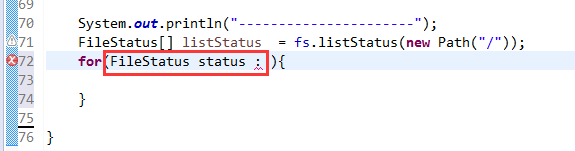




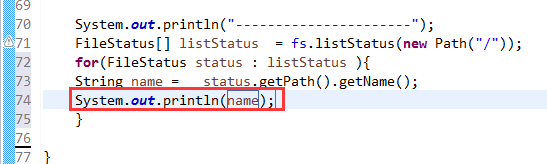
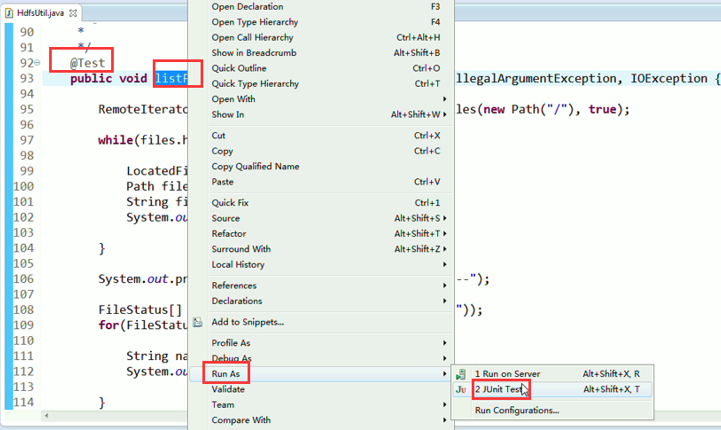
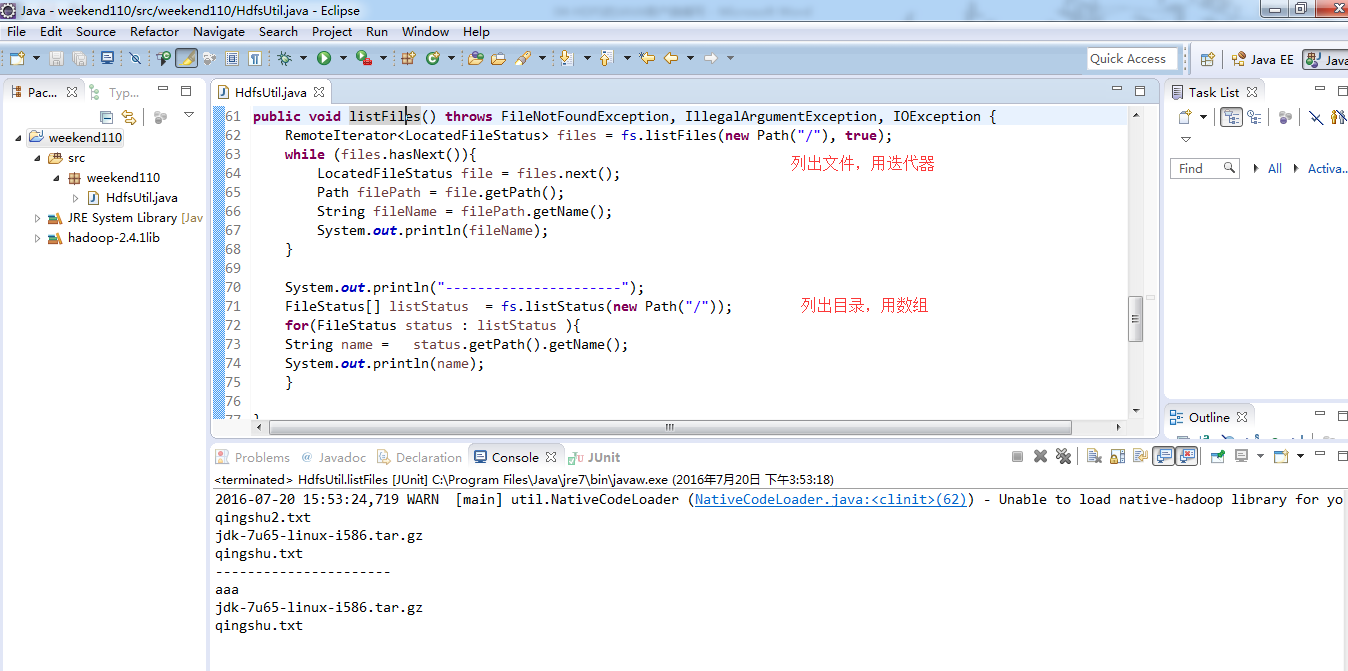
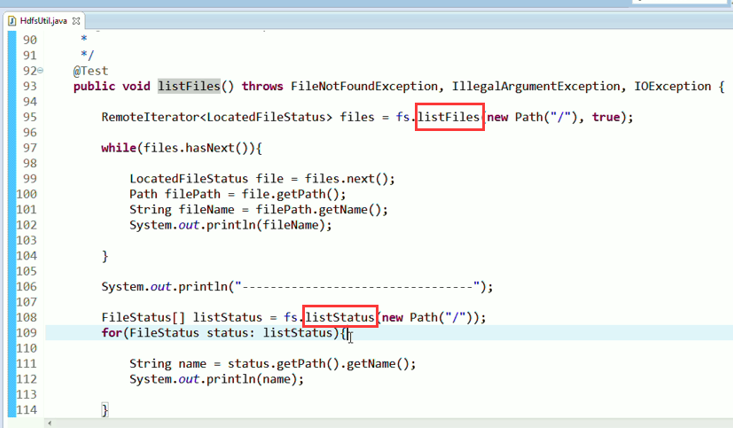
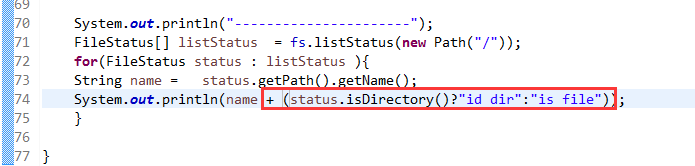
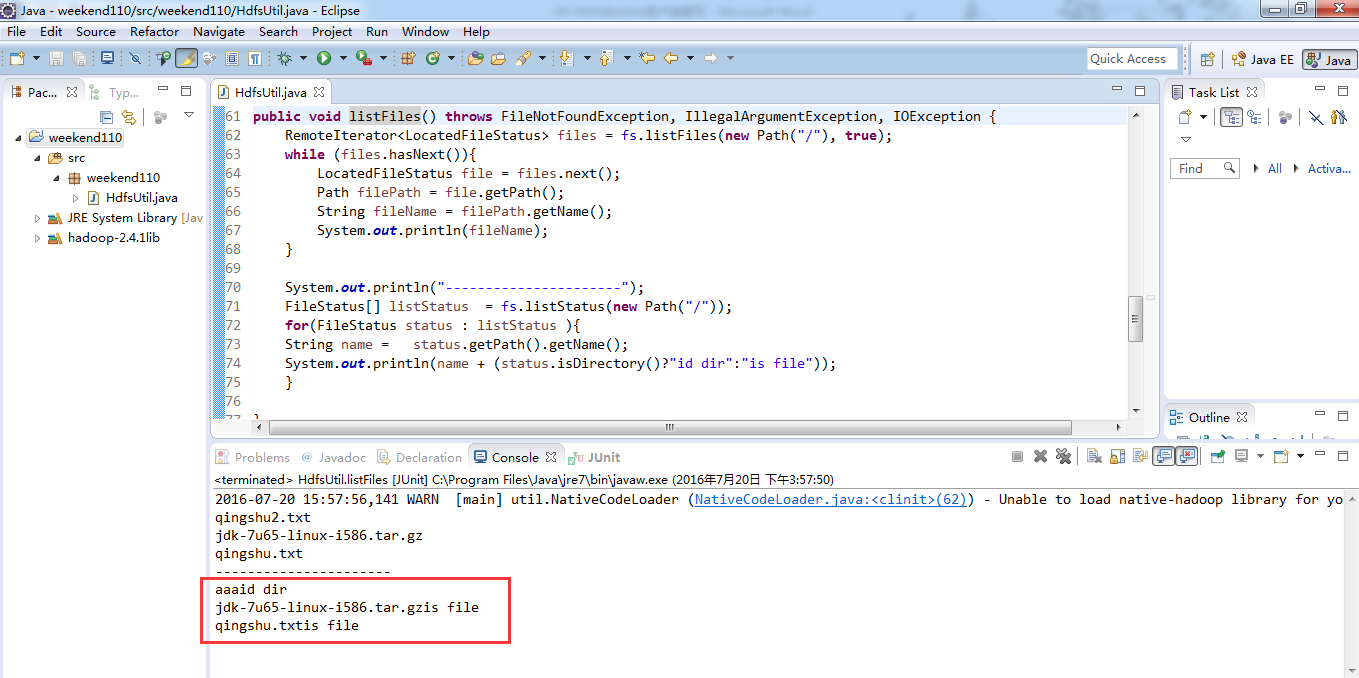
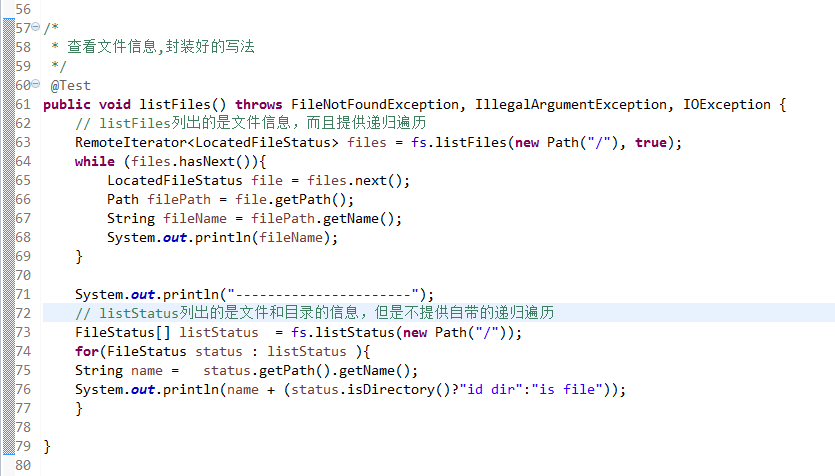


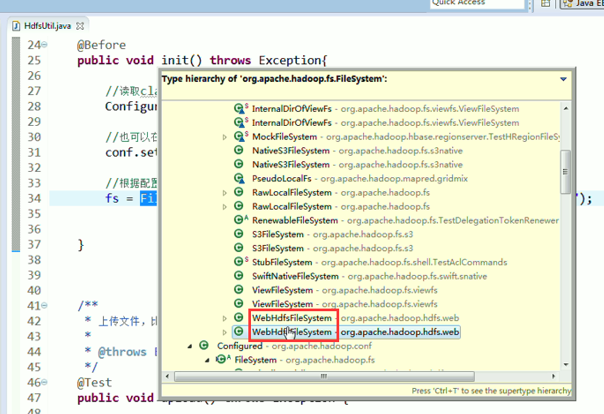
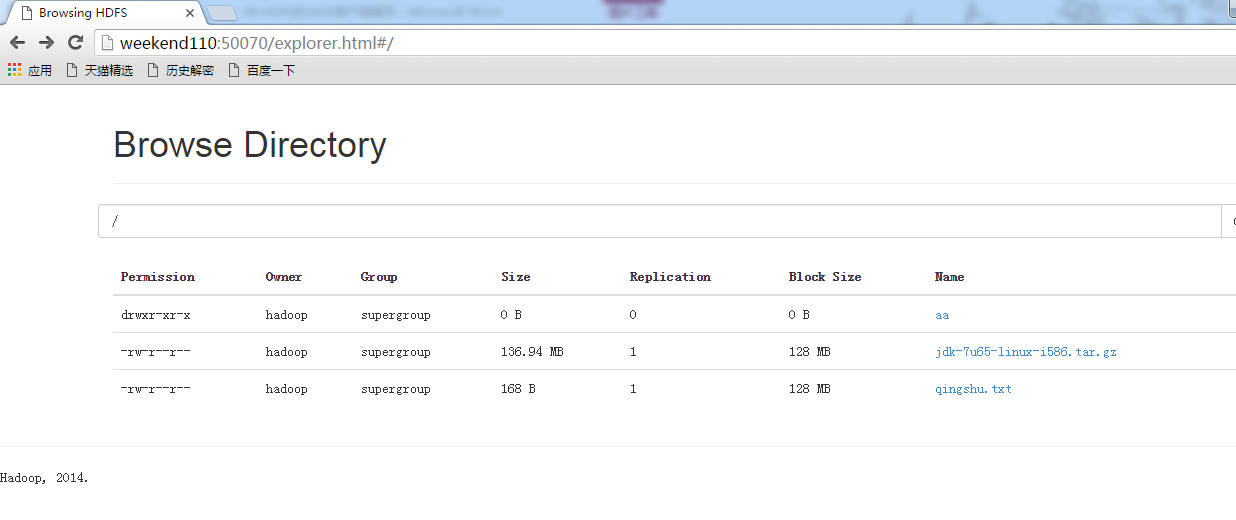
总结,本地文件系统操作很简单,new file即可,
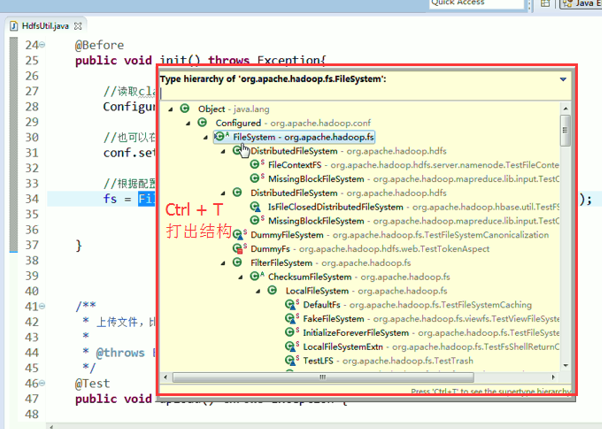
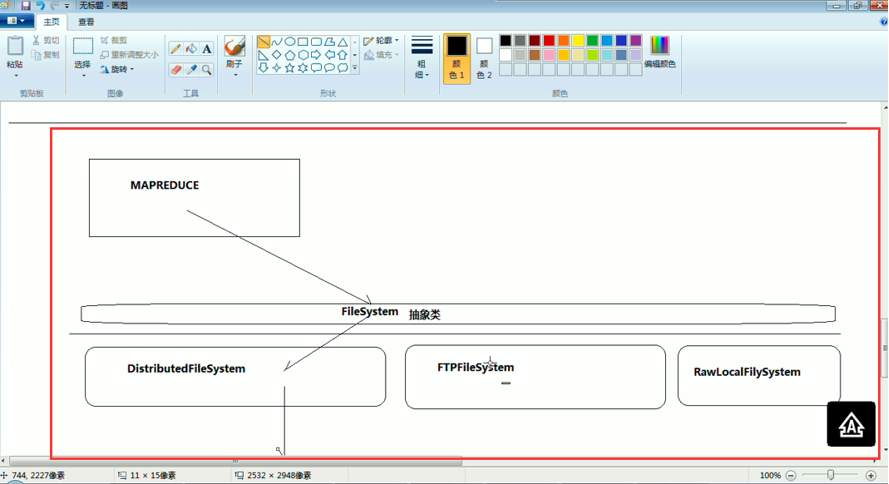
具体的实现是不一样的。但是,上层有一个抽象的文件系统,是Filesystem,为什么这么弄?
是因为Hadoop的文件系统伴随其他的框架结耦合的,我在编程时,只需面向父即抽象,filesystem就可以了,filesystem具体去拿哪个文件系统,我上层不需去管,
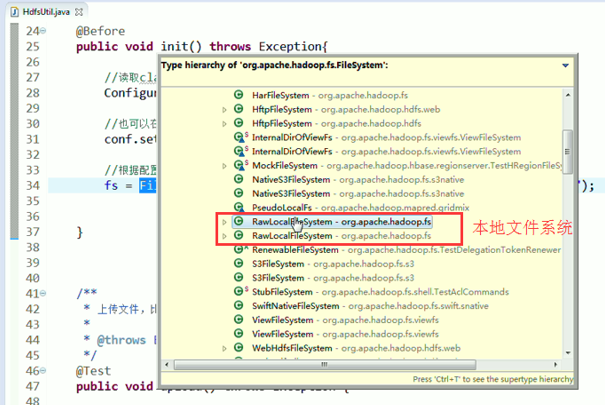
你具体是本地文件系统RawLocalFileSystem,那我就可以拿本地文件系统去读啊
你的数据是放在hdfs里面,那我就可以拿DistributedFileSystem去读啊
你的数据是放在S3里面,那我就可以拿S3FileSystem去读啊
你的数据是放在htp服务器里面,,,,,,,都可以。
总而言之,降低耦合度。
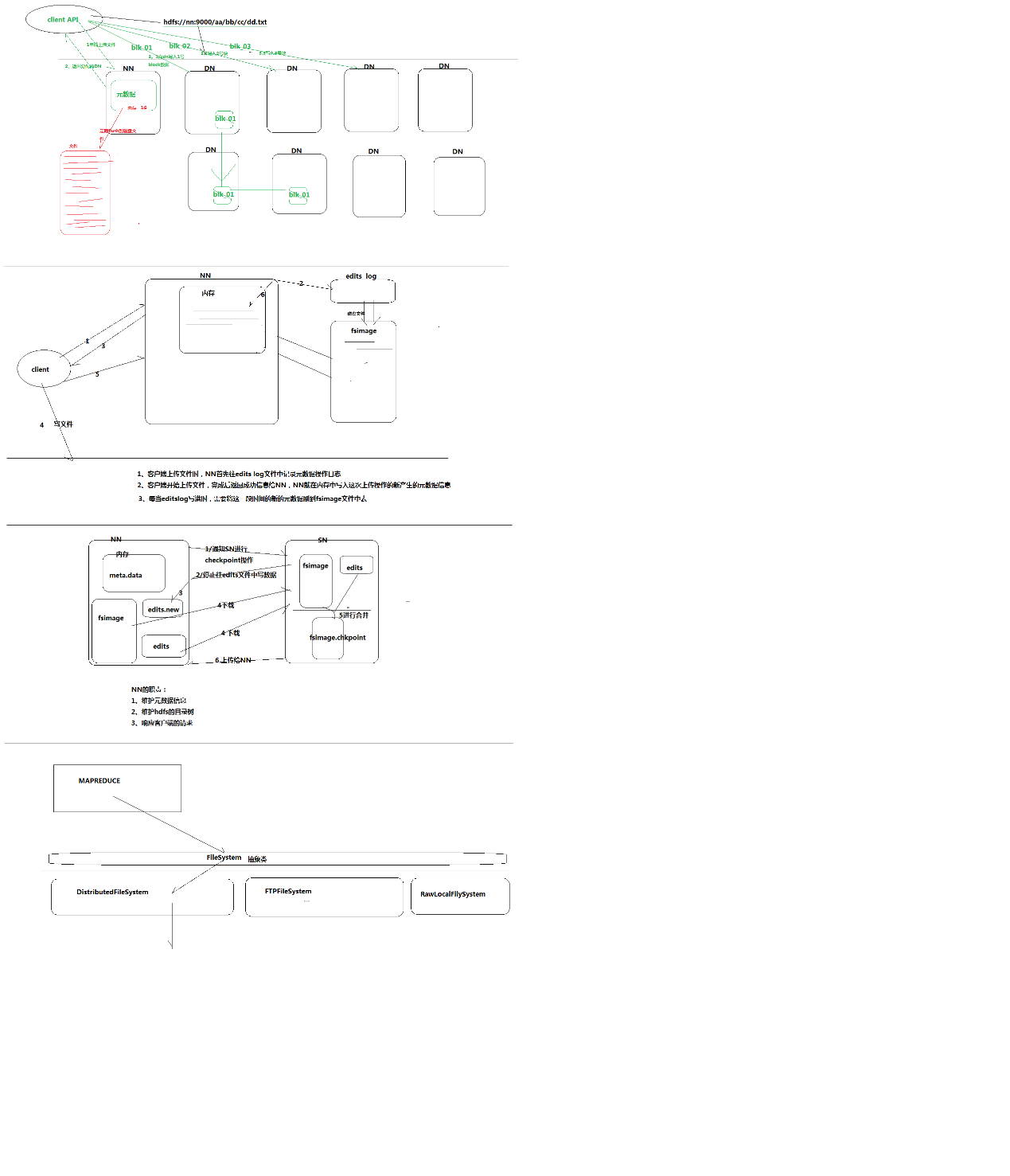
Filesystem设计思想总结

也可以这样来,
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号