

SurfaceTexture的Buffer入队流程
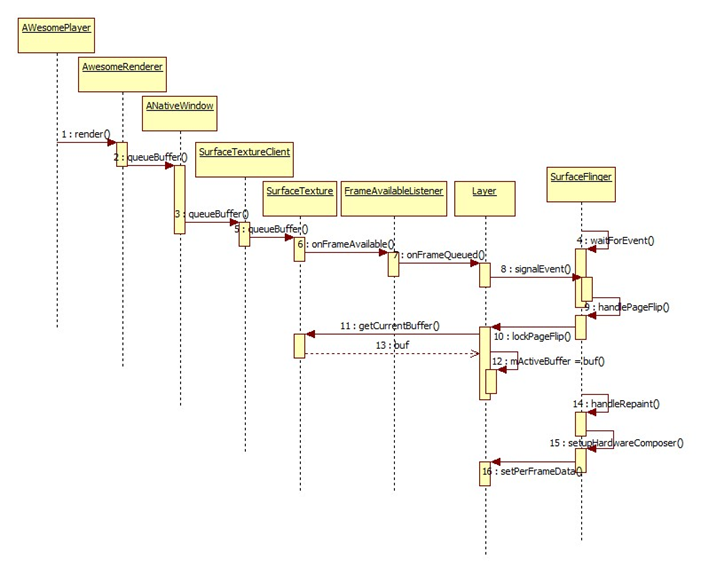
Figure 1queueBuffer流程
1. 在AWesomePlayer的Render中将解码后的Buf通过ANativeWindow接口通知SurfaceTextureClient
struct AwesomeNativeWindowRenderer : public AwesomeRenderer {
virtual void render(MediaBuffer *buffer) {
int64_t timeUs;
CHECK(buffer->meta_data()->findInt64(kKeyTime, &timeUs));
native_window_set_buffers_timestamp(mNativeWindow.get(), timeUs * 1000);
status_t err = mNativeWindow->queueBuffer(
mNativeWindow.get(), buffer->graphicBuffer().get());
}
}
进入到SurfaceTextureClient的queueBuffer(),这里的工作主要有:
1) 更新timestamp,如果没有,则用系统时间
2) 根据Buffer地址从slots中取出Buffer的序号
3) 将序号以及时间戳、以及其它信息通过Binder通信发送给SurfaceTexture。
int SurfaceTextureClient::queueBuffer(android_native_buffer_t* buffer) {
LOGV("SurfaceTextureClient::queueBuffer");
Mutex::Autolock lock(mMutex);
int64_t timestamp;
if (mTimestamp == NATIVE_WINDOW_TIMESTAMP_AUTO) {
timestamp = systemTime(SYSTEM_TIME_MONOTONIC);
LOGV("SurfaceTextureClient::queueBuffer making up timestamp: %.2f ms",
timestamp / 1000000.f);
} else {
timestamp = mTimestamp;
}
int i = getSlotFromBufferLocked(buffer);
status_t err = mSurfaceTexture->queueBuffer(i, timestamp,
&mDefaultWidth, &mDefaultHeight, &mTransformHint);
return err;
}
2. 在SurfaceFlinger进程中,本地端的SurfaceTexture接收到Binder消息,并进入queueBuffer函数。主要做以下工作:
1) 根据传入的int buf从slots中找出相应的Buffer,并更新此buffer的相关信息。
2)发信号mDequeueCondition.signal(),用作通知等待者
3) 通知监听者,onFrameAvailable有帧到达
status_t SurfaceTexture::queueBuffer(int buf, int64_t timestamp,
uint32_t* outWidth, uint32_t* outHeight, uint32_t* outTransform) {
ST_LOGV("queueBuffer: slot=%d time=%lld", buf, timestamp);
sp<FrameAvailableListener> listener;
{ // scope for the lock
Mutex::Autolock lock(mMutex);
//一些参数检查
if (mSynchronousMode) {
// In synchronous mode we queue all buffers in a FIFO.
mQueue.push_back(buf);
// Synchronous mode always signals that an additional frame should
// be consumed.
listener = mFrameAvailableListener;
} else {
// In asynchronous mode we only keep the most recent buffer.
if (mQueue.empty()) {
mQueue.push_back(buf);
// Asynchronous mode only signals that a frame should be
// consumed if no previous frame was pending. If a frame were
// pending then the consumer would have already been notified.
listener = mFrameAvailableListener;
} else {
Fifo::iterator front(mQueue.begin());
// buffer currently queued is freed
mSlots[*front].mBufferState = BufferSlot::FREE;
// and we record the new buffer index in the queued list
*front = buf;
}
}
mSlots[buf].mBufferState = BufferSlot::QUEUED;
mSlots[buf].mCrop = mNextCrop;
mSlots[buf].mTransform = mNextTransform;
mSlots[buf].mScalingMode = mNextScalingMode;
mSlots[buf].mTimestamp = timestamp;
mFrameCounter++;
mSlots[buf].mFrameNumber = mFrameCounter;
mDequeueCondition.signal();
*outWidth = mDefaultWidth;
*outHeight = mDefaultHeight;
*outTransform = 0;
} // scope for the lock
// call back without lock held
if (listener != 0) {
listener->onFrameAvailable();
}
return OK;
}
在Layer中,第一次引用时会创建SurfaceTexture,并实现FrameAvailableListener
void Layer::onFirstRef()
{
LayerBaseClient::onFirstRef();
struct FrameQueuedListener : public SurfaceTexture::FrameAvailableListener {
FrameQueuedListener(Layer* layer) : mLayer(layer) { }
private:
wp<Layer> mLayer;
virtual void onFrameAvailable() {
sp<Layer> that(mLayer.promote());
if (that != 0) {
that->onFrameQueued();
}
}
};
mSurfaceTexture = new SurfaceTextureLayer(mTextureName, this);
mSurfaceTexture->setFrameAvailableListener(new FrameQueuedListener(this));
mSurfaceTexture->setSynchronousMode(true);
mSurfaceTexture->setBufferCountServer(2);
}
控制流进入Layer:onFrameQueued()函数,最后调用SurfaceFlinger的事件函数,通知其新事件。
void Layer::onFrameQueued() {
android_atomic_inc(&mQueuedFrames);
mFlinger->signalEvent();
}
3. 在SurfaceFlinger中获得事件,进入主循环处理事件
bool SurfaceFlinger::threadLoop()
{
waitForEvent();
// post surfaces (if needed)
handlePageFlip();//设置刚入队的Buffer为当前激活的Buffer
handleRepaint();//将当前激活的Buffer地址送给硬件叠加层,进行叠加
在lockPageFlip函数中遍历每一层设置当前激活的Buffer
bool SurfaceFlinger::lockPageFlip(const LayerVector& currentLayers)
{
bool recomputeVisibleRegions = false;
size_t count = currentLayers.size();
sp<LayerBase> const* layers = currentLayers.array();
for (size_t i=0 ; i<count ; i++) {
const sp<LayerBase>& layer(layers[i]);
layer->lockPageFlip(recomputeVisibleRegions);
}
return recomputeVisibleRegions;
}
对每个Layer将当前Buffer设置为激活Buffer
void Layer::lockPageFlip(bool& recomputeVisibleRegions)
{
// update the active buffer
mActiveBuffer = mSurfaceTexture->getCurrentBuffer();
在handleRepaint()中调用setupHardwareComposer建立叠加层
setupHardwareComposer(mDirtyRegion);
void SurfaceFlinger::setupHardwareComposer(Region& dirtyInOut)
{
/*
* update the per-frame h/w composer data for each layer
* and build the transparent region of the FB
*/
for (size_t i=0 ; i<count ; i++) {
const sp<LayerBase>& layer(layers[i]);
layer->setPerFrameData(&cur[i]);
}
}
将当前激活的buffer设置到 handware composer中进行叠加
void Layer::setPerFrameData(hwc_layer_t* hwcl) {
const sp<GraphicBuffer>& buffer(mActiveBuffer);
if (buffer == NULL) {
// this can happen if the client never drew into this layer yet,
// or if we ran out of memory. In that case, don't let
// HWC handle it.
hwcl->flags |= HWC_SKIP_LAYER;
hwcl->handle = NULL;
} else {
hwcl->handle = buffer->handle;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号