

这一章中主要介绍了使用LINQ查询内存对象的一些基本语法。在下一章将会有更高级的用法介绍。本章中的示例数据是一个简单的出版社信息。这里是数据文件。下面的图表示了数据模型:
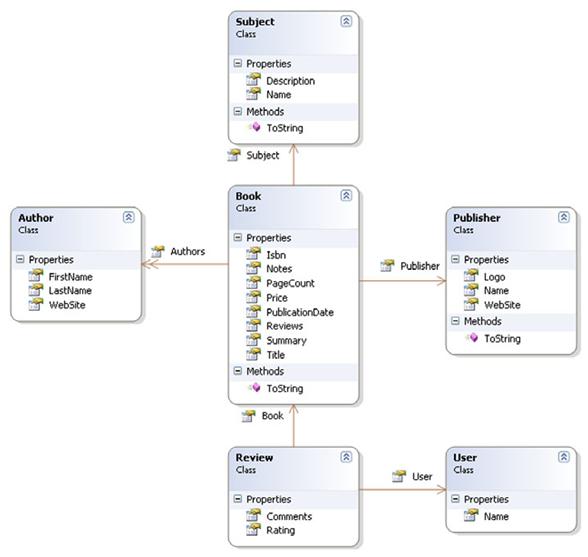
在进入本章以前,有必要了解LINQ能够查询哪些内存对象。
能够使用LINQ查询的内存对象
不是所有的内存对象都可以使用LINQ来查询。正如前面说道的,能够使用LINQ查询的内存对象必须实现了IEnumerable<T>接口。我们称实现了IEnumerable<T>接口的内存对象为序列。因为在使用LINQ处理的时候就像是一个工厂按步骤处理原材料一样。所幸的是所有的.NET泛型集合都实现了IEnumerable<T>接口。也就是说我们可以对所有的.NET泛型对象集合使用LINQ查询。下面是关于所有这些泛型集合的简单示例。
Arrays
我们可以对任何类型的数据使用LINQ查询。包括多种类型的对象组成的集合。如:
|
Object[] array = { "string", 12, true, 'a' }; var types = array.Select(item => item.GetType().Name) .OrderBy(type => type); |
下面是执行结果:
|
Boolean Char Int32 String |
此外,还可以为自定义的对象集合使用LINQ操作。如下,就是对示例中的Book类使用LINQ操作。
|
Book[] books = { new Book{Title = "LINQ in Action"}, new Book{Title = "LINQ for Fun"}, new Book{Title = "Extreme LINQ"} }; var titles = books .Where(book => book.Title.Contains("Action")) .Select(book => book.Title); |
返回的结果为” LINQ in Action”。
由此可见,对于普通的数据,我们可以很方便的使用LINQ来遍历其中的元素。这对于我们在程序中处理数据是很方便的。
泛型List
在.NET中使用最为广泛的集合无疑是泛型的List。泛型的List包括:
· System.Collections.Generic.List<T>
· System.Collections.Generic.LinkedList<T>
· System.Collections.Generic.Queue<T>
· System.Collections.Generic.Stack<T>
· System.Collections.Generic.HashSet<T>
· System.Collections.ObjectModel.Collection<T>
· System.ComponentModel.BindingList<T>
在这里,我们仅对List<T>举一个简单的例子。其他的泛型List由于结构的不同在操作上可能有所不同。
|
List<Book> books = new List<Book>{ new Book{Title = "LINQ in Action"}, new Book{Title = "LINQ for Fun"}, new Book{Title = "Extreme LINQ"} }; var titles = books .Where(book => book.Title.Contains("Action")) .Select(book => book.Title); |
输出的结果和上面的一样,是” LINQ in Action”。
泛型字典
另外一个可以使用LINQ操作的常用集合是泛型字典(Generical Dictionary)。.NET中的泛型字典包括:
· System.Collections.Generic.Dictionary<TKey,TValue>
· System.Collections.Generic.SortedDictionary<TKey, TValue>
· System.Collections.Generic.SortedList<TKey, TValue>
泛型字典实现了IEnumerable<KeyValuePair<TKEY, TVALUE>>。KeyValuePair结构中包含了Key和Value的属性。下面是一个简单的示例:
|
Dictionary<int, string> frenchNumbers = new Dictionary<int, string>(); frenchNumbers.Add(0, "Zero"); frenchNumbers.Add(1, "un"); frenchNumbers.Add(2, "deux"); frenchNumbers.Add(3, "toris"); frenchNumbers.Add(4, "quatre"); var evenNumbers = from item in frenchNumbers where item.Key % 2 == 0 select item.Value; |
处理结果为:
|
Zero deux quatre |
字符串
通常,字符串并不当成一个集合。但实际上.NET的字符串实现了IEnumerable<Char>接口。因此,我们也可以对字符串使用LINQ。如:
|
string strLine = "Non-letter characters in this string: 8"; var NonLetterCount = strLine .Where(c => !Char.IsLetter(c)) .Count(); |
处理结果为8。即有8个非字母字符。
可能你也注意到了,在string的只能语法提示中没有IEnumerable<T>的扩展方法。但是,我们还是可以使用它们。
除了上面提到的数据、泛型List、泛型字典和字符串以外,其他实现了IEnumerable<T>的结合都可以使用LINQ来查询。对于实现了非泛型的IEnumerable集合,如:DataSet和ArrayList等,我们也可以使用LINQ查询,但是需要做一些特殊处理。后面将会提到。
一些主要的标准查询操作符
下面将会介绍一些主要的标准操作符。在书中包含了如何将查询结果绑定到ASP.NET和WinForm。为了不分散注意力,我把这方面的内容虑过了。有兴趣的话可以参考原书。
条件操作符where
Where操作符用来从数据源中过滤满足给定条件的数据。下面是该扩展方法的定义:
|
public static IEnumerable<T> Where<T>( this IEnumerable<T> source, Func<T, bool> predicate); |
例如,可以使用下面的查询列出价格在15以上的书:
|
var books = SampleData.Books.Where(book => book.Price >= 15); |
使用查询表达式的写法如下,需要注意的是,使用查询表达式的时候必须带一个select语句。
|
var books = from book in SampleData.Books where book.Price >= 15 select book; |
Where还有一个重载版本,定义如下:
|
public static IEnumerable<T> Where<T>( this IEnumerable<T> source, Func<T, int, bool> predicate); |
使用重载版本,我们可以根据index来指定记录。如,下面的查询返回价格在15以上的前两条记录:
|
var books = SampleData.Books.Where( (book, index) => (book.Price >= 15) && index > 2); |
使用查询表达式的时候不能使用重载版本(注:个人认为不行。需要确认。)。
Select
Select用来选择要抽出的字段或者说属性。可以像SQL一样取别名等。下面是Select扩展方法的定义:
|
public static IEnumerable<S> Select<T, S>( this IEnumerable<T> source, Func<T, S> selector); |
下面的示例从Books中选择出所有Book的标题:
|
var books = SampleData.Books.Select(book => book.Title); |
对应的LINQ表达式写法为:
|
var books = from book in SampleData.Books select book.Title; |
也可以在Select中使用匿名类型。如:
|
var books = from book in SampleData.Books select new { Title = book.Title, Publisher = book.Publisher.Name, Author = book.Authors.First().LastName }; |
SelectMany
在说明SelectMany以前先来看一种情况。从给定的示例数据中我们知道,一个Book对象可能有多个Author。因此,Book的Authors属性背身就是一个集合。如果我们需要列出所有Book的所有Author应该怎么做?下面是一种可供选择的方法:
|
var temp = SampleData.Books.Select(book => book.Authors); foreach (var authors in temp) { foreach (var author in authors) { Console.WriteLine(author.FirstName + " " + author.LastName); } } |
很明显,这样的做法不能让人满意。LINQ的SelectMany为我们提供了另一种选择。下面是LINQ操作符的写法:
|
var authors = SampleData.Books.SelectMany(book => book.Authors); |
这就大大的简化了代码。实际上,SelectMany返回的也是一个IEnumberable<T>的实例。下面是SelectMany的定义:
|
public static IEnumerable<S> SelectMany<T, S>( this IEnumerable<T> source, Func<T, IEnumerable<S>> selector); |
注意粗体部分,这也是与Select显著不同的地方。表明它的返回仍然是一个IEnumerable<S>的实例。
在LINQ表达式不提供对SelectMany的支持,但是可以使用多个From语句实现相同的功能:
|
var authors = from book in SampleData.Books from author in book.Authors select author.FirstName + " " + author.LastName; |
相比较下,个人认为使用LINQ表达式更有灵活性。例如,我们需要在列出所有的作者的同时列出书名。使用LINQ操作符就不能实现。但是,使用LINQ表达式就很容易了:
|
var authors = from book in SampleData.Books from author in book.Authors select new {Title = book.Title, Author = author.FirstName + " " + author.LastName}; |
另外需要说明一下,Select和SelectMany都支持在LINQ操作符中使用Index。但是在LINQ表达式中还是不能使用。下面是一个例子:
|
var books = SampleData.Books.Select((book, index) => new { index, Title = book.Title }) .OrderBy(book => book.Title); |
Distinct
与SQL一样,LINQ也使用Distinct来除去重复数据。只是由于C#是强类型语言,在判断是不是重复的时候需要实现IEquatable<T>接口,通过使用Equals方法来判断是否重复。如果没有实现IEquatable<T>接口,将使用Object.Equals()方法进行比较。所以,我们可以自定义比较方式。有兴趣的话可以查查看。
下面的示例是选出所有出过书的作者:
|
var authors = SampleData.Books .SelectMany(book => book.Authors) .Distinct() .Select(author => author.FirstName + " " + author.LastName); |
运行结果为:
|
Johnny Good Graziella Simplegame Octavio Prince Jeremy Legrand Jeremy Prince |
注意:对于比较,我有点迷惑。一般的情况下我们都没有实现IEquatable<T>接口。所以会使用Object.Equals()方法进行比较。但是,我在自定义对象中重载了Equals函数后视乎仍然没有作用。下面是我定义的Author类:
|
using System; using System.Collections.Generic; using System.Text; namespace LinqInAction.LinqBooks.Common { public class Author { public String FirstName {get; set;} public String LastName {get; set;} public String WebSite { get; set;} public override bool Equals(object obj) { Author objAuthor = (Author)obj; return this.FirstName == objAuthor.FirstName; } } } |
然后,再进行查询,结果仍然为:
|
Johnny Good Graziella Simplegame Octavio Prince Jeremy Legrand Jeremy Prince |
在重载的Equals中,我将FirstName相同的Author判定为相同。但运行结果明显不是我想要的。这个问题有待于进一步研究。这里做个标记。
转换操作符
使用转化操作符,LINQ可以将一个序列转化为其他的集合。常用的转换操作符有:ToList()、ToArray()和ToDictionary()。在前面我们已经知道,使用转换操作符将会使查询立即执行,并拷贝一个镜像到另外一个集合。这样,但查询的数据源发生改变的时候我们镜像(即,转换后的集合)就不会同步更新。但是,有的时候我们需要使用转换操作。一种通常的情况是当我们在using模块中使用查询的时候,由于退出using的时候已经关闭了数据连接。使得查询就不再有效。因此,常用的做法是在退出using模块以前拷贝一份镜像在另外一个集合中,这样我们就可以在using模块以外使用数据了。这里就不再多说。
需要特别提一下的是ToDictionary()。从名字可知,它将序列转化为一个Dictionary。因此,我们需要提供一个参数作为KEY值。如下面的代码表示要将序列转化为一个Dictionary,KEY值设为ISBN:
|
var books = SampleData.Books.ToDictionary(book => book.Isbn); |
需要注意的是,指定的KEY值是不能重复的。因为Dictionary的KEY值就是唯一的。如果指定了一个重复的KEY值将会导致运行时的错误。如下面的示例,Books的Publisher就是重复的,就不能使用Publisher作为KEY值:
|
var books = SampleData.Books.ToDictionary(book => book.Publisher); |
聚集操作符
通常说的聚集操作符包括:
· Count:取得集合中的记录数。
· Sum:计算数字项目的和(注意是数字项目)。
· Min和Max:对集合中的数字项目找出最大值和最小值(注意是数字项目)。
下面是他们的使用方法的示例。由于没有什么特别的,因此就不多做描述。只是提醒注意他们的使用方法。下面的使用方法都是合法的。
|
var books = SampleData.Books.ToDictionary(book => book.Publisher); var minPrice = SampleData.Books.Min(book => book.Price); var maxPrice = SampleData.Books.Select(book => book.Price).Max(); var totalPrice = SampleData.Books.Sum(book => book.Price); var nbCheapBooks = SampleData.Books.Where(book => book.Price < 30).Count(); |
OrderBy,ThenBy,OrderByDescending,ThenByDescending
与SQL中一样,OrderBy用来对记录进行排序。需要说明的是这里的排序、下面的嵌入查询和连接查询都是在内存中创建一个查询对象的新视图来仅此那个操作。下面是OderBy的一个例子:
|
var result = from book in SampleData.Books orderby book.Publisher.Name, book.Price descending, book.Title select new { Publisher = book.Publisher.Name, Price = book.Price, Title = book.Title }; ObjectDumper.Write(result); |
注意:ObjectDumper是MS在示例代码中提供的方法。
上面的代码被编译为IL代码的时候如下:
|
ObjectDumper.Write(SampleData.Books.OrderBy<Book, string>(delegate(Book book) { return book.Publisher.Name; }).ThenByDescending<Book, decimal>(delegate(Book book) { return book.Price; }).ThenBy<Book, string>(delegate(Book book) { return book.Title; }).Select(delegate(Book book) { return new { Publisher = book.Publisher.Name, Price = book.Price, Title = book.Title }; })); |
可以看出,当几个OrderBy连接在一起的时候,编译器在编译的时候实际上是按顺序调用对应的扩展方法。另外,在这里你也可以看见LINQ查询是怎么样被延迟执行的。
嵌入查询
考虑这样的情况,假设需要查询每个出版社及其发行的书的名字。应该怎么做?下面的做法是一个可选的方式:
|
var result = from book in SampleData.Books select new { Publisher = book.Publisher.Name, Book = book.Title }; |
上面的查询结果如下,可以看见,这并不能给我们一个有层次的、直观的感受:
|
Publisher=FunBooks Book=Funny Stories Publisher=Joe Publishing Book=LINQ rules Publisher=Joe Publishing Book=C# on Rails Publisher=Joe Publishing Book=All your base are belong to us Publisher=FunBooks Book=Bonjour mon Amour |
使用嵌入查询,我们可以这样做:
|
var result = from publisher in SampleData.Publishers select new { Publisher = publisher.Name, Book = from book in SampleData.Books where book.Publisher.Name == publisher.Name select book.Title }; |
查询的结果大致如下,注意到I Publisher没有对应的Book。
|
FunBooks |
Funny Stories Bonjour mon Amour |
|
Joe Publishing |
LINQ rules C# on Rails All your base are belong to us |
|
I Publisher |
|
Grouping
我们可以使用Grouping实现和上面一样的效果。代码如下:
|
var result = from book in SampleData.Books group book by book.Publisher into pubBooks select new { Publisher = pubBooks.Key.Name, Book = from pubBook in pubBooks select pubBook.Title, Count = pubBooks.Count() }; |
执行结果大致如下:
|
FunBooks |
Funny Stories Bonjour mon Amour |
2 |
|
Joe Publishing |
LINQ rules C# on Rails All your base are belong to us |
3 |
先看看group … by… into … 是怎么工作的。通过使用上面的表达式,所有的属于同一个Publisher的书都会被聚集到一个pubBooks中。pubBooks是一个IGrouping<TKey, T>的实例。IGrouping<TKey, T>的定义如下:
|
public interface IGrouping<TKey, T> : IEnumerable<T> { TKey Key { get; } } |
因此,它也实现了IEnumerable<T>接口。它的内存布局应该形如:
|
KEY |
BOOKS |
|
FunBooks |
Books published by FunBooks |
|
Joe Publishing |
Books published by Joe Publishing |
|
I Publisher |
Books published by I Publisher |
需要注意的是每一个KEY对应的BOOKS也是一个IEnumberable<T>集合。我们可以多这个集合进行IEnumerable<T>的所有操作。如,上面用的求和。
和嵌入查询相比,group… by… into… 至少有两个优点:
1. 更简洁易读。
2. 可以对分组取别名,从而允许我们在同一个查询内多次使用分组结果。
3. 对比结果我们可以知道,嵌入查询由于是以Publisher为主表,因此查出了没有对应Book的记录。而分组查询以Books为主表,避免了这个问题。
数据源的连接
同SQL一样,LINQ的数据源连接也有内联(Inner Join)、左外联(Left Outter Join)和笛卡尔连接。此外,还有一种分组连接。下面依次介绍。
内联(Inner Join)
内联使两个数据源按照给定的条件连接在一起组成一个查询序列。需要说明的是内联的时候两个数据源之间没有主从关系。这样以来,就不会存在一个数据源的空数据被抽出。
|
var resultInnerJoin = from publisher in SampleData.Publishers join book in SampleData.Books on publisher equals book.Publisher select new { Publisher = book.Publisher.Name, Book = book.Title }; |
需要注意的是,在equals的左边应该是from关键字后面的数据源;右边是join关键字后面的数据源。即,数据源应该按顺序出现在equals的左右。这个顺序不能乱,否则就会出错。
上面的输出结果大致为:
|
Publisher |
Book |
|
FunBooks |
Funny Stories |
|
Joe Publishing |
LINQ rules |
|
Joe Publishing |
C# on Rails |
|
Joe Publishing |
All your base are belong to us |
|
FunBooks |
Bonjour mon Amour |
使用LINQ操作符的表示如下:
|
var resultInnerOpt = SampleData.Books.Join( SampleData.Publishers, book => book.Publisher, publisher => publisher, (book, publisher) => new { Publisher = book.Publisher.Name, Book = book.Title }); |
由于表达式在编译的时候要转化为操作符,而操作符又与函数调用的参数有关。因此,在写表达式的时候一定要按照顺序。即,equals的左边写from关键字的数据源;右边写join后面的数据源。
左外联(Left Outer Join)
先来看看左外联的一个例子:
|
var resultLeft = from publisher in SampleData.Publishers join book in SampleData.Books on publisher equals book.Publisher into pubBooks from pubBook in pubBooks.DefaultIfEmpty() select new { Publisher = publisher.Name, Book = pubBook == default(Book) ? "(No Books)" : pubBook.Title }; |
左外联就有了主数据源和次数据源之分。在这里,Publisher是主数据源,Books是次数据源。上面的代码执行结果大致为:
|
Publisher |
Book |
|
FunBooks |
Funny Stories |
|
Joe Publishing |
LINQ rules |
|
Joe Publishing |
C# on Rails |
|
Joe Publishing |
All your base are belong to us |
|
FunBooks |
Bonjour mon Amour |
|
I Publisher |
(No Books) |
可以看见,多出了最后一条记录,它没有对应的Books。这正是外联要达到的效果。接下来可能要问内联和外联的关键区别在哪里呢?
先把上面的pubBooks.DefaultIfEmpty()改为pubBooks。然后再执行,我们就会发现,最后那条没有Books的数据没有了。那么可以确定,问题就处在这个DefaultIfEmpty()函数。实际上,每次连接LINQ都会先把它当作外联来处理,并产生一个集合。这个集合是附表的一个镜像,同时包含了一些空行,这些空行就是主表中存在但是附表不存在的记录的一个标示。使用这个集合的DefaultIfEmpty函数就可以得到一个包含这些空行的集合,而直接使用这个集合的话得到的就是内联之后的结果。另外需要注意的是join后面的数据源的生存周期仅在下一个from开启之前。对于上面的查询,我们在select中就不能再使用book变量了。
在IL代码中,Left Outer Join 最终调用的其实是GroupJoin。如下面:
|
ObjectDumper.Write(SampleData.Publishers.GroupJoin( SampleData.Books, delegate (Publisher publisher) { return publisher;}, delegate (Book book) { return book.Publisher;}, delegate (Publisher publisher, IEnumerable<Book> pubBooks) { return new { publisher = publisher, pubBooks = pubBooks };}) .SelectMany(delegate (<>f__AnonymousType6<Publisher, IEnumerable<Book>> <>h__TransparentIdentifier5a) { return <>h__TransparentIdentifier5a.pubBooks.DefaultIfEmpty<Book>();}, delegate (<>f__AnonymousType6<Publisher, IEnumerable<Book>> <>h__TransparentIdentifier5a, Book pubBook) { return new { Book = (pubBook == null) ? "(No Books)" : pubBook.Title, Publisher = pubBook.Publisher.Name };})); |
很复杂,也看不明白。
有一点要特别注意,对于外联,如果使用了.DefaultIfEmpty那么在使用副表的使用一定要使用default(Book)之类的东西。否则遇见空的项目的时候就会出错。而如果没有使用.DefaultIfEmpty函数就无所谓了,因为这个时候相当于内联,不会出现对应副表记录为空的记录。
笛卡尔连接(Cross Join)
笛卡尔积就很简单了,它将列出所有的可能组合。如:
|
var result = from publisher in SampleData.Publishers from book in SampleData.Books select new { Match = (book.Publisher == publisher), Publisher = publisher.Name, Book = book.Title }; |
上面的处理结果如下:
|
Match=True Publisher=FunBooks Book=Funny Stories Match=False Publisher=FunBooks Book=LINQ rules Match=False Publisher=FunBooks Book=C# on Rails Match=False Publisher=FunBooks Book=All your base are belong to us Match=True Publisher=FunBooks Book=Bonjour mon Amour Match=False Publisher=Joe Publishing Book=Funny Stories Match=True Publisher=Joe Publishing Book=LINQ rules Match=True Publisher=Joe Publishing Book=C# on Rails Match=True Publisher=Joe Publishing Book=All your base are belong to us Match=False Publisher=Joe Publishing Book=Bonjour mon Amour Match=False Publisher=I Publisher Book=Funny Stories Match=False Publisher=I Publisher Book=LINQ rules Match=False Publisher=I Publisher Book=C# on Rails Match=False Publisher=I Publisher Book=All your base are belong to us Match=False Publisher=I Publisher Book=Bonjour mon Amour |
GroupJoin
下面是一个Grouo Join的例子
|
var resultGroup = from book in SampleData.Books group book by book.Publisher into publisherBooks select new { Publisher=publisherBooks.Key.Name, Books=publisherBooks }; |
上面的代码将Books中的记录按Publisher分类。并将分类的结果保存在publisherBooks中。然后再从这个集合中处理数据。在前面有这样的说明。这里就不多说了。
Skip & Take
书中还介绍了Skip和Take的相关内容。这里只简单的举几个例子:
|
var resultPartitining = SampleData.Books.Select((book, index) => new { Index = index, Book = book.Title }) .Skip(startIndex).Take(endIndex - startIndex + 1); |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号