

Kafka学习
Kafka是一种基于发布订阅模式的分布式的消息队列系统,原本开发自LinkedIn,用作LinkedIn的活动流(ActivityStream)和运营数据处理管道(Pipeline)的基础。现在它已被多家不同类型的公司作为多种类型的数据管道和消息系统使用。具有高吞吐量、高可用、高可扩展性等特点。
消息队列发展简史:ActiveMQ、RabbitMQ、Kafka、RocketMQ、PulSar

总结:
概念:
逻辑上:Topic、Producer、Consumer、Consumer Group
物理上:Broker、Partition、Replication、Segment
特点:分布式、高吞吐量、高可用、高可扩展性、数据只在Partition内有序等
高写性能(高吞吐量)的原因:(可参阅分布式数据库提高写入速度的原理,万变不离其宗)
存储方Broker:
设计上:分Partition以支持高并发并行读写
利用内存:WAL延迟持久化、批量持久化
磁盘写的策略:顺序追加写(append)、只增不减(append only)、采用OS页缓存而非Java堆缓存、零拷贝等
发送方Producer:攒一定数据量再发送以减少IO
高可扩展性(水平扩展):通过增加 topic 的 partition 数实现。
存在的问题:
使用OS缓存若刷盘不及时可能丢数据。解决:配置OS即时刷盘。
数据分布不均:数据分布容易不均匀,依赖于写入时的分区策略。
扩容问题:节点增减或replication变化时需要全量复制partition数据,代价高效率低。
改进:Kafka的替代者PulSar——存算分离、对等模式、quorum写入。可参阅此文章。
随着 Kafka 的发展,它的定位已经从“分布式消息队列”变成了“分布式流处理平台”,添加了 Connector 及 Stream Processor 的概念。只是这些并不改变它的基本概念和结构。
(有点像流水账,好记性不如烂笔头,权记于此以备忘)
以下为正文
=========================
1 Kafka消息队列简介
1.1 基本术语
-
BrokerKafka集群包含一个或多个服务器,这种服务器被称为broker
-
Topic每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
-
PartitionPartition是物理上的概念,每个Topic包含一个或多个Partition. 消息id只在一个partition内唯一,消息也只在一个partition内有序。
-
Producer负责发布消息到Kafka broker
-
Consumer消息消费者,向Kafka broker读取消息的客户端。
-
Consumer Group每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
1.2 消息队列
1.2.2 消息格式
- 一个topic对应一种消息格式,因此消息用topic分类
- 一个topic代表的消息有1个或者多个patition(s)组成
- 一个partition中
- 一个partition应该存放在一到多个server上
- 如果只有一个server,就没有冗余备份,是单机而不是集群
- 如果有多个server
- 一个server为leader,其他servers为followers;leader需要接受读写请求;followers仅作冗余备份;leader出现故障,会自动选举一个follower作为leader,保证服务不中断;每个server都可能扮演一些partitions的leader和其它partitions的follower角色,这样整个集群就会达到负载均衡的效果
- 消息按顺序存放,顺序不可变
- 只能追加消息,不能插入
- 每个消息都有一个offset,用作消息ID, 在一个partition中唯一
- offset由consumer保存和管理,因此读取顺序实际上是完全有consumer决定的,不一定是线性的
- 消息有超时日期,过期则删除
- 一个partition应该存放在一到多个server上
- 一个Consumer可以有多个线程进行消费,线程数应不多于topic的partition数,因为对于一个包含一或多消费线程的consumer group来说,一个partition只能分给其中的一个消费线程消费,且让尽可能多的线程能分配到partition(不过实际上真正去消费的线程及线程数还是由线程池的调度机制来决定)。这样如果线程数比partition数多,那么会有多出的线程,它们就不会消费到任何一个partition的数据而空转耗资源 。
- 如果consumer从多个partition读到数据,不保证数据间的顺序性,kafka只保证在一个partition上数据是有序的,但多个partition,根据你读的顺序会有不同
- 增减broker,partition会导致rebalance,所以rebalance后consumer对应的partition会发生变化
可见,对于一个 topic 消息的消费,partition与消费方允许多对一但不允许一对多:允许多个partition被consumer group中的一个consumer消费但不允许一个partition被其中的多个consumer消费;允许多个partition被一个consumer中的一个线程消费但不允许一个partition被其中的多个线程消费。即partition与一个consumer 中的线程是多对一的关系,这样保证了从一个partition读取到的是完整的且有序的数据。
2. 安装和使用
以kafka_2.11-0.10.0.0为例。
下载解压后,进入kafka_2.11-0.10.0.0/
2.1 启动Zookeeper
测试时可以使用Kafka附带的Zookeeper:
启动: ./bin/zookeeper-server-start.sh config/zookeeper.properties & ,config/zookeeper.properties是Zookeeper的配置文件。
结束: ./bin/zookeeper-server-stop.sh
不过最好自己搭建一个Zookeeper集群,提高可用性和可靠性。详见:Zookeeper的安装和使用——MarchOn
2.2 启动Kafka服务器
2.2.1 配置文件
配置config/server.properties文件,一般需要配置如下字段,其他按默认即可:
broker.id: 每一个broker在集群中的唯一表示,要求是正数 listeners(效果同之前的版本的host.name及port):注意绑定host.name,否则可能出现莫名其妙的错误如consumer找不到broker。这个host.name是Kafka的server的机器名字,会注册到Zookeeper中 log.dirs: kafka数据的存放地址,多个地址的话用逗号分割,多个目录分布在不同磁盘上可以提高读写性能 log.retention.hours: 数据文件保留多长时间, 存储的最大时间超过这个时间会根据log.cleanup.policy设置数据清除策略 zookeeper.connect: 指定ZooKeeper的connect string,以hostname:port的形式,可有多个以逗号分隔,如hostname1:port1,hostname2:port2,hostname3:port3,还可有路径,如:hostname1:port1,hostname2:port2,hostname3:port3/kafka,注意要事先在zk中创建/kafka节点,否则会报出错误:java.lang.IllegalArgumentException: Path length must be > 0
所有参数的含义及配置可参考:http://orchome.com/12、http://blog.csdn.net/lizhitao/article/details/25667831
一个配置示例如下:


1 # Licensed to the Apache Software Foundation (ASF) under one or more 2 # contributor license agreements. See the NOTICE file distributed with 3 # this work for additional information regarding copyright ownership. 4 # The ASF licenses this file to You under the Apache License, Version 2.0 5 # (the "License"); you may not use this file except in compliance with 6 # the License. You may obtain a copy of the License at 7 # 8 # http://www.apache.org/licenses/LICENSE-2.0 9 # 10 # Unless required by applicable law or agreed to in writing, software 11 # distributed under the License is distributed on an "AS IS" BASIS, 12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 13 # See the License for the specific language governing permissions and 14 # limitations under the License. 15 # see kafka.server.KafkaConfig for additional details and defaults 16 17 ############################# Server Basics ############################# 18 19 # The id of the broker. This must be set to a unique integer for each broker. 20 broker.id=1 21 22 ############################# Socket Server Settings ############################# 23 24 # The address the socket server listens on. It will get the value returned from 25 # java.net.InetAddress.getCanonicalHostName() if not configured. 26 # FORMAT: 27 # listeners = security_protocol://host_name:port 28 # EXAMPLE: 29 # listeners = PLAINTEXT://your.host.name:9092 30 listeners=PLAINTEXT://192.168.6.128:9092 31 32 # Hostname and port the broker will advertise to producers and consumers. If not set, 33 # it uses the value for "listeners" if configured. Otherwise, it will use the value 34 # returned from java.net.InetAddress.getCanonicalHostName(). 35 #advertised.listeners=PLAINTEXT://your.host.name:9092 36 37 # The number of threads handling network requests 38 num.network.threads=3 39 40 # The number of threads doing disk I/O 41 num.io.threads=8 42 43 # The send buffer (SO_SNDBUF) used by the socket server 44 socket.send.buffer.bytes=102400 45 46 # The receive buffer (SO_RCVBUF) used by the socket server 47 socket.receive.buffer.bytes=102400 48 49 # The maximum size of a request that the socket server will accept (protection against OOM) 50 socket.request.max.bytes=104857600 51 52 53 ############################# Log Basics ############################# 54 55 # A comma seperated list of directories under which to store log files 56 log.dirs=/usr/local/kafka/kafka_2.11-0.10.0.0/kfk_data/ 57 58 # The default number of log partitions per topic. More partitions allow greater 59 # parallelism for consumption, but this will also result in more files across 60 # the brokers. 61 num.partitions=2 62 auto.create.topics.enable=false 63 64 # The number of threads per data directory to be used for log recovery at startup and flushing at shutdown. 65 # This value is recommended to be increased for installations with data dirs located in RAID array. 66 num.recovery.threads.per.data.dir=1 67 68 ############################# Log Flush Policy ############################# 69 70 # Messages are immediately written to the filesystem but by default we only fsync() to sync 71 # the OS cache lazily. The following configurations control the flush of data to disk. 72 # There are a few important trade-offs here: 73 # 1. Durability: Unflushed data may be lost if you are not using replication. 74 # 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush. 75 # 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to exceessive seeks. 76 # The settings below allow one to configure the flush policy to flush data after a period of time or 77 # every N messages (or both). This can be done globally and overridden on a per-topic basis. 78 79 # The number of messages to accept before forcing a flush of data to disk 80 #log.flush.interval.messages=10000 81 82 # The maximum amount of time a message can sit in a log before we force a flush 83 #log.flush.interval.ms=1000 84 85 ############################# Log Retention Policy ############################# 86 87 # The following configurations control the disposal of log segments. The policy can 88 # be set to delete segments after a period of time, or after a given size has accumulated. 89 # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens 90 # from the end of the log. 91 92 # The minimum age of a log file to be eligible for deletion 93 log.retention.hours=4 94 95 # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining 96 # segments don't drop below log.retention.bytes. 97 #log.retention.bytes=1073741824 98 99 # The maximum size of a log segment file. When this size is reached a new log segment will be created. 100 log.segment.bytes=1073741824 101 102 # The interval at which log segments are checked to see if they can be deleted according 103 # to the retention policies 104 log.retention.check.interval.ms=300000 105 106 ############################# Zookeeper ############################# 107 108 # Zookeeper connection string (see zookeeper docs for details). 109 # This is a comma separated host:port pairs, each corresponding to a zk 110 # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". 111 # You can also append an optional chroot string to the urls to specify the 112 # root directory for all kafka znodes. 113 zookeeper.connect=192.168.6.131:2181,192.168.6.132:2181,192.168.6.133:2181 114 115 # Timeout in ms for connecting to zookeeper 116 zookeeper.connection.timeout.ms=6000
注意:
auto.create.topics.enable 字段,默认为true。若为true则如果producer写入某个不存在的topic时会自动创建该topic,若为false则需要事先创建否则会报错:failed after 3 retries。
可通过 broker.id.generation.enable 和 reserved.broker.max.id 来配合生成新的 broker.id。默认分别为true、1000。前者表示启不启用自动生成、后者表示自动生成的id不小于的值,可见默认情况下会自动生成broker id且值从1001起。
体会下这里zk地址配置为啥要列上所有zk节点?因为zk是作为协调服务出现在这的,其有可能有节点故障,若只列一个,有可能那个地址对应的节点挂了,所以要全列上。
2.2.2 命令
启动: bin/kafka-server-start.sh config/server.properties ,生产环境最好以守护程序启动:nohup &
结束: bin/kafka-server-stop.sh
2.2.3 Kafka在Zookeeper中的存储结构
若上述的zookeeper.connect的值没有路径,则为根路径,启动Zookeeper和Kafka,命令行连接Zookeeper后,用 get / 命令可发现有 consumers、config、controller、admin、brokers、zookeeper、controller_epoch 这几个目录。
其结构如下:(具体可参考:apache kafka系列之在zookeeper中存储结构)
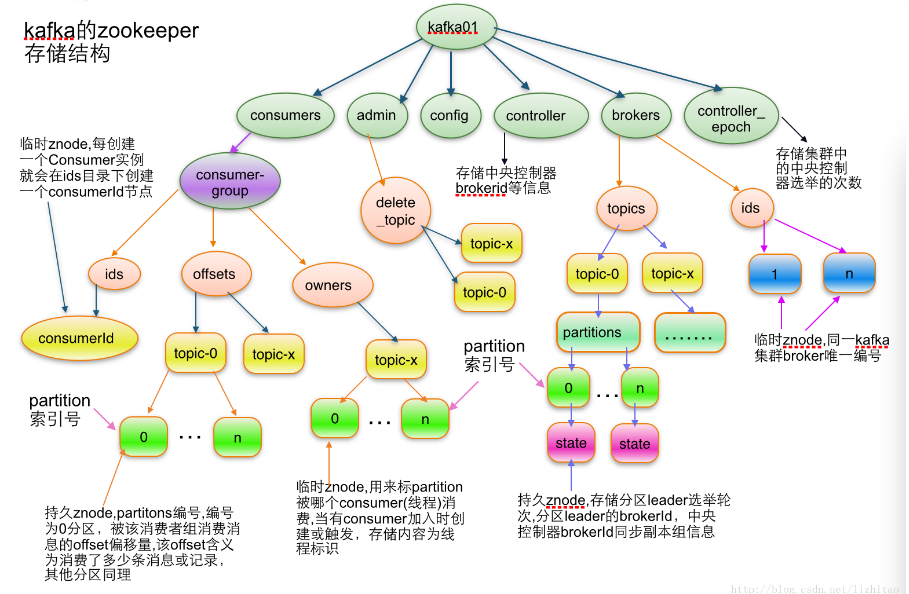
主要znode的作用:
/brokers/ids 目录:当加入一个kafka节点时,会在该目录下创建临时znode节点、节点值为broker.id
/controller 目录:用于“抢占坑位”来选举一个broker作为controller
/consumers/${consumer-group-name} 目录:存储消费组元数据及消费进度(offset)信息
2.3 使用
kafka本身是和zookeeper相连的,而对应producer和consumer的状态保存也都是通过zookeeper完成的。对Kafka的各种操作通过其所连接的Zookeeper完成。
2.3.1 命令行客户端
创建topic: bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
列出所有topic: bin/kafka-topics.sh --list --zookeeper localhost:2181
查看topic信息(包括分区、副本情况等): kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic ,会列出分区数、副本数、副本leader节点、副本节点、活着的副本节点
往某topic生产消息: bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
从某topic消费消息: bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning (默认用一个线程消费指定topic的所有分区的数据)
删除某个Kafka groupid:连接Zookeeper后用rmr命令,如删除名为JSI的消费组: rmr /consumers/JSI
查看消费进度:
./bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group test-mirror-consumer-zsm --zkconnect ec2-12345.cn-north-1.compute.amazonaws.com.cn:2181/kafka/blink/0822 --topic GPS2 各参数: --group指MirrorMaker消费源集群时指定的group.id -zkconnect指源集群的zookeeper地址 --topic指定查的topic,没指定则返回所有topic的消费情况
2.3.2 Java客户端
1、Topic操作:
1 import kafka.admin.DeleteTopicCommand; 2 import kafka.admin.TopicCommand; 3 4 /** 5 * @author zsm 6 * @date 2016年9月27日 上午10:26:42 7 * @version 1.0 8 * @parameter 9 * @since 10 * @return 11 */ 12 public class JTopic { 13 public static void createTopic(String zkAddr, String topicName, int partition, int replication) { 14 String[] options = new String[] { "--create", "--zookeeper", zkAddr, "--topic", topicName, "--partitions", 15 partition + "", "--replication-factor", replication + "" }; 16 TopicCommand.main(options); 17 } 18 19 public static void listTopic(String zkAddr) { 20 String[] options = new String[] { "--list", "--zookeeper", zkAddr }; 21 TopicCommand.main(options); 22 } 23 24 public static void describeTopic(String zkAddr, String topicName) { 25 String[] options = new String[] { "--describe", "--zookeeper", zkAddr, "--topic", topicName, }; 26 TopicCommand.main(options); 27 } 28 29 public static void alterTopic(String zkAddr, String topicName) { 30 String[] options = new String[] { "--alter", "--zookeeper", zkAddr, "--topic", topicName, "--partitions", "5" }; 31 TopicCommand.main(options); 32 } 33 34 // 通过删除zk里面对应的路径来实现删除topic的功能,只会删除zk里面的信息,Kafka上真实的数据并没有删除 35 public static void deleteTopic(String zkAddr, String topicName) { 36 String[] options = new String[] { "--zookeeper", zkAddr, "--topic", topicName }; 37 DeleteTopicCommand.main(options); 38 } 39 40 public static void main(String[] args) { 41 // TODO Auto-generated method stub 42 43 String myTestTopic = "ZsmTestTopic"; 44 int myPartition = 4; 45 int myreplication = 1; 46 47 //createTopic(ConfigureAPI.KafkaProperties.ZK, myTestTopic, myPartition, myreplication); 48 // listTopic(ConfigureAPI.KafkaProperties.ZK); 49 describeTopic(ConfigureAPI.KafkaProperties.ZK, myTestTopic); 50 // alterTopic(ConfigureAPI.KafkaProperties.ZK, myTestTopic); 51 // deleteTopic(ConfigureAPI.KafkaProperties.ZK, myTestTopic); 52 } 53 54 }
2、写:(写时可以指定key以供Kafka根据key将数据写入某个分区,若无指定,则几乎就是随机找一个分区发送无key的消息,然后把这个分区号加入到缓存中以备后面直接使用——当然,Kafka本身也会清空该缓存(默认每10分钟或每次请求topic元数据时))
1 package com.zsm.kfkdemo; 2 3 import java.util.ArrayList; 4 import java.util.List; 5 import java.util.Properties; 6 7 import com.zsm.kfkdemo.ConfigureAPI.KafkaProperties; 8 9 import kafka.javaapi.producer.Producer; 10 import kafka.producer.KeyedMessage; 11 import kafka.producer.ProducerConfig; 12 13 /** 14 * 可以指定规则(key和分区函数)以让消息写到特定分区: 15 * <p> 16 * 1、若发送的消息没有指定key则Kafka会随机选择一个分区 17 * </p> 18 * <p> 19 * 2、否则,若指定了分区函数(通过partitioner.class)则该函数以key为参数确定写到哪个分区 20 * </p> 21 * <p> 22 * 3、否则,Kafka根据hash(key)%partitionNum确定写到哪个分区 23 * </p> 24 * 25 * @author zsm 26 * @date 2016年9月27日 上午10:26:42 27 * @version 1.0 28 * @parameter 29 * @since 30 * @return 31 */ 32 public class JProducer extends Thread { 33 private Producer<String, String> producer; 34 private String topic; 35 private final int SLEEP = 10; 36 private final int msgNum = 1000; 37 38 public JProducer(String topic) { 39 Properties props = new Properties(); 40 props.put("metadata.broker.list", KafkaProperties.BROKER_LIST);// 如192.168.6.127:9092,192.168.6.128:9092 41 // request.required.acks 42 // 0, which means that the producer never waits for an acknowledgement from the broker (the same behavior as 0.7). This option provides the lowest latency but the weakest durability guarantees 43 // (some data will be lost when a server fails). 44 // 1, which means that the producer gets an acknowledgement after the leader replica has received the data. This option provides better durability as the client waits until the server 45 // acknowledges the request as successful (only messages that were written to the now-dead leader but not yet replicated will be lost). 46 // -1, which means that the producer gets an acknowledgement after all in-sync replicas have received the data. This option provides the best durability, we guarantee that no messages will be 47 // lost as long as at least one in sync replica remains. 48 props.put("request.required.acks", "-1"); 49 // 配置value的序列化类 50 props.put("serializer.class", "kafka.serializer.StringEncoder"); 51 // 配置key的序列化类 52 props.put("key.serializer.class", "kafka.serializer.StringEncoder"); 53 // 提供自定义的分区函数将消息写到分区上,未指定的话Kafka根据hash(messageKey)%partitionNum确定写到哪个分区 54 props.put("partitioner.class", "com.zsm.kfkdemo.MyPartitioner"); 55 producer = new Producer<String, String>(new ProducerConfig(props)); 56 this.topic = topic; 57 } 58 59 @Override 60 public void run() { 61 boolean isBatchWriteMode = true; 62 System.out.println("isBatchWriteMode: " + isBatchWriteMode); 63 if (isBatchWriteMode) { 64 // 批量发送 65 int batchSize = 100; 66 List<KeyedMessage<String, String>> msgList = new ArrayList<KeyedMessage<String, String>>(batchSize); 67 for (int i = 0; i < msgNum; i++) { 68 String msg = "Message_" + i; 69 msgList.add(new KeyedMessage<String, String>(topic, i + "", msg)); 70 // msgList.add(new KeyedMessage<String, String>(topic, msg));//未指定key,Kafka会自动选择一个分区 71 if (i % batchSize == 0) { 72 producer.send(msgList); 73 System.out.println("Send->[" + msgList + "]"); 74 msgList.clear(); 75 try { 76 sleep(SLEEP); 77 } catch (Exception ex) { 78 ex.printStackTrace(); 79 } 80 } 81 } 82 producer.send(msgList); 83 } else { 84 // 单个发送 85 for (int i = 0; i < msgNum; i++) { 86 KeyedMessage<String, String> msg = new KeyedMessage<String, String>(topic, i + "", "Message_" + i); 87 // KeyedMessage<String, String> msg = new KeyedMessage<String, String>(topic, "Message_" + i);//未指定key,Kafka会自动选择一个分区 88 producer.send(msg); 89 System.out.println("Send->[" + msg + "]"); 90 try { 91 sleep(SLEEP); 92 } catch (Exception ex) { 93 ex.printStackTrace(); 94 } 95 } 96 } 97 98 System.out.println("send done"); 99 } 100 101 public static void main(String[] args) { 102 JProducer pro = new JProducer(KafkaProperties.TOPIC); 103 pro.start(); 104 } 105 }
3、读:(对于Consumer,需要注意 auto.commit.enable 和 auto.offset.reset 这两个字段)
1 package com.zsm.kfkdemo; 2 3 import java.text.MessageFormat; 4 import java.util.HashMap; 5 import java.util.List; 6 import java.util.Map; 7 import java.util.Properties; 8 9 import com.zsm.kfkdemo.ConfigureAPI.KafkaProperties; 10 11 import kafka.consumer.Consumer; 12 import kafka.consumer.ConsumerConfig; 13 import kafka.consumer.ConsumerIterator; 14 import kafka.consumer.KafkaStream; 15 import kafka.javaapi.consumer.ConsumerConnector; 16 import kafka.message.MessageAndMetadata; 17 18 /** 19 * 同一consumer group的多线程消费可以两种方法实现: 20 * <p> 21 * 1、实现单线程客户端,启动多个去消费 22 * </p> 23 * <p> 24 * 2、在客户端的createMessageStreams里为topic指定大于1的线程数,再启动多个线程处理每个stream 25 * </p> 26 * 27 * @author zsm 28 * @date 2016年9月27日 上午10:26:42 29 * @version 1.0 30 * @parameter 31 * @since 32 * @return 33 */ 34 public class JConsumer extends Thread { 35 36 private ConsumerConnector consumer; 37 private String topic; 38 private final int SLEEP = 20; 39 40 public JConsumer(String topic) { 41 consumer = Consumer.createJavaConsumerConnector(this.consumerConfig()); 42 this.topic = topic; 43 } 44 45 private ConsumerConfig consumerConfig() { 46 Properties props = new Properties(); 47 props.put("zookeeper.connect", KafkaProperties.ZK); 48 props.put("group.id", KafkaProperties.GROUP_ID); 49 props.put("auto.commit.enable", "true");// 默认为true,让consumer定期commit offset,zookeeper会将offset持久化,否则只在内存,若故障则再消费时会从最后一次保存的offset开始 50 props.put("auto.commit.interval.ms", KafkaProperties.INTERVAL + "");// 经过INTERVAL时间提交一次offset 51 props.put("auto.offset.reset", "largest");// What to do when there is no initial offset in ZooKeeper or if an offset is out of range 52 props.put("zookeeper.session.timeout.ms", KafkaProperties.TIMEOUT + ""); 53 props.put("zookeeper.sync.time.ms", "200"); 54 return new ConsumerConfig(props); 55 } 56 57 @Override 58 public void run() { 59 Map<String, Integer> topicCountMap = new HashMap<String, Integer>(); 60 topicCountMap.put(topic, new Integer(1));// 线程数 61 Map<String, List<KafkaStream<byte[], byte[]>>> streams = consumer.createMessageStreams(topicCountMap); 62 KafkaStream<byte[], byte[]> stream = streams.get(topic).get(0);// 若上面设了多个线程去消费,则这里需为每个stream开个线程做如下的处理 63 64 ConsumerIterator<byte[], byte[]> it = stream.iterator(); 65 MessageAndMetadata<byte[], byte[]> messageAndMetaData = null; 66 while (it.hasNext()) { 67 messageAndMetaData = it.next(); 68 System.out.println(MessageFormat.format("Receive->[ message:{0} , key:{1} , partition:{2} , offset:{3} ]", 69 new String(messageAndMetaData.message()), new String(messageAndMetaData.key()), 70 messageAndMetaData.partition() + "", messageAndMetaData.offset() + "")); 71 try { 72 sleep(SLEEP); 73 } catch (Exception ex) { 74 ex.printStackTrace(); 75 } 76 } 77 } 78 79 public static void main(String[] args) { 80 JConsumer con = new JConsumer(KafkaProperties.TOPIC); 81 con.start(); 82 } 83 }
与Kafka相关的Maven依赖:
1 <dependency> 2 <groupId>org.apache.kafka</groupId> 3 <artifactId>kafka_2.9.2</artifactId> 4 <version>0.8.1.1</version> 5 <exclusions> 6 <exclusion> 7 <groupId>com.sun.jmx</groupId> 8 <artifactId>jmxri</artifactId> 9 </exclusion> 10 <exclusion> 11 <groupId>com.sun.jdmk</groupId> 12 <artifactId>jmxtools</artifactId> 13 </exclusion> 14 <exclusion> 15 <groupId>javax.jms</groupId> 16 <artifactId>jms</artifactId> 17 </exclusion> 18 </exclusions> 19 </dependency>
3 MirrorMaker
Kafka自身提供的MirrorMaker工具用于把一个集群的数据同步到另一集群,其原理就是对源集群消费、对目标集群生产。
运行时需要指定源集群的Zookeeper地址(pull模式)或目标集群的Broker列表(push模式)。
3.1 使用
运行 ./kafka-run-class.sh kafka.tools.MirrorMaker --help 查看使用说明,如下:
1 Option Description 2 ------ ----------- 3 --blacklist <Java regex (String)> Blacklist of topics to mirror. 4 --consumer.config <config file> Consumer config to consume from a 5 source cluster. You may specify 6 multiple of these. 7 --help Print this message. 8 --num.producers <Integer: Number of Number of producer instances (default: 9 producers> 1) 10 --num.streams <Integer: Number of Number of consumption streams. 11 threads> (default: 1) 12 --producer.config <config file> Embedded producer config. 13 --queue.size <Integer: Queue size in Number of messages that are buffered 14 terms of number of messages> between the consumer and producer 15 (default: 10000) 16 --whitelist <Java regex (String)> Whitelist of topics to mirror.
3.2 启动
./bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config zsmSourceClusterConsumer.config --num.streams 2 --producer.config zsmTargetClusterProducer.config --whitelist="ds*" --consumer.config所指定的文件里至少需要有zookeeper.connect、group.id两字段 --producer.config至少需要有metadata.broker.list字段,指定目标集群的brooker列表 --whitelist指定要同步的topic
可以用2.3.1所说的查看消费进度来查看对原集群的同步状况(即消费状况)。
4 Kafka监控工具(KafkaOffsetMonitor)
可以借助KafkaOffsetMonitor来图形化展示Kafka的broker节点、topic、consumer及offset等信息。
以KafkaOffsetMonitor-assembly-0.2.0.jar为例,下载后执行:
#!/bin/bash
java -Xms512M -Xmx512M -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -cp KafkaOffsetMonitor-assembly-0.2.0.jar \
com.quantifind.kafka.offsetapp.OffsetGetterWeb \
--zk 192.168.5.131:2181,192.168.6.132:2181,192.168.6.133:2181 \
--port 8087 \
--refresh 10.seconds \
--retain 1.days 1>./zsm-logs/stdout.log 2>./zsm-logs/stderr.log &
其中,zk按照host1:port1,host2:port2…的格式去写即可,port为开启web界面的端口号,refresh为刷新时间,retain为数据保留时间(单位seconds, minutes, hours, days)
5 Kafka集群管理工具(Kafka Manager)
kafka-manager是yahoo开源出来的项目,属于商业级别的工具用Scala编写。
这个管理工具可以很容易地发现分布在集群中的哪些topic分布不均匀,或者是分区在整个集群分布不均匀的的情况。它支持管理多个集群、选择副本、副本重新分配以及创建Topic。同时,这个管理工具也是一个非常好的可以快速浏览这个集群的工具。
此工具以集群的方式运行,需要Zookeeper。
参考资料:http://hengyunabc.github.io/kafka-manager-install/
5.1 安装
需要从Github下载源码并安装sbt工具编译生成安装包,生成的时间很长且不知为何一直出错,所以这里用网友已编译好的包 (备份链接)。
包为kafka-manager-1.0-SNAPSHOT.zip
>解压:
unzip kafka-manager-1.0-SNAPSHOT.zip
>配置conf/application.conf里的kafka-manager.zkhosts:
kafka-manager.zkhosts="192.168.6.131:2181,192.168.6.132:2181,192.168.6.133:2181"
>启动:
./bin/kafka-manager -Dconfig.file=conf/application.conf (启动后在Zookeeper根目录下可发现增加了kafka-manager目录)
默认是9000端口,要使用其他端口可以在命令行指定http.port,此外kafka-manager.zkhosts也可以在命令行指定,如:
./bin/kafka-manager -Dhttp.port=9001 -Dkafka-manager.zkhosts="192.168.6.131:2181,192.168.6.132:2181,192.168.6.133:2181"
5.2 使用
访问web页面,在Cluster->Add Cluster,输入要监控的Kafka集群的Zookeeper即可。
6 进阶/内部原理
Kafka 内部多个地方涉及到leader角色:controller(broker leader )、replication leader、consumer leader in consumer group。
6.1 消息生产(Producer工作)
6.1.1 消息投递语义
http://www.jasongj.com/kafka/transaction/
Kafka不同消息传递语义的场景:
1 at least once:发送端超时重传,导致消费端重复消费;消费端先处理数据再提交offset,两步中间出故障导致offset未提交,从而下次重复消费
2 at most once:消费端先提交offset再处理数据,两步中间出故障导致数据实际未处理
3 exactly once = 发送端超时重传 + 消费端业务上幂等去重。消费端须是先处理再提交offset否则解决不了上面at most once场景的问题。
超时重传:启用Kafka的ack机制,发送端往Kafka写数据时,收到确认才认为写入成功。若在时间阈值内未收到确认则认为Kafka写入失败,发送端进行重传。
幂等去重:Kafka消息有全局id,消费端消费消息时会记录最近成功消费的消息的id。在读一条新消息时,比较其id与最近成功处理的消息的id关系,若差值大于1则认为消息乱序从而拒绝处理、若小于1则认为该消息是发送端超时重传的从而丢弃。
单纯幂等去重是否可解决at least once、at most once问题与消费端的处理方式有关。只有【消费端“先处理再提交offset”的幂等去重 + 发送端超时重传】才能做到 exactly once语义。
具体是哪种语义,是由Kafka和使用方共同配合达成的。
6.1.2 消息发送原理
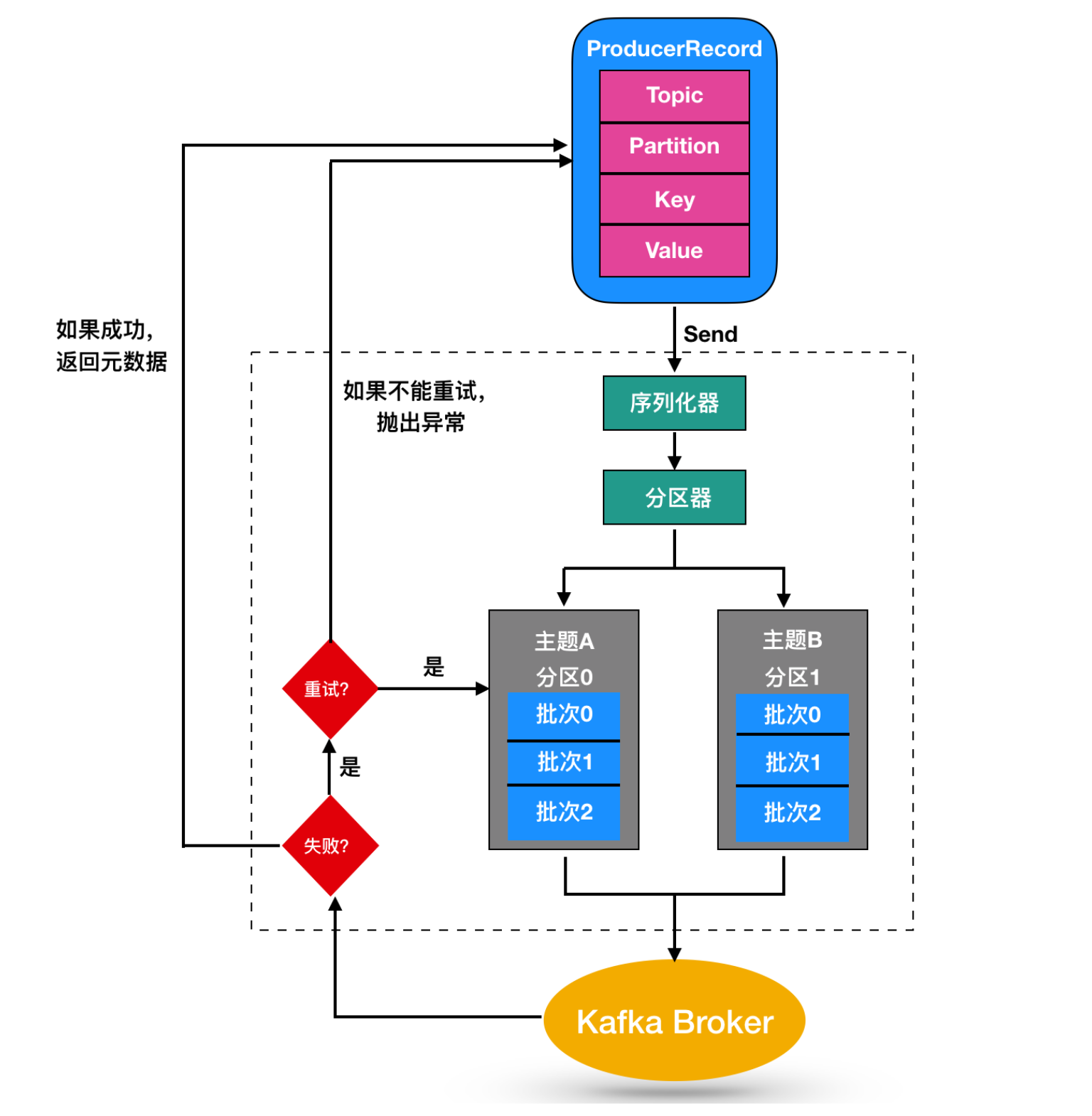
几个点:
分区策略:Producer发送数据前需要指定 topic、partiton。partition通过用户提供的分区策略确定分区、若用户无指定则内部默认会用轮询策略(老版用随机轮询、后来新版用顺序轮询以让数据分布更均匀)。分区策略应该:数据尽可能均匀分到各分区、使同key数据分到同分区(故分区策略通常是key的hash函数,显然轮询策略做不到这点)。
缓存批量发送:Producer会缓存数据到一定量后再批量发送到Broker以减少网络IO。数据按 topic+partition 缓存,见上图。
数据压缩发送:Kafka处理的单元是上述的数据批次,Producer内部在发送前会对一批次消息进行压缩,然后把压缩数据和压缩算法发送给Broker存储。Consumer消费出来时对应地进行解压。支持的压缩算法有 snappy、gzip、lz4等,压缩是时间换空间的做法,默认情况下不启用压缩。

发送示例:
private Properties properties = new Properties(); properties.put("bootstrap.servers","192.168.1.9:9092"); properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer"); properties.put("compression.type", "gzip"); Producer<String,String> producer = new KafkaProducer<String, String>(properties); ProducerRecord<String,String> record = new ProducerRecord<String, String>("CustomerCountry","Precision Products","France");
6.1.3 如何保证数据可靠(数据会丢失吗)?
严格来说,Kafka 只对 「已提交」的消息做「最大限度的持久化保证不丢失」(通过消息确认机制完成)。即严格来说,可能丢失,但有很多措施来最大限度保证已提交的并持久化的数据不丢失。
哪些措施最大限度保证已提交且持久化的数据不丢失:
单节点:WAL技术保证高写入效率的同时内存数据可靠。当然由于是用的OS页缓存,故即使持久化的数据也可能因未实际写入磁盘而丢失,故要配置OS的即时刷新策略或调用fsync命令强制刷盘。
多节点:数据冗余——partition多replication,各replication中一个leader多个follower,follower从leader同步数据(通过复制WAL的日志实现数据同步)。Kafka提供了不同级别的消息确认机制来在 系统可用性 与 数据可靠性/数据一致性 间作选择,通过参数 request.required.acks 控制(详情可参阅文章Kafka副本复制机制)
三种机制:
0 表示消息投出去即可,发送端不知也不管有没有被服务端接收,相当于无ack机制,类似于UDP协议只管发。生产环境不能用此机制。
1 表示被接收且leader replication持久化成功则认为写入成功。特点是吞吐量高,若生产环境要求高吞吐量且允许少量数据丢失则可用此机制。Kafka默认是此机制。
-1或all 表示被接收且leader和ISR中所有replication都持久化成功才认为写入成功。生产环境要求不能丢数据则用此机制。
通常认为不丢,但无法保证绝对不丢,与ISR包含的副本数有关(有配置项):若ISR中含该partition的所有副本则效果相当于所有partition写入完才认为成功(即 replication.factor= min.insync.replicas+1 ),此时就是强一致性的就是数据不丢失的。
这层ISR抽象使得Kafka与很多其他强一致性系统相比灵活性更强——可以据需要通过参数配置在可用性和一致性间权衡调整。
三种机制的数据可靠性依次增强但系统可用性依次减弱:第一种投出去就不管了从而有可能根本没写入Kafka;第二种即使写入成功也可能因写入后leader永久挂了从而各follower中均无该数据;第三种通常认为可靠但实际上也可能丢数据,例如ISR无内容即只有leader一个replication那么该replication挂了数据就丢了。
ISR、OSR:对于一个partition的不同replication,是通过从leader replication复制WAL log来同步数据的。Kafka会动态维护能即时复制(指标有 落后的数据条数、两次复制的时间间隔)的副本列表(称为ISR,In Sync Replication)和落后的副本列表(称为OSR,Out Sync Replication),当leader replication挂掉后会从ISR选新leader。
OSR包括:
慢副本(Slow Replication),持久化操作慢于数据生产效率导致。根据落后的数据条数是否大于参数 replica.lag.max.messages 检测到。
卡副本(Stuck Replication),GC停顿或副本故障导致未从leader同步。根据复制的时间间隔是否大于参数 replica.lag.time.max.ms 检测到,默认10s。
启动副本(Bootstrapping replica),给topic增加副本因子时新增的副本是这种。
6.1.4 数据丢失的场景和解决
(可参阅文章 Kafka到底会不会丢数据)
从上可知会丢失的场景有哪些:【数据根本未提交、数据提交但未持久化、数据提交并持久化了但没正确消费】,分别对应Producer、Broker、Consumer中的丢失场景。
Producer:
场景:
Producer内部会按 topic+分区 缓存一定量数据后再【压缩并批量】发送以减少IO,即使是一条条发送,也可能因【网络原因 或 消息体太大超过Broker接收范围(message.max.bytes,默认1MB)而拒收】从而丢失。
发送端发送数据,采用第一、第二、第三种ack机制。
解决:与上面对应
使用带回调通知函数的方法进行发送消息,即 Producer.send(msg, callback),收到发送失败事件时,进行超时重试或者调整消息内容。
采用第三种确认机制,且设置参数 replication.factor >= 2 min.insync.replicas > 1 防止ISR为空的情形。若为了最大限度保证事件可靠性则可进一步设置 replication.factor= min.insync.replicas+1(以牺牲了系统可用性为代价)。
Broker:
场景:单节点上通过WAL写到OS页缓存,内存中数据未及时刷盘,若此时Broker Crash 掉,且选举了一个落后 Leader Partition 很多的 Follower Partition 成为新的 Leader Partition,那么落后的消息数据就会丢失。
解决:OS刷盘策略设置得及时些(间隔变短、数据量阈值变小)、手动fsync等。
Consumer:
场景:上述 at most once 的情形。即先提交offset再处理数据的情形会导致数据被忽略,像“丢失”。
解决:禁用自动提交( enable.auto.commit = false) -> 使用【拉取数据、处理数据、手动提交offset】的方式 -> 业务上幂等去重。
6.2 消息存取与集群管理(Broker工作)
6.2.1 消息存储
(可参阅这篇文章)
一个Topic在物理上分为多个partition(表现为在磁盘上有多个该topic对应的目录,每个partition对应一个topic名+0起的序号的子目录)、一个partition内被分为多个Segment。每条数据都有个offset,数据在partition内才有序,在一个partition内数据offset唯一。
如何存储?每个Segment包括两个文件: .index 索引文件和 .log 数据文件,文件名为该Segment内第一个数据的offset-1。.log文件存数据,.index文件的每条记录包含两个部分:所对应的数据是该segment.log文件内的第几条(逻辑位置)、在.log文件内的物理偏移地址因为不同消息大小不同(物理位置)。
 、
、
如何查找:根据offset查询某条数据时包括两个过程:利用文件名二分查找确定offset在哪个Segment、确定Segment后根据该Segment的 .index 文件内容进行二分查找定位offset的范围,最后在该范围内顺序扫描。
数据不是永久存储的,可以配置最多存储多少大小的数据量、最多存多久的数据,当超过配置值时会自动清理旧数据。
Kafka 内部对Consumer的读数据请求是用 响应式(Reactor)模式 处理的,详可参阅这篇文章。
6.2.2 集群管理(Controller Broker)
虽然在使用者看来,Kafka集群的各个Broker是对等的,但内部实际上与很多分布式系统一样有个管理者的角色(即master/worker架构中的master),称为Controller Broker。
6.2.2.1 Controller 选举
利用zk进行非公平leader选举——各Broker尝试在zk的 /controller 目录下创建临时的同名znode来抢占坑位(谁抢到谁成为Controller),并监听该znode下的数据变化。可见,当第一Broker加入时它称为Controller、后续加入新Broker;当该Controller下线后各存活Broker收到通知并重新尝试抢占坑位。
6.2.2.2 Controller 作用
1 元数据管理:Controller自身内存存储系列元数据,并会在zk上保存一份。当Controller初始化时(Broker被选为Controller时)会从zk读取数据到本地。元数据信息主要三类:
broker信息和partition信息:broker信息、 broker 中的所有分区、分区副本信息,当前都有哪些运行中的 broker,哪些正在关闭中的 broker 。
topic 信息:包括具体的分区信息,比如领导者副本是谁,ISR 集合中有哪些副本等。
所有涉及运维任务的分区。包括当前正在进行 Preferred 领导者选举以及分区重分配的分区列表。
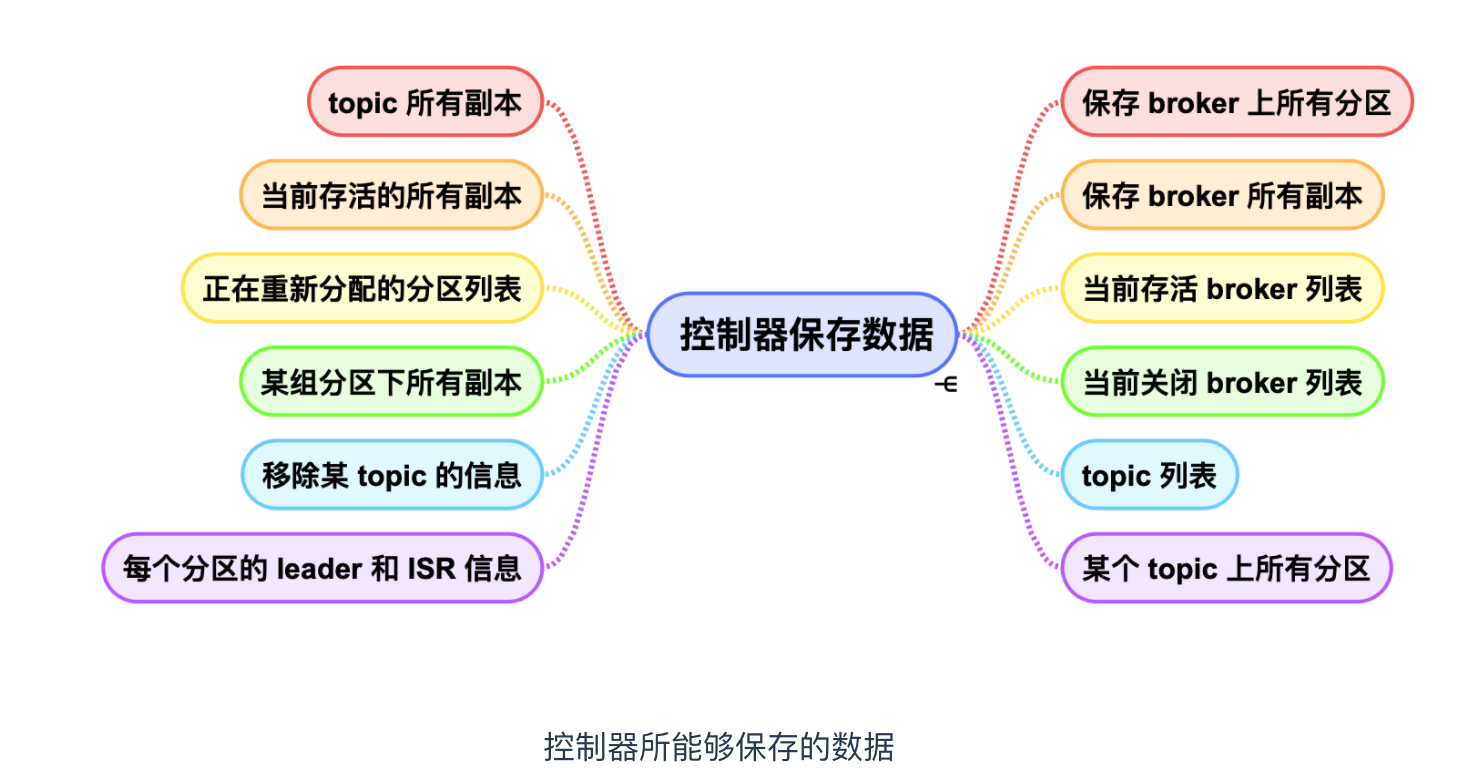
Consumer 也会在本地保存一份元数据,并定期从zk拉取更新本地元数据,这样读数据时可直接找到对应的Broker、partition。
2 数据分区管理:监控系统中Broker的增减,管理partition、replication。
partition 分配:Broker上线时,Controller通过元数据检查该Broker是否以前加入过及分配了哪些partition,并更新元数据以让消息发送到该Broker;此外会参与协调partition的rebalance,分配到新Broker上。(注意与Consumer消费时的partition rebalance做区分)
leader replication选举:Broker下线时,若其上面有leader partition,则Controller发起对 replication partition 选举新leader。默认情况下从ISR中选新leader,若ISR为空且 unclean.leader.election.enable=true (默认为false)则从OSR中选新leader,后者称为 Unclean Leader Election。
3 接收用户对 topic、partition 的管理。
topic管理:topic的创建、删除。用户执行 kafka-topics 脚本时Kafka内部就是由Controller完成的。
partition管理:分区的创建、重分配。kafka-reassign-partitions 脚本提供的对已有主题分区进行细粒度的分配功能,内部就是由Controller完成的。
关于partition replication的同步复制与异步复制:同步复制是指follower从leader复制时是 请求-响应-保存 这样一次次先后复制的,异步是指producer往kafka写数据时不用等所有replication写完(具体写多少个replication视采用的ack策略而定)就可返回。可见,是相对不同的视角而言的。
在当前的kafka版本实现中,对于zookeeper的所有操作都是由kafka controller来完成的。
6.3 消息消费(Consumer工作)
Kafka中的消费方主要有 Consumer、Consumer Group 两个概念,创建每个Consumer前可以指定该Consumer属于哪个Consumer Group,即一个Consumer Group可含有多个Consumer。
Kafka中消费的一个主要特点是,一个partition(从而一条消息)只会被一个Consumer Group中的一个Consumer消费。当然,也可被多个Consumer Group 消费。
6.3.1 两种消费模型
采用恰当的方式消费Kafka,可以逻辑上达到不同的消费模型效果。
队列模式(点对点模式):一个Topic只被一个Consumer Group消费。这样一条消息全局上也只会被该Group内的一个Consumer消费,从而不会存在消息被重复消费的情况。
发布订阅模式:一个Topic被多个Consumer Group消费。这样一条消息全局上看会分别被各Group内的一个Consumer消费。
可见,对于一个Topic来说,多个Consumer Group对其以发布订阅模式的模式消费、一个Consumer Group内对其以队列的模式消费(但不满足FIFO,只有partition内按序消费)。
6.3.2 offset管理
kafka会记录offset到zk中。但是,zk client api对zk的频繁写入是一个低效的操作。0.8.2 kafka引入了native offset storage,将offset管理从zk移出,并且可以做到水平扩展。其原理就是利用了kafka的compacted topic,offset 以 consumer group,topic与partion的组合作为key 直接提交到compacted topic中(名为" _consumer_offset")。同时Kafka又在内存中维护了三元组来维护最新的offset信息,consumer来取最新offset信息时直接从内存拿即可。当然,kafka允许你快速checkpoint最新的offset信息到磁盘上。
默认是会自动提交offfset(会周期性自动提交已收到的消息的最新offset,enable.auto.commit=true、auto.commit.interval.ms=5s),推荐手动提交。当先处理数据再提交offset可能因后者提交失败导致重复消费(at least once语义)、当先提交offset再处理数据可能因后者失败而漏处理数据(at most once语义),推荐先处理再提交并配合业务幂等保证来避免重复消费。
6.3.3 消费的内部原理(partition rebalance等)
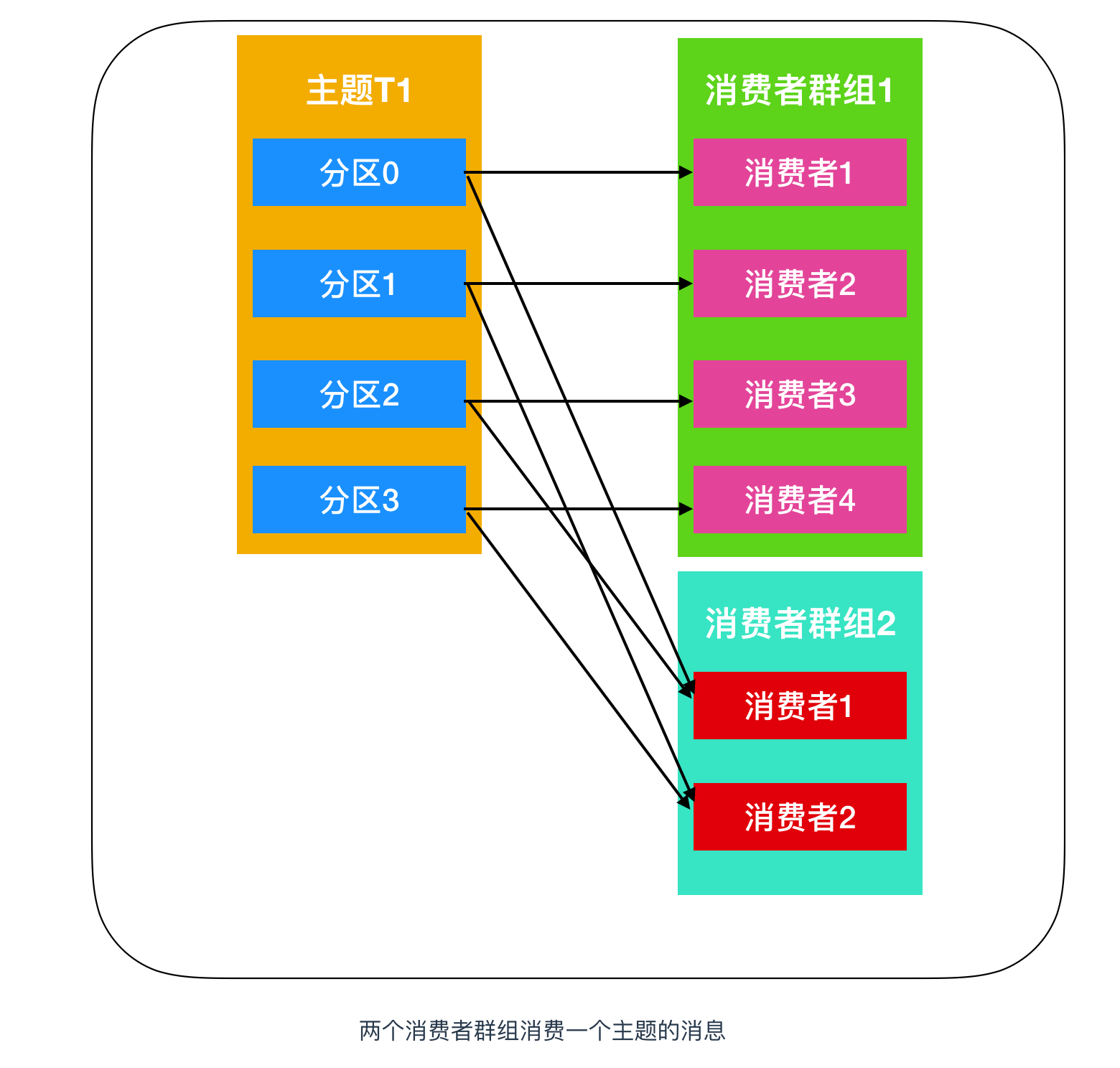
分区与消费者线程的对应关系
一个Topic内部有多个partition,一个Consumer Group可以有多个Consumer、一个Consumer内部可以有多个线程进行消费(此时相当于变成了有多个Consumer)。
一个Topic可被多个Consumer Group消费(未指定group的Consumer都属于同一默认Group),即被多个消费组订阅。
一个Topic被一个Consumer Group消费时,内部会进行partition与Consumer Group内消费者线程间的映射:允许多对一但不允许一对多、尽可能一一对应,即一个Consumer Group内一个线程可消费多个partition但反之不行。
一个线程消费多个partition时只能保证一个partition内消费的数据有序。
一一对应后右边有剩时剩的线程会空闲,故Consumer Group内总消费线程数应不大于目标topic下的partition数。
 、
、
分区与消费者线程的分配策略
Kafka自带两种分配策略:Range(默认采用的策略)、RoundRobin,即按分区号范围分配、轮询分配。可通过 partition.assignment.strategy 来配置(详见下面的rebalance一节)。假设某Topic有m个分区、某消费该Topic的Consumer Group内有m个消费者,则:
Range:依次分配 math.ceil(m/n) 个partition。例如m=11、n=3,则分配结果为: [1 2 3 4]、[5 6 7 8]、[9 10 11]。
RoundRobin:见名之意,上述例子在此分配策略下的分配结果为:[1 4 7 10]、[2 5 8 11]、[3 6 9 ]。
可见,一个消费者在两种分配策略下分到的分区数是一样的,只不过分区号不同。
partition rebalance
(可参阅这篇文章)
是什么:在【Topic内partition数变化 或 消费该Topic的某个Consumer Group内的Consumer数发生变化】时,会触发partition到消费线程映射的调整过程,称为重平衡(rebalance)。注意与前面Broker内部partition的rebalance做区分。
发生的条件:消费者订阅的主题变化、topic内partition数变化(broker上线或下线或管理员手动添加分区等)、某Consumer Group内Consumer数变化(个数变化、线程数变化,本质上都是线程变化,例如消费者主动或被动下线或网络故障时长超过心跳阈值等)等
在rebalance期间,消费者无法读取该Topic消息,即STW(stop the world)。
rebalance完成后,利用之前提交保存的offset信息来从标记的地方继续消费。(关于offset的管理见上文)
rebalance内部原理
如果不支持Consumer Group而是每个Consumer自己单干,则很容易想到,与很多分布式系统一样,Consumer会有本地agent来暂存系统的元数据信息(Broker列表和地址,topic、partition分布信息等),当要读数据时直接根据元数据信息到目标Broker、partition去读即可。然而有了Consumer Group,就需要额外考虑组内各Consumer消费哪些partition以免重复、考虑partition的rebalance等问题了。Kafka 中引入了GroupCoordinator(组协调器)、ConsumerCoordinator(消费者协调器)两个角色来解决这些问题,消费的内部实现主要借助这两者完成。
rebalance 原理概括而言:组协调器存有组元数据,当消费者入组/出组时,组协调器选出该组的leader消费者(若已有leader则不需要选);接着将该组的成员列表信息发给该leader,由该leader进行分区到消费者的分配;消费者向组协调器请求入组时会把自己支持的分区分配策略带上,由组协调器选出该组内各消费者都支持的分配策略发给leader;leader完成分配后把分配信息发给组协调器,由组协调者将分配信息发给组内其他消费者,其他消费者只知道分给自己的分区信息。
以下为详情:
GroupCoornidator:每个Broker启动时会创建一个GroupCoornidator,负责管理消费组及组内的消费offset等信息。作用:
connect:接收ConsumerCoordinator连接,维护定时心跳检测。
group:接收ConsumerCoordinator的入组、出组请求,触发rebalance。
rebalance:选leader Consumer(从一个Group内的各Consumer选出一个作为leader),接收该leader的ConsumerCoordinator发来的的分区与消费者的分配结果并下发给该组内其他ConsumerCoordinator。
metadata:维护各Consumer Group的元数据信息(group列表、group consuer列表、partition到consumer的分配信息等),存入Kafka内部topic并在内存缓存一份;创建定时任务,清理过期的消费组元数据及过期的offset数据。
GroupMetadata包含Consumer的 memberId、leaderId、分区分配关系,状态元数据等。状态元数据可以是五种状态(PreparingRebalance、AwaitingSync、Stable、Dead、Empty),具体说明如下:
PreparingRebalance:消费组准备进行平衡操作
AwaitingSync:等待leader消费者将分区分配关系发送给组协调器
Stable:消费者正常运行状态,心跳检测正常
Dead:处于该状态的消费组没有任何消费者成员,且元数据信息也已经被删除
Empty:处于该状态的消费组没有任何消费者成员,但元数据信息也没有被删除,直到所有消费者对应的消费偏移量元数据信息过期。
offset:接收与之连接的ConsumerCoordinator发来的offset提交,并保存到Kafka内部topic。
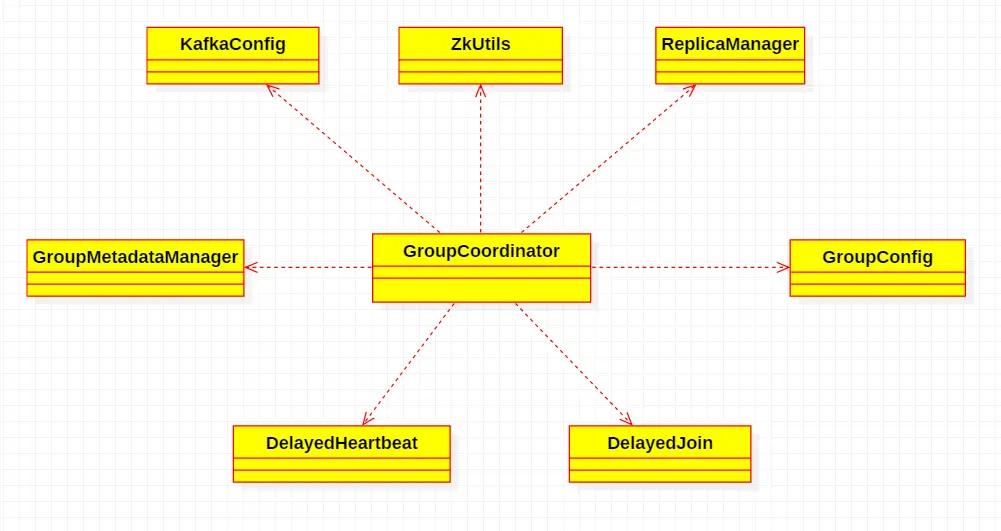
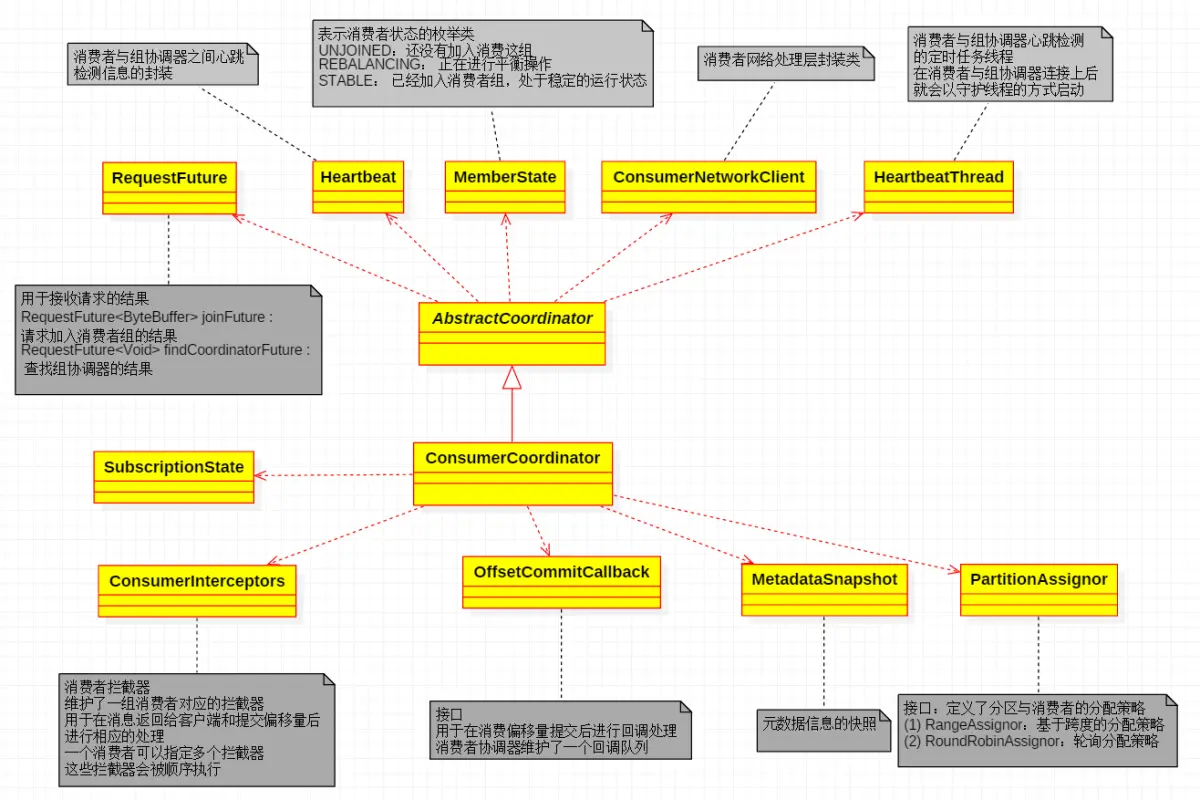
ConsumerCoordinator:每个Consumer内部有一个ConsumerCoordinator,相当于是Consumer功能的内部核心实现。作用:
connect:与GroupCoornidator连接、并执行定时心跳检测任务。
group:向GroupCoornidator发起加入组和离开组的请求。以入组过程为例,过程见下节介绍。
rebalance:GroupCoornidator会从一个Group内的各Consumer选出一个作为leader,该leader Consumer负责partition到Group内各Consumer的分配、并把分配结果发给GroupCoornidator,然后由GroupCoornidator将分配结果下发给Group内其他ConsumerCoordinator。
分区与消费者线程及分区分配策略见上节所述。
选出leader Consumer来负责分区分配,而不是由Broker完成,目的是减轻服务端计算压力。
metadata:本地缓存了:集群的元数据信息(Broker列表和地址,topic、partition到Broker的分布等)、所在Consumer Group的元数据信息(Consumer列表、partition到组内Consumer的分配信息等)自己被分配的分区信息(只有leader consumer会从GroupCoordinator获得Consumer Group元数据信息),这样可直接根据元数据信息请求目标Broker、partition。
offset:向GroupCoornidator提交本Consumer的offset信息。
消费者入组过程
上节说到,消费数据及重平衡时,内部是借助ConsumerCoordinator与GroupCoordinator完成的,其前提是消费者要先与某个GroupCoordinator关联。那对于一个消费者来说怎么确定与哪个GroupCoordinator(也就是哪个Broker)交互、入组过程是怎样的呢?
消费者创建后,ConsumerCoordinator选择一个负载较小的Broker,向其发送寻找GroupCoordinator请求。
KafkaApis按如下逻辑确定:先确定这个消费组元数据会存到内部topic(“_consumer_offset”)的哪个分区,该分区所在的Broker就是GroupCoordinator所在节点。怎么确定哪个分区呢? hash(groupName)% groupMetadataTopicPartitionCount ,即【组名的哈希值】对【存组元数据的topic的分区数】取余。
确定了GroupCoordinator,ConsumerCoordinator向其发送 JoinGroupRequest 请求。
KafkaApis调用 handleJoinGroup() 方法处理请求:把消费者注册到消费组中,把消费者的clientId与一个UUID值生成一个memberId分配给消费者,构造该消费者的MemberMetadata信息并注册到GroupMetadata中,第一个加入组的消费者将成为leader。
把处理JoinGroupRequest请求的结果返回给消费者。
加入组成功后,进行partition rebalance。
6.4 其他
如何确定分区数
分区数的确定与硬件、软件、负载情况等都有关,要视具体情况而定,不过依然可以遵循一定的步骤来尝试确定分区数:创建一个只有1个分区的topic,然后测试这个topic的producer吞吐量和consumer吞吐量。假设它们的值分别是Tp和Tc,单位是MB/s。然后假设总的目标吞吐量是Tt,那么分区数 = Tt / max(Tp, Tc)
7 参考资料
https://github.com/hlyzsm/bestJavaer/blob/master/kafka/kafka-basic.md
1、使用入门:
https://lotabout.me/2018/kafka-introduction(Kafka入门简介)
http://www.cnblogs.com/fanweiwei/p/3689034.html(Kafka的使用)
http://blog.csdn.net/lizhitao/article/details/25667831(Broker的配置)
http://www.cnblogs.com/huxi2b/p/4757098.html?utm_source=tuicool&utm_medium=referral(如何确定分区数、key、consumer线程数)
2、使用及内部原理较全面的介绍:https://github.com/hlyzsm/bestJavaer/blob/master/kafka/kafka-basic.md(全面入门)、https://github.com/hlyzsm/bestJavaer/blob/master/kafka/kafka-deep.md(内部复制、存储、重平衡等原理)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号