
Zookeeper学习小记
 、
、
总结:
what:分布式应用的协调服务。用于对分布式系统进行【配置管理/命名管理、节点管理、leader选举、分布式锁、队列功能】等。zookeeper自身也是个分布式系统,有多个节点,具备强一致性(借助Paxos算法)、容错性、高可用等特点。
原理:从设计模式角度来看,是一个基于观察者模式(Kafka则是基于发布订阅模式)分布式应用的管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper 就将负责通知已经在 Zookeeper 上注册的那些观察者。
核心概念:znode、watch
znode
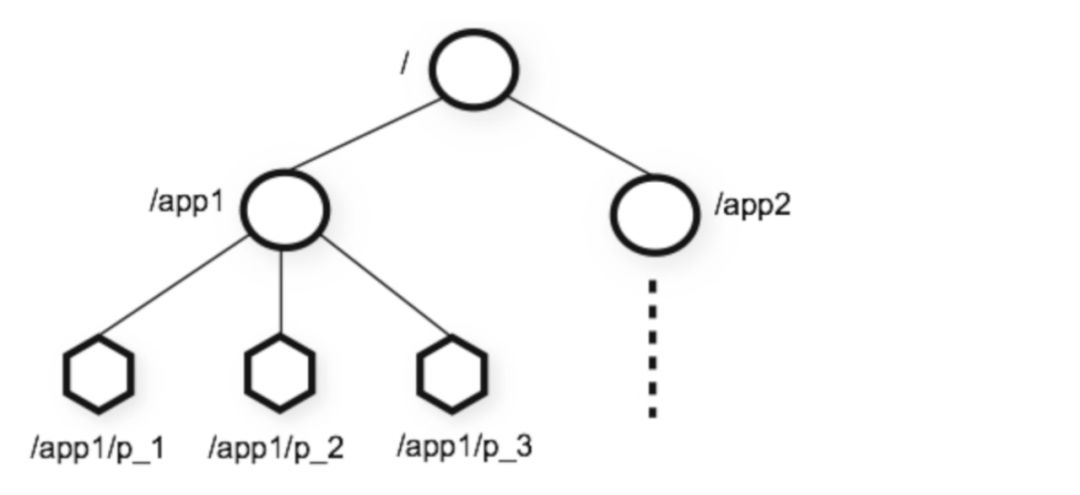
zookeeper中的数据是以树形结构组织的,类似于树形文件系统。树中的节点称为znode,znode有名字、值、可以有子节点。znode有持久型和临时型两个类型,具体来说有四种:
持久型:PERSISTENT、PERSISTENT_SEQUENTIAL
临时型:EPHEMERAL、EPHEMERAL_SEQUENTIAL
临时型的znode在创建者与zookeeper连接断开时(客户端主动断开、服务端宕机导致被动断开等)会被自动删除,持久型的则不会;带SEQUENTIAL后缀的与不带的相比区别在于前者类型的znode写入时会自动在末尾加编号,编号按创建顺序递增,客户端可以根据编号排序来推断事件的顺序或实现一些功能(如leader选举、实现读写锁等)。
watch 机制:zookeeper支持接受客户端对znode注册事件(数据值更改、数据删除、子节点增减、子节点值变化),当znode上事件发生时zookeeper会通知已注册监听该事件的相关客户端。
主要应用场景:
(均为通过利用 zookeeper znode及znode变化通知机制 来实现。对于前者,要么利用“zk中节点不能重名”的特性、要么利用节点顺序做文章。临时节点用得多)
配置管理/命名管理:用于存储所管理的分布式系统的配置数据(如节点的地址等),这些数据被系统的各节点共享。zookeeper自身的配置数据也存储在树形文件系统中。这些存储的信息可以被分布式系统中的节点甚至非该系统中的其他节点读取,且借助watch机制可在存储的信息发生变更时感知到新的值。
节点管理(membership):各节点连接zookeeper后往同一个目录(如/kafka/nodes)下创建一个EPHEMERAL类型的zonde,值为当前节点的id(如将ip:port作为id);并监控该目录节点。这样每个节点都可知道系统中其他节点的存在,当节点增减时也能收到通知从而感知到系统的节点的变化。
leader选举(master/slave选举、replication leader选举):
方式1(公平方式):与节点选管理类似,只不过进一步地,各节点从节点列表中按定好的规则选出一个作为leader。如改为创建EPHEMERAL_SEQUENTIAL类型的节点,并将编号最小创建者的作为leader。
方式2(非公平方式):利用“zk中的同一目录下的znode不能重名”的特性,所有客户端尝试创建同名临时znode,谁创建成功谁称为leader。
分布式锁:(有多种实现方式。利用临时型znode在连接断开时自动删除、znode自动有序的特点)
分布式排他锁:本质与leader选举一样,故有两种实现方式。
方式1(公平方式):与leader选举类似,按预定的规则选出的znode(如将编号最小的znode)的创建者作为锁的获得者,其他的创建者等待并监听共同父目录的children变化事件。锁是否是公平的与规则有关,若规则为选编号最小者(即先写者先得)则是公平的(因为编号是按创建顺序递增的)。
方式2(非公平方式):利用“zk中的同一目录下的znode不能重名”的特性来实现排他锁(这就与借助Redis实现分布式排它锁原理类似了):各客户端创建同一EPHEMERAL znode,只会有一个创建成功,成功者获得锁,失败者等待并监听该znode的删除事件,这是非公平锁。流程图:

Kafka 的Controller Broker 的选举就是通过这种方式实现的,写的znode是 /controller 目录。
屏障(barrier):与节点管理类似,只不过各节点等监控到集群中节点数达到预期数量时才开始接下来的工作。
读/写锁(读时不允许其他写、写时不允许其他读写):各客户端往同一目录下创建EPHEMERAL_SEQUENTIAL节点(写或读节点,结果如"read_1"、"write_2"、"read_3"),然后获取目录下的znode列表并按序号升序排序.
读锁:若当前客户端创建的znode前无写znode则获得读锁,否则等待并监听该写节点的删除事件。
写锁:若当前客户端创建的znode前无节点(即为第一个节点)则获得锁,否则等待并监听当前节点的前一节点的删除事件。(不是监听第一个,这样可少触发事件)
读锁: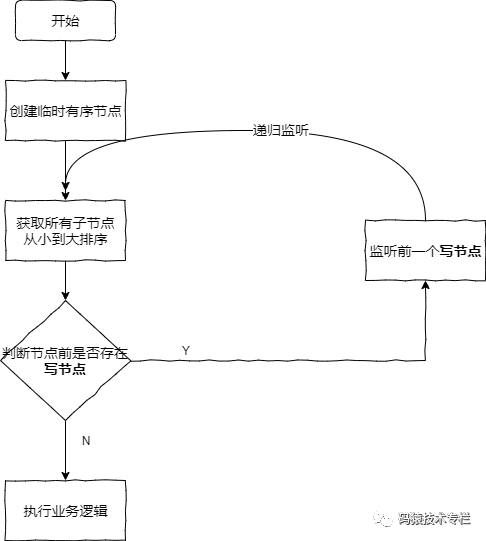 写锁:
写锁: 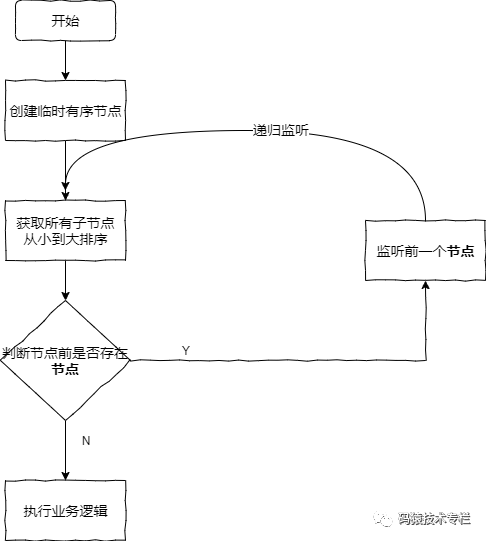
队列管理:同步队列——即上面屏障的功能,等队列成员齐聚后才可消费;FIFO队列——入队有编号、出队按编号。
=============以下为正文=============
Apache Zookeeper 由 Apache Hadoop 的 Zookeeper 子项目发展而来,现已经成为 Apache 的顶级项目,它是一个开放源码的分布式应用程序协调服务,是Google Chubby的一个开源实现。它是一个为分布式应用提供一致性服务的组件,提供的功能包括:配置管理,名字服务,提供分布式同步、队列管理、集群管理等。
使用场景(即上述的功能):典型应用场景篇一,典型应用场景篇二
原理:Zookeeper 从设计模式角度来看,是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper 就将负责通知已经在 Zookeeper 上注册的那些观察者做出相应的反应,从而实现集群中类似 Master/Slave 管理模式。
1、安装
Zookeeper有两种运行模式:
1.1、独立模式(standalone mode)
(具体参考:http://blog.csdn.net/csfreebird/article/details/44006453)
只运行在一台服务器上,适合测试环境。
1.2、复制模式(replicated mode)
运行于一个集群上,适合生产环境,这个计算机集群被称为一个“集合体”(ensemble)。
Zookeeper通过复制来实现高可用性,只要集合体中半数以上的机器处于可用状态,它就能够保证服务继续。这跟Zookeeper的复制策略有关:Zookeeper确保对znode树的每一个修改都会被复制到集合体中超过半数的机器上。
由于ZooKeeper集群,会有一个Leader负责管理和协调其他集群服务器,因此服务器的数量通常都是奇数,例如3,5,7...等,这样2n+1的数量的服务器就可以允许最多n台服务器的失效。
(安装可参考:http://blog.csdn.net/csfreebird/article/details/44007295)
这里以zookeeper-3.4.8为例:
1.2.1、下载解压
解压后目录结构为:
. ├── bin ├── build.xml ├── CHANGES.txt ├── conf ├── contrib ├── dist-maven ├── docs ├── ivysettings.xml ├── ivy.xml ├── lib ├── LICENSE.txt ├── NOTICE.txt ├── README_packaging.txt ├── README.txt ├── recipes ├── src ├── zookeeper-3.4.8.jar ├── zookeeper-3.4.8.jar.asc ├── zookeeper-3.4.8.jar.md5 └── zookeeper-3.4.8.jar.sha1
1.2.2、配置文件
进入conf目录, cp zoo_sample.cfg zoo.cfg ,修改配置文件zoo.cfg为如下:


# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/usr/local/zookeeper/zookeeper-3.4.8/zk_data # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.1=192.168.6.131:2888:3888 server.2=192.168.6.132:2888:3888 server.3=192.168.6.133:2888:3888
各配置项的含义:
1. tickTime = 2000:Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,每隔tickTime时间就会发送一个心跳。
2. initLimit: 配置 Zookeeper 接受客户端(此客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已超过initLimit个tickTime长度后 Zookeeper 服务器还没有收到客户端的返回信息,则表明客户端连接失败。总的时间长度就是 initLimit * tickTime 秒。
3. syncLimit: 配置 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 syncLimit * tickTime 秒
4. dataDir: Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
5. dataLogDir:若没提供的话则用dataDir。zookeeper的持久化都存储在这两个目录里。dataLogDir里是放到的顺序日志(WAL)。而dataDir里放的是内存数据结构的snapshot,便于快速恢复。为了达到性能最大化,一般建议把dataDir和dataLogDir分到不同的磁盘上,以充分利用磁盘顺序写的特性。
6. clientPort:Zookeeper服务器监听的端口,以接受客户端的访问请求。
7. server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,此端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
每个节点的配置文件都一样。
更多可参考Zookeeper的配置
1.2.3、添加myid文件
除了修改 zoo.cfg 配置文件,集群模式下还要配置一个文件 myid,这个文件在 上述dataDir 指定的目录下,这个文件里面就只有一个数据就是 A 的值,Zookeeper 启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是那个 server。
1.2.4、启动/结束
bin/zkServer.sh start|start-foreground|stop|restart|status|upgrade|print-cmd ,启动后默认在bin下产生日志文件zookeeper.out
1. 启动ZK服务: bin/zkServer.sh start 2. 查看ZK服务状态: bin/zkServer.sh status 3. 停止ZK服务: bin/zkServer.sh stop 4. 重启ZK服务: bin/zkServer.sh restart
(启动后在zoo.cfg所指定的dataDir下有version-2文件夹(下有log.1文件)和zookeeper_server.pid文件)
启动后可以借助下面的命令行客户端看是否能连上以确定是否成功启动,也可使用四字命令(如 echo stat|netcat localhost 2181 )快速确定节点状态
2、使用
2.1、Shell客户端
2.1.1 zk命令
命令行客户端连接ZooKeeper: ./bin/zkCli.sh -server localhost:2181 ,连接成功后,会输出 ZooKeeper 的相关环境以及配置信息。并能进行一些操作:
1. 显示根目录下、文件: ls / 使用 ls 命令来查看当前 ZooKeeper 中所包含的内容 2. 显示根目录下、文件: ls2 / 查看当前节点数据并能看到更新次数等数据 3. 创建文件并设置初始内容:create /zk "test" 创建一个新的 znode节点“ zk ”以及与它关联的字符串 4. 获取文件内容: get /zk 确认 znode 是否包含我们所创建的字符串 5. 修改文件内容: set /zk "zkbak" 对 zk 所关联的字符串进行设置 6. 删除文件: delete /zk 将刚才创建的 znode 删除 7. 删除目录(即使非空):rmr 目录 如可用于删除Kafka的某个Consumer Group 8. 退出客户端: quit 9. 帮助命令: help
客户端连接后,用get / 命令可以发现此时只有zookeeper一项;如果此Zookeeper用于对Kafka或JStorm等提供服务,则还会有相应的其他目录。
2.1.2 四字命令
此外,也可通过四字命令更方便地获取服务端信息, 四字命令的用法为 echo 四字命令|netcat localhost 2181 ,常用的四字命令如下:
- conf:输出Zookeeper服务器配置的详细信息
- cons:输出所有连接到服务器的客户端的完全的连接/会话的详细信息。包括“接收/发送”的包数量、会话ID、操作延迟、最后的操作执行等
- dump:输出未经处理的会话和临时节点
- envi:输出关于服务器运行环境的详细信息
- reqs:输出未经处理的请求
- ruok:测试服务是否处于正确状态。若是则会返回“imok”,否则不做任何反应
- stat:输出关于性能和连接的客户端的列表。(通过此命令也可查看节点是leader还是follower)
- wchs:输出服务器watch的详细信息
- wchc:通过session列出服务器watch的详细信息,它的输出是一个与watch相关的会话的列表
- wchp:通过路径列出服务器watch的详细信息,它输出一个与session相关的路径
- mntr:输出一些Zookeeper运行时信息,通过对这些返回结果的解析可以达到监控效果
2.2、Java客户端
使用Java进行Zookeeper的CRUD操作,示例如下:
1 package cn.edu.buaa.act.test.TestZookeeper; 2 3 import java.io.IOException; 4 5 import org.apache.zookeeper.CreateMode; 6 import org.apache.zookeeper.KeeperException; 7 import org.apache.zookeeper.Watcher; 8 import org.apache.zookeeper.ZooDefs.Ids; 9 import org.apache.zookeeper.ZooKeeper; 10 11 /** 12 * 此类包含两个主要的 ZooKeeper 函数,分别为 createZKInstance ()和 ZKOperations ()。<br> 13 * <br> 14 * 15 * (1)createZKInstance ()函数负责对 ZooKeeper 实例 zk 进行初始化。 ZooKeeper 类有两个构造函数,我们这里使用 16 * “ ZooKeeper ( String connectString, , int sessionTimeout, , Watcher watcher 17 * )”对其进行初始化。因此,我们需要提供初始化所需的,连接字符串信息,会话超时时间,以及一个 watcher 实例。<br> 18 * <br> 19 * 20 * (2)ZKOperations ()函数是我们所定义的对节点的一系列操作。它包括:创建 ZooKeeper 21 * 节点、查看节点、修改节点数据、查看修改后节点数据、删除节点、查看节点是否存在。另外,需要注意的是:在创建节点的时候,需要提供节点的名称、数据、 22 * 权限以及节点类型。此外,使用 exists 函数时,如果节点不存在将返回一个 null 值。 23 */ 24 public class ZookeeperTest { 25 26 // 会话超时时间,设置为与系统默认时间一致 27 28 private static final int SESSION_TIMEOUT = 30000; 29 30 // 创建 ZooKeeper 实例 31 32 ZooKeeper zk; 33 34 // 创建 Watcher 实例 35 36 Watcher wh = new Watcher() { 37 38 public void process(org.apache.zookeeper.WatchedEvent event) { 39 System.out.println("event=" + event.toString()); 40 } 41 42 }; 43 44 // 初始化 ZooKeeper 实例 45 46 private void createZKInstance() throws IOException { 47 zk = new ZooKeeper("192.168.6.131:2181,192.168.6.132:2181,192.168.6.133:2181", ZookeeperTest.SESSION_TIMEOUT, 48 this.wh); 49 } 50 51 private void ZKOperations() throws IOException, InterruptedException, KeeperException { 52 53 System.out.println("\n 创建 ZooKeeper 节点 (znode : zoo2, 数据: myData2 ,权限: OPEN_ACL_UNSAFE ,节点类型: Persistent"); 54 zk.create("/zoo2", "myData2".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); 55 56 System.out.println("\n 查看是否创建成功: "); 57 System.out.println(new String(zk.getData("/zoo2", false, null))); 58 59 System.out.println("\n 修改节点数据 "); 60 zk.setData("/zoo2", "shenlan211314".getBytes(), -1); 61 62 System.out.println("\n 查看是否修改成功: "); 63 System.out.println(new String(zk.getData("/zoo2", false, null))); 64 65 System.out.println("\n 删除节点 "); 66 zk.delete("/zoo2", -1); 67 68 System.out.println("\n 查看节点是否被删除: "); 69 System.out.println(" 节点状态: [" + zk.exists("/zoo2", false) + "]"); 70 71 } 72 73 private void ZKClose() throws InterruptedException { 74 zk.close(); 75 } 76 77 public static void main(String[] args) throws IOException, InterruptedException, KeeperException { 78 ZookeeperTest dm = new ZookeeperTest(); 79 dm.createZKInstance(); 80 dm.ZKOperations(); 81 dm.ZKClose(); 82 } 83 84 }
相关Maven依赖:
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.2</version>
</dependency>
3、Zookeeper dashboard
GitHub Zookeeper UI Dashboard
4、进阶
4.1 数据及日志维护
Zookeeper的数据文件存放在配置中指定的dataDir中,每个数据文件名都以snapshot开头,每个数据文件为zookeeper某个时刻数据全量快照。在zookeeper中,对数据的更新操作,包括创建节点、更新节点内容、删除节点都会记录事务日志;客户端对ZK的更新操作都是永久的,不可回退的。为做到这点,ZK会将每次更新操作以事务日志的形式写入磁盘,写入成功后才会给予客户端响应。zookeeper在完成若干次事务日志(snapCount)后会生成一次快照,把当前zk中的所有节点的状态以文件的形式dump到硬盘中,生成一个snapshot文件。这里的事务次数是可以配置,默认是100000个。
Zookeeper的日志包括两个部分,一部分是系统日志,另一部分是事务日志。
系统日志使用log4j进行管理,conf目录中有一个log4j配置文件,该配置文件默认没有打开滚动输出,需要用户自己配置,具体请参看log4j介绍。
事务日志默认存放在dataDir中,当然可以使用dataLogDir指定存放的位置。正常运行过程中,针对所有更新操作,在返回客户端“更新成功”的响应前,ZK会确保已经将本次更新操作的事务日志写到磁盘上,只有这样,整个更新操作才会生效。每触发一次数据快照,就会生成一个新的事务日志。
默认情况下,zk不会自动清理数据文件和日志文件,因此需要管理员自己清理。我们可以使用ZK的工具类PurgeTxnLog进行清理,当然,我们也可以写脚本自己维护,同时可以使用工具慢慢清理,避免占用大量IO。清理脚本如下:
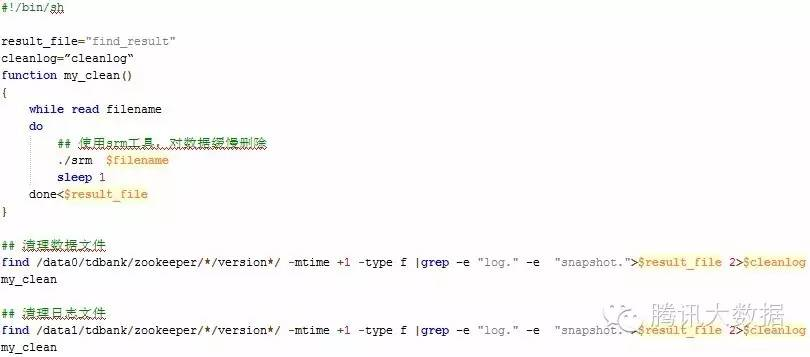
务必注意:
如果长时间不清理,切忌同一时间使用rm命令同时删除大量文件,这样会造成IO利用率瞬间飙升,zookeeper的连接会出现断连或session超时,影响现网业务使用。
另外,对于每一个数据文件,它都是某一时刻的完整快照,我们可以定时将该文件备份,方便对数据进行还原或将zookeeper直接迁移到另外一个集群。
4.2 数据清理
具体详见:http://nileader.blog.51cto.com/1381108/932156
4.3 可视化事务日志
具体详见:http://nileader.blog.51cto.com/1381108/926753
Zookeeper运行久了产生的日志和事务数据非常大,在我们的实践中甚至由于从没清理导致磁盘满了,虽然Zookeeper节点没死,但ZK UI监控上显示出“This instance is not serviceing requests”。由于Zookeeper不能提供服务,JStorm节点就死了,Kafka节点也无法提供服务(没死),清理数据后就好了。
上述参考资料里列出了几种方法,我们采取定时自动清理的做法(每次留10个),写如下脚本,加入crontab定期执行:
#snapshot file dir dataDir=/usr/local/zookeeper/zookeeper-3.4.8/zk_data/version-2 #tran log dir dataLogDir=/usr/local/zookeeper/zookeeper-3.4.8/zk_data/version-2 #zk log dir #Leave 10 files count=10 count=$[$count+1] ls -t $dataLogDir/log.* | tail -n +$count | xargs rm -f ls -t $dataDir/snapshot.* | tail -n +$count | xargs rm -f
4.4 权限控制
具体参见:使用super身份对有权限的节点进行操作 和 ZooKeeper权限控制
4.5 Zookeeper应用场景及实践
经典应用:
1)NameService
不多说,本身就是一个共享的树形文件系统
2)配置管理
不同的process watch 自己的配置znode, 当配置变化可以收到通知
3)集群membership管理
集群节点下,每个server对应一个EPHEMERAL的节点,节点名就是server name/ IP,当它和zookeeper的心跳断了,对应的节点被删除,并且所有集群内的节点可以收到新的child List,保证每个server都知道进群内的其他server
4) master选举
和3)类似,但是节点换成EPHEMERAL_SEQUENTIAL的,大家都约定以当前编号最小的server做为master。当master挂了,每个server都会被通知到一份新的server 列表,大家都把编号最小的那个作为master
5) 分布式独占锁
类似Java synchronized的语义 在约定的锁节点上创建EPHEMERAL_SEQUENTIAL节点作为等待队列,如果编号最小的就是自己就获得锁,否则wait()住。获得锁的process通过删除自己的节点释放锁,这样每个等待的process会得到通知,在事件处理函数里判断自己是不是最小的编号,如果是则唤醒之前wait住的线程,这样本进程就获得了锁
6)barrier屏障
意思是所有相关的process都到达齐了再往下执行。实现方法,也是在barrier节点创建EPHEMERAL_SEQUENTIAL的节点,每个process都会得到变化后的children list,当大小为barrier要求数的时候,各个process继续执行。 zookeeper作为分布式process协调的中介,本身是一个单点failure点,所以它本身也做为一个集群,通常部署2n + 1台, 客户端连接不同的zookeeper server,但是得到视图是一样的,这点是zookeeper内部保证的
Zookeeper客户端主要有原生客户端、zclient、Apache Curator等。
以下代码使用Zookeeper原生的客户端(Zookeeper源码里),推荐使用更方便的客户端 Curator
4.5.1 配置管理
1 package cn.edu.buaa.act.test.TestZookeeper; 2 3 import java.io.IOException; 4 5 import org.apache.zookeeper.CreateMode; 6 import org.apache.zookeeper.KeeperException; 7 import org.apache.zookeeper.Watcher; 8 import org.apache.zookeeper.ZooKeeper; 9 import org.apache.zookeeper.ZooDefs.Ids; 10 11 /** 12 * <h1>配置管理</h1><br/> 13 * Zookeeper很容易实现集中式的配置管理:<br/> 14 * 15 * <p> 16 * 比如将APP1的所有配置配置到/APP1 17 * node下,APP1所有机器一启动就对/APP1这个节点进行监控(zk.exist("/APP1",true)),并且实现回调方法Watcher. 18 * </p> 19 * 20 * <p> 21 * 那么在zookeeper上/APP1 22 * znode节点下数据发生变化的时候,每个机器都会收到通知,Watcher方法将会被执行,那么应用再取下数据即可(zk.getData("/APP1", 23 * false,null)); 24 * </p> 25 * 26 * @author zsm Email: qzdhzsm@163.com 27 * @date Sep 13, 2016 8:31:08 PM 28 * @version 1.0 29 * @parameter 30 * @since 31 * @return 32 * 33 */ 34 public class ManageConfiguration { 35 private static final int SESSION_TIMEOUT = 30000; 36 private static final String zookeeperAddr = "192.168.6.131:2181,192.168.6.132:2181,192.168.6.133:2181"; 37 private static final String znodePath = "/zsm_dbIP"; 38 39 private ZooKeeper zk; 40 41 public ManageConfiguration() throws KeeperException, InterruptedException, IOException { 42 Watcher wh = new Watcher() { 43 public void process(org.apache.zookeeper.WatchedEvent event) { 44 try { 45 System.out.println("db ip changed,new value:" + new String(zk.getData(znodePath, true, null))); 46 } catch (KeeperException e) { 47 // TODO Auto-generated catch block 48 e.printStackTrace(); 49 } catch (InterruptedException e) { 50 // TODO Auto-generated catch block 51 e.printStackTrace(); 52 } 53 } 54 }; 55 56 // 初始化 ZooKeeper 实例,初始化时提供的Watcher就会触发一次 57 zk = new ZooKeeper(zookeeperAddr, SESSION_TIMEOUT, wh); 58 59 { 60 // 为了确保节点存在,不存在则先创建 61 if (zk.exists(znodePath, false) == null) { 62 zk.create(znodePath, "192.168.0.7".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); 63 System.out.println("节点不存在,新建节点:" + znodePath + "=" + new String(zk.getData(znodePath, true, null))); 64 } 65 } 66 67 } 68 69 public static void main(String[] args) throws InterruptedException, KeeperException, IOException { 70 new ManageConfiguration(); 71 while (true) { 72 ; 73 } 74 } 75 }
4.5.2 集群管理
1 package cn.edu.buaa.act.test.TestZookeeper; 2 3 import java.io.IOException; 4 5 import org.apache.zookeeper.CreateMode; 6 import org.apache.zookeeper.KeeperException; 7 import org.apache.zookeeper.Watcher; 8 import org.apache.zookeeper.ZooDefs.Ids; 9 import org.apache.zookeeper.ZooKeeper; 10 11 /** 12 * <h1>集群管理</h1> <br/> 13 * 14 * <pre> 15 * 在 Zookeeper 上创建一个 EPHEMERAL 类型的节点,然后每个 Server 在它们创建目录节点的父目录节点上调用getChildren(String path, boolean watch) 方法并设置 watch 为 true 16 * </pre> 17 * 18 * <pre> 19 * 由于是 EPHEMERAL 目录节点,当创建它的 Server 死去,这个目录节点也随之被删除,所以 Children 将会变化,这时 20 * getChildren上的 Watch 将会被调用,所以其它 Server 就知道已经有某台 Server 死去了。新增 Server 同理。 21 * </pre> 22 * 23 * <pre> 24 * 若创建的是EPHEMERAL_SEQUENTIAL 节点,节点名会自动被append上一个唯一编号。可以在节点加入或删除触发wh时取编号最小的作为Leader,实现master选举 25 * </pre> 26 * 27 * @author zsm 28 * @date Sep 13, 2016 8:31:08 PM 29 * @version 1.0 30 * @parameter 31 * @since 32 * @return 33 */ 34 public class ManageCluster { 35 private static final int SESSION_TIMEOUT = 30000; 36 private static final String zookeeperAddr = "192.168.6.131:2181,192.168.6.132:2181,192.168.6.133:2181"; 37 private static final String znodePath = "/zsm_Nodes"; 38 39 private ZooKeeper zk; 40 41 public ManageCluster(String thisNodeID) throws IOException, KeeperException, InterruptedException { 42 43 Watcher wh = new Watcher() { 44 public void process(org.apache.zookeeper.WatchedEvent event) { 45 // System.out.println("*********wh1:event=" + event.toString() + 46 // " ********"); 47 try { 48 System.out.println("节点变化,现有所有节点:" + zk.getChildren(znodePath, true)); 49 } catch (KeeperException e) { 50 // TODO Auto-generated catch block 51 e.printStackTrace(); 52 } catch (InterruptedException e) { 53 // TODO Auto-generated catch block 54 e.printStackTrace(); 55 } 56 } 57 }; 58 59 // 初始化 ZooKeeper 实例,初始化时提供的Watcher就会触发一次 60 zk = new ZooKeeper(zookeeperAddr, SESSION_TIMEOUT, wh); 61 62 {// 根节点不存在的话创建PERSISTENT根节点 63 if (zk.exists(znodePath, null) == null) { 64 zk.create(znodePath, "root node".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); 65 } 66 } 67 68 // 创建EPHEMERAL_SEQUENTIAL节点 69 zk.create(znodePath + "/" + thisNodeID, thisNodeID.getBytes(), Ids.OPEN_ACL_UNSAFE, 70 CreateMode.EPHEMERAL_SEQUENTIAL); 71 72 // 在父节点getChildren,true 73 zk.getChildren(znodePath, true); 74 75 } 76 77 public static void main(String[] args) throws IOException, KeeperException, InterruptedException { 78 // TODO Auto-generated method stub 79 if (args.length < 0) { 80 System.out.println("args length is <0."); 81 System.exit(1); 82 } 83 new ManageCluster(args[0]); 84 while (true) { 85 ; 86 } 87 } 88 89 }
4.5.3 分布式同步锁、队列等
1 package cn.edu.buaa.act.test.TestZookeeper; 2 3 import java.io.IOException; 4 import java.util.Arrays; 5 import java.util.List; 6 7 import org.apache.zookeeper.CreateMode; 8 import org.apache.zookeeper.KeeperException; 9 import org.apache.zookeeper.Watcher; 10 import org.apache.zookeeper.ZooDefs.Ids; 11 import org.apache.zookeeper.ZooKeeper; 12 13 /** 14 * <pre> 15 * 分布式共享锁,与通过Zookeeper管理Cluster类似,只是每次触发Watcher后的操作,取现有所有节点后有下一步操作: 若最小节点等于当前节点, 16 * 则获得锁. 17 * 18 * <pre/> 19 * 20 * <pre> 21 * 如果所有节点的nodeid都一样,则各节点优先级一样,先进先得到锁;若不同节点的nodeid不能一样.则nodeid越小优先级越大 22 * 23 * <pre/> 24 * 25 * @author zsm 26 * @date 2016年9月18日 下午10:15:24 27 * @version 1.0 28 * @parameter 29 * @since 30 * @return 31 */ 32 public class T3_ManageLocks { 33 private static final int SESSION_TIMEOUT = 5000; 34 private static final String zookeeperAddr = "192.168.6.131:2181,192.168.6.132:2181,192.168.6.133:2181"; 35 private static final String znodePath = "/zsm_Locks"; 36 37 private ZooKeeper zk; 38 private static String thisNodeID; 39 40 public T3_ManageLocks(String thisNodeID) throws IOException, KeeperException, InterruptedException { 41 T3_ManageLocks.thisNodeID = thisNodeID; 42 43 Watcher wh = new Watcher() { 44 public void process(org.apache.zookeeper.WatchedEvent event) { 45 // System.out.println("*********wh1:event=" + event.toString() + 46 // " ********"); 47 try { 48 List<String> nodeListTmp = zk.getChildren(znodePath, true); 49 System.out.println("节点变化,现有所有节点:" + nodeListTmp); 50 51 String[] nodeList = nodeListTmp.toArray(new String[nodeListTmp.size()]); 52 Arrays.sort(nodeList); 53 54 String nodeIdWithLock = new String(zk.getData(znodePath + "/" + nodeList[0], null, null)); 55 System.out.println("curnode: " + T3_ManageLocks.thisNodeID + " node with lock: " + nodeIdWithLock); 56 if (nodeIdWithLock.equals(T3_ManageLocks.thisNodeID)) { 57 System.out.println("当前节点 " + nodeIdWithLock + " 获得锁"); 58 // do something then System.exit(0); 59 } 60 61 } catch (KeeperException e) { 62 // TODO Auto-generated catch block 63 e.printStackTrace(); 64 } catch (InterruptedException e) { 65 // TODO Auto-generated catch block 66 e.printStackTrace(); 67 } 68 } 69 }; 70 71 // 初始化 ZooKeeper 实例,初始化时提供的Watcher就会触发一次 72 zk = new ZooKeeper(zookeeperAddr, SESSION_TIMEOUT, wh); 73 74 {// 根节点不存在的话创建PERSISTENT根节点 75 if (zk.exists(znodePath, null) == null) { 76 zk.create(znodePath, "root node".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); 77 } 78 } 79 80 // 创建EPHEMERAL_SEQUENTIAL节点 81 zk.create(znodePath + "/" + thisNodeID, thisNodeID.getBytes(), Ids.OPEN_ACL_UNSAFE, 82 CreateMode.EPHEMERAL_SEQUENTIAL); 83 84 // 在父节点getChildren,true 85 // zk.getChildren(znodePath, true); 86 87 } 88 89 public static void main(String[] args) throws IOException, KeeperException, InterruptedException { 90 // TODO Auto-generated method stub 91 if (args.length < 0) { 92 System.out.println("args length is <0."); 93 System.exit(1); 94 } 95 new T3_ManageLocks(args[0]); 96 while (true) { 97 ; 98 } 99 } 100 }
5、参考资料
1、http://blog.csdn.net/csfreebird/article/details/43984425(安装)
2、http://www.cnblogs.com/yuyijq/p/3424473.html(Zookeeper系列)
3、http://www.blogjava.net/BucketLi/archive/2010/12/21/341268.html(使用)
4、http://data.qq.com/article?id=2863(全。腾讯大数据之Zookeeper运营经验分享)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号