面试问题记录 二 (数据库、Linux、Redis)
面试问题记录 二 (数据库、Linux、Redis)
前言
接着上次的面试问题记录,在最后还有几道问的数据结构方面的知识点要补充
还是那句话:如果文中解释有明显错误,劳烦请及时指正我,在这不胜感激!!!
一、MySQL
1.说说MySQL与MongoDB的区别?
答:首先就是MySQL是关系型数据库,由二维表及其自身之间的关系组成的数据组织,这样易于维护,而且适用于SQL复杂的查询、支持事务等;MongoDB的话是以数据结构化的方式存储,而且和MySQL不同,它是只能存储在随机存储器上的,底层数据结构是B树, 虽然本身没有事务机制,但是可以从逻辑上实现事务。
2.内连接、左连接、右连接是怎样的?
答:内连接(inner join)是把匹配的都显示出来,比如两张表,首先确定从哪张表查出要匹配的字段,然后加上关键字inner join,把后面符合条件的结果查出来;左连接(left join)是将左表为基准,来一一匹配右表,如果匹配不上返回左表内容,右表返回空;右连接(right join)是将右表为基准,来一一匹配左表,如果匹配不上则返回右表内容,左表返回null。
3.如何分库分表?为什么分?
答:当我们一开始数据库中没有进行分库分表的时候,由于数据库中的数据量并不是可控的,而且随着业务的发展,数据量就会不断扩大,这样会导致数据库的操作开销越来越大,而且服务器的资源是有限的,最终数据量和数据库的处理能力都会到达瓶颈;分库分表有垂直和水平方式,一般是先垂直后水平,垂直是按一个系统中不同的业务来分库分表,也可以解决那种表中字段较多,数据量大,不常用的,长度比较长的进行分表处理;水平是将数据量大的单张表的数据分到不同的数据库,相同结构的表中。当然使用这种策略还会遇到事务一致性、容量限制、分页排序、全局主键唯一等问题。分库分表的话,目前知道的是用单独的服务MyCat去实现或者用ApacheShardingJDBC实现,只不过ShardingJDBC是融合在项目中的。
4.说一下事务?
答:事务就是将一组SQL语句放在同一批次内执行,如果一组中有一个SQL语句执行不成功,则整个批次中的SQL语句都不会执行,而MySQL事务只支持InnoDB和嵌入型数据库BDB。事务具有的ACID原则,也就是原子性、一致性、隔离性、持久性;而原子性表示整个事务中所有操作,要么全成功,要么全都不执行;一致性表示不管在任何给定的时间并发事务有多少,都要保持系统处于一致的状态;隔离性表示如果有两个或多个事务同一时间发生,事务将进行串行化或序列化,来保证同一时间只有一个请求来操作数据;持久性表示事务一旦执行完毕后,事务所做的操作将持久的保存在数据库中,而且不会回滚。
5.如何分页?
答:用limit关键字,limit (pageNo-1)*pageSzie,pageSzie [pageNo:页码,pageSize:单页面显示条数]
6.三大范式知道吗?
答:第一范式是表示列的原子性,保证每一列都是最小单元,不能再分割了;第二范式是在第一范式的基础上建立的,每一列都要和主键相关,主要针对联合主键而言,就是每个表只描述一件事情;第三范式确保满足第二范式,每一列都和主键直接相关,而不是间接相关,也就是避免数据冗余。
具体可参考下面两篇文章:《数据库设计三大范式 》 《数据库范式那些事》
面试文章:数据库面试题
7.它的索引是怎么实现的?
答:快速定位表中内容的一种机制,帮助MySQL高效获取数据的数据结构。索引主要有四种,一主键索引Primary Key,二唯一索引Unique,三常规索引index,四全文索引FullText。而且mysql5.6以前的版本只有MyIsam支持全文索引,之后的话,两种数据引擎都支持全文索引,且字段数据类型为char,varchar、text及其系列的数据类型。
可参考文章:漫谈数据库索引
二、Linux
1.说一下你常用的命令
答:最基础的话,比如cd进入某个目录、pwd显示当前文件路径、ls查看文件列表、ll查看文件列表详情、mkdir创建目录、rm删除、mv移动、cp复制、find搜索、whereis显示二进制文件路径、which查找文件、cat查看文件内容、grep匹配文件中具体内容,tar压缩解压、zip压缩、unzip解压、init 6重启、init 0立刻关机、shutdown关机、ifconfig、ip addr查看网络接口属性、ps -ef查看所有进程、top显示进程状态、netstat监听连接端口、kill进程、service、systemctl服务查看、启动、终止(service命令服务名在中间,systemctl命令服务名在最后),data显示系统日期时间。
三、Redis
1.Redis是什么?为什么用它?
答:redis是基于内存可持久化的日志型、key-value型数据库;首先就是它可以做高速缓存,而且有多种数据类型,支持事务,其次可以简单实现消息队列和session共享;redis的话也是针对一些数据量不是很大,访问频繁的数据。这样访问数据的话,就会变得快而且安全。
可参考文章:《Redis面试题》 《为什么要用Redis》
2.Redis支持的数据类型有哪些?
答:应该有8种,最基本的是五种;字符串string、哈希hash、集合set、列表list、有序集合zset;
3.缓存雪崩、缓存穿透、缓存击穿可以解释一下吗?
答:首先缓存是这样
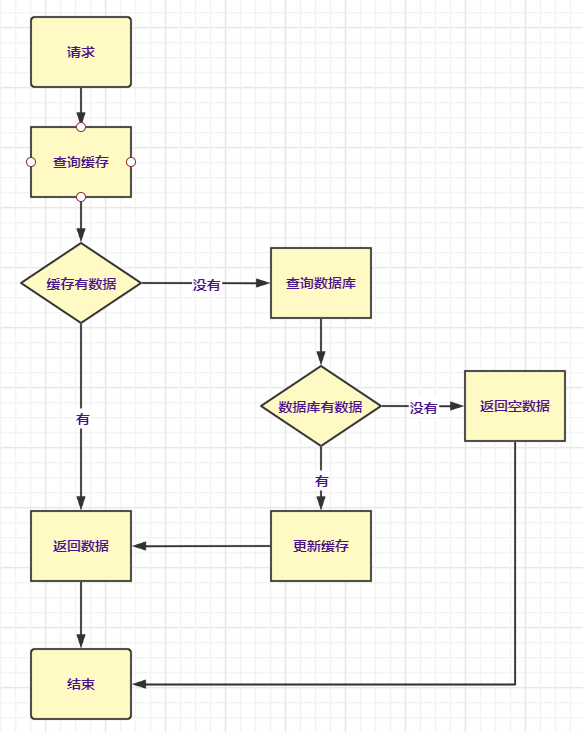
缓存雪崩:缓存中大量key同时失效,导致大量请求打在数据库上,导致数据库承受不住,宕机;还有就是缓存服务器崩了。可以使用热点数据永不失效、排队、限流、降级、主从+哨兵模式,这方面并未有做过深的探究。
缓存击穿:和雪崩相反,当某些超热点的数据在缓存过期瞬间打在数据库上,使数据库压力过重,崩溃。可以将热点数据设置永不过期,或者在拿数据的时候加互斥锁。
缓存穿透:如果缓存和数据库都没有的数据记录,被频繁的请求和调用,导致数据库中没有数据,缓存也没法更新数据;这样的方式也被用于恶意攻击,不走寻常路。可以在后端做数据校验,增添过滤器。
4.如何保证缓存和数据库数据一致?
答:一般是设置缓存过期时间,等超时之后直接从数据库重新读取回填缓存,也就是要删除缓存,更新数据库的操作。
二是先删除缓存,再更新数据库。方法就是延时双删,比如有两个线程A和B,首先A删除缓存,去更新数据库,然后B来读缓存,发现缓存已经被删除,然后去读数据库,此时A还未更新完成,所以B拿到的数据是旧的,然后将旧值写入缓存,因为给A设置了一个估算时间sleep,这个时间是大于B的整个过程的,所以这个时间已过,缓存将又被删除,这样当有别的线程来访问,则从数据库中得到最新的数据。
四、上篇补充内容
1.快速排序是怎样的?
答:参考:《十大经典排序算法(动图演示)》,《玩转Java快速排序》
2.说一下HashMap?
答:存储结构 默认容量 装载因子 hashcode/equals 1.7和1.8版本变化
1.内部存储结构:数组+链表+红黑树(JDK8)
2.默认容量16,默认装载因子0.75。
3.key和value对数据类型的要求都是泛型。
4.key可以为null,放在table[0]中。
5.hashcode:计算键的hashcode作为存储键信息的数组下标用于查找键对象的存储位置。equals:HashMap使用equals()判断当前的键是否与表中存在的键相同
3.为什么用迭代器?
答:为了提供给不同集合类的统一遍历的接口,迭代器也是一种设计模式吧。
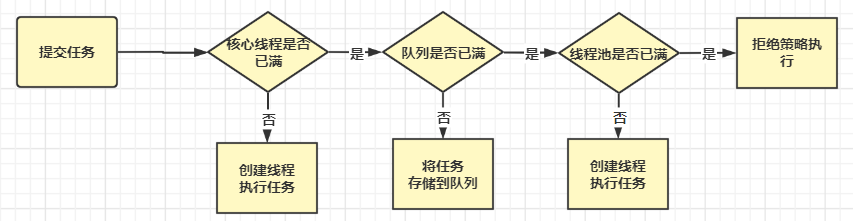
4.线程池流程
最后
就简单的记录了一下,到后期会把一些面试的资料也会总结一下,毕竟这次也是一小部分的问题;具体关于JavaEE上的还未修改出来,也会在最近加紧总结。其实现在面试也更多去偏向业务上的东西,加上自己的理解,像“八股文”这种东西还是需要看的,毕竟有些问题实在是很基础,不问也不行。
最近也是发现一句话“无关紧要的事情,直接舍弃。集中火力,不要分散自己的学习精力。你不能什么都学”
平常真的是把注意力放在了广度上,而从未去深度的get那个点。
警言: 无论人生上到哪一层台阶,阶下有人在仰望你,阶上亦有人在俯视你。你抬头自卑,低头自得,唯有平视,才能看见真实的自己。
转载请注明原文链接:https://www.cnblogs.com/yuyueq/p/15084725.html
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢你的支持!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号