


上一篇中,我们分析了Common中的几个类,这几个类都是辅助用的,其实不太重要,重要使我们今天要分析的这几个类,包括Entity、IDatabase、IEntityDataAccess,其中Entity作为所有实体类的基类,更是重中之重,而IDatabase、IEntityDataAccess这两个接口,则是为Entity类服务的。
先看那个熟悉的系统结构图。

Entity、IDatabase、IEntityDataAccess这三个类型位于Business层中。该层目前的类图如下:
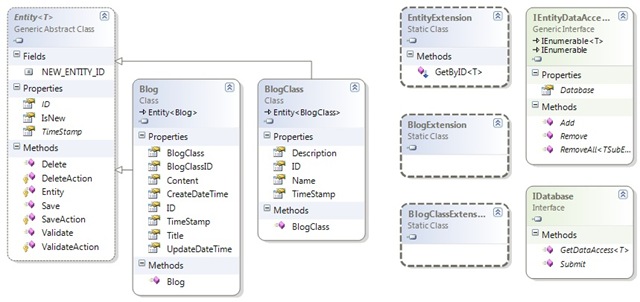
从图中可以看到,Business层包含Blog和BlogClass这两个实体类,他们都继承于Entity类;每个实体类(包括Entity)都对应一个Entension类,这个类自然就是存放该类相关的Extension方法的地方,通常是对IQueryable和IEntityAccess接口的扩展;另外IDatabase和IEntityAccess两个接口定义了数据库访问的方法。
一、Entity类。Entity是所有实体类的基类,是一个模板类不能是结构体的泛型类。它为所有的实体类提供了ID、TimeStamp和IsNew的属性,Validate、Save和Delete方法,每个方法又包含实际操作ValidateAction、SaveAction和DeleteAction。
1,属性:
ID和TimeStamp属性是抽象属性,之所以这样,是因为Linq的继承目前还不是很成熟,所以我们把ID和TimeStamp的具体信息推迟的每个实体类(使用代码生成),这样,对于Linq来说,就是一个不存在继承的实体体系。另外,ID和TimeStamp是只读的,Linq可以通过反射设置字段的内容,所以我们把ID和TimeStamp设置为只读,只由Linq负责这两个字段的值,防止类外部的修改,这一技巧也可以用于其它不允许类外部修改的属性(即只包括get方法的属性)。IsNew方法是基于ID字段判断的,参看以下代码。由于ID是只读的,所以我们可以安全的通过判断ID是否为0来识别该字段是new出来的还是从数据库中读取出来的。
1: /// <summary>
2: /// 新实体的ID取值
3: /// </summary>
4: public const int NEW_ENTITY_ID = 0;
5: /// <summary>
6: /// 取得实体是否是新实体
7: /// </summary>
8: public bool IsNew
9: {10: get { return ID == NEW_ENTITY_ID; }
11: }2,方法:
Entity提供了Validate、Save和Delete三个方法,每个方法又包含可以被子类重写的实际操作:ValidateAction、SaveAction和DeleteAction。两两之间通常是这样子的:
1: /// <summary>
2: /// 验证
3: /// </summary>
4: /// <param name="database">数据库</param>
5: /// <returns>验证结果</returns>
6: public ValidateResult Validate(IDatabase database)
7: {8: if (database == null)
9: throw new ArgumentNullException("database");
10: 11: var validater = new Validater();
12: ValidateAction(validater, database);13: return validater.Validate();
14: }15: /// <summary>
16: /// 验证动作
17: /// </summary>
18: /// <param name="validater">验证器</param>
19: /// <param name="database">数据库</param>
20: protected virtual void ValidateAction(Validater validater, IDatabase database) { }
即Validate等入口方法提供了诸如验证参数等得共同操作,而提供给子类可以重写的Action方法。三个方法中比较特别的是Save方法,它在执行Action前,会先调用Validate方法,以保证保存进数据库的数据全部是合法数据。如下:
1: public void Save(IDatabase database)
2: {3: if (database == null)
4: throw new ArgumentNullException("database");
5: 6: var validateResult = this.Validate(database);
7: if (!validateResult.IsValidated)
8: throw new ValidateFailException(validateResult);
9: 10: SaveAction(database); 11: }Validate、Save和Delete所带的参数都是IDatabase接口,这个接口定义了数据库所要实现的全部操作,应该说是一个非常粗颗粒度的接口(虽然现在该接口只有一个方法)。使用粗颗粒度的接口的好处是:实体类内部在处理与自身相关的数据时,可以访问到整个数据库,使用起来方便。从逻辑上讲,这三个方法使用数据库作为参数,表示在该数据上下文环境中,执行Validate、Save和Delete操作,意思也是很清晰的。后面会出现的对于数据库的操作,都将以这种粗颗粒度的接口作为参数。不过使用粗颗粒度的接口也要注意,实现机制不能过于臃肿,不然构造太多的实例会影响系统性能,我们使用Lazy Load解决这个问题,在分析数据访问的实现时,我们还会回到这个问题上来。
EntityExtension这个类提供了一个非常常用的扩展方法:根据ID取得实体:
1: /// <summary>
2: /// 根据ID取得实体
3: /// </summary>
4: /// <typeparam name="T">实体类型</typeparam>
5: /// <param name="query">实体查询</param>
6: /// <param name="id">ID</param>
7: /// <returns>对应的实体,不存在则返回空</returns>
8: public static T GetByID<T>(this IQueryable<T> query, int id)
9: where T : Entity<T>
10: {11: if (query == null)
12: throw new ArgumentNullException("query");
13: 14: return query.SingleOrDefault(entity => entity.ID == id);
15: }有了这个方法,结合数据访问接口,就可以通过这样的方式取得一个Blog:database.GetDataAccess<Blog>().GetByID(1);
该方式,以后还会进一步简化为:database.Blogs.GetByID(1);
今天我们分析了实体基类的代码和设计方式,下一篇中我们将着重研究数据访问两个接口的设计与实现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号