

Python基于途牛网站的全国景点分析
网站 http://menpiao.tuniu.com/cat_0_0_0_0_0_0_1_1_1.html
1.爬虫的操作文档
(1)分析网页,
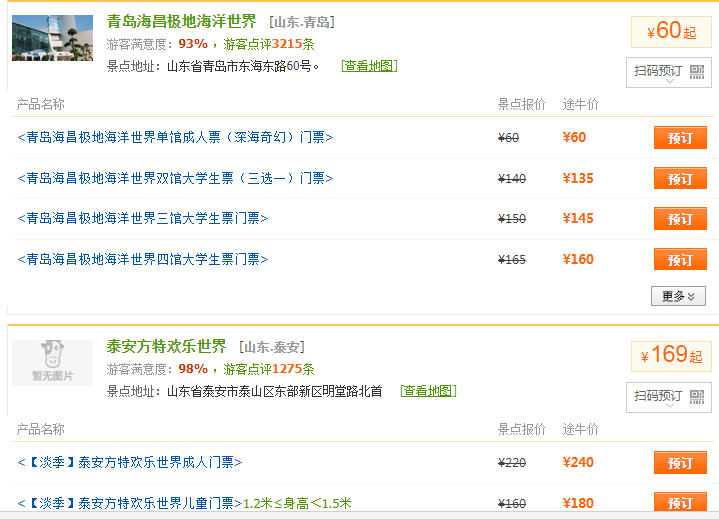
(2).可以发现,每个景点是一个list_item都属于list_view
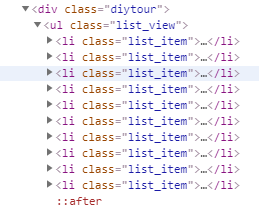
所以可以使用response.xpath("//ul[@class='list_view']//li[@class='list_item']")
获取这些内容

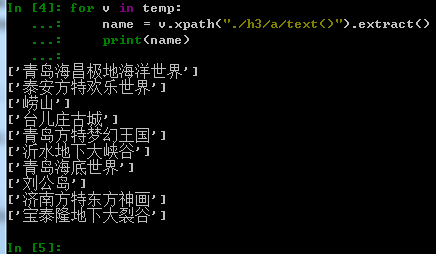
(3)票价的位置
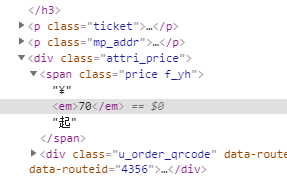
可以使xpath("./div[@class='attri_price']/span[@class='price f_yh']/em/text()").extract()获取
(4)通过这种类似的边测试边修改爬虫代码将网页上的数据爬取出来
2.爬虫代码如下
import scrapy import re import time def data_write(list1): output = open('zghjingdian.xls','a+',encoding='gbk') #output.write('name\tgender\tstatus\tage\n') for i in range(len(list1)): for j in range(len(list1[i])): output.write(str(list1[i][j])) #write函数不能写int类型的参数,所以使用str()转化 output.write('\t') #相当于Tab一下,换一个单元格 output.write('\n') #写完一行立马换行 output.close() class zghjingdian(scrapy.Spider): #需要继承scrapy.Spider类 name = "zghjingdian" # 定义蜘蛛名 start_urls = ['http://menpiao.tuniu.com/cat_0_0_0_0_0_0_1_1_1.html'] def parse(self, response): list2 = [] temp =response.xpath("//ul[@class='list_view']//li[@class='list_item']") time.sleep(5)#防止每一页爬取太快 for v in temp: name = v.xpath("./h3/a/text()").extract() if(name): name = name[0].strip() else: name = "缺失" location1=v.xpath("./h3/span/a/text()").extract() #location="".join(location1) location=location1[0] if(location): location = location else: location = "缺失" manyidu=v.xpath("./p[@class='ticket']/strong/text()").extract() if(manyidu): manyidu = manyidu[0].strip() else: manyidu = "缺失" dianpingshuliang=v.xpath("./p[@class='ticket']/span/strong/text()").extract() if(dianpingshuliang): dianpingshuliang = dianpingshuliang[0].strip() else: dianpingshuliang = "缺失" jutididian=v.xpath("./p[@class='mp_addr']/text()").extract() if(jutididian): jutididian = jutididian[0].strip() else: jutididian = "缺失" price=v.xpath("./div[@class='attri_price']/span[@class='price f_yh']/em/text()").extract() if(price): price = price[0].strip() else: price = "缺失" list1 = [] list1.append(name) list1.append(location) list1.append(manyidu) list1.append(dianpingshuliang) list1.append(jutididian) list1.append(price) list2.append(list1) #write_excel_xls_append(zghjingdian.file_name_excel,list2) data_write(list2) response.css('a.page_next ').extract()[0].split('"')[5] next_page ="http://menpiao.tuniu.com"+response.css('a.page_next').extract()[0].split('"')[5] if next_page is not None: next_page = response.urljoin(next_page) zghjingdian.start_urls[0] = next_page yield scrapy.Request(next_page, callback=self.parse)
3.运行命令
scrapy crawl zghjingdian
4.爬取的数据
目前最多爬取了796条,第一页的某些数据
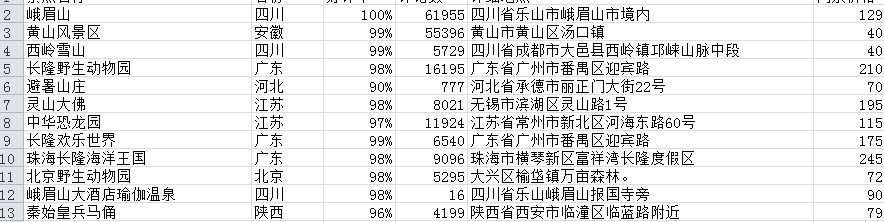
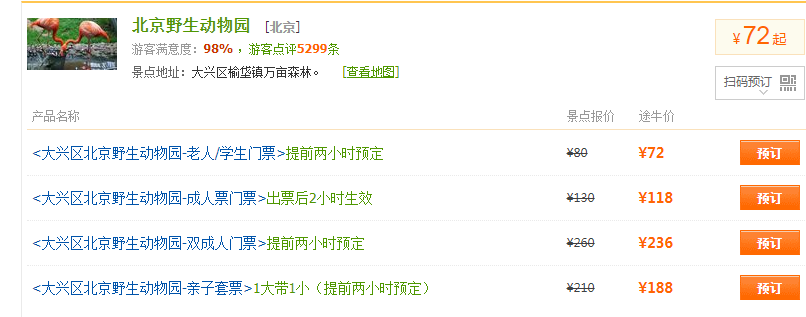
目前找不到最后一页是第几页,所以选择下面的页面对比
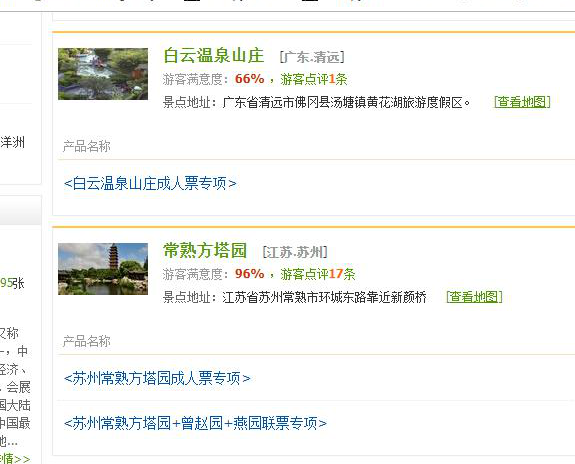
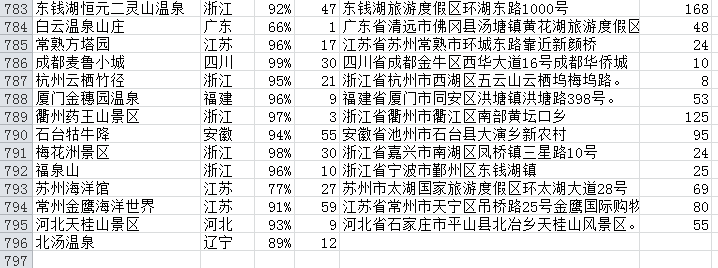
导入数据
import pandas as pd import numpy as np jingdian = pd.read_excel(r"C:\Users\lenovo\Desktop\QuanguoJD\zghjingdian.xlsx") jingdian

门票价格和好评率的散点图
plt.plot(jingdian["好评率"],jingdian["门票价格"],'o') plt.xlabel("好评率") plt.ylabel("门票价格") plt.show()
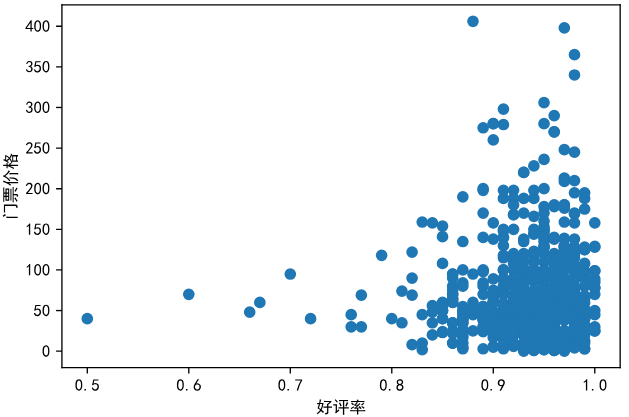
通过分析,一般好评率高的景点,门票也一般集中在0-150元左右
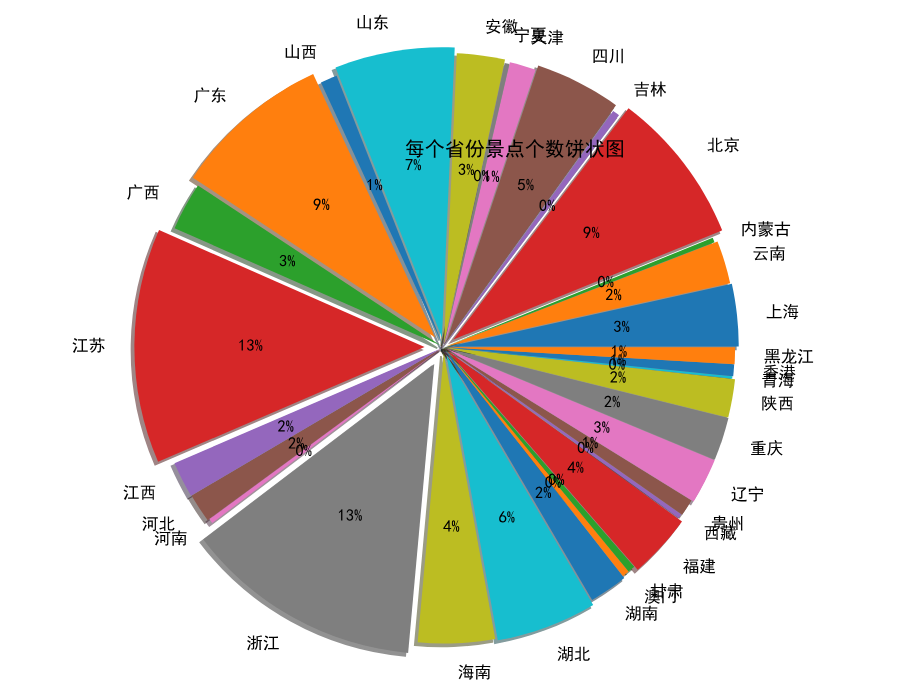
每个省份景点的个数统计
x=list(geshu["景点名称"]) y=list(geshu["省份"]) geshu["景点名称"].sum() bili=(geshu["景点名称"]/geshu["景点名称"].sum())#每个省份的占比 plt.subplot(1,1,1) labels=y x=np.array(x) explode=bili labeldistance=1.1 plt.pie(x,labels=labels,autopct="%.0f%%",shadow=True,explode=explode,radius=2.0,labeldistance=labeldistance) plt.title("每个省份景点个数饼状图",loc="right")
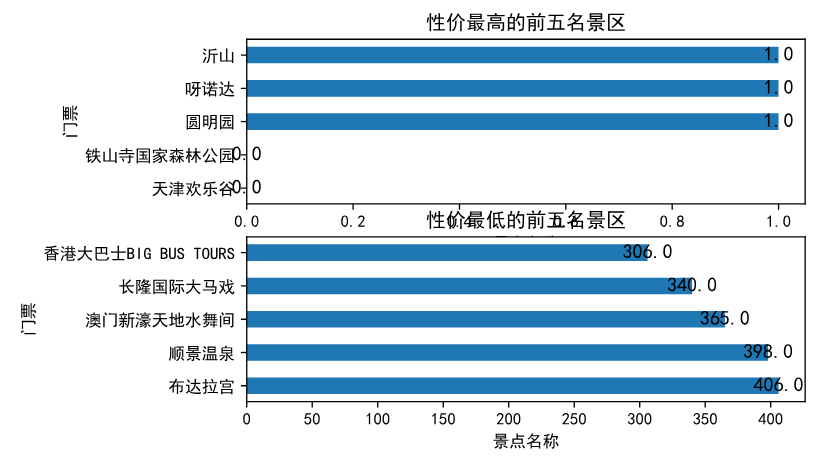
分析性价比高的景点
取前5名和后5分析
xjb1=jingdian.sort_values(by=["门票价格","好评率"],ascending=[True,False]).head(5) xjb2=jingdian.sort_values(by=["门票价格","好评率"],ascending=[False,True]).head(5)
sf1=xjb1["景点名称"] mp1=xjb1["门票价格"] sf2=xjb2["景点名称"] mp2=xjb2["门票价格"]
plt.subplot(2,1,1) x=np.array(sf1) y=np.array(mp1) plt.barh(x,height=0.5,width=y,align='center') plt.title("性价最高的前五名景区",loc="center") for a,b in zip(x,y): plt.text(b,a,b,ha='center',va='center',fontsize=12) plt.xlabel('景点名称') plt.ylabel('门票') plt.grid(False) plt.subplot(2,1,2) x=np.array(sf2) y=np.array(mp2) plt.barh(x,height=0.5,width=y,align='center') plt.title("性价最低的前五名景区",loc="center") for a,b in zip(x,y): plt.text(b,a,b,ha='center',va='center',fontsize=12) plt.xlabel('景点名称') plt.ylabel('门票') plt.grid(False)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号