

[数据结构] 2.2 Huffman树
注:本文原创,转载请注明出处,本人保留对未注明出处行为的责任追究。
1.Huffman树是什么
Huffman树也称为哈夫曼编码,是一种编码方式,常用于协议的制定,以节省传输空间。

A - F字母,出现的频率分别为:
A:5,B: 24, C:7,D:17,E:34,F:5,G:13
对比:
1)使用常规协议
如果我们将这些字母无论大小进行编码,一共是7个字母,因此协议规定用三位二进制数表示,传输完这105个字符,共需要105*3 = 315位。
2)使用Huffman树
如果我们按照Huffman树的规则(如上图),共需要 5*4 + 24 * 2 + 7*4 + 17*2 + 34*1+5*5+13*3 = 228位,共节省87位,大约节省27%的带宽占用。
2.Huffman树的原理
Huffman树是依据字符的出现频次,对字符进行二进制的编码,出现频次高的节点编码字符少,出现频次低的字节编码字符多。
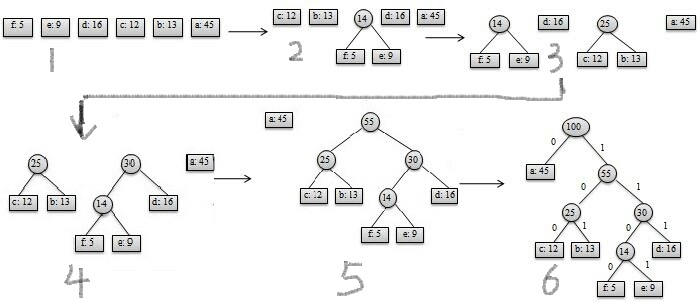
感谢: https://www.cnblogs.com/journal-of-xjx/p/6670464.html 博主:Jiaxin Tse
如图是huffman树的构建过程,字符的权重为出现频次。
构建过程:
STEP1:将权重最小的两个字符节点构建一个父节点,权重为两者权重之和
STEP1 进行 size - 1次 ,即可完成huffman树的构建。
编码过程: 给定字符串,以及"单词-频次Map" ,构建huffman树,将给定字符串转成二进制字符串
以字符d为例子,从根节点开始,右枝为1,左枝为0,因此d的编码就是111
给定 abdc => 0101111100
因为每一个被编码的字符节点是叶子节点,因此每一串二进制编码都有唯一对应的译码
解码过程: 给定二进制编码,以及"单词-频次Map",构建huffman树,将给定的二进制字符串转成字符串
0101111100 => abdc
3.Huffman树的三大操作
Huffman树常见的三大操作有 构建、编码、解码。上面给出了一些基本原理和使用,接下来是代码设计的思路。
Node 以及Tree :
/** * 哈夫曼树 */ public class HuffmanTree { static class Node{ Character ch; // 保存被编码的字符 long frequency ; // 被编码的字符出现频次 Node left; // 左子节点 Node right; // 右子节点 Node parent; // 父节点 } static class Tree{ Node root; List<Node> leafNodes; }
1)构建huffman树
STEP1: 将每个字符抽象成一个节点,使用PriprotiesQueue这种排序的结构,按照Node的权值,也就是单词的出现频次为优先级排序
STEP2: 取出其中权值最小的两个节点,进行构建父节点,父节点权值为子节点权值之和。
假设初始的节点数(初始的队列大小)为size,那么需要size - 1次STEP2才能完成整颗huffman树的构建。
记得存储叶子节点的列表,以便编码的时候能从叶子节点向根节点进行拼接字符串。
/**
* 构建huffman树
* @return
*/
public static Tree buildHuffmanTree(
Map<Character,Long> charAndCounts){
Tree huffmanTree = new Tree();
huffmanTree.leafNodes = new ArrayList<Node>();
// 依据Node有序的队列
PriorityQueue<Node> priorityQueue = new PriorityQueue<Node>();
// 对每个字符进行遍历
for(Character ch : charAndCounts.keySet()){
long frequency = charAndCounts.get(ch);
Node node = new Node(ch,frequency);
// 存入叶子节点列表,以便于遍历
huffmanTree.leafNodes.add(node);
// 入堆
priorityQueue.add(node);
}
// 进行建树操作,进行size-1次操作,每次取出两个最小的权值的节点,构建父节点并合并权值。
for(int i = 0 ; i < charAndCounts.size() - 1 ; i++ ){
Node node1 = priorityQueue.poll(); // 第一小 ,默认放右边
Node node2 = priorityQueue.poll(); // 第二小,默认放左边
Node top = new Node();
top.right = node1;
top.left = node2;
top.frequency = node1.frequency + node2.frequency;
node1.parent = top;
node2.parent = top;
priorityQueue.add(top);
}
// 经过size-1次合并操作后,队列中只剩下一个节点
huffmanTree.root = priorityQueue.poll();
return huffmanTree;
}
2)编码 : 给定字符串,以及"单词-频次Map" ,构建huffman树,将给定字符串转成二进制字符串
首先使用 "单词-频次"Map 构建huffman树。
依次遍历每个huffman树的叶子节点,每个节点由叶子节点向根节点遍历,并进行 0 、1的拼接。
这样就生成了 Map<字符,二进制编码>表。
然后依次遍历给定字符串的每个字符,分别转成二进制编码拼接即可。
/**
* 进行编码
* @param str
* @param charAndCounts
* @return
*/
public static String encode(
String str,
Map<Character,Long> charAndCounts){
Map<Character,String> chAndEncoding = new HashMap<Character, String>();
// 1. 构建huffman树
Tree tree = buildHuffmanTree(charAndCounts);
// 2.依次遍历每个huffman树的叶子节点,每个节点由叶子节点向根节点遍历,并进行 0 、1的拼接。
List<Node> leafNodes = tree.leafNodes;
for(Node leafNode : leafNodes){
Node current = leafNode;
String binaryCode = "";
while(current != tree.root && current != null){
if(current.parent != null && current == current.parent.left){
binaryCode = "0" + binaryCode;
}else if(current.parent != null && current == current.parent.right){
binaryCode = "1" + binaryCode;
}
current = current.parent;
}
chAndEncoding.put(leafNode.ch,binaryCode);
}
System.out.println(chAndEncoding);
// 3.遍历每个字符进行编码
StringBuffer strEncoded = new StringBuffer();
for(char ch : str.toCharArray()){
strEncoded.append(chAndEncoding.get(ch));
}
return strEncoded.toString();
}
测试:
public static void main(String[] args) {
Map<Character,Long> map = new HashMap<Character, Long>();
map.put('a',5l);
map.put('b',24l);
map.put('c',7l);
map.put('d',17l);
map.put('e',34l);
map.put('f',5l);
map.put('g',13l);
System.out.println(encode("abcd",map));
}
结果:
{a=01001, b=10, c=0101, d=11, e=00, f=01000, g=011}
0100110010111
3)解码:给定二进制字符串,以及"单词-频次Map“,构建huffman树,将给定二进制字符串转成原未经编码的字符串。
首先使用"单词-频次"Map 构建huffman树。
然后按照给定的二进制字符串,挨个进行从根的查找,找到叶子节点后就转成原字符,从下一个字符串索引开始继续解码。
/** * 解码过程 * @param binStr * @param charsAndCounts * @return */ public static String decode( String binStr, Map<Character,Long> charsAndCounts){ // 1.获得Huffman树 Tree tree = buildHuffmanTree(charsAndCounts); // 2.按照给定的二进制字符串,挨个进行从根的查找,找到叶子节点后就转成原字符,从下一个字符串索引开始继续解码。 StringBuffer originalStr = new StringBuffer(); int i = 0; while(i < binStr.length()){ char ch = '\0'; Node current = tree.root; while(current.ch ==null && i < binStr.length()){ ch = binStr.charAt(i); if(ch == '1'){ current = current.right; }else if(ch == '0'){ current = current.left; } i++; } originalStr.append(current.ch); } return originalStr.toString(); }
测试:
public static void main(String[] args) { Map<Character,Long> map = new HashMap<Character, Long>(); map.put('a',5l); map.put('b',24l); map.put('c',7l); map.put('d',17l); map.put('e',34l); map.put('f',5l); map.put('g',13l); System.out.println(encode("abcd",map)); System.out.println(decode("0100110010111",map)); }
结果:
{a=01001, b=10, c=0101, d=11, e=00, f=01000, g=011}
0100110010111
abcd
abcd

