huffman编码
哈夫曼编码应该算数据结构“树”这一章最重要的一个问题了,当时大一下学期学的时候没弄懂,一年后现在算是明白了。
首先,讲讲思路。
正好这学期在学算法,这里面就用到了贪心算法,刚好练练手。
整个问题有几个关键点:
1,首先是要思考怎么样存下从txt中读取的所有字符中的每种字符出现的次数,首先想到的应该是结构体数组,再仔细想想不对呀,时间复杂度太高了,每次判断一个字符都对知道它属于结构体数组中的哪一个,那要是txt中有很多字符,那光这个就得花好多时间。然后想想,如果读取的字符如果只有那255个ASCII中的字符时可以直接用一个整形数组来表示呀!数组的下标为整数,整数和字符数不正是通过ASCII码一一对应了吗。当然这些字符必须全部是那255个中的。所以整形数组的大小也只需255.当然了,如果对C++关联容器的知识比较熟悉,用关联容器更方便,毕竟,我们这种方法其实就是在模拟关联容器。
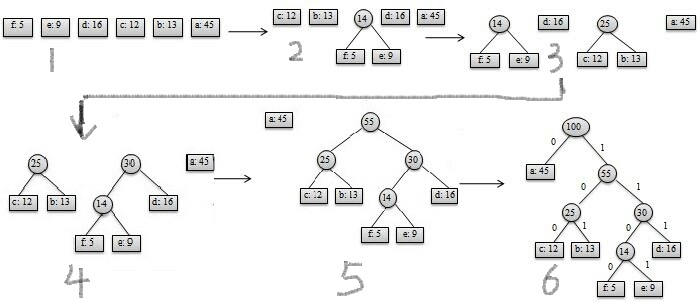
2,然后我们怎么从刚才得到的各个字符的频率来整出一颗哈夫曼树呢?首先,离散数学上讲的构建哈夫曼树应该是比较容易理解的,就是每次选取两个权值(也就是这里的频率)最小的两个节点作为左右孩子(小的在左,大的在右),然后把它们的权值之和作为一个新的待选择的结点去和剩余结点判断,自底向上构建,直到剩余权值最大的一个结点,完毕。虽然这样说着很简单,但是落实到代码就值得思考了。我们该怎么样表示这样一棵树呢?习惯性地用指针?认真思考后我们发现,用指针行不通,因为这棵树是自底向上构建的,我们在构建完成之前是不知道这棵树的遍历序列的,也就没法通过递归的形式来创建这棵树。那么,我们现在应该想到的是用数组,没错,用数组可以!显然是结构体数组,所以得考虑结构体中要有哪些变量,首先要有每个结点表示的字符,对应的权值,还要有左右孩子的下标,双亲的下标。这样就可以在数组中存下这棵树了。
3,在得到哈夫曼树后,该怎么输出每个字符对应的哈夫曼编码呢?从每个叶子结点出发,逐步向根结点方向遍历,每次到达其双亲时,判断自己是双亲的左孩子还是右孩子,如果是左孩子,在该叶子表示的字符对应的编码(用string表示)加上0,否则加上1。然后再找到双亲的双亲,。。。直到到达根结点(根结点没有双亲,对应的双亲下标可以设为0),由于这样得到的编码01字符串是反的,所以我们要反一下就得到了正确的编码。
这里放一个ppt,是我们老师上课讲的,便于理解 https://files.cnblogs.com/files/journal-of-xjx/huffman.pptx
注意我是把一个txt文件中的所有字符读到一个string中去的。自己测试的时候随便放一个input.txt进去就可以了(注意必须是ASCII小于等于255的字符,超过这个范围的字符不能用这种方式表示)
代码如下:
1 #include <iostream> 2 #include <fstream> 3 #include <algorithm> 4 5 using namespace std; 6 7 #define NUM_CHARS 256 //读取的字符串中最多出现这么多种字符 8 #define MAX_FREQ 10000 //最大频率必须小于这个数 9 #define MAX_SIZE 512 10 11 //Huffman Tree结点 12 typedef struct HuffNode 13 { 14 char data; 15 unsigned int freq; 16 int parent; 17 int lchild; 18 int rchild; 19 }HuffNode; 20 //编码结点 21 typedef struct HuffCode 22 { 23 char data;//保存字符 24 string s;//保存字符对应的编码 25 }HuffCode; 26 27 //给定一个字符串,把字符的出现频率保存到freqs数组中 28 //注意字符出现的频率不能超出unsigned int所能表示的范围 29 int Create_freq_array(unsigned int (&freqs)[NUM_CHARS],string s, int &char_size)//传入数组的引用, 30 { 31 int i, maxfreq = 0; 32 for(int i=0;i<NUM_CHARS;i++) 33 freqs[i] = 0;//注意传入的数组的各元素先赋值为0 34 for(auto iter =s.begin(); iter!=s.end(); iter++) 35 { 36 freqs[*iter]++; //*iter为char型,这里转换成了int型,即以某个字符的ASCII码作为 37 if(freqs[*iter] > maxfreq)//它在freq数组中的下标,注意这种方式不能表示非ASCII码字符! 38 maxfreq = freqs[*iter];//每次记得更新maxfreq的值 39 } 40 for(i=0; i<NUM_CHARS; i++)//计算char_size值 41 { 42 if(freqs[i]) 43 { 44 char_size++; 45 } 46 } 47 return 0; 48 } 49 50 //打印字符频率表 51 int Print_freqs(unsigned int (&freqs)[NUM_CHARS],int n) 52 { 53 int i; 54 char c; 55 for(i = 0; i < NUM_CHARS; i++) 56 { 57 if(freqs[i]) 58 { 59 c = i;//把i以ASCII码值还原出对应的字符 60 cout << "字符 " << c << " 出现的频率为:" << freqs[i] << endl; 61 } 62 63 } 64 cout << endl << "以上共出现" << n << "种字符" << endl <<endl; 65 return 0; 66 } 67 68 int Build_Huffman_tree(unsigned int (&freqs)[NUM_CHARS],HuffNode (&Huffman_array)[MAX_SIZE],int n) 69 { //n表示freqs数组中实际包含的字符种类数 70 char c; 71 int k = 0,x1,x2; 72 unsigned int m1, m2; 73 74 for(int i=0;i<NUM_CHARS;i++)//把前n个叶结点的信息输入Huffman_array数组 75 { 76 if(freqs[i]) 77 { 78 c=i;//还原字符 79 Huffman_array[k].data = c; 80 Huffman_array[k].freq = freqs[i]; 81 Huffman_array[k].parent = 0; 82 Huffman_array[k].lchild = 0; 83 Huffman_array[k].rchild = 0; 84 k++; 85 } 86 } 87 for(int i=n;i<2*n-1;i++)//处理剩下n-1个非叶子结点 88 { 89 Huffman_array[i].data = '#'; 90 Huffman_array[i].freq = 0; 91 Huffman_array[i].parent = 0; 92 Huffman_array[i].lchild = 0; 93 Huffman_array[i].rchild = 0; 94 } 95 // 循环构造 Huffman 树 96 for(int i=0; i<n-1; i++) 97 { 98 m1=m2=MAX_FREQ; // m1、m2中存放两个无父结点且结点权值最小的两个结点 99 x1=x2=0; //x1、x2:构造哈夫曼树不同过程中两个最小权值结点在数组中的序号 100 /* 找出所有结点中权值最小、无父结点的两个结点,并合并之为一颗二叉树 */ 101 for (int j=0; j<n+i; j++) 102 { 103 if (Huffman_array[j].freq < m1 && Huffman_array[j].parent==0) 104 { //如果当前判断的结点的权值小于最小的m1,则把它赋给m1,同时 105 m2=m1; //更新m1结点的下标, 保持m1是当前所有判断过的元素中是最小的 106 x2=x1; //再把m1的信息赋给m2,保持m2是当前所有判断过的元素中是第二小的 107 m1=Huffman_array[j].freq ; 108 x1=j; 109 } 110 else if (Huffman_array[j].freq < m2 &&Huffman_array[j].parent==0) 111 //如果当前判断的结点的权值大于等于最小的m1,但是小于m2, 112 { //则只需把它赋给m2,更新m2,保持m2是当前所有判断过的元素中是第二小的 113 m2=Huffman_array[j].freq ; 114 x2=j; 115 } 116 } 117 /* 设置找到的两个子结点 x1、x2 的父结点信息 */ 118 Huffman_array[x1].parent = n+i; 119 Huffman_array[x2].parent = n+i; 120 Huffman_array[n+i].freq = Huffman_array[x1].freq + Huffman_array[x2].freq ; 121 Huffman_array[n+i].lchild = x1; 122 Huffman_array[n+i].rchild = x2; 123 } 124 return 0; 125 } 126 //哈夫曼编码,输出string中各种字符对应的编码 127 int Huffman_code(HuffNode(&Huffman_array)[MAX_SIZE],HuffCode (&Huffman_code_array)[NUM_CHARS],int n) 128 { 129 int temp; 130 for(int i = 0;i < n;i++) 131 { 132 temp = i;//当前处理的Huffman_array数组下标 133 Huffman_code_array[i].data = Huffman_array[i].data; 134 while(Huffman_array[temp].parent) 135 { 136 if(Huffman_array[Huffman_array[temp].parent].lchild == temp)//左孩子为0 137 { 138 Huffman_code_array[i].s += '0'; 139 } 140 else//右孩子为1 141 { 142 Huffman_code_array[i].s += '1'; 143 } 144 temp = Huffman_array[temp].parent; 145 } 146 reverse(Huffman_code_array[i].s.begin(), Huffman_code_array[i].s.end()); 147 } //注意翻转每一个string,这里用到了#include <algorithm> 148 return 0; 149 } 150 151 int Print_huffman_code(HuffCode (&Huffman_code_array)[NUM_CHARS],int n) 152 { 153 for(int i = 0;i < n;i++) 154 { 155 cout << "字符 " << Huffman_code_array[i].data << " 对应的哈夫曼编码为:" << Huffman_code_array[i].s << endl; 156 } 157 cout << endl; 158 return 0; 159 } 160 161 int main() 162 { 163 ifstream in("input.txt",ios::in);//从input.txt中读取输入数据 164 ofstream out("output.txt",ios::out);//向output.txt中写入数据 165 string s,temp; 166 int char_size = 0;//用以保存string中所包含的字符种类 167 unsigned int freqs[NUM_CHARS]; 168 HuffNode Huffman_array[MAX_SIZE]; 169 HuffCode Huffman_code_array[NUM_CHARS]; 170 while(getline(in,temp))//按行读取一个txt文件中的各个字符到一个string,每读完一行加上一个'\n' 171 { 172 s += temp; 173 s += '\n'; 174 } 175 cout << "输入的字符总数为: " << s.size() << endl << endl << "其中:" << endl;//string中包含的字符数 176 Create_freq_array(freqs,s,char_size); 177 Print_freqs(freqs,char_size); 178 Build_Huffman_tree(freqs,Huffman_array,char_size); 179 Huffman_code(Huffman_array,Huffman_code_array,char_size); 180 Print_huffman_code(Huffman_code_array,char_size); 181 return 0; 182 }
参考了别人的一些代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号