


目录
- 我的多线程WinForm程序老是抛出InvalidOperationException ,怎么解决?
- Invoke,BeginInvoke干什么用的,内部是怎么实现的
- 每个线程都有消息队列吗?
- 为什么Winform不允许跨线程修改UI线程控件的值
- 有没有什么办法可以简化WinForm多线程的开发
- CLR怎样实现lock(obj)锁定?
- WaitHandle是什么,他和他的派生类怎么使用
- 什么是用双锁实现Singleton,为什么要这样做,为什么有人说双锁检验是不安全的
- 互斥对象(Mutex)、事件(Event)对象与lock语句的比较
我只简单列举几种常用的方法,详细可参考.Net多线程总结(一)
一)使用Thread类
 ThreadStart threadStart=new ThreadStart(Calculate);//通过ThreadStart委托告诉子线程讲执行什么方法,这里执行一个计算圆周长的方法Thread thread=new Thread(threadStart);thread.Start(); //启动新线程
ThreadStart threadStart=new ThreadStart(Calculate);//通过ThreadStart委托告诉子线程讲执行什么方法,这里执行一个计算圆周长的方法Thread thread=new Thread(threadStart);thread.Start(); //启动新线程 public void Calculate(){
public void Calculate(){
 double Diameter=0.5;Console.Write("The perimeter Of Circle with a Diameter of {0} is {1}"Diameter,Diameter*Math.PI);
double Diameter=0.5;Console.Write("The perimeter Of Circle with a Diameter of {0} is {1}"Diameter,Diameter*Math.PI); }
}
二)使用Delegate.BeginInvoke
static CalculateMethod calcMethod = new CalculateMethod(Calculate);//把委托和具体的方法关联起来
static void Main(string[] args)
{
//此处开始异步执行,并且可以给出一个回调函数(如果不需要执行什么后续操作也可以不使用回调)
calcMethod.BeginInvoke(5, new AsyncCallback(TaskFinished), null);
Console.ReadLine();
}
//线程调用的函数,给出直径作为参数,计算周长
public static double Calculate(double Diameter)
{
return Diameter * Math.PI;
}
//线程完成之后回调的函数
public static void TaskFinished(IAsyncResult result)
{
double re = 0;
re = calcMethod.EndInvoke(result);
Console.WriteLine(re);
}
三)使用ThreadPool.QueueworkItem
WaitCallback w = new WaitCallback(Calculate);//下面启动四个线程,计算四个直径下的圆周长ThreadPool.QueueUserWorkItem(w, 1.0);ThreadPool.QueueUserWorkItem(w, 2.0);ThreadPool.QueueUserWorkItem(w, 3.0);ThreadPool.QueueUserWorkItem(w, 4.0);public static void Calculate(double Diameter){return Diameter * Math.PI;}
下面两条来自于http://www.cnblogs.com/tonyman/archive/2007/09/13/891912.html
必须要了解,执行.NET应用的线程实际上仍然是Windows线程。但是,当某个线程被CLR所知时,我们将它称为受托管的线程。具体来说,由受托管的代码创建出来的线程就是受托管的线程。如果一个线程由非托管的代码所创建,那么它就是非托管的线程。不过,一旦该线程执行了受托管的代码它就变成了受托管的线程。
一个受托管的线程和非托管的线程的区别在于,CLR将创建一个System.Threading.Thread类的实例来代表并操作前者。在内部实现中,CLR将一个包含了所有受托管线程的列表保存在一个叫做ThreadStore地方。
CLR确保每一个受托管的线程在任意时刻都在一个AppDomain中执行,但是这并不代表一个线程将永远处在一个AppDomain中,它可以随着时间的推移转到其他的AppDomain中。
从安全的角度来看,一个受托管的线程的主用户与底层的非托管线程中的Windows主用户是无关的。
启动了多个线程的程序在关闭的时候却出现了问题,如果程序退出的时候不关闭线程,那么线程就会一直的存在,但是大多启动的线程都是局部变量,不能一一的关闭,如果调用Thread.CurrentThread.Abort()方法关闭主线程的话,就会出现ThreadAbortException 异常,因此这样不行。
后来找到了这个办法: Thread.IsBackground 设置线程为后台线程。
msdn对前台线程和后台线程的解释:托管线程或者是后台线程,或者是前台线程。后台线程不会使托管执行环境处于活动状态,除此之外,后台线程与前台线程是一样的。一旦所有前台线程在托管进程(其中 .exe 文件是托管程序集)中被停止,系统将停止所有后台线程并关闭。通过设置 Thread.IsBackground 属性,可以将一个线程指定为后台线程或前台线程。例如,通过将 Thread.IsBackground 设置为 true,就可以将线程指定为后台线程。同样,通过将 IsBackground 设置为 false,就可以将线程指定为前台线程。从非托管代码进入托管执行环境的所有线程都被标记为后台线程。通过创建并启动新的 Thread 对象而生成的所有线程都是前台线程。如果要创建希望用来侦听某些活动(如套接字连接)的前台线程,则应将 Thread.IsBackground 设置为 true,以便进程可以终止。
所以解决办法就是在主线程初始化的时候,设置:Thread.CurrentThread.IsBackground = true;
这样,主线程就是后台线程,在关闭主程序的时候就会关闭主线程,从而关闭所有线程。但是这样的话,就会强制关闭所有正在执行的线程,所以在关闭的时候要对线程工作的结果保存。
经常看到名为BeginXXX和EndXXX的方法,他们是做什么用的
这是.net的一个异步方法名称规范
.Net在设计的时候为异步编程设计了一个异步编程模型(APM),这个模型不仅是使用.NET的开发人员使用,.Net内部也频繁用到,比如所有的Stream就有BeginRead,EndRead,Socket,WebRequet,SqlCommand都运用到了这个模式,一般来讲,调用BegionXXX的时候,一般会启动一个异步过程去执行一个操作,EndEnvoke可以接收这个异步操作的返回,当然如果异步操作在EndEnvoke调用的时候还没有执行完成,EndInvoke会一直等待异步操作完成或者超时
.Net的异步编程模型(APM)一般包含BeginXXX,EndXXX,IAsyncResult这三个元素,BeginXXX方法都要返回一个IAsyncResult,而EndXXX都需要接收一个IAsyncResult作为参数,他们的函数签名模式如下
IAsyncResult BeginXXX(...);
<返回类型> EndXXX(IAsyncResult ar);
BeginXXX和EndXXX中的XXX,一般都对应一个同步的方法,比如FileStream的Read方法是一个同步方法,相应的BeginRead(),EndRead()就是他的异步版本,HttpRequest有GetResponse来同步接收一个响应,也提供了BeginGetResponse和EndGetResponse这个异步版本,而IAsynResult是二者联系的纽带,只有把BeginXXX所返回的IAsyncResult传给对应的EndXXX,EndXXX才知道需要去接收哪个BeginXXX发起的异步操作的返回值。
这个模式在实际使用时稍显繁琐,虽然原则上我们可以随时调用EndInvoke来获得返回值,并且可以同步多个线程,但是大多数情况下当我们不需要同步很多线程的时候使用回调是更好的选择,在这种情况下三个元素中的IAsynResult就显得多余,我们一不需要用其中的线程完结标志来判断线程是否成功完成(回调的时候线程应该已经完成了),二不需要他来传递数据,因为数据可以写在任何变量里,并且回调时应该已经填充,所以可以看到微软在新的.Net Framework中已经加强了对回调事件的支持,这总模型下,典型的回调程序应该这样写
a.DoWork+=new SomeEventHandler(Caculate);
a.CallBack+=new SomeEventHandler(callback);
a.Run();
(注:我上面讲的是普遍的用法,然而BeginXXX,EndXXX仅仅是一种模式,而对这个模式的实现完全取决于使用他的开发人员,具体实现的时候你可以使用另外一个线程来实现异步,也可能使用硬件的支持来实现异步,甚至可能根本和异步没有关系(尽管几乎没有人会这样做)-----比如直接在Beginxxx里直接输出一个"Helloworld",如果是这种极端的情况,那么上面说的一切都是废话,所以上面的探讨并不涉及内部实现,只是告诉大家微软的模式,和框架中对这个模式的经典实现)
有一句话总结的很好:多线程是实现异步的一种手段和工具
我们通常把多线程和异步等同起来,实际是一种误解,在实际实现的时候,异步有许多种实现方法,我们可以用进程来做异步,或者使用纤程,或者硬件的一些特性,比如在实现异步IO的时候,可以有下面两个方案:
1)可以通过初始化一个子线程,然后在子线程里进行IO,而让主线程顺利往下执行,当子线程执行完毕就回调
2)也可以根本不使用新线程,而使用硬件的支持(现在许多硬件都有自己的处理器),来实现完全的异步,这是我们只需要将IO请求告知硬件驱动程序,然后迅速返回,然后等着硬件IO就绪通知我们就可以了
实际上DotNet Framework里面就有这样的例子,当我们使用文件流的时候,如果制定文件流属性为同步,则使用BeginRead进行读取时,就是用一个子线程来调用同步的Read方法,而如果指定其为异步,则同样操作时就使用了需要硬件和操作系统支持的所谓IOCP的机制
我的多线程WinForm程序老是抛出InvalidOperationException ,怎么解决?
在WinForm中使用多线程时,常常遇到一个问题,当在子线程(非UI线程)中修改一个控件的值:比如修改进度条进度,时会抛出如下错误
Cross-thread operation not valid: Control 'XXX' accessed from a thread other than the thread it was created on.
在VS2005或者更高版本中,只要不是在控件的创建线程(一般就是指UI主线程)上访问控件的属性就会抛出这个错误,解决方法就是利用控件提供的Invoke和BeginInvoke把调用封送回UI线程,也就是让控件属性修改在UI线程上执行,下面列出会报错的代码和他的修改版本
ThreadStart threadStart=new ThreadStart(Calculate);//通过ThreadStart委托告诉子线程讲执行什么方法Thread thread=new Thread(threadStart);thread.Start();public void Calculate(){ double Diameter=0.5; double result=Diameter*Math.PI; CalcFinished(result);//计算完成需要在一个文本框里显示}public void CalcFinished(double result){ this.TextBox1.Text=result.ToString();//会抛出错误}上面加粗的地方在debug的时候会报错,最直接的修改方法是修改Calculate这个方法如下
delegate void changeText(double result);public void Calculate(){ double Diameter=0.5; double result=Diameter*Math.PI; this.BeginInvoke(new changeText(CalcFinished),t.Result);//计算完成需要在一个文本框里显示} 这样就ok了,但是最漂亮的方法是不去修改Calculate,而去修改CalcFinished这个方法,因为程序里调用这个方法的地方可能很多,由于加了是否需要封送的判断,这样修改还能提高非跨线程调用时的性能
delegate void changeText(double result);public void CalcFinished(double result){ if(this.InvokeRequired){
if(this.InvokeRequired){ this.BeginInvoke(new changeText(CalcFinished),t.Result);
this.BeginInvoke(new changeText(CalcFinished),t.Result); } else{ this.TextBox1.Text=result.ToString(); }}
} else{ this.TextBox1.Text=result.ToString(); }}上面的做法用到了Control的一个属性InvokeRequired(这个属性是可以在其他线程里访问的),这个属性表明调用是否来自另非UI线程,如果是,则使用BeginInvoke来调用这个函数,否则就直接调用,省去线程封送的过程
Invoke,BeginInvoke干什么用的,内部是怎么实现的?
这两个方法主要是让给出的方法在控件创建的线程上执行
Invoke使用了Win32API的SendMessage,
UnsafeNativeMethods.PostMessage(new HandleRef(this, this.Handle), threadCallbackMessage, IntPtr.Zero, IntPtr.Zero);
BeginInvoke使用了Win32API的PostMessage
UnsafeNativeMethods.PostMessage(new HandleRef(this, this.Handle), threadCallbackMessage, IntPtr.Zero, IntPtr.Zero);
这两个方法向UI线程的消息队列中放入一个消息,当UI线程处理这个消息时,就会在自己的上下文中执行传入的方法,换句话说凡是使用BeginInvoke和Invoke调用的线程都是在UI主线程中执行的,所以如果这些方法里涉及一些静态变量,不用考虑加锁的问题
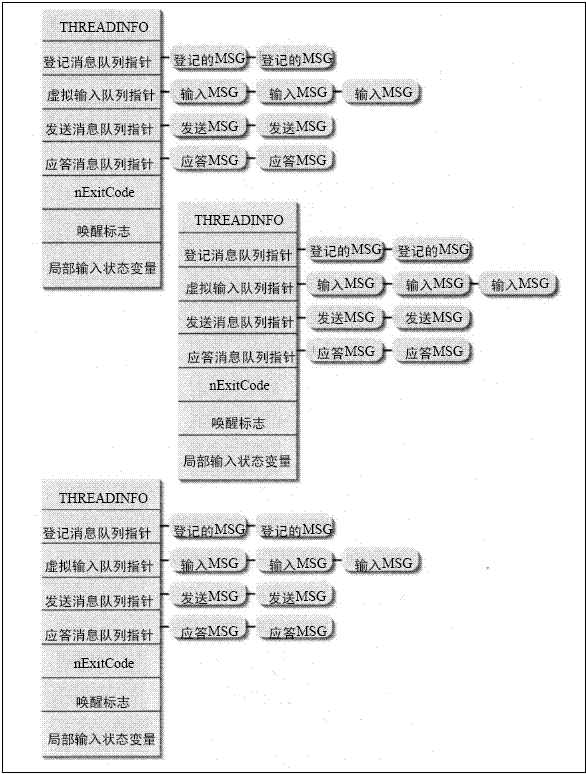
不是,只有创建了窗体对象的线程才会有消息队列(下面给出<Windows 核心编程>关于这一段的描述)
当一个线程第一次被建立时,系统假定线程不会被用于任何与用户相关的任务。这样可以减少线程对系统资源的要求。但是,一旦这个线程调用一个与图形用户界面有关的函数(例如检查它的消息队列或建立一个窗口),系统就会为该线程分配一些另外的资源,以便它能够执行与用户界面有关的任务。特别是,系统分配一个T H R E A D I N F O结构,并将这个数据结构与线程联系起来。
这个T H R E A D I N F O结构包含一组成员变量,利用这组成员,线程可以认为它是在自己独占的环境中运行。T H R E A D I N F O是一个内部的、未公开的数据结构,用来指定线程的登记消息队列(posted-message queue)、发送消息队列( send-message queue)、应答消息队列( r e p l y -message queue)、虚拟输入队列(virtualized-input queue)、唤醒标志(wake flag)、以及用来描述线程局部输入状态的若干变量。图2 6 - 1描述了T H R E A D I N F O结构和与之相联系的三个线程。
在vs2003下,使用子线程调用ui线程创建的控件的属性是不会有问题的,但是编译的时候会出现警告,但是vs2005及以上版本就会有这样的问题,下面是msdn上的描述
"当您在 Visual Studio 调试器中运行代码时,如果您从一个线程访问某个 UI 元素,而该线程不是创建该 UI 元素时所在的线程,则会引发 InvalidOperationException。调试器引发该异常以警告您存在危险的编程操作。UI 元素不是线程安全的,所以只应在创建它们的线程上进行访问"
从上面可以看出,这个异常实际是debugger耍的花招,也就是说,如果你直接运行程序的exe文件,或者利用运行而不调试(Ctrl+F5)来运行你的程序,是不会抛出这样的异常的.大概ms发现v2003的警告对广大开发者不起作用,所以用了一个比较狠一点的方法.
不过问题依然存在:既然这样设计的原因主要是因为控件的值非线程安全,那么DotNet framework中非线程安全的类千千万万,为什么偏偏跨线程修改Control的属性会有这样严格的限制策略呢?
这个问题我还回答不好,希望博友们能够予以补充
使用backgroundworker,使用这个组建可以避免回调时的Invoke和BeginInvoke,并且提供了许多丰富的方法和事件
参见.Net多线程总结(二)-BackgroundWorker,我在这里不再赘诉
作用是减小线程创建和销毁的开销
创建线程涉及用户模式和内核模式的切换,内存分配,dll通知等一系列过程,线程销毁的步骤也是开销很大的,所以如果应用程序使用了完一个线程,我们能把线程暂时存放起来,以备下次使用,就可以减小这些开销
所有进程使用一个共享的线程池,还是每个进程使用独立的线程池?
每个进程都有一个线程池,一个Process中只能有一个实例,它在各个应用程序域(AppDomain)是共享的,.Net2.0 中默认线程池的大小为工作线程25个,IO线程1000个,有一个比较普遍的误解是线程池中会有1000个线程等着你去取,其实不然, ThreadPool仅仅保留相当少的线程,保留的线程可以用SetMinThread这个方法来设置,当程序的某个地方需要创建一个线程来完成工作时,而线程池中又没有空闲线程时,线程池就会负责创建这个线程,并且在调用完毕后,不会立刻销毁,而是把他放在池子里,预备下次使用,同时如果线程超过一定时间没有被使用,线程池将会回收线程,所以线程池里存在的线程数实际是个动态的过程
当我首次看到线程池的时候,脑袋里的第一个念头就是给他设定一个最大值,然而当我们查看ThreadPool的SetMaxThreads文档时往往会看到一条警告:不要手动更改线程池的大小,这是为什么呢?
其实无论FileStream的异步读写,异步发送接受Web请求,甚至使用delegate的beginInvoke都会默认调用 ThreadPool,也就是说不仅你的代码可能使用到线程池,框架内部也可能使用到,更改的后果影响就非常大,特别在iis中,一个应用程序池中的所有 WebApplication会共享一个线程池,对最大值的设定会带来很多意想不到的麻烦
线程池有一个方法可以让我们看到线程池中可用的线程数量:GetAvaliableThread(out workerThreadCount,out iocompletedThreadCount),对于我来说,第一次看到这个函数的参数时十分困惑,因为我期望这个函数直接返回一个整形,表明还剩多少线程,这个函数居然一次返回了两个变量.
原来线程池里的线程按照公用被分成了两大类:工作线程和IO线程,或者IO完成线程,前者用于执行普通的操作,后者专用于异步IO,比如文件和网络请求,注意,分类并不说明两种线程本身有差别,线程就是线程,是一种执行单元,从本质上来讲都是一样的,线程池这样分类,举例来说,就好像某施工工地现在有1000把铁锹,规定其中25把给后勤部门用,其他都给施工部门,施工部门需要大量使用铁锹来挖地基(例子土了点,不过说明问题还是有效的),后勤部门用铁锹也就是铲铲雪,铲铲垃圾,给工人师傅修修临时住房,所以用量不大,显然两个部门的铁锹本身没有区别,但是这样的划分就为管理两个部门的铁锹提供了方便
线程池中两种线程分别在什么情况下被使用,二者工作原理有什么不同?
下面这个例子直接说明了二者的区别,我们用一个流读出一个很大的文件(大一点操作的时间长,便于观察),然后用另一个输出流把所读出的文件的一部分写到磁盘上
我们用两种方法创建输出流,分别是
创建了一个异步的流(注意构造函数最后那个true)
FileStream outputfs=new FileStream(writepath, FileMode.Create, FileAccess.Write, FileShare.None,256,true);
创建了一个同步的流
FileStream outputfs = File.OpenWrite(writepath);
然后在写文件期间查看线程池的状况
string readpath = "e:\\RHEL4-U4-i386-AS-disc1.iso";string writepath = "e:\\kakakak.iso";byte[] buffer = new byte[90000000];//FileStream outputfs=new FileStream(writepath, FileMode.Create, FileAccess.Write, FileShare.None,256,true);//Console.WriteLine("异步流");//创建了一个同步的流FileStream outputfs = File.OpenWrite(writepath);Console.WriteLine("同步流"); //然后在写文件期间查看线程池的状况ShowThreadDetail("初始状态");FileStream fs = File.OpenRead(readpath);fs.BeginRead(buffer, 0, 90000000, delegate(IAsyncResult o){ outputfs.BeginWrite(buffer, 0, buffer.Length, delegate(IAsyncResult o1) { Thread.Sleep(1000); ShowThreadDetail("BeginWrite的回调线程"); }, null); Thread.Sleep(500);//this is important cause without this, this Thread and the one used for BeginRead May seem to be same one},null);Console.ReadLine();public static void ShowThreadDetail(string caller){ int IO; int Worker; ThreadPool.GetAvailableThreads(out Worker, out IO); Console.WriteLine("Worker: {0}; IO: {1}", Worker, IO);}输出结果
异步流
Worker: 500; IO: 1000
Worker: 500; IO: 999
同步流
Worker: 500; IO: 1000
Worker: 499; IO: 1000
这两个构造函数创建的流都可以使用BeginWrite来异步写数据,但是二者行为不同,当使用同步的流进行异步写时,通过回调的输出我们可以看到,他使用的是工作线程,而非IO线程,而异步流使用了IO线程而非工作线程
其实当没有制定异步属性的时候,.Net实现异步IO是用一个子线程调用fs的同步Write方法来实现的,这时这个子线程会一直阻塞直到调用完成.这个子线程其实就是线程池的一个工作线程,所以我们可以看到,同步流的异步写回调中输出的工作线程数少了一,而使用异步流,在进行异步写时,采用了 IOCP方法,简单说来,就是当BeginWrite执行时,把信息传给硬件驱动程序,然后立即往下执行(注意这里没有额外的线程),而当硬件准备就绪, 就会通知线程池,使用一个IO线程来读取
没有提供方法控制加入线程池的线程:一旦加入线程池,我们没有办法挂起,终止这些线程,唯一可以做的就是等他自己执行
1)不能为线程设置优先级
2)一个Process中只能有一个实例,它在各个AppDomain是共享的。ThreadPool只提供了静态方法,不仅我们自己添加进去的WorkItem使用这个Pool,而且.net framework中那些BeginXXX、EndXXX之类的方法都会使用此Pool。
3)所支持的Callback不能有返回值。WaitCallback只能带一个object类型的参数,没有任何返回值。
4)不适合用在长期执行某任务的场合。我们常常需要做一个Service来提供不间断的服务(除非服务器down掉),但是使用ThreadPool并不合适。
下面是另外一个网友总结的什么不需要使用线程池,我觉得挺好,引用下来
如果您需要使一个任务具有特定的优先级。
如果您具有可能会长时间运行(并因此阻塞其他任务)的任务。
如果您需要将线程放置到单线程单元中(所有 ThreadPool 线程均处于多线程单元中)。
如果您需要与该线程关联的稳定标识。例如,您应使用一个专用线程来中止该线程、将其挂起或按名称发现它。
从原理上讲,lock和Syncronized Attribute都是用Moniter.Enter实现的,比如如下代码
object lockobj=new object();lock(obj){ //do things  }
}
在编译时,会被编译为类似
try{ Moniter.Enter(obj){ //do things }}catch{}finally{ Moniter.Exit(obj);}
而[MethodImpl(MethodImplOptions.Synchronized)]标记为同步的方法会在编译时被lock(this)语句所环绕
所以我们只简单探讨Moniter.Enter的实现
(注:DotNet并非使用Win32API的CriticalSection来实现Moniter.Enter,不过他为托管对象提供了一个类似的结构叫做Syncblk)
每个对象实例头部都有一个指针,这个指针指向的结构,包含了对象的锁定信息,当第一次使用Moniter.Enter(obj)时,这个obj对象的锁定结构就会被初时化,第二次调用Moniter.Enter时,会检验这个object的锁定结构,如果锁没有被释放,则调用会阻塞

WaitHandle是Mutex,Semaphore,EventWaitHandler,AutoResetEvent,ManualResetEvent共同的祖先,他们包装了用于同步的内核对象,也就是说是这些内核对象的托管版本。
Mutex:类似于一个接力棒,拿到接力棒的线程才可以开始跑,当然接力棒一次只属于一个线程(Thread Affinity),如果这个线程不释放接力棒(Mutex.ReleaseMutex),那么没办法,其他所有需要接力棒运行的线程都知道能等着看热闹
Semaphore:类似于一个小桶,里面装了几个小球,凡是拿到小球就可以跑,比如指定小桶里最初有四个小球,那么开始的四个线程就可以直接拿着自己的小球开跑,但是第五个线程一看,小球被拿光了,就只好乖乖的等着有谁放一个小球到小桶里(Semophore.Release),他才能跑,但是这里的游戏规则比较特殊,我们可以随意向小桶里放入小球,也就是说我可以拿走一个小球,放回去俩,甚至一个都不拿,放回去5个,这样就有五个线程可以拿着这些小球运行了.我们可以规定小桶里有开始有几个小球(构造函数的第一个参数),也可以规定最多不能超过多少小球(构造函数的第二个参数)
ManualResetEvent,AutoResetEvent可以参考http://www.cnblogs.com/uubox/archive/2007/12/18/1003953.html
什么是用双锁实现Singleton,为什么要这样做,双锁检验是不安全的吗?
使用双锁检验技巧来实现单件,来自于Java社区
public static MySingleton Instance{get{ if(_instance!=null)}{ lock(_instance){ if(s_value==null){ _instance= new MySingleton(); } } }}} 这样做其实是为了提高效率,比起
public static MySingleton Instance{
get{
lock(_instance){
if(s_value==null){
_instance= new MySingleton();
}
}
前一种方法在instance创建的时候不需要用lock同步,从而增进了效率
在java中这种技巧被证明是不安全的详细见http://www.cs.umd.edu/~pugh/java/memoryModel/
但是在.Net下,这样的技巧是成立的,因为.Net使用了改进的内存模型
并且在.Net下,我们可以使用LazyInit来实现单件
private static readonly _instance=new MySingleton()
public static MySingleton Instance{
get{return _instance}
}
当第一此使用_instance时,CLR会生成这个对象,以后再访问这个字段,将会直接返回
互斥对象(Mutex),信号量(Semaphore),事件(Event)对象与lock语句的比较
首先这里所谓的事件对象不是System.Event,而是一种用于同步的内核机制
互斥对象和事件对象属于内核对象,利用内核对象进行线程同步,线程必须要在用户模式和内核模式间切换,所以一般效率很低,但利用互斥对象和事件对象这样的内核对象,可以在多个进程中的各个线程间进行同步。
lock或者Moniter是.net用一个特殊结构实现的,不涉及模式切换,也就是说工作在用户方式下,同步速度较快,但是不能跨进程同步
刚刚接触锁定的程序员往往觉得这个世界非常的危险,每个静态变量似乎都有可能产生竞争
首先锁定是解决竞争条件的,也就是多个线程同时访问某个资源,造成意想不到的结果,比如,最简单的情况,一个计数器,如果两个线程同时加一,后果就是损失了一个计数,但是频繁的锁定又可能带来性能上的消耗,还有最可怕的情况,死锁
到底什么情况下我们需要使用锁,什么情况下不用呢?
只有共享资源才需要锁定
首先,只有可以被多线程访问的共享资源才需要考虑锁定,比如静态变量,再比如某些缓存中的值,属于线程内部的变量不需要锁定
把锁定交给数据库
数据库除了存储数据之外,还有一个重要的用途就是同步,数据库本身用了一套复杂的机制来保证数据的可靠和一致性,这就为我们节省了很多的精力.保证了数据源头上的同步,我们多数的精力就可以集中在缓存等其他一些资源的同步访问上了
了解你的程序是怎么运行的
实际上在web开发中大多数逻辑都是在单个线程中展开的,无论asp.net还是php,一个请求都会在一个单独的线程中处理,其中的大部分变量都是属于这个线程的,根本没有必要考虑锁定,当然对于asp.net中的application对象中的数据,我们就要小心一些了
WinForm中凡是使用BeginInvoke和Invoke调用的方法也都不需要考虑同步,因为这用这两个方法调用的方法会在UI线程中执行,因此实际是同步的,所以如果调用的方法中存在某些静态变量,不需要考虑锁定
业务逻辑对事务和线程安全的要求
这条是最根本的东西,开发完全线程安全的程序是件很费时费力的事情,在电子商务等涉及金融系统的案例中,许多逻辑都必须严格的线程安全,所以我们不得不牺牲一些性能,和很多的开发时间来做这方面的工作,而一般的应用中,许多情况下虽然程序有竞争的危险,我们还是可以不使用锁定,比如有的时候计数器少一多一,对结果无伤大雅的情况下,我们就可以不用去管他
计算一下冲突的可能性
我以前曾经谈到过,架构不要过设计,其实在这里也一样,假如你的全局缓存里的某个值每天只有几百或者几千个访问,并且访问时间很短,并且分布均匀(实际上这是大多数的情况),那么冲突的可能性就非常的少,也许每500天才会出现一次或者更长,从7*24小时安全服务的角度来看,也完全符合要求,那么你还会为这样万分之一的可能性花80%的精力去设计吗?
请多使用lock,少用Mutex
如果你一定要使用锁定,请尽量不要使用内核模块的锁定机制,比如.net的Mutex,Semaphore,AutoResetEvent,ManuResetEvent,使用这样的机制涉及到了系统在用户模式和内核模式间的切换,所以性能差很多,但是他们的优点是可以跨进程同步线程,所以应该清楚的了解到他们的不同和适用范围
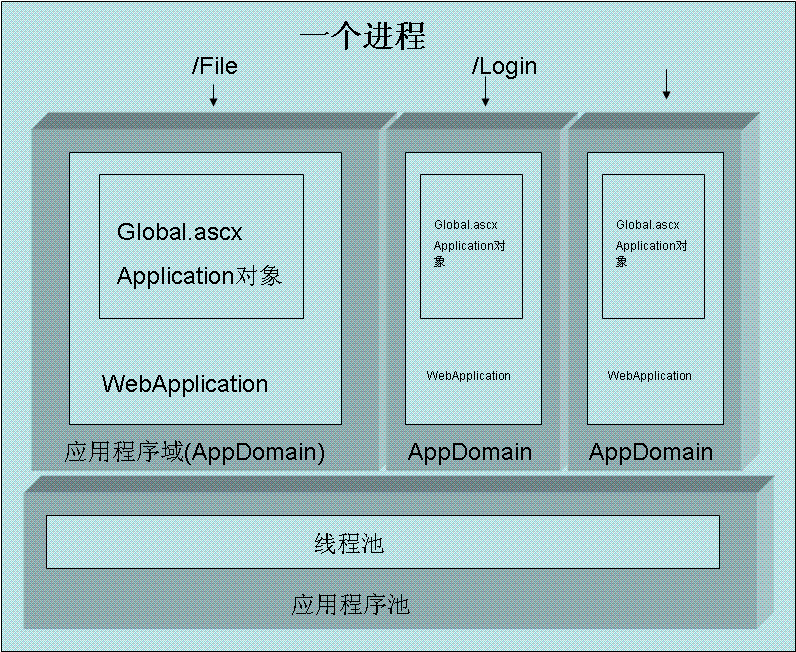
应用程序池,WebApplication,和线程池之间有什么关系
一个应用程序池是一个独立的进程,拥有一个线程池,应用程序池中可以有多个WebApplication,每个运行在一个单独的AppDomain中,这些WebApplication公用一个线程池
不同的AppDomain保证了每个WebApplication的静态变量不会互相干扰,不同的应用程序池保证了一个网站瘫痪,其他不同进程中的站点还能正常运行
下图说明了他们的关系
把Page的Async属性设置为true,就可以调用异步的方法,但是这样调用的效果可能并不如我们的相像,请参考Web中使用多线程来增强用户体验
推荐文章
http://alang79.blogdriver.com/alang79/456761.html
A low-level Look at the ASP.NET Architecture
参考资料
<Windows 核心编程>这本书里对内核对象的描述比较详尽
<.Net框架程序设计>和上面一本一样也是大牛Jeffery Richard的作品

 浙公网安备 33010602011771号
浙公网安备 33010602011771号