
Python学习笔记——基础篇【第五周】——算法(4*4的2维数组和冒泡排序)、时间复杂度
目录
1、算法基础
2、冒泡排序
3、时间复杂度
(1)时间频度
(2)时间复杂度
4、指数时间
5、常数时间
6、对数时间
7、线性时间
1、算法基础
要求:生成一个4*4的2维数组并将其顺时针旋转90度
#!_*_coding:utf-8_*_
array=[[col for col in range(5)] for row in range(5)] #初始化一个4*4数组
#array=[[col for col in 'abcde'] for row in range(5)]
for row in array: #旋转前先看看数组长啥样
print(row)
print('-------------')
for i,row in enumerate(array):
for index in range(i,len(row)):
tmp = array[index][i] #get each rows' data by column's index
array[index][i] = array[i][index] #
print tmp,array[i][index] #= tmp
array[i][index] = tmp
for r in array:print r
print('--one big loop --')
2、冒泡排序
将一个不规则的数组按从小到大的顺序进行排序
data = [10,4,33,21,54,3,8,11,5,22,2,1,17,13,6]
print("before sort:",data)
previous = data[0]
for j in range(len(data)):
tmp = 0
for i in range(len(data)-1):
if data[i] > data[i+1]:
tmp=data[i]
data[i] = data[i+1]
data[i+1] = tmp
print(data)
print("after sort:",data)
代码优化(提升性能)


1 count=0 2 data = [10,4,33,21,1,54,3,8,11,5,22,2,1,17,13,6] 3 #for index,i in enumerate(data[0:-1]): 4 print(len(data)) 5 for j in range(1,len(data)): 6 for i in range(len(data)-j): #J= 0 1 2 3 4 5 6 提升地方 7 if data[i]>data[i+1]: 8 tmp=data[i+1] 9 data[i+1]=data[i] #把10赋值给4 10 data[i]=tmp #把4赋值给10 11 count+=1 12 print(data) 13 print("count",count)
3、时间复杂度
(1)时间频度 一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测 试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法 中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
(1)时间频度 一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测 试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法 中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
(2)时间复杂度 在刚才提到的时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断
变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
4、指数时间
 而呈
而呈for (i=1; i<=n; i++) x++; for (i=1; i<=n; i++) for (j=1; j<=n; j++) x++;
第一个for循环的时间复杂度为Ο(n),第二个for循环的时间复杂度为Ο(n2),则整个算法的时间复杂度为Ο(n+n2)=Ο(n2)。
5、常数时间
若对于一个算法, 的上界与输入大小无关,则称其具有常数时间,记作
的上界与输入大小无关,则称其具有常数时间,记作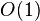 时间。一个例子是访问数组中的单个元素,因为访问它只需要一条指令。但是,找到无序数组中的最小元素则不是,因为这需要遍历所有元素来找出最小值。这是一项线性时间的操作,或称
时间。一个例子是访问数组中的单个元素,因为访问它只需要一条指令。但是,找到无序数组中的最小元素则不是,因为这需要遍历所有元素来找出最小值。这是一项线性时间的操作,或称 时间。但如果预先知道元素的数量并假设数量保持不变,则该操作也可被称为具有常数时间。
时间。但如果预先知道元素的数量并假设数量保持不变,则该操作也可被称为具有常数时间。
6、对数时间
若算法的T(n) = O(log n),则称其具有对数时间
对数时间的算法是非常有效的,因为每增加一个输入,其所需要的额外计算时间会变小。
递归地将字符串砍半并且输出是这个类别函数的一个简单例子。它需要O(log n)的时间因为每次输出之前我们都将字符串砍半。 这意味着,如果我们想增加输出的次数,我们需要将字符串长度加倍。
7、线性时间
如果一个算法的时间复杂度为O(n),则称这个算法具有线性时间,或O(n)时间。非正式地说,这意味着对于足够大的输入,运行时间增加的大小与输入成线性关系。例如,一个计算列表所有元素的和的程序,需要的时间与列表的长度成正比。
详细见Alex金角大王的文档
http://www.cnblogs.com/alex3714/articles/5143440.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号