

[图解tensorflow源码] TF系统概述篇
|
Rendezvous
|
1. 定义在core/framework/rendezvous.h 2. A Rendezvous is an abstraction for passing a Tensor from a producer to a consumer where the consumer may safely request the Tensor before or after it has been produced. A producer never blocks when using a Rendezvous. A consumer has the choice of making a blocking call or providing a callback: in either case, the consumer receives the Tensor as soon as it is available. (简而言之:Nonblocking send, blocking receive) 3. A Rendezvous key encodes a single <producer, consumer> pair. It is an error to call Send() or Recv*() more than once with the same key. 4. 在消息通信机制中,消息传递涉及到信箱容量问题。一个极端的情况是信箱容量为0,那么,当send在receive之前执行的话,则发送进程被阻塞,直到receive做完。 执行receive时信件可从发送者直接拷贝到接收者,不用任何中间缓冲。类似的,如果receive先被执行,接受者将被阻塞直到send发生。上述策略称为回合(rendezvous)原则。 5. tensorflow 的消息传递属于【发送不阻塞,接收阻塞】,实现场景有以下两种:
> LocalRendezvous (本地消息传递) > RpcRemoteRendezvous (分布式消息传递) > 另外一种特殊的通信形式是IntraProcessRendezvous (rendezvous_mgr.h),用于本地不同设备间通信。 Buffering of Tensor values is delegated to a "local" Rendezvous obtained from NewLocalRendezvous(). This class just adds functionality to coordinate multiple process-local devices. 6. 在Op Kernels中,有SendOp和RecvOp两个类(kernels/sendrecv_ops.h),与Rendezvous结合使用。 7. 【Each node:port specified in inputs is replaced with a feed node, which will pick up the provided input tensor from specially-initialized entries in a Rendezvous object used for the Run call】(from tensorflow white paper) |
|||
|
符号编程
|
前向计算图(显式) + 反向计算图(隐式)
 |
|||
|
Session
|
## 说明:A Session instance lets a caller drive a TensorFlow graph computation Extend函数,把额外的节点和边扩充到当前的运算流图中。 Run()是Session接口中另一个重要的函数。Run()函数的参数包括最终运算输出的变量名,及运算流图中涉及到的张量运算集。 为得到所期望的输出结果,运行过程中TensorFlow对所有节点进行传递闭包运算。并遵照节点间的运算依赖关系进行排序(具体细节将在3.1节中介绍)。 在大部分的TensorFlow应用中,一般构建一次Session,然后通过调用Run()对整个运算流图或是部分独立的子图进行多次运算。
表(1)TensorFlow核心库中的部分运算 |
|||
|
设备及内存分配
|
1. tensorflow设备内存管理模块实现了一个best-fit with coalescing (bfc)算法
> bfc选择合适内存块的原则是:找到chunk size大于等于x的最小的那个空闲内存块
2. 每个 worker 负责一个或者多个设备,每个设备有一个设备类型和一个名字。设备名字由识别设备类型的部分,在 worker 中的设备索引,以及在分布式设定中,worker 的 job和任务(或者 localhost 当设备是和进程在同一机器时)的标志构成。一些例子如/job:localhost/device:cpu:0 或者 /job:worker/task:17/device:gpu:3。 每个设备对象负责管理分配和解除分配设备内存,对在 TensorFlow 实现中的更高层请求任意 kernel 的执行调度管理。
3. tensorflow中,基类Device的子类有【GPUDevice, CPUDevice(即ThreadPoolDevice), GPUCompatibleCPUDevice】
|
|||
|
Graph
|
Graph describes a set of computations that are to be performed, as well as the dependencies between those computations. The basic model is a DAG (directed acyclic graph) with
* internal nodes representing computational operations to be performed;
* edges represent dependencies, indicating the target may only be executed once the source has completed;
> 正常边,正常边上可以流动数据,即正常边就是tensor
> 特殊边,又称作控制依赖,(control dependencies)
* predefined "source" (start) and "sink" (finish) nodes -- the source should be the only node that doesn't depend on anything, and the sink should be the only node that nothing depends on.
* graph优化:
|
|||
| Gradients |
MXNet设计笔记之:深度学习的编程模式比较: (Backprop和AutoDiff的案例分析)
|
|||
| 目录 |
core/
----BUILD bazel编译文件,相关编译函数定义在.bzl文件中
----client
----common_runtime
----debug
----distributed_runtime
----example
----framework
----graph DAG图相关
----kernels 核心Op,如【matmul, conv2d, argmax, batch_norm】等
----lib 基础公共库【core gif gtl hash histogram io jpeg monitoring png random strings wav】
> /lib/gtl: (google template library),包含array_slice,iterator_range, inlined_vector, map_util, std_util,等基础库
----ops 均为.cc文件,为基本op操作,如【array_ops, math_ops, image_ops, function_ops, random_ops, io_ops】
流运算【control_flow_ops, data_flow_ops】
以及定义了op梯度计算方式:【array_grad, math_grad, functional_grad, nn_grad, random_grad】
----platform 平台相关文件,如设备内存分配
----protobuf 均为.proto文件,用于数据传输时的结构序列化
----public 公共头文件,用于外部接口调用的API定义,主要是[session.h, tensor_c_api.h]
----user_ops 用户自定义op
----util
stream_executor/ 参考:https://github.com/henline/streamexecutordoc
----cuda/ cuda函数封装。(CUDA-specific support for BLAS functionality)
StreamExecutor is currently used as the runtime for the vast majority of Google's internal GPGPU applications,
and a snapshot of it is included in the open-source TensorFlow project, where it serves as the GPGPU runtime. (Google Stream Executor team)
|
|||
| Register |
ops_kernel注册: REGISTER_KERNEL_BUILDER("MatMul", MatMulOp); (kernels/matmul_ops.cc)
ops_grad 注册: REGISTER_OP_GRADIENT("MatMul", MatMulGrad); (ops/math_grad.cc)
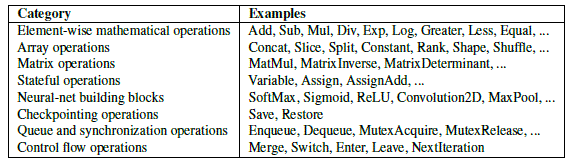
ops 注册:
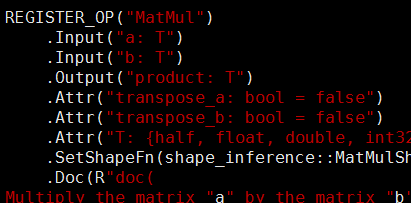 (ops/math_ops.cc) (ops/math_ops.cc) |



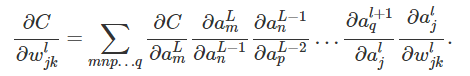


 浙公网安备 33010602011771号
浙公网安备 33010602011771号