
PYTHON黑帽编程 4.1 SNIFFER(嗅探器)之数据捕获(下)
上一节(《4.1 SNIFFER(嗅探器)之数据捕获(上)》)中, 我们讲解了通过Raw Socket的方式来编写Sniffer的基本方法。 本节我们继续来编写Sniffer,只不过使用现成的库,可以大大 缩短我们的工作时间和编程难度,和上一篇文章对比就知道了。
4.1.6 使用Pypcap编写Sniffer
如果在你的电脑上找不到pypcap模块,需要手动进行安装一下。在Kali中使用下面的命令进行安装:
apt-get install libpcap-dev
pip install pypcap
安装过程如图1,图2:
图1
图2
调用pcap模块的pcap方法可以返回一个用来捕获数据包的pcap对象。
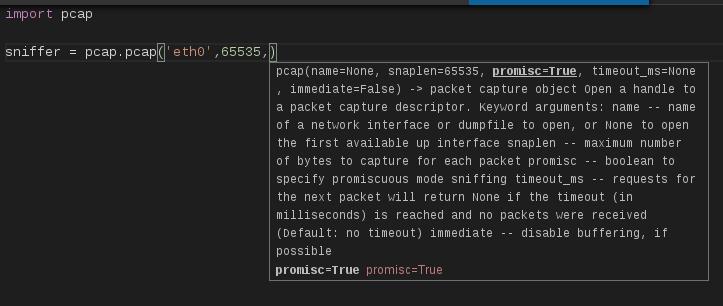
图3
如图3,pcap方法接收5个参数:
- name,监听的网卡名称。
- snaplen,捕获的每个数据包的最大长度。
- promisc,是否开启混杂模式
- timeout_ms,接收数据包的超时时间
- immediate,立即模式,如果启用则不会缓存数据包
每一个参数都有默认值,如果有多个网卡的话,需要设置第一个参数的值,传入网卡名称。下面 我们定义一个方法,返回一个pcap对象。
import pcap def getSniffer(ifName=None,filter=''): pc = pcap.pcap('eth0',65535,True) if(filter != ''): pc.setfilter(filter) return pc
在上面的代码中,我们创建了一个pcap对象,然后调用了setfilter方法,设置数据包过滤器。 pcap使用的过滤器为符合BPF格式的数据包过滤字符串。
什么是BPF
伯克利包过滤(Berkeley Packet Filter,BPF)语言。让你能够通过比较第2、3、4层协议中各个数据字段值的方法对流量进行过滤。BPF中内置了一些“基元”来指代一些常用的协议字段。可以用“host”、"prot"之类的基元写出非常简洁的BPF过滤规则,也可以检测位于指定偏移量上的字段(甚至可以是一个位)的值。BPF过滤器也可以由详尽的条件链和嵌套的逻辑“与”、“或”操作组成。
BPF基元
现在,构造一个BPF过滤器的最简单的办法就是使用BPF“基元”来指定协议、协议元素或者其他抓包规则。基元通常是由一个id(名称或序号)再加上一个或多个限定符组成的。 \
- type限定符:规定了id名或id序号指的是哪种类型的数据,可能的type有host、net、prot和protrange
- dir限定符:规定了流量是从id流进还是流出的(或两种兼有)。可能的dir有src、dst、ser or dst、src and dst、addr1、addr2、addr3和addr4
- Proto限定符:规定了所匹配的协议。可能的proto有:ether、fddi、tr、wlan、ip、ip6、arp、rarp、decnet、tcp和udp \
最常用的BPF基元要数“host id”,它是用来过滤与某台主机相关的流量的,其中id一栏中应该填上一个地址或主机名。输入“tcp and host 10.10.10.10”这样的过滤规则,将值获取流入/流出得做10.10.10.10的TCP流量,其他的所有帧都会被过滤掉。 \ 举例说明:\ 假设我们现在希望仅仅获取IP地址为192.168.0.1的计算机与除IP地址10.1.1.1之外的其他所有计算机在138、139和445端口上发送的所有通信,下面这个BPF过滤规则就能完成上述任务:
'host 192.168.0.1 and not host 10.1.1.1 and (port 138 or port 139 or port 445)'常用的BPF基元有:
- host id , dst host id , src host id
- net id , dst net id , src net id
- ether host id , ether dst host id , ether src host id
- port id , dst port id , src port id
- gateway id , ip proto id , ether proto id
- tcp, udp, icmp, arp
- vlan id
根据字节的值过滤数据包
BPF语言也可以用来检查帧内任意一个单字节字段(或多字节字段)的值是不是规定值。下面是一些例子:
ip[8]<64
这个过滤规则规定要抓取的是:所有自ip头偏移8个字节的那个单字节字段的值小于64的IP包。被检查的这个字段表示的是“包的存活时间”或称“TTL”。大多数Windows系统中TTL的默认值是128,所以这个过滤规则将丢弃局域网中所有来自Windows系统的流量,只获取所有来自Linux系统的流量(因为在LInux系统中TTL的默认起始值是64)
ip[9]!=1
这一过滤规则规定要抓取的是所有IP头部偏移9个字节的那个单字节字段的值不等于“1”的帧。因为IP头部偏移9个字节的这个字段表示的是嵌入协议,如果等于“1”则表示“ICMP”协议,所以这个过滤规则将抓取除ICMP包之外的所有流量。这一表达式也等价于基元“not icmp”。
icmp[0] = 3 and icmp[1] = 0
这个语句规定要抓取的是:所有ICMP头部偏移0个字节的那个单字节字段等于3,且偏移1个字段的单字节字段等于0的ICMP数据包。换而言之,这一过滤规则将只抓取ICMPtype为3,code为0的“网络不可达”消息。
tcp[0:2] = 31337
这个语句检查了一个多字节字段,它检查的是:TCP头部偏移0个字节起的一个多字节字段(2个字节),该字段表示的是TCP源端口。所以这个表达式就等价于BPF基元“src prot 31337”
ip[12:4] = 0xC0A80101
我们看到的这是一个4字节的比较,它检查的是IP头部偏移12个字节起的4个字节里存放的数据——源IP地址。注意这个表达式里使用了十六进制表示法。转换成十进制数字,它就是192.168.1.1(0xC0=192,0xA8=168,0x01=1)。所以这一过滤规则将捕获所有源IP地址为192.168.1.1的流量。
根据位(bit)的值过滤数据包
BPF语言还提供了一种方法让我们能检查更小的字段或精度更高的偏移量。具体做法是:我们先引用相关的字节,或多个字节,然后再用“位掩码”逐位地把我们需要检查的位分离出来。
假设要过滤所有IP头部中可选字段被启用的包(就是IP头的长度大于20个字节的包)。IP头部的低半个字节表示的是IP头的长度,以“word”(字)为单位(一个word等于4个字节)。我们只需要找出这半个字节的值大于5(5word*4个字节/word=20个字节)的包就等于找出所有IP头部大于20个字节的包了。具体做法是用位掩码“00001111”(或者0x0F)创建一个BPF过滤规>>>则,通过逻辑“与”运算提取目标值。
ip[0] & 0x0F > 0x05 与之类似,如果我们要找出所有“不分片”标志位(位于IP头部偏移6个字节位置上的一位二进制位)被置1的IP包,我们亦可用二进制位掩码“01000000”(0x40)来表示我们只关心IP头部偏移6个字节位置上那个第二最高位的bit值是是不是1。
在构造位掩码是,如果对应的那一位是我们需要检查的,那就用1表示,否则就用0表示。
ip[6] & 0x40 != 0
接下来我们尝试调用getSniffer方法。
sniffer = getSniffer('eth0','tcp port 80') for ptime,data in sniffer: print ptime,data
这段代码中,调用getSniffer方法得到pcap对象,然后我们循环读取监听到的数据。 这里我在虚拟机运行这段代码,然后在从宿主机中访问网页,可以看到打印的数据,证明 监听成功。
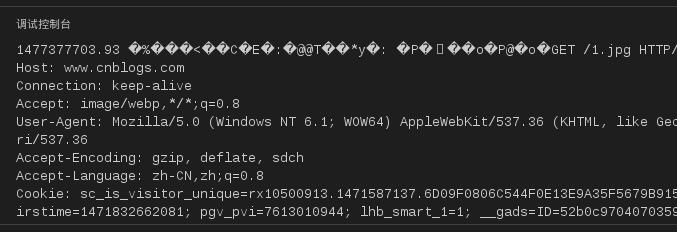
图4
4.1.7 使用Scapy编写Sniffer
又到了强大的Scapy出场的时候了,通过前面章节的介绍,相信大家已经对它不陌生了,在 底层网络编程方面,Scapy机会是万能的存在。下面我们看看使用Scapy编写Sniffer的代码:
from scapy.all import * def packetHandler(pkt): src=pkt[IP].src srcPort=pkt[IP].dst if src=='192.168.1.20': print 'ok' sniff(filter='tcp and port 80',prn=packetHandler,iface='eth0')
先看上面这段简单的代码,最下面一行是调用的scapy的sniff方法,该方法就是用来监听 数据的,我们可以在scapy的交互窗口中使用help来查看sniff方法的说明。
sniff(count=0, store=1, offline=None, prn=None, lfilter=None, L2socket=None, timeout=None, opened_socket=None, stop_filter=None, *arg, **karg) Sniff packets sniff([count=0,] [prn=None,] [store=1,] [offline=None,] [lfilter=None,] + L2ListenSocket args) -> list of packets count: number of packets to capture. 0 means infinity store: wether to store sniffed packets or discard them prn: function to apply to each packet. If something is returned, it is displayed. Ex: ex: prn = lambda x: x.summary() lfilter: python function applied to each packet to determine if further action may be done ex: lfilter = lambda x: x.haslayer(Padding) offline: pcap file to read packets from, instead of sniffing them timeout: stop sniffing after a given time (default: None) L2socket: use the provided L2socket opened_socket: provide an object ready to use .recv() on stop_filter: python function applied to each packet to determine if we have to stop the capture after this packet ex: stop_filter = lambda x: x.haslayer(TCP)
参数说明已经很清楚了,过滤数据包可以使用filter,lfilter,stop_filter,filter是过滤表达式, lfilter 和stopfilter 是python函数。前两者作用一样,用来过滤我们需要的数据包,或者 是一个终止监听的判断条件。 prn是数据包的处理函数,我们要在此做数据包的解析,分析等工作。 数据包的解析,我们会在下一节做详细的讲解,大家在练习的时候一定要结合以太网数据包的格式来 调试分析数据包对象,相互加深,会有事半功倍的效果。
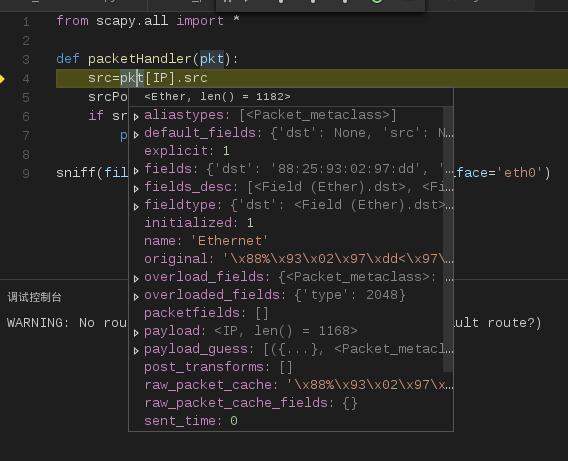
图5
上面代码的运行结果如下:
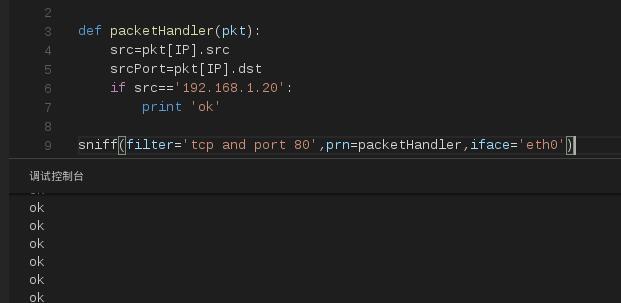
图6
4.1.8 使用Pcapy进行数据捕获
在网络数据分析的工具中,tcpdump绝对是大名鼎鼎,tcpdump底层是libpcap库,由C语言编写。 Pcapy模块则是基于libpcap的Python接口。pcapy在github上的项目地址为: https://github.com/CoreSecurity/pcapy。
下面我们来看看如何使用pcapy实现数据包的捕获。
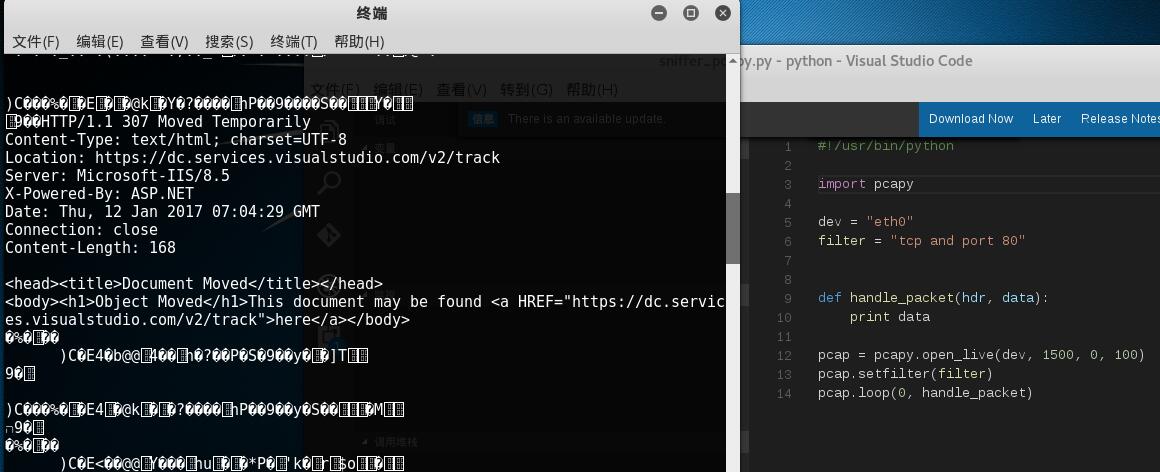
1 #!/usr/bin/python 2 3 import pcapy 4 5 dev = "eth0" 6 filter = "tcp and port 80" 7 8 9 def handle_packet(hdr, data): 10 print data 11 12 pcap = pcapy.open_live(dev, 1500, 0, 100) 13 pcap.setfilter(filter) 14 pcap.loop(0, handle_packet)
上面的代码很简单,首先导入pcapy模块,之后定义了两个变量,dev为要监听的网卡, filter是BPF 格式的过滤表达式,这里我们只捕获http协议的数据。 handle_packet方法是用来处理捕获的数据包的逻辑, 这里我们只是简单的打印捕获的数据,在之后的文章中,我们会继续扩展该方法,用来 做数据解析。
最后三行代码是我们使用pcapy进行数据捕获的具体应用。
pcap = pcapy.open_live(dev, 1500, 0, 100)
open_live方法第一个参数是要打开的设备,第二个参数是捕获数据包的大小, 第三个参数是否打开混杂模式,第四个参数是等待数据包的延迟时间,该方法返回一个 pcapy对象。
pcap.setfilter(filter)
调用setfilter方法,设置过滤器。
pcap.loop(0, handle_packet)
调用loop方法,开始执行数据包捕获,该方法的第一个参数为执行次数,小于或等于0为不限制, 第二个参数为数据包处理函数。
好了,就补充说明这么多,运行结果如下:
4.1.9 小结
本节主要讲了如何利用Pypcap、Scapy和Pcapy来编写Sniffer,完成了监听数据的功能,当然这只是 完成了前置功能,嗅探器的核心是数据分析。下一节我将从协议分析、数据内容分析、数据汇总 三个方面为大家讲解。请关注《Python 黑帽编程4.2 Sniffer之数据分析》。
第4.2节《4.1 Sniffer(嗅探器)之数据分析》已经在微信订阅号抢先发布,进入订阅号(二维码在下方),从菜单“精华”—>”Python黑帽编程”进入即可。
查看完整系列教程,请关注我的微信订阅号(xuanhun521,下方二维码),回复“python”。问题讨论请加qq群:Hacking (1群):303242737 Hacking (2群):147098303。

玄魂工作室-专注原创
作者:玄魂
出处:http://www.cnblogs.com/xuanhun/
原文链接:http://www.cnblogs.com/xuanhun/
更多内容,请访问我的个人站点 对编程,安全感兴趣的,加qq群:hacking-1群:303242737,hacking-2群:147098303,nw.js,electron交流群 313717550。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
关注我:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号