

Spark踩坑记——初试
目录
Spark简介
整体认识
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架。最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一。
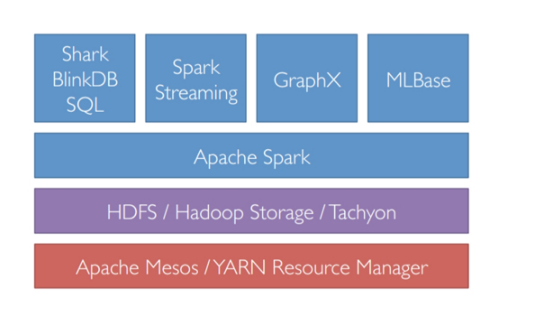
Spark在整个大数据系统中处于中间偏上层的地位,如下图,对hadoop起到了补充作用:
基本概念
Fork/Join框架是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
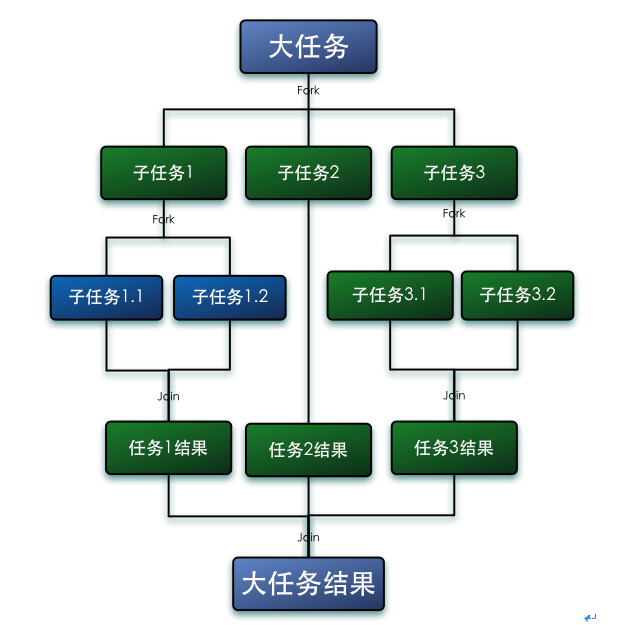
- 第一步分割任务。首先我们需要有一个fork类来把大任务分割成子任务,有可能子任务还是很大,所以还需要不停的分割,直到分割出的子任务足够小。
- 第二步执行任务并合并结果。分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。
具体可参考Fork/Join
核心概念
- RDD(Resilient Distributed Dataset) 弹性分布数据集介绍
弹性分布式数据集(基于Matei的研究论文)或RDD是Spark框架中的核心概念。可以将RDD视作数据库中的一张表。其中可以保存任何类型的数据。Spark将数据存储在不同分区上的RDD之中。
RDD可以帮助重新安排计算并优化数据处理过程。
此外,它还具有容错性,因为RDD知道如何重新创建和重新计算数据集。
RDD是不可变的。你可以用变换(Transformation)修改RDD,但是这个变换所返回的是一个全新的RDD,而原有的RDD仍然保持不变。
RDD支持两种类型的操作:- 变换(Transformation)
- 行动(Action)
变换:变换的返回值是一个新的RDD集合,而不是单个值。调用一个变换方法,不会有任何求值计算,它只获取一个RDD作为参数,然后返回一个新的RDD。变换函数包括:map,filter,flatMap,groupByKey,reduceByKey,aggregateByKey,pipe和coalesce。
行动:行动操作计算并返回一个新的值。当在一个RDD对象上调用行动函数时,会在这一时刻计算全部的数据处理查询并返回结果值。
行动操作包括:reduce,collect,count,first,take,countByKey以及foreach。
- 共享变量(Shared varialbes)
- 广播变量(Broadcast variables)
- 累加器(Accumulators)
- Master/Worker/Driver/Executor
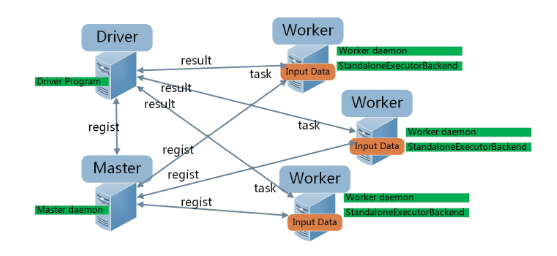
- Master:1. 接受Worker的注册请求,统筹记录所有Worker的CPU、Memory等资源,并跟踪Worker结点的活动状态;2. 接受Driver中App的注册请求(这个请求由Driver端的Client发出),为App在Worker上分配CPU、Memory资源,生成后台Executor进程;之后跟踪Executor和App的活动状态。
- Worker:负责接收Master的指示,为App创建Executor进程。Worker在Master和Executor之间起着桥梁作用,实际不会参与计算工作。
- Driver:负责用户侧逻辑处理。
- Executor:负责计算,接受并执行由App划分的Task任务,并将结果缓存在本地内存或磁盘。
Spark部署
关于Spark的部署网上相关资料很多,这里进行归纳整理
部署环境
- Ubuntu 14.04LTS
- Hadoop:2.7.0
- Java JDK 1.8
- Spark 1.6.1
- Scala 2.11.8
Hadoop安装
由于Spark会利用HDFS和YARN,所以需要提前配置Hadoop,配置教程可以参考:
Setting up a Apache Hadoop 2.7 single node on Ubuntu 14.04
Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
Spark安装
在安装好Hadoop的基础上,搭建Spark,配置教程参考:
Spark快速入门指南 – Spark安装与基础使用
scala安装
Scala作为编写Spark的源生语言,更新速度和支持情况肯定是最好的,而另一方面Scala本身语言中对于面向对象和函数式编程两种思想的糅合,使得该语言具有很多炫酷的语法糖,所以在使用Spark的过程中我采用了Scala语言进行开发。
- Scala最终编译成字节码需要运行在JVM中,所以需要依托于jdk,需要部署jdk
- Eclipse作为一款开发Java的IDE神器,在Scala中当然也可以使用,有两种方式:
- Eclipse->Help->Install New Software安装Scala Plugins
- 下载官网已经提供的集成好的Scala IDE
- 基于以上两步已经可以进行Scala开发,需要用到Scala自带的SBT编译的同学可以装下Scala官网下载地址,本人一直使用Maven进行包管理就延续Maven的使用
简单示例:WordCount(Spark Scala)
- 开发IDE:Eclipse Scala
- 包管理:Maven
- 开发语言:Scala
创建Maven项目
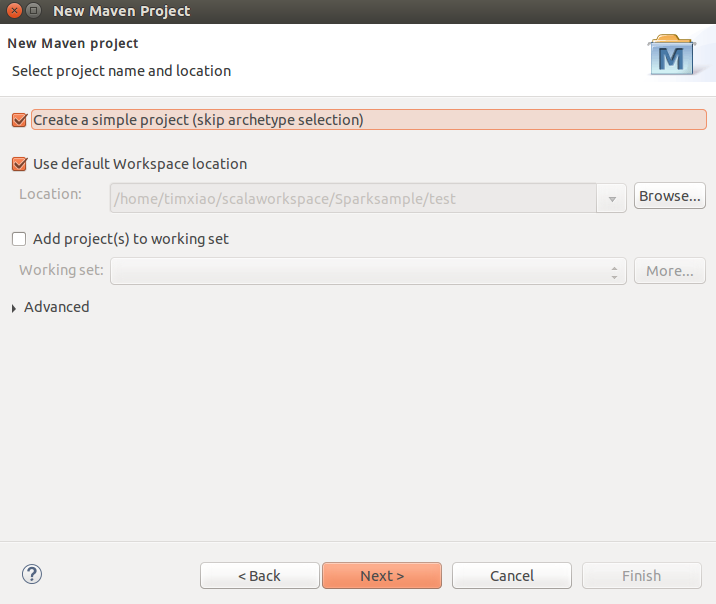
跳过archetype项目模板的选择- 下载模板pom.xml
- 对maven项目添加Scala属性:
Right click on project -> configure - > Add Scala Nature. - 调整下Scala编译器的版本,与Spark版本对应:
Right click on project- > Go to properties -> Scala compiler -> update Scala installation version to 2.10.5 - 从Build Path中移除Scala Library(由于在Maven中添加了Spark Core的依赖项,而Spark是依赖于Scala的,Scala的jar包已经存在于Maven Dependency中):
Right click on the project -> Build path -> Configure build path and remove Scala Library Container. - 添加package包com.spark.sample
- 创建Object WordCount和SimpleCount,用来作为Spark的两个简单示例
Spark Sample
源码
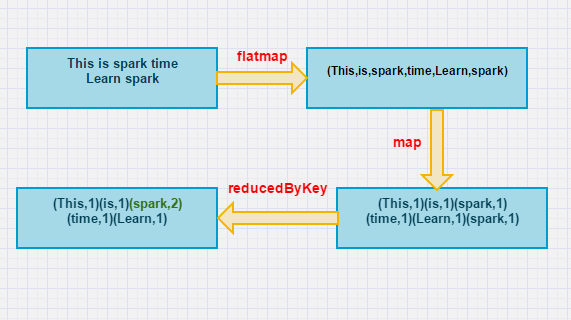
原理如下图:
参考文献:
- http://km.oa.com/group/2430/articles/show/181711?kmref=search&from_page=1&no=1&is_from_iso=1
- http://spark.apache.org/docs/latest/programming-guide.html#resilient-distributed-datasets-rdds
- http://www.infoq.com/cn/articles/apache-spark-introduction?utm_source=infoq_en&utm_medium=link_on_en_item&utm_campaign=item_in_other_langs
- http://www.infoq.com/cn/articles/apache-spark-sql
- http://www.infoq.com/cn/articles/apache-spark-streaming
- http://www.devinline.com/2016/01/apache-spark-setup-in-eclipse-scala-ide.html
- https://databricks.gitbooks.io/databricks-spark-reference-applications/content/
- http://wuchong.me/blog/2015/04/06/spark-on-hbase-new-api/
- http://colobu.com/2015/01/05/kafka-spark-streaming-integration-summary/
- http://www.devinline.com/2016/01/apache-spark-setup-in-eclipse-scala-ide.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号