
一.hadoop入门须知
目录:
3.hadoop mapreduce之WordCount例子
1)基本介绍
- hadoop是什么?
Hadoop是一个开源的框架,可编写和运行分不是应用处理大规模数据,是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。Hadoop=HDFS(文件系统,数据存储技术相关)+ Mapreduce(数据处理),Hadoop的数据来源可以是任何形式,在处理半结构化和非结构化数据上与关系型数据库相比有更好的性能,具有更灵活的处理能力,不管任何数据形式最终会转化为key/value,key/value是基本数据单元。用函数式变成Mapreduce代替SQL,SQL是查询语句,而Mapreduce则是使用脚本和代码,而对于适用于关系型数据库,习惯SQL的Hadoop有开源工具hive代替。 - hadoop能做什么?
hadoop擅长日志分析,facebook就用Hive来进行日志分析,2009年时facebook就有非编程人员的30%的人使用HiveQL进行数据分析;淘宝搜索中的自定义筛选也使用的Hive;利用Pig还可以做高级的数据处理,包括Twitter、LinkedIn 上用于发现您可能认识的人,可以实现类似Amazon.com的协同过滤的推荐效果。淘宝的商品推荐也是!在Yahoo!的40%的Hadoop作业是用pig运行的,包括垃圾邮件的识别和过滤,还有用户特征建模。(2012年8月25新更新,天猫的推荐系统是hive,少量尝试mahout!)
- 日志处理
- 用户细分特征建模
- 个性化广告推荐
- 智能仪器推荐
2)名词解释:
| Hadoop | 中文 | 相关解释 | |
| NameNode | Master | 主控服务器 | 整个文件系统的大脑,它提供整个文件系统的目录信息,并且管理各个数据服务器 |
| Secondary | 无 | 备份主控服务器 | 备用的主控服务器,在身后默默的拉取着主控服务器的日志,等待主控服务器牺牲后转正。 |
| DataNode | Chunk | 数据服务器 | 分布式文件系统中的每一个文件,都被切分陈若干数据块,每一个数据块都被存储在不同的服务器上,这些服务器称之为数据服务器。 |
| Block | Chunk | 数据块 | 每个文件都会被切分陈若干块,每一块都有连续的一段文件内容,是存储的基本单位,在这里统一称作数据块。 |
| Packet | 无 | 数据包 | 客户端写文件的时候,不是一个字节一个字节写入文件系统的,而是累计到一定数量后,往文件系统中写入,每发送一次的数据,都称为一个数据包。 |
| Chunk | 无 | 传输块 | 将数据切成更小的块,每一个块配上一个奇偶校检码,这样的块,就是传输块。 |
| JobTracker | Master | 作业服务器 | 用户提交作业的服务器,同时,它还负责各个作业任务分配,管理所有的任务服务器 |
| TaskTracker | Worker | 任务服务器 | 负责执行具体的任务 |
| Job | Job | 作业 | 用户的每一个计算请求,称为一个作业 |
| Task | Task | 任务 | 每一个作业,都需要拆分开了,然后交由多个服务器来完成,拆分出来的执行单元,就称之为任务 |
| Speculative Task | Backup Task | 备份任务 | 每一个任务,都有可能执行失败或者缓慢,为了降低为此付出的代价,系统会未雨绸缪的实现在另外的任务服务器上执行同一个任务,这就是备份任务 |
| Slot | 无 | 插槽 | 一个任务服务器可能有多个插槽,每个插槽负责执行一个具体的任务 |
1、Hadoop Common :Hadoop体系最底层的一个模块,为Hadoop各子项目提供各种工具,如:配置文件和日志操作等。
2、HDFS:分布式文件系统,提供高吞吐量的应用程序数据访问,对外部客户机而言,HDFS 就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。但是 HDFS 的架构是基于一组特定的节点构建的(参见图 1),这是由它自身的特点决定的。这些节点包括 NameNode(仅一个),它在 HDFS 内部提供元数据服务;DataNode,它为 HDFS 提供存储块。由于仅存在一个 NameNode,因此这是 HDFS 的一个缺点(单点失败)。
3. 存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小(通常为 64MB)和复制的块数量在创建文件时由客户机决定。NameNode 可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
4、Avro :doug cutting主持的RPC项目,主要负责数据的序列化。有点类似Google的protobuf和Facebook的thrift。avro用来做以后hadoop的RPC,使hadoop的RPC模块通信速度更快、数据结构更紧凑。
5、Hive :类似CloudBase,也是基于hadoop分布式计算平台上的提供data warehouse的sql功能的一套软件。使得存储在hadoop里面的海量数据的汇总,即席查询简单化。hive提供了一套QL的查询语言,以sql为基础,使用起来很方便。
6、HBase :基于Hadoop Distributed File System,是一个开源的,基于列存储模型的可扩展的分布式数据库,HBase是一个面向列的数据库,支持大型表的存储结构化数据。
7、Pig :是一个并行计算的高级的数据流语言和执行框架 ,SQL-like语言,是在MapReduce上构建的一种高级查询语言,把一些运算编译进MapReduce模型的Map和Reduce中,并且用户可以定义自己的功能。
8、ZooKeeper :Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
9、Chukwa :一个管理大型分布式系统的数据采集系统 由yahoo贡献。
10、Cassandra :无单点故障的可扩展的多主数据库
11、Mahout :一个可扩展的机器学习和数据挖掘库
Hive和Hbase是两种基于Hadoop的不同技术--Hive是一种类SQL的引擎,并且运行MapReduce任务,Hbase是一种在Hadoop之上的NoSQL 的Key/vale数据库。当然,这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase可以用来进行实时查询,数据也可以从Hive写到Hbase,设置再从Hbase写回Hive
3)必需条件
JDK1.6以上
SSH无密码访问(hadoop的使用,必须配置成ssh无密码访问):
解决方法:
root用户下:
//移除密钥文件 $ cd ~/.ssh $ rm -rf *.pub $ rm -rf authorized_keys //生成密钥文件 $ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
ssh localhost后,然后可以无密码登录了。 (使用cp id_dsa.pub authorized_keys方式也行,cp id_dsa.pub authorized_keys)
顺便贴个图:hadoop生态圈层次图
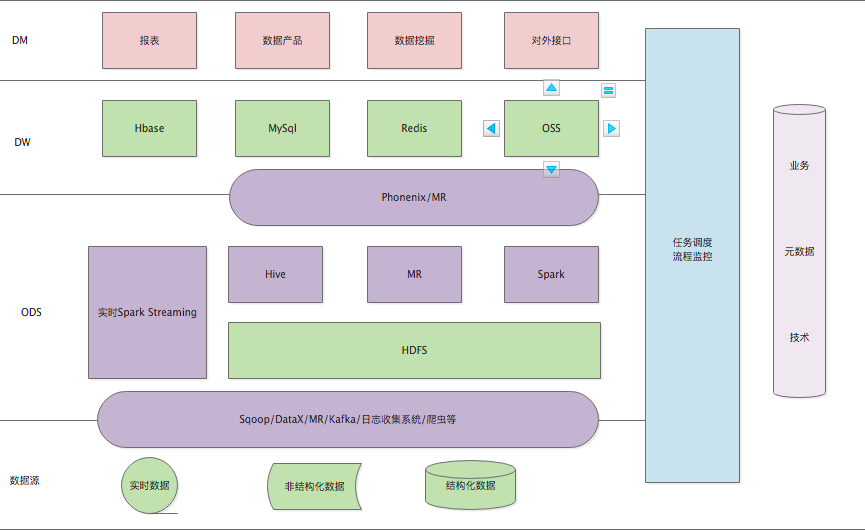
ods:操作型数据存储/运营数据仓储
dw:数据仓库
dm:数据模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号