




SQL Server 与MySQL中排序规则与字符集相关知识的一点总结
字符集&&排序规则
字符集是针对不同语言的字符编码的集合,比如UTF-8字符集,GBK字符集,GB2312字符集等等,不同的字符集使用不同的规则给字符进行编码
排序规则则是在特定字符集的基础上特定的字符排序方式,排序规则是基于字符集的,是对字符集在排序方式维度上的一个划分。
排序规则是依赖于字符集的,一种字符集可以有多种排序规则,但是一种排序规则只能基于某一种字符集的
比如中文字符集,也即汉字,可以按照“拼音排序”、“按姓氏笔划排序”等等。
而对于英语,就没有“拼音”和“姓氏笔画”,但是可以分为区分大小写、不区分大小写等等
而其他语言下面也有自己特定的排序规则。
在SQL Server中,任何一种字符集的数据库,都能存储任何一种语言的字符。
并不是说拉丁(Latin)字符集的数据就存储不了中文,中文(Chinese)字符集的数据库就存储不了蒙古语(只要操作系统本身支持)
sqlserver中,不管哪种字符集(实际上是排序规则)的数据库(或者字段),都是可以使用nvarchar(或者nchar),而nvarchar(或者nchar)是可以存储任意非Unicode字符的
至于排序规则,那是根据不同的字符集所支持的不同的排序规则人为定义的。
SQL Server中的字符集和排序规则
排序规则只不过是指定了存储的数据的排序(比较)规则而已,换句话说就是,排序规则中已经包含了字符集的信息。
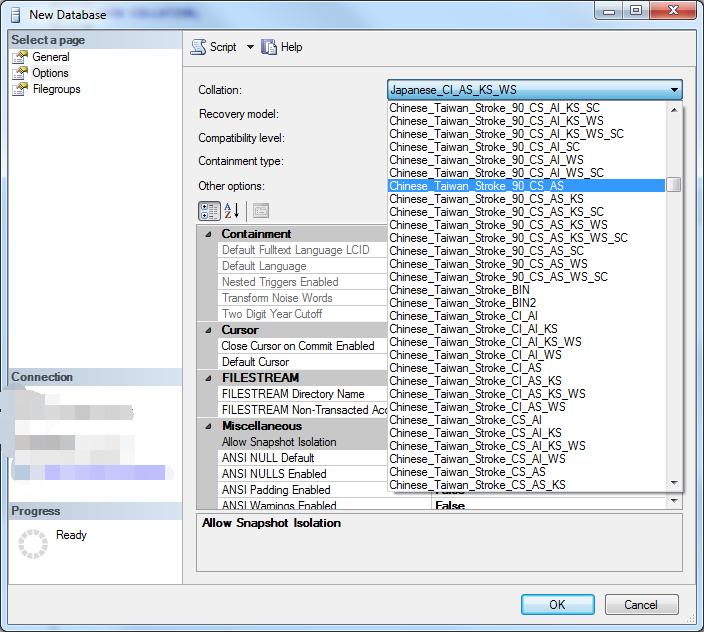
因此在sqlserver中 ,不需要关心字符集,只需要关心排序规则,sqlserver中在创建只能指定排序规则(不能直接指定字符集),
如截图,只能指定collation,也就是字符集
在MySQL中的字符集和排序规则
上面说了,排序规则是依赖于字符集的,一种字符集可以有多种排序规则,但是一种排序规则只能基于某一种字符集的。
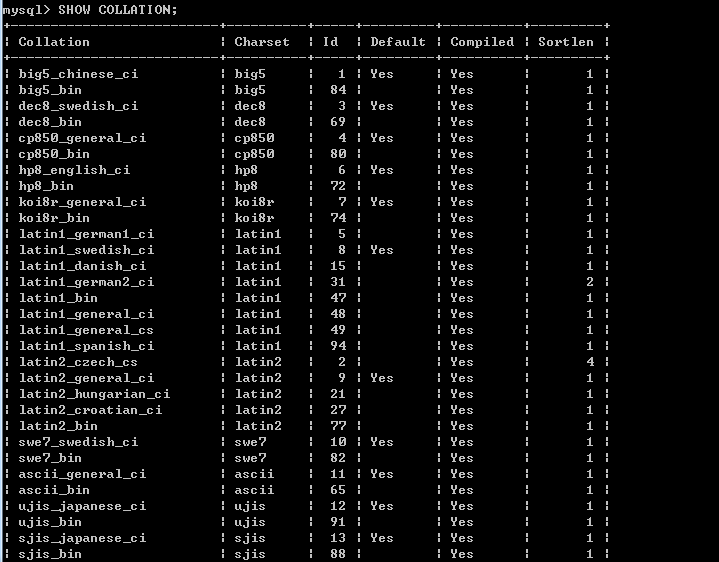
如下是MySQL中排序规则和字符集的对应关系。
MySQL的建库语法比较扯,可以指定字符集和排序规则,
如果指定的排序规则在字符集的下面,则是没有问题的,如果指定的排序规则不在字符集下面,则会报错。
比如下面这一句,排序规则utf8_bin是属于字符集utf8下面的一种排序规则,这个语句执行是没有问题的
create database test_database2 charset utf8 collate utf8_bin;
再比如下面这一句,排序规则latin1_bin不是属于字符集utf8下面的一种排序规则,这个语句执行是会报错的
create database test_database2 charset utf8 collate latin1_bin;

以上是字符集和排序规则在sqlserver和MySQL中的一些基本应用,再说说常用的排序规则的区别
***_genera_ci & ***_genera_cs & ***_bin 常见排序规则的特点
以上是某种字符集下常用的三种排序规则,下面以常见的utf8为例说明
utf8_genera_ci不区分大小写,ci为case insensitive的缩写,即大小写不敏感,
utf8_general_cs区分大小写,cs为case sensitive的缩写,即大小写敏感,但是目前MySQL版本中已经不支持类似于***_genera_cs的排序规则,直接使用utf8_bin替代。
utf8_bin将字符串中的每一个字符用二进制数据存储,区分大小写。
那么,同样是区分大小写,utf8_general_cs和utf8_bin有什么区别?
cs为case sensitive的缩写,即大小写敏感;bin的意思是二进制,也就是二进制编码比较。
utf8_general_cs排序规则下,即便是区分了大小写,但是某些西欧的字符和拉丁字符是不区分的,比如ä=a,但是有时并不需要ä=a,所以才有utf8_bin
utf8_bin的特点在于使用字符的二进制的编码进行运算,任何不同的二进制编码都是不同的,因此在utf8_bin排序规则下:ä<>a
在utf8_genera_ci的情况下A=a,ä=a
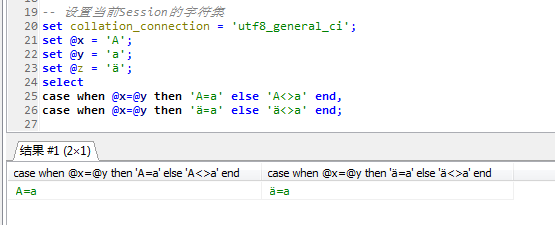
在utf8_bin排序规则下,A<>a,ä<>a

所以要想区分大小写,有没有特殊需求,就直接使用utf8_bin(实际上***_general_cs在MySQL中本身就不支持,在SQL Server中支持)
以上字符集的特点以及使用情况在SQL Server中表现为类似。
以上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号