托管代码和非托管代码效率的对比。
2006-12-07 10:14 无常 阅读(26234) 评论(76) 收藏 举报一直以来只知道托管代码的效率要比非托管代码低,至于低多少也没有可参考的数据。今天在csdn看到的英特尔多核平台编程优化大赛的广告,把里面的代码下载回来,分别用非托管c/托管cpp/c#做了个简略的性能测试,不比不知道,一比吓了一跳。且看数据说话。
第一步:原始代码如:
 /* compute the potential energy of a collection of */
/* compute the potential energy of a collection of */ /* particles interacting via pairwise potential */
/* particles interacting via pairwise potential */ #include <stdio.h>#include <stdlib.h>#include <math.h>#include <windows.h>#include <time.h> #define NPARTS 1000#define NITER 201#define DIMS 3 int rand( void );int computePot(void);void initPositions(void);void updatePositions(void); double r[DIMS][NPARTS];double pot;double distx, disty, distz, dist;int main() {
#include <stdio.h>#include <stdlib.h>#include <math.h>#include <windows.h>#include <time.h> #define NPARTS 1000#define NITER 201#define DIMS 3 int rand( void );int computePot(void);void initPositions(void);void updatePositions(void); double r[DIMS][NPARTS];double pot;double distx, disty, distz, dist;int main() {
 int i; clock_t start, stop; initPositions(); updatePositions(); start=clock();
int i; clock_t start, stop; initPositions(); updatePositions(); start=clock(); for( i=0; i<NITER; i++ ) {
for( i=0; i<NITER; i++ ) { pot = 0.0; computePot(); if (i%10 == 0) printf("%5d: Potential: %10.3f\n", i, pot); updatePositions();
pot = 0.0; computePot(); if (i%10 == 0) printf("%5d: Potential: %10.3f\n", i, pot); updatePositions(); } stop=clock(); printf ("Seconds = %10.9f\n",(double)(stop-start)/ CLOCKS_PER_SEC); int e; scanf("%d",&e);
} stop=clock(); printf ("Seconds = %10.9f\n",(double)(stop-start)/ CLOCKS_PER_SEC); int e; scanf("%d",&e); } void initPositions() { int i, j; for( i=0; i<DIMS; i++ ) for( j=0; j<NPARTS; j++ ) r[i][j] = 0.5 + ( (double) rand() / (double) RAND_MAX );} void updatePositions() { int i, j; for( i=0; i<DIMS; i++ ) for( j=0; j<NPARTS; j++ ) r[i][j] -= 0.5 + ( (double) rand() / (double) RAND_MAX );} int computePot() { int i, j; for( i=0; i<NPARTS; i++ ) { for( j=0; j<i-1; j++ ) { distx = pow( (r[0][j] - r[0][i]), 2 ); disty = pow( (r[1][j] - r[1][i]), 2 ); distz = pow( (r[2][j] - r[2][i]), 2 ); dist = sqrt( distx + disty + distz ); pot += 1.0 / dist; } } return 0;}
} void initPositions() { int i, j; for( i=0; i<DIMS; i++ ) for( j=0; j<NPARTS; j++ ) r[i][j] = 0.5 + ( (double) rand() / (double) RAND_MAX );} void updatePositions() { int i, j; for( i=0; i<DIMS; i++ ) for( j=0; j<NPARTS; j++ ) r[i][j] -= 0.5 + ( (double) rand() / (double) RAND_MAX );} int computePot() { int i, j; for( i=0; i<NPARTS; i++ ) { for( j=0; j<i-1; j++ ) { distx = pow( (r[0][j] - r[0][i]), 2 ); disty = pow( (r[1][j] - r[1][i]), 2 ); distz = pow( (r[2][j] - r[2][i]), 2 ); dist = sqrt( distx + disty + distz ); pot += 1.0 / dist; } } return 0;}
执行结果如下:

执行时间4.609s。
第二步:托管
新建一个 C++ CLR Console Aplication,命名为mcpp。打开mcpp.cpp文件,将原始代码粘贴进来即可(代码太长这里就不贴出来了,可以在全贴下面的下载全部源码)。
执行结果如下:
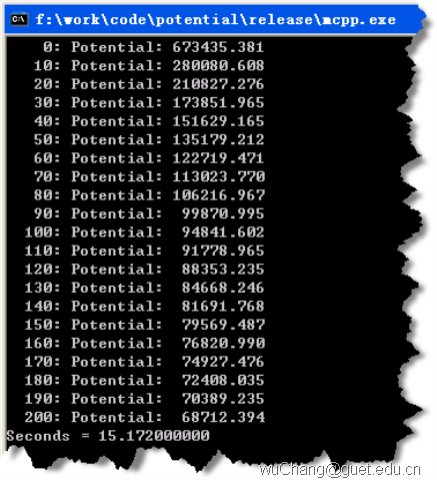
执行时间:15.1720s。
第二步:c#
笔者将原始代码翻译成CS代码,如下:
using System;using System.Collections.Generic;using System.Text;namespace cs{ class Program { private const int RAND_MAX = 0x7fff; private const int NPARTS = 1000; private const int NITER = 201; private const int DIMS = 3; private double pot; private double distx, disty, distz, dist; private Random random = new Random(Environment.TickCount); private double[][] r = new double[DIMS][]; public void main() { int i; int start, stop; for (int ii = 0; ii < DIMS; ii++) { r[ii] = new double[NPARTS]; } initPositions(); updatePositions(); start = Environment.TickCount; for (i = 0; i < NITER; i++) { pot = 0.0; computePot(); if (i % 10 == 0) Console.WriteLine("{0}: Potential: {1:##########.###}", i, pot); updatePositions(); } stop = Environment.TickCount; Console.WriteLine("Seconds = {0:##########.#########}", (double)(stop - start)/1000); } private void computePot() { int i, j; for (i = 0; i < NPARTS; i++) { for (j = 0; j < i - 1; j++) { distx = Math.Pow((r[0][j] - r[0][i]), 2); disty = Math.Pow((r[1][j] - r[1][i]), 2); distz = Math.Pow((r[2][j] - r[2][i]), 2); dist = Math.Sqrt(distx + disty + distz); pot += 1.0 / dist; } } } private void updatePositions() { int i, j; for (i = 0; i < DIMS; i++) for (j = 0; j < NPARTS; j++) r[i][j] -= 0.5 + ((double)random.Next(RAND_MAX)/(double)RAND_MAX); } private void initPositions() { int i, j; for (i = 0; i < DIMS; i++) for (j = 0; j < NPARTS; j++) r[i][j] = 0.5 + ((double)random.Next(RAND_MAX)/(double)RAND_MAX); } static void Main(string[] args) { Program p = new Program(); p.main(); Console.ReadLine(); } }}执行结果如下:

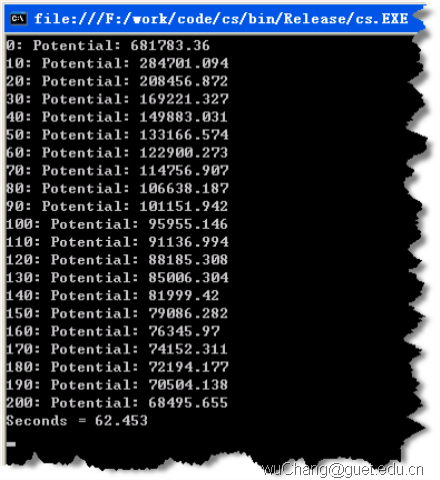
执行时间:62.453s!
第四、数据比较
非托管C: 4.609s
托管cpp: 15.720s
托管c#: 62.453s
PS机器配置:p4 3.0G双核,1G内存

 浙公网安备 33010602011771号
浙公网安备 33010602011771号