


Hadoop学习笔记一 简要介绍
这里先大致介绍一下Hadoop.
本文大部分内容都是从官网Hadoop上来的。其中有一篇介绍HDFS的pdf文档,里面对Hadoop介绍的比较全面了。我的这一个系列的Hadoop学习笔记也是从这里一步一步进行下来的,同时又参考了网上的很多文章,对学习Hadoop中遇到的问题进行了归纳总结。
言归正传,先说一下Hadoop的来龙去脉。谈到Hadoop就不得不提到Lucene和Nutch。首先,Lucene并不是一个应用程序,而是提供了一个纯Java的高性能全文索引引擎工具包,它可以方便的嵌入到各种实际应用中实现全文搜索/索引功能。Nutch是一个应用程序,是一个以Lucene为基础实现的搜索引擎应用,Lucene为Nutch提供了文本搜索和索引的API,Nutch不光有搜索的功能,还有数据抓取的功能。在nutch0.8.0版本之前,Hadoop还属于Nutch的一部分,而从nutch0.8.0开始,将其中实现的NDFS和MapReduce剥离出来成立一个新的开源项目,这就是Hadoop,而nutch0.8.0版本较之以前的Nutch在架构上有了根本性的变化,那就是完全构建在Hadoop的基础之上了。在Hadoop中实现了Google的GFS和MapReduce算法,使Hadoop成为了一个分布式的计算平台。
其实,Hadoop并不仅仅是一个用于存储的分布式文件系统,而是设计用来在由通用计算设备组成的大型集群上执行分布式应用的框架。
Hadoop包含两个部分:
1、HDFS
即Hadoop Distributed File System (Hadoop分布式文件系统)
HDFS具有高容错性,并且可以被部署在低价的硬件设备之上。HDFS很适合那些有大数据集的应用,并且提供了对数据读写的高吞吐率。HDFS是一个master/slave的结构,就通常的部署来说,在master上只运行一个Namenode,而在每一个slave上运行一个Datanode。
HDFS支持传统的层次文件组织结构,同现有的一些文件系统在操作上很类似,比如你可以创建和删除一个文件,把一个文件从一个目录移到另一个目录,重命名等等操作。Namenode管理着整个分布式文件系统,对文件系统的操作(如建立、删除文件和文件夹)都是通过Namenode来控制。
下面是HDFS的结构:
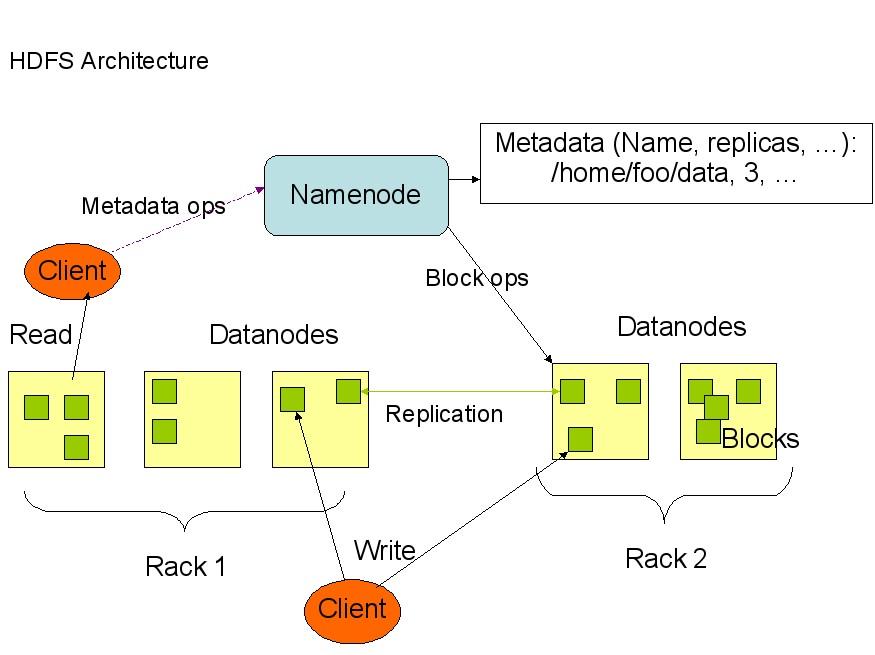
从上面的图中可以看出,Namenode,Datanode,Client之间的通信都是建立在TCP/IP的基础之上的。当Client要执行一个写入的操作的时候,命令不是马上就发送到Namenode,Client首先在本机上临时文件夹中缓存这些数据,当临时文件夹中的数据块达到了设定的Block的值(默认是64M)时,Client便会通知Namenode,Namenode便响应Client的RPC请求,将文件名插入文件系统层次中并且在Datanode中找到一块存放该数据的block,同时将该Datanode及对应的数据块信息告诉Client,Client便这些本地临时文件夹中的数据块写入指定的数据节点。
HDFS采取了副本策略,其目的是为了提高系统的可靠性,可用性。HDFS的副本放置策略是三个副本,一个放在本节点上,一个放在同一机架中的另一个节点上,还有一个副本放在另一个不同的机架中的一个节点上。当前版本的hadoop0.12.0中还没有实现,但是正在进行中,相信不久就可以出来了。
2、MapReduce的实现
MapReduce是Google 的一项重要技术,它是一个编程模型,用以进行大数据量的计算。对于大数据量的计算,通常采用的处理手法就是并行计算。至少现阶段而言,对许多开发人员来说,并行计算还是一个比较遥远的东西。MapReduce就是一种简化并行计算的编程模型,它让那些没有多少并行计算经验的开发人员也可以开发并行应用。
MapReduce的名字源于这个模型中的两项核心操作:Map和 Reduce。也许熟悉Functional Programming(函数式编程)的人见到这两个词会倍感亲切。简单的说来,Map是把一组数据一对一的映射为另外的一组数据,其映射的规则由一个函数来指定,比如对[1, 2, 3, 4]进行乘2的映射就变成了[2, 4, 6, 8]。Reduce是对一组数据进行归约,这个归约的规则由一个函数指定,比如对[1, 2, 3, 4]进行求和的归约得到结果是10,而对它进行求积的归约结果是24。
关于MapReduce的内容,建议看看孟岩的这篇MapReduce:The Free Lunch Is Not Over!
好了,作为这个系列的第一篇就写这么多了,我也是刚开始接触Hadoop,下一篇就是讲Hadoop的部署,谈谈我在部署Hadoop时遇到的问题,也给大家一个参考,少走点弯路。
本文大部分内容都是从官网Hadoop上来的。其中有一篇介绍HDFS的pdf文档,里面对Hadoop介绍的比较全面了。我的这一个系列的Hadoop学习笔记也是从这里一步一步进行下来的,同时又参考了网上的很多文章,对学习Hadoop中遇到的问题进行了归纳总结。
言归正传,先说一下Hadoop的来龙去脉。谈到Hadoop就不得不提到Lucene和Nutch。首先,Lucene并不是一个应用程序,而是提供了一个纯Java的高性能全文索引引擎工具包,它可以方便的嵌入到各种实际应用中实现全文搜索/索引功能。Nutch是一个应用程序,是一个以Lucene为基础实现的搜索引擎应用,Lucene为Nutch提供了文本搜索和索引的API,Nutch不光有搜索的功能,还有数据抓取的功能。在nutch0.8.0版本之前,Hadoop还属于Nutch的一部分,而从nutch0.8.0开始,将其中实现的NDFS和MapReduce剥离出来成立一个新的开源项目,这就是Hadoop,而nutch0.8.0版本较之以前的Nutch在架构上有了根本性的变化,那就是完全构建在Hadoop的基础之上了。在Hadoop中实现了Google的GFS和MapReduce算法,使Hadoop成为了一个分布式的计算平台。
其实,Hadoop并不仅仅是一个用于存储的分布式文件系统,而是设计用来在由通用计算设备组成的大型集群上执行分布式应用的框架。
Hadoop包含两个部分:
1、HDFS
即Hadoop Distributed File System (Hadoop分布式文件系统)
HDFS具有高容错性,并且可以被部署在低价的硬件设备之上。HDFS很适合那些有大数据集的应用,并且提供了对数据读写的高吞吐率。HDFS是一个master/slave的结构,就通常的部署来说,在master上只运行一个Namenode,而在每一个slave上运行一个Datanode。
HDFS支持传统的层次文件组织结构,同现有的一些文件系统在操作上很类似,比如你可以创建和删除一个文件,把一个文件从一个目录移到另一个目录,重命名等等操作。Namenode管理着整个分布式文件系统,对文件系统的操作(如建立、删除文件和文件夹)都是通过Namenode来控制。
下面是HDFS的结构:
从上面的图中可以看出,Namenode,Datanode,Client之间的通信都是建立在TCP/IP的基础之上的。当Client要执行一个写入的操作的时候,命令不是马上就发送到Namenode,Client首先在本机上临时文件夹中缓存这些数据,当临时文件夹中的数据块达到了设定的Block的值(默认是64M)时,Client便会通知Namenode,Namenode便响应Client的RPC请求,将文件名插入文件系统层次中并且在Datanode中找到一块存放该数据的block,同时将该Datanode及对应的数据块信息告诉Client,Client便这些本地临时文件夹中的数据块写入指定的数据节点。
HDFS采取了副本策略,其目的是为了提高系统的可靠性,可用性。HDFS的副本放置策略是三个副本,一个放在本节点上,一个放在同一机架中的另一个节点上,还有一个副本放在另一个不同的机架中的一个节点上。当前版本的hadoop0.12.0中还没有实现,但是正在进行中,相信不久就可以出来了。
2、MapReduce的实现
MapReduce是Google 的一项重要技术,它是一个编程模型,用以进行大数据量的计算。对于大数据量的计算,通常采用的处理手法就是并行计算。至少现阶段而言,对许多开发人员来说,并行计算还是一个比较遥远的东西。MapReduce就是一种简化并行计算的编程模型,它让那些没有多少并行计算经验的开发人员也可以开发并行应用。
MapReduce的名字源于这个模型中的两项核心操作:Map和 Reduce。也许熟悉Functional Programming(函数式编程)的人见到这两个词会倍感亲切。简单的说来,Map是把一组数据一对一的映射为另外的一组数据,其映射的规则由一个函数来指定,比如对[1, 2, 3, 4]进行乘2的映射就变成了[2, 4, 6, 8]。Reduce是对一组数据进行归约,这个归约的规则由一个函数指定,比如对[1, 2, 3, 4]进行求和的归约得到结果是10,而对它进行求积的归约结果是24。
关于MapReduce的内容,建议看看孟岩的这篇MapReduce:The Free Lunch Is Not Over!
好了,作为这个系列的第一篇就写这么多了,我也是刚开始接触Hadoop,下一篇就是讲Hadoop的部署,谈谈我在部署Hadoop时遇到的问题,也给大家一个参考,少走点弯路。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号