


mysql高可用
做高可用最大的代价就是可能发生裂脑。
1.1 heartbeat作用
可以将资源(一般是IP)从一台已经故障的计算机快速转移到另一台正常运转的机器上继续提供服务。功能与keepalived有很多相同之处,在我们生产中实际的业务应用两者是有区别的,互有不可替代性。
官方网址http://linux-ha.org/wiki/Main-Page
1.2 heartbeat工作原理
heartbeat主备模式:通过修改heartbeat软件的配置文件,可以指定哪一台heartbeat服务器作为主服务器,另一台将自动成为热备服务器,然后在热备服务器上配置heartbeat守护程序来监听来自主服务器的心跳消息,如果热备服务器在指定时间内未监听到来自主服务器的心跳,就会启动故障转移程序,并取得主服务器上的相关资源服务的所有权,接管主服务器继续不间断的提供服务,从而达到资源及服务高可用性的目的。
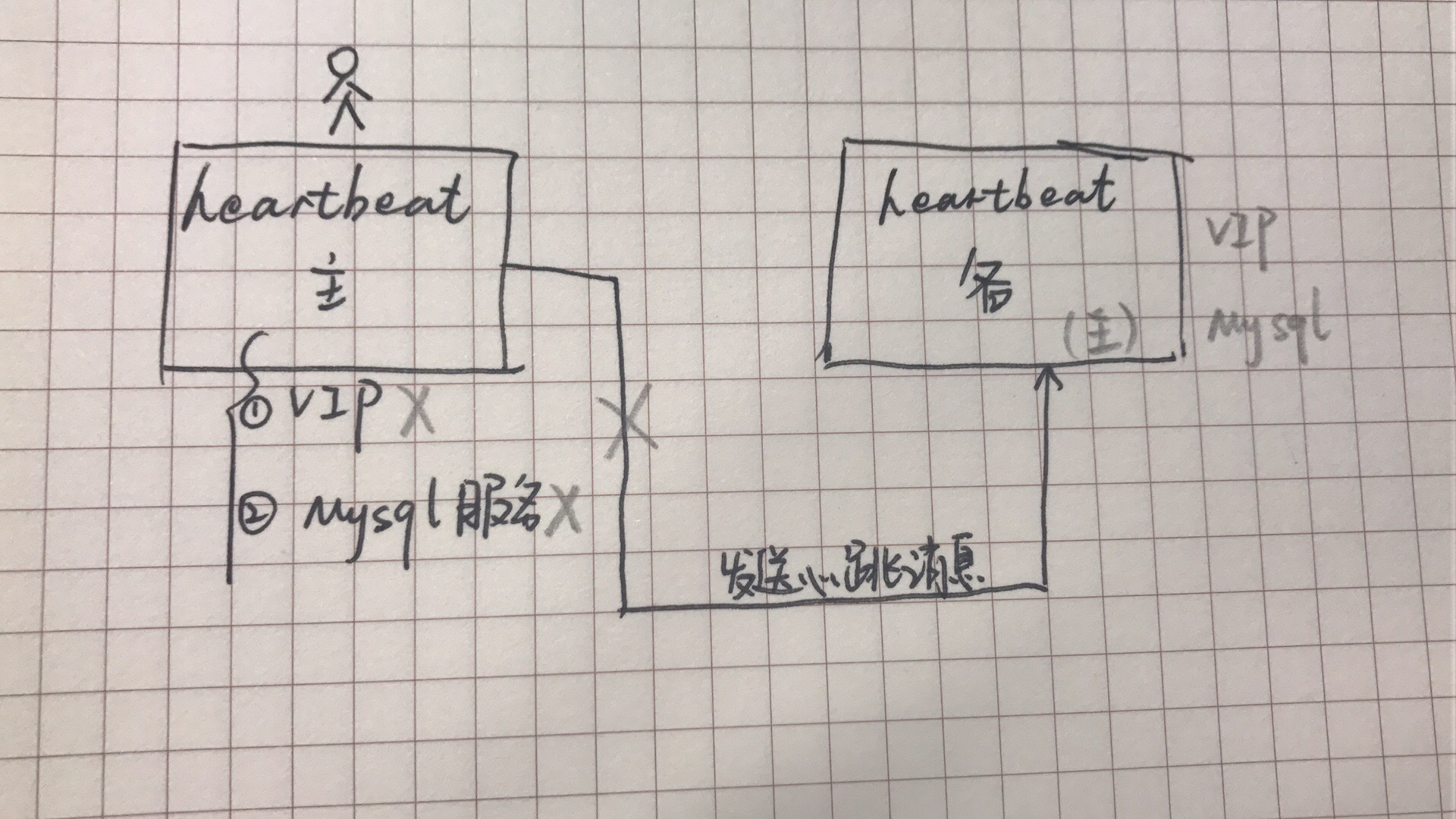
heartbeat主主模式:互为主备,指定时间内收不到消息,会认为对方宕机,于是启动自身模块来接管对方的资源服务,保障业务不间断(在故障转移期间也是需要切换时间的,一般在5-20秒)
和keepalived服务一样,heartbeat高可用是服务器级别的,不是服务级别的,比如主上的Apache断了,不会切换,除非停掉主库上的keepalived。
切换的常见条件:
服务器宕机;
heartbeat服务本身故障;
心跳连接故障(主备网络连接)
1.3 heartbeat心跳连接
串行电缆,所谓的串口(首选,但距离不能太远)
一根以太网线,两网卡直连(推荐)
以太网电缆,通过交换机等网络设备连接(次选,心跳容易出现故障)
1.4 heartbeat裂脑
由于两台高可用服务器对之间在指定时间内,无法互相检测对方心跳而各自启动故障转移功能,取得了资源及服务的所有权,而此时的两台高可用服务器对都还活着并在正常运行,这样就会导致同一个IP或服务在两端同时启动而发生冲突的严重问题,最严重的是两台主机占用同一个VIP地址,当用户写入数据时可能会分别写入到两端,导致数据不一致或丢失数据,这种情况就被成为裂脑,也称为分区集群或大脑垂直分割。
裂脑发生的原因:
1)高可用服务器对之间心跳线链路故障,导致无法正常通信;
心跳线坏了(包括断了、老化)
网卡坏了及相关驱动坏了,IP配置及冲突问题(网卡直连的情况)
心跳线间连接的设备故障(网卡及交换机)
仲裁的机器出问题
2)高可用服务器对上开启了防火墙阻挡了心跳消息传输
3)高可用服务器对上心跳网卡地址等信息配置不正确,导致发送心跳失败
4)其他服务配置不当等原因,如心跳方式不同,心跳广播冲突,软件BUG等
防止裂脑的方法:
1)同时使用串行电缆和以太网电缆连接,同时用两条心跳线路,这样一条线路坏了,另一个还可以传送心跳消息(网卡设备和网线设备)
2)检测到裂脑时,强行关闭一个心跳节点(这个功能需要特殊设备支持,如Stonith、fence),相当于程序上设备节点发现心跳线故障,发送关机命令到主节点
3)做好对裂脑的监控报警(如邮件),在问题发生时人为第一时间介入仲裁,降低损失。在实施高可用方案时,要根据业务实际需求是否能容忍这样的损失
4)启用磁盘锁(一般要用共享磁盘组),正在服务一方锁住共享磁盘,裂脑发生时,让对方完全抢不走共享磁盘资源,但使用磁盘锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动解锁,另一方永远得不到共享磁盘,现实中如果服务节点突然死机或奔溃,就不可能执行解锁命令,后备节点也就接管不了共享资源和应用服务
5)报警报在服务器接管之前,给人员处理留足够时间(例如:让服务器接管时间在报警之后五分钟),接管的时间较长,数据不会丢,导致用户无法写数据
6)报警后,不直接自动服务器接管,而是由人为人员控制接管
7)增加仲裁机制,确定谁该获得资源(比如ping不通网关的一方放弃竞争或自动重启,或借助第三方软件)
fence:
fence是HA集群环境下的术语,在硬件领域,fence设备其实就是一个智能电源管理设备。这些设备带有以太网口的,用来在HA切换触发时通过网络重启提供资源服务的服务器。
IBM提供的fence设备是RSA,HP的是ILO,DELL的是IDRAC,外部fence设备如APC。
1.5 heartbeat消息类型
心跳消息:单播、广播或多播,控制心跳频率及出现故障要等待多久进行故障切换;
集群转换消息:ip-request和ip-request-resp
在发生切换的时候,主会宕机,当主修好后,如果主备内存、CPU等配置一致,其实无需切换回原始模式,如果主的配置比备高,则需要切回主库
当主服务器恢复在线状态时,会通过ip-request消息要求备机释放主服务器失败时备服务器获得的资源;备服务器释放资源后,会通过ip-request-resp消息通知主服务器已经归还资源,主服务器收到消息之后,启动失败时释放的资源及服务,并开始提供正常的访问服务;
重传请求:rexmit-request控制重传心跳请求,此消息相对不重要。
以上心跳控制消息都使用UDP协议发送到/etc/ha.d/ha.cf文件指定的任意端口或指定的多播地址。
1.6 heartbeat IP地址接管和故障转移
heartbeat是通过IP地址接管和ARP广播进行故障转移的。 #可通过arp -a查看ARP表
ARP广播:在主服务器故障时,备用节点接管资源后,会立即强制更新所有客户端本地的ARP表(即清楚客户端本地缓存的失败服务器的VIP地址和Mac地址的解析记录),确保客户端和新的主服务器对话。
1.7 VIP和IP
IP:真实IP,又称管理IP,在负载均衡及高可用环境中,管理IP不对外提供用户访问服务的,仅是管理服务器所用,如ssh可以通过这个管理IP连接服务器;
VIP:虚拟IP,对于heartbeat就是临时绑定在物理网卡上的别名IP(heartbeat3起采用辅助IP,keepalived也是),在实际高可用生产环境中,需在DNS配置中把网站域名地址解析到这个VIP地址,由VIP对用户提供服务,这样做的好处就是服务器宕机之后,VIP可以自动漂移。
手工配置VIP方法:
别名方式----ifconfig eth1:1 192.168.0.1/24 up 或ifconfig eth1:1 192.168.0.1 netmask 255.255.255.254 up #查不到辅助IP
ifconfig eth1:1 down
辅助IP方式---ip addr add 10.0.15.1/24 broadcast 10.0.15.255 dev eth1 #ip addr可以查看到别名IP和辅助IP
ip addr del 10.0.15.1/24 broadcast 10.0.15.255 dev eth1
1.8 heartbeat默认目录
启动脚本:/etc/init.d/
资源目录:/etc/ha.d/resource.d/ 为heartbeat提供服务的脚本
配置文件:/etc/ha.d (常用的配置文件:ha.cf即heartbeat参数配置文件、authkey即heartbeat认证文件、haresource即heartbeat资源配置文件,如启动IP资源及脚本等)
1.9 生产应用场景
heartbeat:web服务,配合Nginx和haproxy;数据库主的高可用,从库可以负债均衡LVS;存储如NFS的高可用,或者分布式存储MFS
keepalived:web服务(特别是配合LVS)
1.10 heartbeat高可用需求及部署
两台服务器,两个物理IP(eth0),两个VIP,假设网卡间用网线直连
操作系统:CentOS5.8/6.4
| 名称 | 端口 | IP | 用途 |
| MASTER | eth0 | 10.0.0.7 | 外网管理IP,用于WLAN数据转发 |
| eth1 | 172.16.1.7 | 内网管理IP,用于LAN数据转发(此网卡可无) | |
| eth2 | 10.0.10.7 | 用于服务器间心跳连接(直连) | |
| vip | 10.0.0.17 | 用户提供应用程序A挂载服务 | |
| SLAVE | eth0 | 10.0.0.8 | 外网管理IP,用于WLAN数据转发 |
| eth1 | 172.16.1.8 | 内网管理IP,用于LAN数据转发(此网卡可无) | |
| eth2 | 10.0.10.8 | 用于服务器间心跳连接(直连) | |
| vip | 10.0.0.18 | 用户提供应用程序B挂载服务 |
1)装操作系统
2)配置eth0 eth2(/1)
3)修改hostname :
hostname data-1-1
sed -i ' s#HOSTNAME=moban#HOSTNAME=data-1-1#g' /etc/sysconfig/network
vi /etc/hosts
4)配置心跳连接 在/etc/hosts下写入 10.0.10.7 data-1-1 10.0.10.8 data-1-2
在data-1-1上增加路由:/sbin/route add -host 10.0.10.8 dev eth2(/1) 用route -n查看 如需永久生效echo '/sbin/route add -host 10.0.10.8 dev eth2'>>/etc/rc.local
在data-1-2上增加路由:/sbin/route add -host 10.0.10.7 dev eth2(/1)
5)安装heartbeat
对于CentOS5.8(heartbeat2) 配置yum保留rpm包文件 安装heartbeat:yum install heartbeat -y即可(此句话可能要执行两遍)
对于CentOS6.4(heartbeat3.0,默认没有heartbeat的包):
wget http://mirrors.ustc.edu.cn/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm
rpm -ivh epel-release-6-8.noarch.rpm
rpm -qa |grep epel

yum search heartbeat

yum install heartbeat -y
6)配置ha.cf文件
ll /etc/ha.d/ (默认的配置文件在/usr/share/doc/heartbeat-3.0.4/,放置heartbeat的一些模板)
cd /usr/share/doc/heartbeat-3.0.4/
cp ha.cf haresources authkeys /etc/ha.d/
cd /etc/ha.d/
ha.cf中参数说明>>>
debugfile /var/log/ha-debug heartbeat的调试日志存放位置
logfile /var/log/ha-log 日志存放位置
logfacility local1 在syslog服务中配置通过local1设备接收日志
keepalive 2 指定心跳间隔时间为2秒
deadtime 30 指定若备节点30秒内没有收到主节点的心跳信号,则立刻接管主节点的服务资源
warntime 10 指定心跳延迟的时间为10秒,当10秒钟内备份节点不能接收到主节点的心跳信号时,就会往日志中写入一个警告日志,但此时不会切换服务
initdead 120 指定heartbeat首次运行后,需要等待120秒才启动主服务器的任何资源,确认对端死没死,至少为deadtime的两倍。因此单机启动时遇到VIP绑定很慢是正常现象。
#bcast eth1 广播方式,在eth1上广播
mcast eth1 255.9.1.181 694 1 0 多播,需指定网卡及网址等
auto_failback on 用来定义当主节点恢复时,要不要自动切回
node data-1-1 节(备)点主机名,可通过uname -n查看
crm no 是否开启集群资源管理功能(一般都关掉)
authkey中参数说明>>>
# authentication file authkey权限必须为600
#available methods:crc,shal,md5可以设置的认证方法,shal的方式被认为是最好的
haresource中参数说明>>>
data-1-1 IPaddr::10.0.0.17/24/eth0 主机名,heartbeat配置IP的脚本,VIP地址,子网掩码,绑定的设备(只要用冒号分隔,一遍前面代表脚本,后面代表传参)
7)启动heartbeat
/etc/init.d/heartbeat start
ip add|grep 10.0.0. (出现17这个IP可能要等待两分钟)
测试其高可用性-----
停掉两端的防火墙:/etc/init.d/iptable stop
重启heartbeat:/etc/init.d/heartbeat stop
/etc/init.d/heartbeat start
停掉heartbeat1节点:/etc/init.d/heartbeat stop
查看2节点是否接管1节点:ip add|grep 10.0.0.
#所有的操作记录都可以在/var/log/ha-log和/var/log/ha-debug,/var/log/messages中查看,也可通过tail -f跟踪
1.11 web高可用
在两台heartbeat服务器上部署web:yum install httpd -y
/etc/init.d/httpd start
cd /var/www/html/
echo 10.7 >index.html #echo 10.8>index.html
在网页中打开http://10.0.0.7查看是否成功
测试高可用1-----
#除了之前的停掉节点的方法,这里采取了standby、接管的方法
在1节点上:/usr/lib64/heartbeat/hb_standby #/usr/share/heartbeat/hb_standby heartbeat3.0.4版本
在1节点上:/usr/lib64/heartbeat/hb_takeover #/usr/share/heartbeat/hb_takeover heartbeat3.0.4版本 发现会把两个节点都接管过来了
测试高可用2-----
关闭两节点httpd服务:/etc/init.d/httpd stop
chkconfig httpd off #直接停掉web,交给heartbeat管理
lsof -i :80
在两台机器上把脚本放到heartbeat脚本目录下---- cp /etc/init.d/httpd /etc/init.d/resource.d/ #脚本执行需要以/etc/init.d/httpd stop/start方式,确保脚本具备可执行权限
vi haresource ----- data-1-1 IPaddr::10.0.0.17/24/eth0 httpd #这里只添加了1节点的httpd,配置http服务启动脚本,让heartbeat同时负责httpd和VIP的启动
关闭两节点heartbeat服务:/etc/init.d/heartbeat stop
重新启heartbeat:/etc/init.d/heartbeat start
lsof -i: 80 #发现1节点web服务启了,但是2节点没启(因为没有添加httpd),这时只有1节点的heartbeat挂了,2节点才会启服务(这里可以1节点/etc/init.d/heartbeat stop试一下)
在生产场景中,heartbeat可以仅控制VIP资源的漂移(适合web服务),也可即控制VIP资源的迁移,又控制服务资源启动与停止(适合数据服务(数据库和存储))
1.11 heartbeat和keepalived的应用场景区别
1)对于一般的web、db、负载均衡(Nginx、haproxy)等,两者都可以实现;
2)lvs负载均衡最好和keepalived结合,虽然heartbeat也可以调用ipvsadm命令的脚本来启动和停止lvs负载均衡,但是heartbeat本身并没有对下面节点rs的健康检查功能,heartbeat的这个缺陷可以通过ldircetord插件来弥补;
3)需要数据同步(配合drbd)的高可用业务最好用heartbeat,例如:mysql双主多从,NFS/MFS存储,他们的特点是需要数据同步;
4)熟悉哪个运维用哪个
二、高可用工具drbd(heartbeat最好的做实时同步的工具)
2.1 drbd(distributed replicated block device)介绍
基于块设备在不同的高可用服务器对之间同步和镜像数据的软件(一个块一个快同步过去),通过其可以实现在网络中的两台服务器之间基于块设备级别的实时或异步镜像或同步复制,基于文件系统底层的块层级同步,比rsync+inotify这种物理文件同步效率更高,效果更好。#其中块可以是磁盘分区,LVM逻辑卷,或整块磁盘等。同步是基于network,被理解为network based raid-1。
实现实时数据同步! 这样主节点故障,备节点上会有一份和主节点相同的数据备份可以继续使用,不但数据不会丢失,还会提升用户体验。
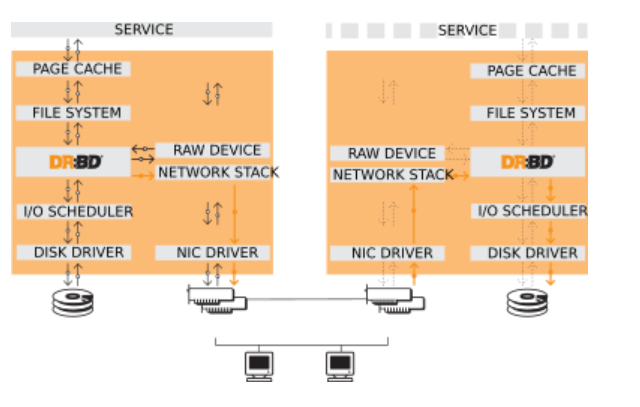
drbd工作原理图:一边写入数据磁盘(disk driver),一边通过TCP/IP(network stack)传送到对端的裸设备(raw device),再写入对端的disk driver
2.2 drbd同步模式
实时同步:当数据写入到本地磁盘和远端所有服务器磁盘都成功后才会返回成功写入,服从协议C,有效防止本地和远端数据丢失和不一致,是生产环境中主要采取的模式
异步模式:
协议A:本地写成功后就返回成功,远端数据放在发送buffer中,可能丢失,但是速度快;
协议B:内存同步(半同步)复制协议,本地写成功并将数据发送到对方后立即返回,如果双机掉电,数据可能丢失;-----对于半同步,mysql5.5以上,SQLserver(保障一台同步,另外几台异步)
###协议C:同步复制协议,本地和对方服务器磁盘都写成功确认后返回成功,如果单机掉电或单机磁盘损坏,则数据不会丢失,工作中一般选择,不过会影响流量,从而影响网络时延。
2.3 drbd应用模式
单主模式:及主备模式,为典型的高可用集群方案;
双主模式:需要采用共享cluster文件系统,如GFS和OCFS2,用于需要从2个节点并发访问数据的场合,需特别配置,生产中较少用。
应用场景:常用于基于高可用服务器之间的数据同步解决方案,例如:heartbeat+drbd+nfs/mfs/gfs,heartbeat+drbd+mysql/oracle,但drbd存在主节点在写,备节点不可见(非mount)的状态,适合中小型公司。
2.4 运维同步工具
rsync(配合实时同步工具:sersync,inotify,lsyncd)
scp (配合实时同步工具:sersync,inotify,lsyncd)
nc
nfs(网络文件系统,也可实时同步)
union双机同步
csync2多机同步
软件的自身同步机制(mysql,oracle,MongoDB,ttserver,redis...),文件放到数据库同步到从库,再把文件拿出来。
drbd
2.5 安装drbd
>>>部署模式
CentOS5.4 ----- drbd8.3 yum
CentOS6.4 ----- drbd8.4
1)主备模式
IP资源配置:和heartbeat一样,与heartbeat配合使用时则需要心跳线
| 名称 | 端口 | IP | 用途 |
| MASTER | eth0 | 10.0.0.7 | 外网管理IP,用于WLAN数据转发 |
| eth2 | 10.0.10.7 | 用于服务器间心跳连接及数据同步(直连) | |
| vip | 10.0.0.17 | 用户提供应用程序A挂载服务 | |
| SLAVE | eth0 | 10.0.0.8 | 外网管理IP,用于WLAN数据转发 |
| eth2 | 10.0.10.8 | 用于服务器间心跳连接及数据同步(直连) | |
| vip | 10.0.0.18 | 用户提供应用程序B挂载服务 |
>>>目标:实现分区/dev/sda1的同步
配置主机名:heartbeat已配过 ping data-1-1 ping data-1-2
停止防火墙,时间同步:/etc/init.d/iptables stop setenforce 0
配置网卡:eth0和eth2(/1) heartbeat已配过
配置心跳添加路由:heartbeat已配过
需要为主备节点分别添加一块硬盘,比如主0.5G,备1G,并分区。 /dev/sdb
drbd需要分成两个区,一个区放数据(384M)/dev/sdb1 可以设置挂载目录/data,第二个区就是剩余的大小/dev/sdb2 -----meta data分区,存储drbd同步的状态信息。 (可以用fdisk /dev/sdb partprobe实现),分区完成后记得格式化(sdb1必须要格式化mkfs.ext4 /dev/sdb1不能挂载,sdb2不需要格式化 mount /dev/sdb2 /mnt)
安装drbd软件:
CentOS5.4 ---- yum install kmod-drbd83 drbd83 -y
CentOS6.4 ----
法1:编译安装
mkdir /home/oldboy/tools -p
cd /home/oldboy/tools
export LC_ALL=C
wget http://oss.linbit.com/drbd/8.4/drbd-8.4.4.tar.gz
ls drbd-8.4.4.tar.gz
tar xf drbd-8.4.4.tar.gz
cd drbd-8.4.4
./configure --prefix=/application/drbd8.4.4 --with-km --with-heartbeat --sysconfdir=/etc/
ls -l /usr/src/kernels/$(uname -r)/ (如果没有路径,需装kernel-devel)
make KDIR=/usr/src/kernels/$(uname -r)/ #指定内核源码路径
echo $? ---显示结果为0代表make成功
make install
lsmod |grep drbd
modprobe drbd #配置一个模块
lsmod |grep drbd
法2:找到包含drbd的源
mkdir /home/oldboy/tools -p
cd /home/oldboy/tools
wget http://mirrors.ustc.edu.cn/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm
rpm -ivh epel-release-6-8.noarch.rpm
yum install kernel-devel kernel-headers flex drbd84-utils kmod-drbd84
这里再次理顺/data各配置列表
| 主机名称 | data-1-1 | data-1-2 |
| 管理IP | eth0:10.0.0.7 | eth0:10.0.0.8 |
| DRBD管理名称 | data | data |
| DRBD挂载目录 | /data | /data |
| DRBD逻辑设备 | /dev/drbd0 | /dev/drdb0 |
| DRBD对接IP | eth1:10.0.0.7/24 | eth2:10.0.0.8/24 |
| DRBD存储设备 | /dev/sdb1 | /dev/sdb1 |
| DRBD Meta设备 | /dev/sdb2[0] | /dev/sdb2[0] |
| NFS导出目录 | /data | /data |
| NFS虚拟IP | eth0:192.168.1.249/24 | eth0:192.168.1.249/24 |
drbd的配置参数查看:
ll /etc/drbd.conf #修改配置文件,一系列内容,把默认的global_XXXX删掉
ll /etc/erbd.d/
把/etc/hosts里的网址都改成心跳线的网址
drbdadm crearte-md data #初始化metal分区,出现successful表示成功
drbdadm up data(data这个资源可以用all替换) #出现is configured代表成功
cat /proc/drbd #查看drbd角色,显示secondary/secondary是正确的 (如果出现secondary/Unknown可能出现了裂脑现象)
/etc/init.d/iptables stop #两端连不上,可能需要重启防火墙
drbdadm --overwrite-data-of-peer primary data #一个资源只能在一端执行同步数据到对端的命令
挂载测试数据库同步及查看备节点数据(时刻也要确保两节点未出现UNknown状态,该软件状态至少在虚机上不稳定?):
主节点:
mkdir /data
mount /dev/drbd0 /data
df -h
cd /data
ll
cat /proc/drbd #查看状态
备节点:
drbdadm down data #只有先down掉才能下一步的挂载
mount /dev/sdb1 /mnt
ll /mnt
drbdadm up data #发现起不来,则需要卸载
umount /mnt/
drbdadm up data
cat /proc/drbd
三、MySQL+drbd+heartbeat高可用模式实战
企业生产场景中,一主多从的mysql数据库架构是最常用的DB架构方案,多个从可以通过LVS或haproxy等代理实现对多个从库的负载均衡,分担读的压力,同时排除单点问题(比如一主四从,其中三个从通过lvs做一个负载均衡,另外一个从做备份,其中从节点宕机影响不大)。
mysql高可用架构拓扑(单主热备模式):
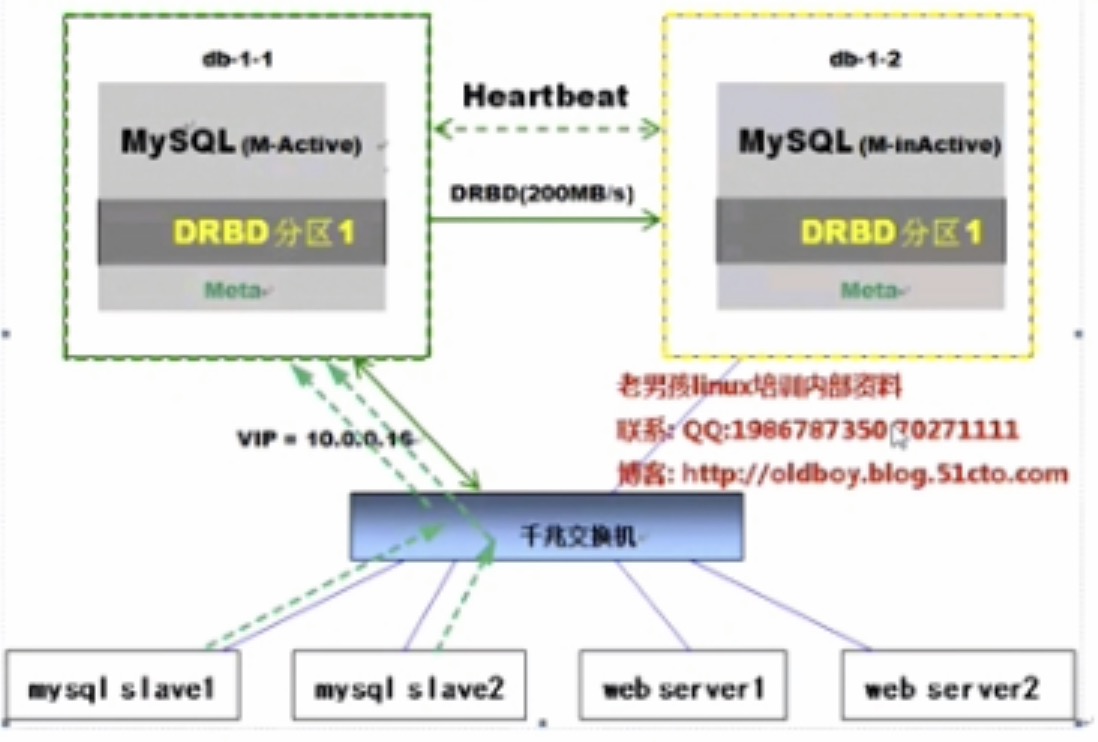
db-1-1为mysql的主,负责数据库的写,旗下有两个从,负责读,为了利于主从切换,需配置VIP实现
db-1-2为热备的主(正常状态下不可见),db-1-1和db-1-2通过heartbeat进行高可用,并直接利用drbd进行数据同步
mysql高可用发生故障后切换:
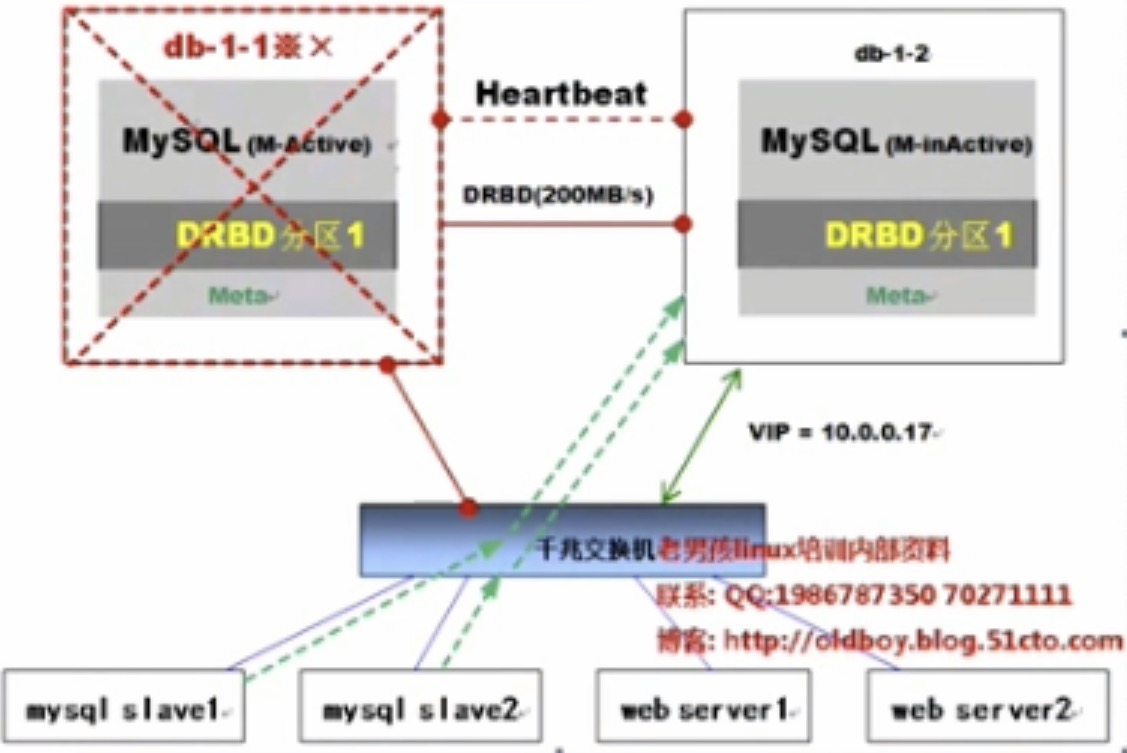
发生故障后,mysql热备主节点首先接管VIP,然后接管mysql相关服务。
由于mysql数据库的从配置时是通过VIP与主库同步的,所以发生故障时也会自动切换到与mysql热备的服务器重新做主从关系(此切换过程大概要60S)
热备主库的硬件配置和原主库一致或更好的情况下,也可以在MySQL原宕机主库恢复后,降低角色作为热备节点。
通过MySQL同步做双主的方式,是难以做到主库宕机从库和新的主库自动同步的。
mysql高可用架构拓扑(双主热备模式):
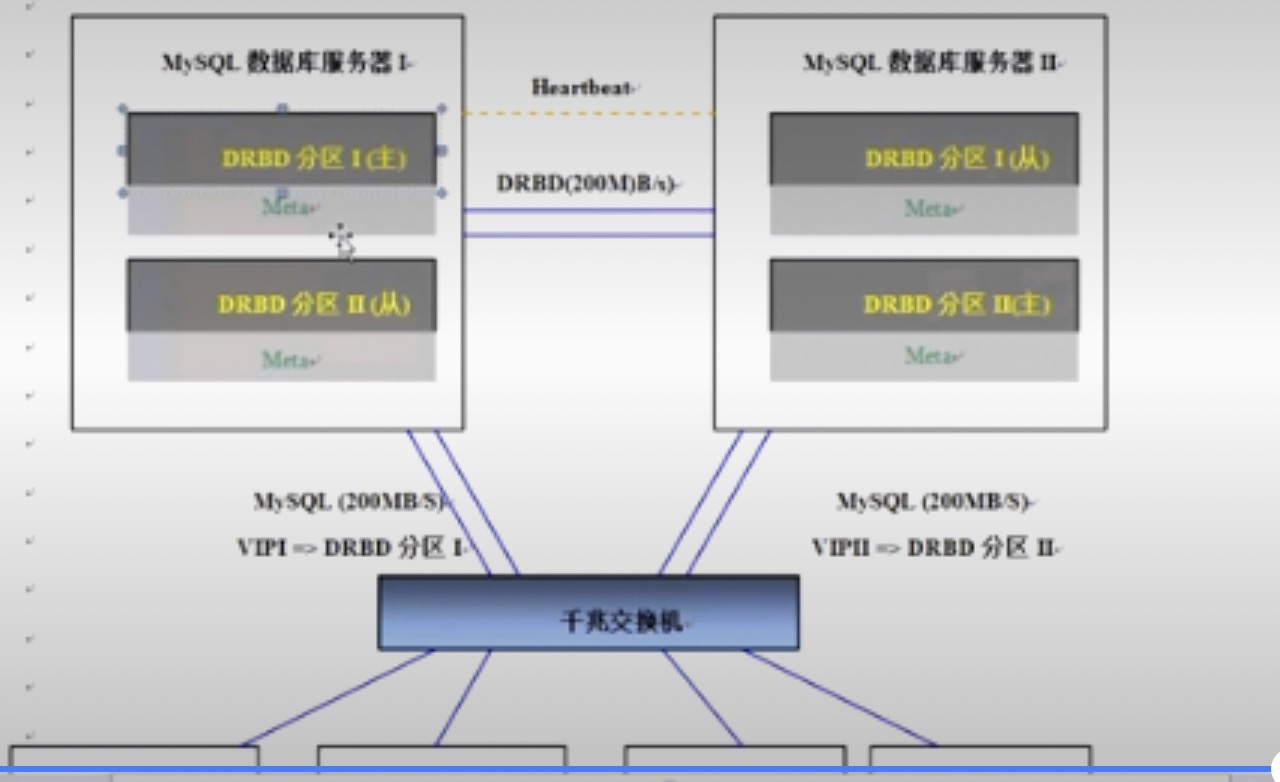
网卡及IP资源:
#准备两台新服务器,首先也进行网卡(setup---network configuration)及主机名(hostname)的配置,并添加心跳路由,做好基础环境的准备。
#echo '/sbin/route add -host 10.0.10.7 dev eth1'>>/etc/rc.local 可通过route -n查询
| 名称 | 端口 | IP | 用途 |
| MASTER | eth0 | 10.0.0.7 | 管理IP,用于LAN数据转发 |
| eth1 | 10.0.10.7 | 用于mysql服务器间心跳连接(直连) | |
| eth2 | 10.0.11.7 | 用于mysql服务器DRBD同步(直连) | |
| vip | 10.0.0.17 | 用户提供对外mysql数据库服务VIP,需绑定在管理IP上 | |
| SLAVE | eth0 | 10.0.0.8 | 管理IP,用于LAN数据转发 |
| eth1 | 10.0.10.8 | 用于mysql服务间心跳连接(直连) | |
| eth2 | 10.0.11.8 | 用于mysql服务器DRBD同步(直连) | |
| vip |
1)下载并安装epel (换yum源)
安装并完成两节点的heartbeat配置 yum install heartbeat -y,启动heartbeat
#如果不通,检查防火墙以及两个几点是否通畅:/etc/init.d/iptables stop chkconfig iptables off setenforce 0 sed -i ' s#SELINUX=enforcing#SELINUX=disabled=g' /etc/selinux/config
2)安装drbd
增加一块硬盘(大于2T),通过parted方式进行非交互分区
#data-1-1和data-1-2
parted /dev/sdb mklabel gpt
parted /dev/sdb mkpart primary 0 1024 (Ignore)
parted /dev/sdb p
parted /dev/sdb mkpart primary 1025 2146 (Ignore)
parted /dev/sdb p
下载含有drbd的安装途径
mkdir -p /home/oldboy/tools
cd /home/oldboy/tools
wget -q http://elrepo.org/elrepo-release-6-5.el6.elrepo.noarch.rpm
rpm -ivh elrepo-release-6-5.el6.elrepo.noarch.rpm
sed -i 's#keepcache=0#keepcache=1#g' /etc/yum.conf
yum install drbd kmod-drbd84 -y
ll /etc/dr
将drbd加载到内核:
modprobe drbd
lsmod |grep drbd
echo "modprobe drbd >/dev/null 2>&1" >/etc/sysconfig/modules/drbd.modules
完成drbd的配置
# global { # minor-count 64; # dialog-refresh 5; # 5 seconds # disable-ip-verification; usage-count no; } common { protocol C; disk { on-io-error detach; no-disk-flushes; no-md-flushes; } net { sndbuf-size 512k; # timeout 60; # connect-int 10; # ping-int 10; # ping-timeout 5; max-buffers 8000; unplug-watermark 1024; max-epoch-size 8000; # ko-count 4; # allow-two-primaries; cram-hmac-alg "sha1"; shared-secret "hdhwXwes23sYEhart8t"; after-sb-0pri disconnect; after-sb-1pri disconnect; agter-sb-2pri disconnect; rr-conflict disconnect; # data-integrity-alg "md5"; # no-tcp-cork; } syncer { rate 330M; al-extents 517; } } resource data { on data-1-1 { device /dev/drbd0; disk /dev/sdb1; address 10.0.10.7:7788; #此处为心跳网址 meta-disk /dev/sdb2 [0]; } on data-1-2 { device /dev/drbd0; disk /dev/sdb1; address 10.0.10.8:7788; meta-disk /dev/sdb2 [0]; } } (END)
初始化drbd:
drbdadm create-md data
启动drbd:
drbd up data
cat /proc/drbd 两边都是从,为正常状态 #cat /etc/hosts 这里记得添加两台主机的心跳网卡地址和主机名
指定data-1-1这台机器为主,将数据推到data-1-2(原机器上的数据会被覆盖掉):
drbdadmin -- --overwrite-data-of-peer primary data #只在data-1-1上执行
cat /proc/drbd #cs:连接状态,ro:角色,ds:磁盘状态(UpToDate代表同步完成,Inconsistent一般发生在没完成配置的时候暂未同步),ns:网络发送,nr:网络接收,dw:硬盘写入,dr:硬盘读
mkdir /data -p #创建用于存放数据的目录
mkfs -t ext4 -b 4096 /dev/drbd0 #只格式化主节点,备节点不需要格式化!会通过主节点同步~
mount /dev/drbd0 /data
可以在/data下放个文件对同步性进行测试,然后通过对二节点的mount与umount查看一下是否同步过去数据,此过程中不能有数据操作,否则两边不同步:
drbdadm down data
mount /dev/sdb1 /mnt
ll /mnt
umont /mnt
drbdadm up data
3)配合heartbeat调试drbd服务配置(#整个过程可在/var/log/ha-log中查看):
vi /etc/ha.cf
data-1-1 IPaddr::10.0.0.17/24/eth0 drbddisk::data Filesystem::/dev/drbd0::/data::ext4
启动heartbeat
/etc/init.d/heartbeat stop
chkconfig heartbeat off #记得关闭自启动
chkconfig drbd off #记得关闭自启动
/etc/init.d/heartbeat start
检查:
ip add|grep 10.0.0
cat /proc/drbd
df -h #检查/data挂没挂载上
若发生裂脑现象,一般是自动启动没有关,此时需在从上做如下处理:
drbdadm disconnect data
drbdadm -- --discard-my-data connect data
4)部署mysql
对于像mysql-5.5.32-linux2.6-x86_64.tar.gz这种二进制解压既可以使用的包
cd /home/oldboy/tools
实现mysql安装(可写成脚本执行)
#红色为放置mysql.cnf的脚本包
#(1)judge soft mkdir -p /home/oldboy/tools cd /home/oldboy/tools [ -f mysql-5.5.32-linux2.6-x86_64.tar.gz -a -f data-mysql.cnf.tar.gz ] || { echo "lost mysql soft, please check it." exit 1 } #(2)untar soft tar zxf mysql-5.5.32-linux2.6-x86_64.tar.gz mkdir -p /application/ /bin/mv mysql-5.5.32-linux2.6-x86_64.tar.gz /application/mysql-5.5.32 ln -s /application/mysql-5.5.32/ /application/mysql #(3)create mysql user groupadd mysql useradd -g mysql -M mysql #(4)init db and config my.cnf tar zxf data-mysql.cnf.tar.gz -C / find /data -name mysql -exc chmod 700 {} \; chown -R mysql.mysql /data /application/mysql/scripts/mysql_install_db --basedir=/application/mysql --datadir=/data/3306/data --user=mysql /application/mysql/scripts/mysql_install_db --basedir=/application/mysql --datadir=/data/3307/data --user=mysql #(5)start mysql sed -i 's#/usr/local/mysql#/application/mysql#g' /application/mysql/bin/mysqld_safe /data/3306/mysql start /data/3307/mysql start sleep 5 lsof -i :3306 lsof -i :3307 /bin/cp /application/mysql/bin/mysql* /usr/local/sbin mysqladmin -u root password 456 -S /data/3306/mysql.sock mysql -uroot -p456 -S /data/3306/mysql.sock mysqladmin -u root password 456 -S /data/3307/mysql.sock mysql -uroot -p456 -S /data/3307/mysql.sock
5)当发生故障时,若VIP已经切换过去,修复好后,需要靠一个参数来控制是否切换回来:
即heartbeat配置文件中的auto_failback on/off参数
6)对于故障切换时,要使mysql主节点下的从节点能够同时实现切换到mysql备节点,需利用VIP配置主从节点。
一键实现备份脚本
#!/bin/sh MYUSER=root MYPASS="oldboy123" MYSOCK=/data/3307/mysql.sock MAIN_PATH=/server/backup DATA_PATH=/server/backup LOG_FILE=${DATA_PATH}/mysqllogs_'date +%F'.log DATA_FILE=${DATA_PATH}/mysql_backup_'date +%F'.sql.gz MYSQL_PATH=/application/mysql/bin MYSQL_CMD="$MYSQL_PATH/mysql -u$MYUSER -p$MYPASS -S $MYSOCK" MYSQL_DUMP="$MYSQL_PATH/mysqldump -u$MYUSER -p$MYPASS -S $MYSOCK -A -B --flush-logs" [ ! -f $MAIN_PATH ] && mkdir -p $MAIN_PATH #以下部分生产环境中最好做成一个session,暂不建议在生产环境中用 [ '$MYSQL_CMD -e "select user,host from mysql.user"|grep rep|wc -l' -ne 1 ] &&\ $MYSQL_CMD -e "grant replication slave on *.* to 'rep'@'10.0.0.%' identified by 'oldboy123'" $MYSQL_CMD -e "flush tables with read lock;" echo "------show master status result------" >$LOG_FILE $MYSQL_CMD -e "show master status;" >>$LOG_FILE ${MYSQL_DUMP} | gzip >$DATA_FILE $MYSQL_CMD -e "unlock tables;" cat $LOG_FILE
一键配置mysql主从脚本(配置文件中需要配置为绑定在主节点3306上的VIP)
#!/bin/sh MYUSER=root MYPASS="oldboy123" MYSOCK=/data/3307/mysql.sock MAIN_PATH=/server/backup DATA_PATH=/server/backup LOG_FILE=${DATA_PATH}/mysqllogs_'date +%F'.log DATA_FILE=${DATA_PATH}/mysql_backup_'date +%F'.sql.gz MYSQL_PATH=/application/mysql/bin MYSQL_CMD="$MYSQL_PATH/mysql -u$MYUSER -p$MYPASS -S $MYSOCK" #recover cd ${DATA_PATH} && rm -f mysql_backup_'date +%F'.sql.gz gzip -d mysql_backup_'date +%F'.sql.gz $MYSQL_CMD < mysql_backup_'date +%F'.sql.gz #config slave cat |$MYSQL_CMD<< EOF CHANGE MASTER TO MASTER_HOST='10.0.0.17', MASTER_PORT=3306, MASTER_USER='rep', MASTER_PASSWORD='oldboy123', MASTER_LOG_FILE="'tail -1 $LOG_FILE|cut -f1'", MASTER_LOG_POS='tail -1 $LOG_FILE|cut -f2'; EOF $MYSQL_CMD -e "start slave;" #此部分可能没反应 $MYSQL_CMD -e "show slave status\G"|egrep "IO_Running|SQL_Running" >>$LOG_FILE #mail -s "mysql slave result" 209093099@qq.com < $LOG_FILE
对于多主多从高可用集群自动切换,切换前需确保以下四项内容正常:
1)ip add |grep 0.17 #即VIP正常
2)cat /proc/drbd
3)df -h #/dev/drbd0 /data挂载正常
4)lsof -i :3306 #数据库正常
停掉data-1-1服务器上的heartbeat,data-1-2会实现接管。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号