MySQL 之 索引原理与慢查询优化
浏览目录
1. 索引介绍
需求:
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。
说起加速查询,就不得不提到索引了。索引:
简单的说,相当于图书的目录,可以帮助用户快速的找到需要的内容.
在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。能够大大提高查询效率。特别是当数据量非常大,查询涉及多个表时,使用索引往往能使查询速度加快成千上万倍.
本质:
索引本质:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
2.索引方法
1. B+TREE 索引
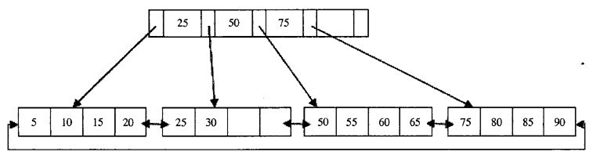
B+树是一种经典的数据结构,由平衡树和二叉查找树结合产生,它是为磁盘或其它直接存取辅助设备而设计的一种平衡查找树,在B+树中,所有的记录节点都是按键值大小顺序存放在同一层的叶节点中,叶节点间用指针相连,构成双向循环链表,非叶节点(根节点、枝节点)只存放键值,不存放实际数据。下面看一个2层B+树的例子:
注意:通常其高度都在2~3层,查询时可以有效减少IO次数。
系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一磁盘块中的数据会被一次性读取出来,而不是按需读取。InnoDB 存储引擎使用页作为数据读取单位,页是其磁盘管理的最小单位,默认 page 大小是 16kB。
b+树的查找过程
如图所示,如果要查找数据项30,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定30在28和65之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块由磁盘加载到内存,发生第二次IO,30在28和35之间,锁定当前磁盘块的P1指针,通过指针加载磁盘块到内存,发生第三次IO,同时内存中做二分查找找到30,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
强烈注意: 索引字段要尽量的小,磁盘块可以存储更多的索引.
2. HASH 索引
hash就是一种(key=>value)形式的键值对,允许多个key对应相同的value,但不允许一个key对应多个value,为某一列或几列建立hash索引,就会利用这一列或几列的值通过一定的算法计算出一个hash值,对应一行或几行数据. hash索引可以一次定位,不需要像树形索引那样逐层查找,因此具有极高的效率.
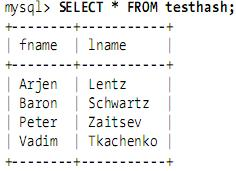
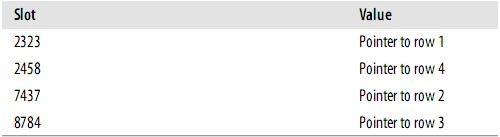
假设索引使用hash函数f( ),如下:
f('Arjen') = 2323 f('Baron') = 7437 f('Peter') = 8784 f('Vadim') = 2458此时,索引的结构大概如下:
![]()
3.HASH与BTREE比较:
hash类型的索引:查询单条快,范围查询慢 btree类型的索引:b+树,层数越多,数据量越大,范围查询和随机查询快(innodb默认索引类型) 不同的存储引擎支持的索引类型也不一样 InnoDB 支持事务,支持行级别锁定,支持 Btree、Hash 等索引,不支持Full-text 索引; MyISAM 不支持事务,支持表级别锁定,支持 Btree、Full-text 等索引,不支持 Hash 索引; Memory 不支持事务,支持表级别锁定,支持 Btree、Hash 等索引,不支持 Full-text 索引; NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 Btree、Full-text 等索引; Archive 不支持事务,支持表级别锁定,不支持 Btree、Hash、Full-text 等索引;
3.索引类型
MySQL中常见索引有:
- 普通索引
- 唯一索引
- 主键索引
- 组合索引
1.普通索引
普通索引仅有一个功能:加速查询
![]() 创建表+索引#创建表同时添加name字段为普通索引 create table tb1( id int not null auto_increment primary key, name varchar(100) not null, index idx_name(name) );
创建表+索引#创建表同时添加name字段为普通索引 create table tb1( id int not null auto_increment primary key, name varchar(100) not null, index idx_name(name) );![]() 创建索引
创建索引#单独为表指定普通索引 create index idx_name on tb1(name);![]() 删除索引drop index idx_name on tb1;
删除索引drop index idx_name on tb1;![]() 查看索引
查看索引show index from tb1;
![]() 查看索引 列介绍1、Table 表的名称。 2、 Non_unique 如果索引为唯一索引,则为0,如果可以则为1。 3、 Key_name 索引的名称 4、 Seq_in_index 索引中的列序列号,从1开始。 5、 Column_name 列名称。 6、 Collation 列以什么方式存储在索引中。在MySQL中,有值‘A’(升序)或NULL(无分类)。 7、Cardinality 索引中唯一值的数目的估计值。 8、Sub_part 如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。 9、 Packed 指示关键字如何被压缩。如果没有被压缩,则为NULL。 10、 Null 如果列含有NULL,则含有YES。如果没有,则该列含有NO。 11、 Index_type 用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。 12、 Comment 多种评注
查看索引 列介绍1、Table 表的名称。 2、 Non_unique 如果索引为唯一索引,则为0,如果可以则为1。 3、 Key_name 索引的名称 4、 Seq_in_index 索引中的列序列号,从1开始。 5、 Column_name 列名称。 6、 Collation 列以什么方式存储在索引中。在MySQL中,有值‘A’(升序)或NULL(无分类)。 7、Cardinality 索引中唯一值的数目的估计值。 8、Sub_part 如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。 9、 Packed 指示关键字如何被压缩。如果没有被压缩,则为NULL。 10、 Null 如果列含有NULL,则含有YES。如果没有,则该列含有NO。 11、 Index_type 用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。 12、 Comment 多种评注2.唯一索引
唯一索引有两个功能:加速查询 和 唯一约束(可含一个null 值)
![]() 创建表+唯一(unique)索引create table tb2( id int not null auto_increment primary key, name varchar(50) not null, age int not null, unique index idx_age (age) )
创建表+唯一(unique)索引create table tb2( id int not null auto_increment primary key, name varchar(50) not null, age int not null, unique index idx_age (age) )![]() 创建unique索引create unique index idx_age on tb2(age);
创建unique索引create unique index idx_age on tb2(age);3.主键索引
主键有两个功能:加速查询 和 唯一约束(不可含null)
注意:一个表中最多只能有一个主键索引
![]() 创建表 + 创建主键#方式一: create table tb3( id int not null auto_increment primary key, name varchar(50) not null, age int default 0 ); #方式二: create table tb3( id int not null auto_increment, name varchar(50) not null, age int default 0 , primary key(id) );
创建表 + 创建主键#方式一: create table tb3( id int not null auto_increment primary key, name varchar(50) not null, age int default 0 ); #方式二: create table tb3( id int not null auto_increment, name varchar(50) not null, age int default 0 , primary key(id) );![]() 创建主键alter table tb3 add primary key(id);
创建主键alter table tb3 add primary key(id);![]() 删除主键#方式一 alter table tb3 drop primary key; #方式二: #如果当前主键为自增主键,则不能直接删除.需要先修改自增属性,再删除 alter table tb3 modify id int ,drop primary key;
删除主键#方式一 alter table tb3 drop primary key; #方式二: #如果当前主键为自增主键,则不能直接删除.需要先修改自增属性,再删除 alter table tb3 modify id int ,drop primary key;4.组合索引
组合索引是将n个列组合成一个索引
其应用场景为:频繁的同时使用n列来进行查询,如:where n1 = 'alex' and n2 = 666。
![]() 创建表+组合索引create table tb4( id int not null , name varchar(50) not null, age int not null, index idx_name_age (name,age) )
创建表+组合索引create table tb4( id int not null , name varchar(50) not null, age int not null, index idx_name_age (name,age) )![]() 创建组合索引create index idx_name_age on tb4(name,age);
创建组合索引create index idx_name_age on tb4(name,age);
![]() 索引应用场景举个例子来说,比如你在为某商场做一个会员卡的系统。 这个系统有一个会员表 有下列字段: 会员编号 INT 会员姓名 VARCHAR(10) 会员身份证号码 VARCHAR(18) 会员电话 VARCHAR(10) 会员住址 VARCHAR(50) 会员备注信息 TEXT 那么这个 会员编号,作为主键,使用 PRIMARY 会员姓名 如果要建索引的话,那么就是普通的 INDEX 会员身份证号码 如果要建索引的话,那么可以选择 UNIQUE (唯一的,不允许重复)
索引应用场景举个例子来说,比如你在为某商场做一个会员卡的系统。 这个系统有一个会员表 有下列字段: 会员编号 INT 会员姓名 VARCHAR(10) 会员身份证号码 VARCHAR(18) 会员电话 VARCHAR(10) 会员住址 VARCHAR(50) 会员备注信息 TEXT 那么这个 会员编号,作为主键,使用 PRIMARY 会员姓名 如果要建索引的话,那么就是普通的 INDEX 会员身份证号码 如果要建索引的话,那么可以选择 UNIQUE (唯一的,不允许重复)


4.聚合索引和辅助索引
数据库中的B+树索引可以分为聚集索引和辅助索引.
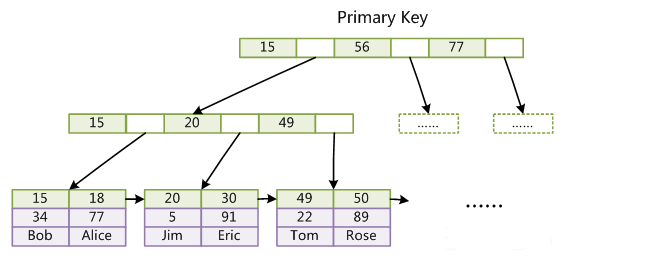
聚集索引:InnoDB表 索引组织表,即表中数据按主键B+树存放,叶子节点直接存放整条数据,每张表只能有一个聚集索引。
如图:
1.当你定义一个主键时,InnnodDB存储引擎则把它当做聚集索引
2.如果你没有定义一个主键,则InnoDB定位到第一个唯一索引,且该索引的所有列值均飞空的,则将其当做聚集索引。
3如果表没有主键或合适的唯一索引INNODB会产生一个隐藏的行ID值6字节的行ID聚集索引,
补充:由于实际的数据页只能按照一颗B+树进行排序,因此每张表只能有一个聚集索引,聚集索引对于主键的排序和范围查找非常有利.
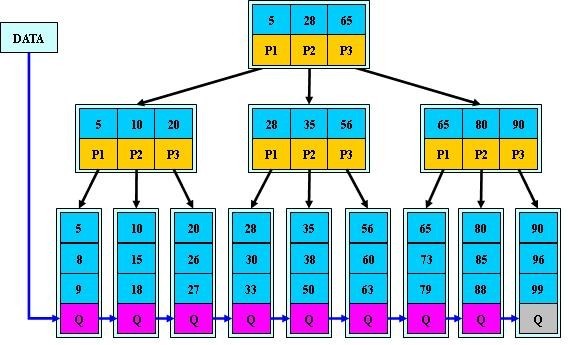
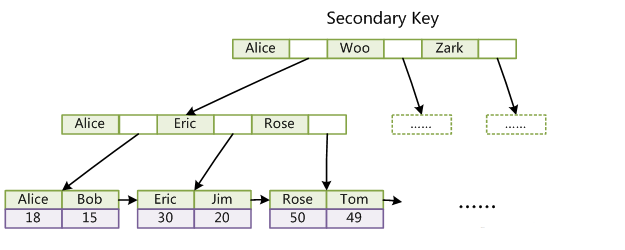
辅助索引:(也称非聚集索引)是指叶节点不包含行的全部数据,叶节点除了包含键值之外,还包含一个书签连接,通过该书签再去找相应的行数据。下图显示了
InnoDB存储引擎辅助索引获得数据的查找方式:
从上图中可以看出,辅助索引叶节点存放的是主键值,获得主键值后,再从聚集索引中查找整行数据。举个例子,如果在一颗高度为3的辅助索引中查找数据,首先从辅助索引中获得主键值(3次IO),接着从高度为3的聚集索引中查找以获得整行数据(3次IO),总共需6次IO。一个表上可以存在多个辅助索引。总结二者区别:
相同的是:不管是聚集索引还是辅助索引,其内部都是B+树的形式,即高度是平衡的,叶子结点存放着所有的数据。
不同的是:聚集索引叶子结点存放的是一整行的信息,而辅助索引叶子结点存放的是单个索引列信息.
何时使用聚集索引或非聚集索引
下面的表总结了何时使用聚集索引或非聚集索引(很重要):
动作描述
使用聚集索引
使用非聚集索引
列经常被分组排序
应
应
返回某范围内的数据
应
不应
一个或极少不同值
不应
不应
频繁更新的列
不应
应
外键列
应
应
主键列
应
应
频繁修改索引列
不应
应
5.测试索引
1.创建数据
![]() 创建表-- 1.创建表 CREATE TABLE userInfo( id int NOT NULL, name VARCHAR(16) DEFAULT NULL, age int, sex char(1) not null, email varchar(64) default null )ENGINE=MYISAM DEFAULT CHARSET=utf8;
创建表-- 1.创建表 CREATE TABLE userInfo( id int NOT NULL, name VARCHAR(16) DEFAULT NULL, age int, sex char(1) not null, email varchar(64) default null )ENGINE=MYISAM DEFAULT CHARSET=utf8;注意:MYISAM存储引擎 不产生引擎事务,数据插入速度极快,为方便快速插入测试数据,等我们插完数据,再把存储类型修改为InnoDB
2.创建存储过程,插入数据
![]() 创建存储过程-- 2.创建存储过程 delimiter$$ CREATE PROCEDURE insert_user_info(IN num INT) BEGIN DECLARE val INT DEFAULT 0; DECLARE n INT DEFAULT 1; -- 循环进行数据插入 WHILE n <= num DO set val = rand()*50; INSERT INTO userInfo(id,name,age,sex,email)values(n,concat('alex',val),rand()*50,if(val%2=0,'女','男'),concat('alex',n,'@qq.com')); set n=n+1; end while; END $$ delimiter;
创建存储过程-- 2.创建存储过程 delimiter$$ CREATE PROCEDURE insert_user_info(IN num INT) BEGIN DECLARE val INT DEFAULT 0; DECLARE n INT DEFAULT 1; -- 循环进行数据插入 WHILE n <= num DO set val = rand()*50; INSERT INTO userInfo(id,name,age,sex,email)values(n,concat('alex',val),rand()*50,if(val%2=0,'女','男'),concat('alex',n,'@qq.com')); set n=n+1; end while; END $$ delimiter;3.调用存储过程,插入500万条数据
call insert_user_info(5000000);
4.此步骤可以忽略。修改引擎为INNODB
ALTER TABLE userinfo ENGINE=INNODB;
5.测试索引
1. 在没有索引的前提下测试查询速度
SELECT * FROM userinfo WHERE id = 4567890;注意:无索引情况,mysql根本就不知道id等于4567890的记录在哪里,只能把数据表从头到尾扫描一遍,此时有多少个磁盘块就需要进行多少IO操作,所以查询速度很慢.2.在表中已经存在大量数据的前提下,为某个字段段建立索引,建立速度会很慢
CREATE INDEX idx_id on userinfo(id);
3.在索引建立完毕后,以该字段为查询条件时,查询速度提升明显
select * from userinfo where id = 4567890;
注意:
1. mysql先去索引表里根据b+树的搜索原理很快搜索到id为4567890的数据,IO大大降低,因而速度明显提升
2. 我们可以去mysql的data目录下找到该表,可以看到添加索引后该表占用的硬盘空间多了
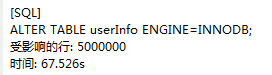
3.如果使用没有添加索引的字段进行条件查询,速度依旧会很慢(如图:)





6.正确使用索引
数据库表中添加索引后确实会让查询速度起飞,但前提必须是正确的使用索引来查询,如果以错误的方式使用,则即使建立索引也会不奏效。
即使建立索引,索引也不会生效,例如:#1. 范围查询(>、>=、<、<=、!= 、between...and) #1. = 等号 select count(*) from userinfo where id = 1000 -- 执行索引,索引效率高 #2. > >= < <= between...and 区间查询 select count(*) from userinfo where id <100; -- 执行索引,区间范围越小,索引效率越高 select count(*) from userinfo where id >100; -- 执行索引,区间范围越大,索引效率越低 select count(*) from userinfo where id between 10 and 500000; -- 执行索引,区间范围越大,索引效率越低 #3. != 不等于 select count(*) from userinfo where id != 1000; -- 索引范围大,索引效率低 #2.like '%xx%' #为 name 字段添加索引 create index idx_name on userinfo(name); select count(*) from userinfo where name like '%xxxx%'; -- 全模糊查询,索引效率低 select count(*) from userinfo where name like '%xxxx'; -- 以什么结尾模糊查询,索引效率低 #例外: 当like使用以什么开头会索引使用率高 select * from userinfo where name like 'xxxx%'; #3. or select count(*) from userinfo where id = 12334 or email ='xxxx'; -- email不是索引字段,索引此查询全表扫描 #例外:当or条件中有未建立索引的列才失效,以下会走索引 select count(*) from userinfo where id = 12334 or name = 'alex3'; -- id 和 name 都为索引字段时, or条件也会执行索引 #4.使用函数 select count(*) from userinfo where reverse(name) = '5xela'; -- name索引字段,使用函数时,索引失效 #例外:索引字段对应的值可以使用函数,我们可以改为一下形式 select count(*) from userinfo where name = reverse('5xela'); #5.类型不一致 #如果列是字符串类型,传入条件是必须用引号引起来,不然... select count(*) from userinfo where name = 454; #类型一致 select count(*) from userinfo where name = '454'; #6.order by #排序条件为索引,则select字段必须也是索引字段,否则无法命中 select email from userinfo ORDER BY name DESC; -- 无法命中索引 select name from userinfo ORDER BY name DESC; -- 命中索引 #特别的:如果对主键排序,则还是速度很快: select id from userinfo order by id desc;
7.组合索引
组合索引: 是指对表上的多个列组合起来做一个索引.
组合索引好处:简单的说有两个主要原因:
- "一个顶三个"。建了一个(a,b,c)的组合索引,那么实际等于建了(a),(a,b),(a,b,c)三个索引,因为每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,这可是不小的开销!
- 索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select * from table where a = 1 and b =2 and c = 3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W*10%=100w 条数据,然后再回表从100w条数据中找到符合b=2 and c= 3的数据,然后再排序,再分页;如果是组合索引,通过索引筛选出1000w *10% *10% *10%=1w,然后再排序、分页,哪个更高效,一眼便知
最左匹配原则: 从左往右依次使用生效,如果中间某个索引没有使用,那么断点前面的索引部分起作用,断点后面的索引没有起作用;select * from mytable where a=3 and b=5 and c=4; #abc三个索引都在where条件里面用到了,而且都发挥了作用
select * from mytable where c=4 and b=6 and a=3; #这条语句列出来只想说明 mysql没有那么笨,where里面的条件顺序在查询之前会被mysql自动优化,效果跟上一句一样
select * from mytable where a=3 and c=7; #a用到索引,b没有用,所以c是没有用到索引效果的
select * from mytable where a=3 and b>7 and c=3; #a用到了,b也用到了,c没有用到,这个地方b是范围值,也算断点,只不过自身用到了索引
select * from mytable where b=3 and c=4; #因为a索引没有使用,所以这里 bc都没有用上索引效果
select * from mytable where a>4 and b=7 and c=9; #a用到了 b没有使用,c没有使用
select * from mytable where a=3 order by b; #a用到了索引,b在结果排序中也用到了索引的效果
select * from mytable where a=3 order by c; #a用到了索引,但是这个地方c没有发挥排序效果,因为中间断点了
select * from mytable where b=3 order by a; #b没有用到索引,排序中a也没有发挥索引效果
8.注意事项
1. 避免使用select * 2. 其他数据库中使用count(1)或count(列) 代替 count(*),而mysql数据库中count(*)经过优化后,效率与前两种基本一样. 3. 创建表时尽量时 char 代替 varchar 4. 表的字段顺序固定长度的字段优先 5. 组合索引代替多个单列索引(经常使用多个条件查询时) 6. 使用连接(JOIN)来代替子查询(Sub-Queries) 7. 不要有超过4个以上的表连接(JOIN) 8. 优先执行那些能够大量减少结果的连接。 9. 连表时注意条件类型需一致 10.索引散列值不适合建索引,例:性别不适合
9.查询计划
explain + 查询SQL - 用于显示SQL执行信息参数,根据参考信息可以进行SQL优化
explain select count(*) from userinfo where id = 1;
执行计划:让mysql预估执行操作(一般正确) type : 查询计划的连接类型, 有多个参数,先从最佳类型到最差类型介绍
性能: null > system/const > eq_ref > ref > ref_or_null > index_merge > range > index > all 慢: explain select * from userinfo where email='alex'; type: ALL(全表扫描) 特别的: select * from userinfo limit 1; 快: explain select * from userinfo where name='alex'; type: ref(走索引)EXPLAIN 参数详解: http://www.cnblogs.com/wangfengming/articles/8275448.html

10.慢日志查询
慢查询日志
将mysql服务器中影响数据库性能的相关SQL语句记录到日志文件,通过对这些特殊的SQL语句分析,改进以达到提高数据库性能的目的。
慢查询日志参数:
long_query_time : 设定慢查询的阀值,超出设定值的SQL即被记录到慢查询日志,缺省值为10s slow_query_log : 指定是否开启慢查询日志 log_slow_queries : 指定是否开启慢查询日志(该参数已经被slow_query_log取代,做兼容性保留) slow_query_log_file : 指定慢日志文件存放位置,可以为空,系统会给一个缺省的文件host_name-slow.log log_queries_not_using_indexes: 如果值设置为ON,则会记录所有没有利用索引的查询.查看 MySQL慢日志信息
#.查询慢日志配置信息 : show variables like '%query%'; #.修改配置信息 set global slow_query_log = on;查看不使用索引参数状态:
# 显示参数 show variables like '%log_queries_not_using_indexes'; # 开启状态 set global log_queries_not_using_indexes = on;查看慢日志显示的方式
#查看慢日志记录的方式 show variables like '%log_output%'; #设置慢日志在文件和表中同时记录 set global log_output='FILE,TABLE';测试慢查询日志
#查询时间超过10秒就会记录到慢查询日志中 select sleep(3) FROM user ; #查看表中的日志 select * from mysql.slow_log;
11.大数据量分页优化
执行此段代码:
select * from userinfo limit 3000000,10;优化方案:
一. 简单粗暴,就是不允许查看这么靠后的数据,比如百度就是这样的
最多翻到72页就不让你翻了,这种方式就是从业务上解决;
二.在查询下一页时把上一页的行id作为参数传递给客户端程序,然后sql就改成了
select * from userinfo where id>3000000 limit 10;这条语句执行也是在毫秒级完成的,id>300w其实就是让mysql直接跳到这里了,不用依次在扫描全面所有的行
如果你的table的主键id是自增的,并且中间没有删除和断点,那么还有一种方式,比如100页的10条数据
select * from userinfo where id>100*10 limit 10;
三.最后第三种方法:延迟关联
我们在来分析一下这条语句为什么慢,慢在哪里。
select * from userinfo limit 3000000,10;玄机就处在这个 * 里面,这个表除了id主键肯定还有其他字段 比如 name age 之类的,因为select * 所以mysql在沿着id主键走的时候要回行拿数据,走一下拿一下数据;
如果把语句改成
select id from userinfo limit 3000000,10;你会发现时间缩短了一半;然后我们在拿id分别去取10条数据就行了;
语句就改成这样了:
select table.* from userinfo inner join ( select id from userinfo limit 3000000,10 ) as tmp on tmp.id=userinfo.id;这三种方法最先考虑第一种 其次第二种,第三种是别无选择


 浙公网安备 33010602011771号
浙公网安备 33010602011771号