
C++11 FAQ 阅读笔记
总体来看, c++11 从 5 方面进行了改善:
- 语言更加严谨: (nullptr, enumClass, initializerList, override)
- 语法更加便利: (auto, R"()", lambda, non static const member variable initialization)
- 更大灵活性: (userDefinedLiterals)
- 更加强大的底层控制: (alignas, alignof)
- 更强大的库: (regex, 异步, 线程)
auto
The use of auto to deduce the type of a variable from its initializer is obviously most useful when that type is either hard to know exactly or hard to write.
template<class T, class U> void multiply(const vector<T>& vt, const vector<U>& vu) { // ... auto tmp = vt[i]*vu[i]; // 当你遇到这样的情况, auto 就凸显其作用. // ... }
enum class
不再是 int.
增加了作用域, 非常好.
The underlying type must be one of the signed or unsigned integer types; the default is int.
constexpr
const: primary function is to express the idea that an object is not modified.
constexpr: primary function is to extend the range of what can be computed at compile time, making such computation type safe.
因此, 该关键字可作为 '#define MAX_PATH (255)' 的替代品.
initializer_list
map<vector<string>,vector<int>> years = { { {"Maurice","Vincent", "Wilkes"},{1913, 1945, 1951, 1967, 2000} }, { {"Martin", "Ritchards"}, {1982, 2003, 2007} }, { {"David", "John", "Wheeler"}, {1927, 1947, 1951, 2004} } };
years.insert({{"Bjarne","Stroustrup"},{1950, 1975, 1985}});
void f(initializer_list<int>); f({1,2}); f({23,345,4567,56789}); f({}); // the empty list
template<class E> class vector
{ public: vector (std::initializer_list<E> s) // initializer-list constructor { reserve(s.size()); // get the right amount of space uninitialized_copy(s.begin(), s.end(), elem); // initialize elements (in elem[0:s.size())) sz = s.size(); // set vector size } // ... as before ... };
方便的不用解释.
但是要注意这种新语法:
char x3{7}; // char x3 = 7;
Delegating constructors
class T { // data. int m_x = 0, m_y = 0, m_sum = 0; public: T() : T(0, 0) // Using delegate constructor. {}; T(int x, int y) : m_x(x), m_y(y) { // ... } };
免去我们为了在多个 ctors 中初始化相同的变量而创建的 init() 函数.
In-class member initializer
// Dirty, urgly. class A { public: A(): a(7), b(5), hash_algorithm("MD5"), s("Constructor run") {} A(int a_val) : a(a_val), b(5), hash_algorithm("MD5"), s("Constructor run") {} A(D d) : a(7), b(g(d)), hash_algorithm("MD5"), s("Constructor run") {} int a, b; private: HashingFunction hash_algorithm; // Cryptographic hash to be applied to all A instances std::string s; // String indicating state in object lifecycle };
// Clear, elegant. class A { public: A() {} A(int a_val) : a(a_val) {} A(D d) : b(g(d)) {} int a = 7; int b = 5; private: HashingFunction hash_algorithm{"MD5"}; // Cryptographic hash to be applied to all A instances std::string s{"Constructor run"}; // String indicating state in object lifecycle };
更优雅的语法.
static_assert
static_assert(sizeof(size_t) == 4, "32 bit machine."); static_assert(sizeof(size_t) == 8, "64 bit machine.");
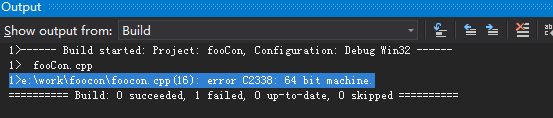
判断常量的真假, 并在编译时期报错.
nullptr
指针类型, 不能和整数进行比较.
代替 NULL 这个 C 语言遗留的诟病. 今后会消灭很多潜在的 bug.
decltype
// Ugly! template<class T, class U> ??? mul(T x, U y) { return x*y; } // Pretty! template<class T, class U> auto mul(T x, U y) -> decltype(x*y) { return x*y; }
解决了一些遗留的语法死角.
using
template <typename N> class T {}; // typedef 无法完成. template <typename N> using F = T<N>;
一种新的语法.
R"(...)"
Raw string literals 极大的方便了编写正则表达式的程序.
为了更特殊的情况, 新标准允许我们使用 R"***(here is string ilterals.)***", 即在 " 和 ( 之间加入一些字符, 当作边界.
User-defined literal
constexpr XX operator"" name(unsigned long long n) {} constexpr XX operator"" name(long double d) {} constexpr XX operator"" name(char c) {} constexpr XX operator"" name(const char* str, size_t sz) {} constexpr XX operator"" name(const char* cstr) {} unsigned operator"" _B(const char *bin) // "" 和 'name' 之间必须有空格. { // 'name' 是需要 prefix '_'. 因为没有 prefix '_' 的 'name' 是保留给 C++ 扩展的. // ... } ... auto bin = 1001_B; // 数字必须紧邻 suffix. bin == 9; // true.
只有上述五种重载形式.
不能重载已有的 'name'.
constexpr 不是必要的, 但是所有常量都可以在 compile-time 进行求值. 这有利于 compiler 的优化.
更大的灵活性.
推荐阅读:
http://akrzemi1.wordpress.com/2013/01/04/preconditions-part-i/
http://akrzemi1.wordpress.com/2012/10/23/user-defined-literals-part-ii/
http://akrzemi1.wordpress.com/2012/10/29/user-defined-literals-part-iii/
Lambda
A lambda expression is a mechanism for specifying a function object.
The primary use for a lambda is to specify a simple action to be performed by some function.
[] no capture.
[=] by value.
[&] by reference.
极大方便了日常编程.
Local types as template arguments
void f(vector<X>& v) { struct Less { bool operator()(const X& a, const X& b) { return a.v<b.v; } }; sort(v.begin(), v.end(), Less()); // C++98: error: Less is local // C++11: ok }
那些只在某个函数中有用的 struct, 别让他们弄脏你的代码.
noexcept
noexcept() operator is a constant expression and does not evaluate its operand.
If a function declared noexcept throws (so that the exception tries to escape the noexceptfunction) the program is terminated (by a call to terminate()). The call of terminate() cannot rely on objects being in well-defined states (i.e. there is no guarantees that destructors have been invoked, no guaranteed stack unwinding, and no possibility for resuming the program as if no problem had been encountered). This is deliberate and makes noexcept a simple, crude, and very efficient mechanism (much more efficient than the old dynamic throw() mechanism).
alignas & alignof
alignas(double) unsigned char c[1024]; // array of characters, suitably aligned for doubles constexpr int n = alignof(int); // ints are aligned on n byte boundaries
强大的底层控制.
override & final
struct B { virtual void f(); virtual void g() const; virtual void h(char); void k(); // not virtual virtual void i() const final;// do not override }; struct D : B { void f() override; // OK: overrides B::f() void g() override; // error: wrong type virtual void h(char); // overrides B::h(); likely warning void k() override; // error: B::k() is not virtual void f() const; // error: D::f attempts to override final B::f };
语法更加严谨.
这两个关键字是 contextual keyword, 因只有在 member function 的声明中才是关键字. 因此你可以定义同名的变量.
New algorithm
bool all_of(Iter first, Iter last, Pred pred); bool any_of(Iter first, Iter last, Pred pred); bool none_of(Iter first, Iter last, Pred pred); Iter find_if_not(Iter first, Iter last, Pred pred); OutIter copy_if(InIter first, InIter last, OutIter result, Pred pred); OutIter copy_n(InIter first, InIter::difference_type n, OutIter result); OutIter move(InIter first, InIter last, OutIter result); OutIter move_backward(InIter first, InIter last, OutIter result); pair<OutIter1, OutIter2> partition_copy(InIter first, InIter last, OutIter1 out_true, OutIter2 out_false, Pred pred); Iter partition_point(Iter first, Iter last, Pred pred); RAIter partial_sort_copy(InIter first, InIter last, RAIter result_first, RAIter result_last); RAIter partial_sort_copy(InIter first, InIter last, RAIter result_first, RAIter result_last, Compare comp); bool is_sorted(Iter first, Iter last); bool is_sorted(Iter first, Iter last, Compare comp); Iter is_sorted_until(Iter first, Iter last); Iter is_sorted_until(Iter first, Iter last, Compare comp); bool is_heap(Iter first, Iter last); bool is_heap(Iter first, Iter last, Compare comp); Iter is_heap_until(Iter first, Iter last); Iter is_heap_until(Iter first, Iter last, Compare comp); T min(initializer_list<T> t); T min(initializer_list<T> t, Compare comp); T max(initializer_list<T> t); T max(initializer_list<T> t, Compare comp); pair<const T&, const T&> minmax(const T& a, const T& b); pair<const T&, const T&> minmax(const T& a, const T& b, Compare comp); pair<const T&, const T&> minmax(initializer_list<T> t); pair<const T&, const T&> minmax(initializer_list<T> t, Compare comp); pair<Iter, Iter> minmax_element(Iter first, Iter last); pair<Iter, Iter> minmax_element(Iter first, Iter last, Compare comp); void iota(Iter first, Iter last, T value); // For each element referred to by the iterator i in the range [first,last), assigns *i = value and increments value as if by ++value
使用 stl algorithm 提高自己的效率.
array
这可以使我们忘记 int arr[].
统一语法.
Unordered containers
unordered_map
unordered_set
unordered_multimap
unordered_multiset
简言之, map 使用 "<" 进行比较, 而 unordered_map 则使用 hash 算法.
对于大型数据结构, 进行一次 lookup, map 进行 log2(size) 次比较, 而 unordered_map 只进行一次 hash 算法.
std::function & std::bind
int f(int,char,double); auto frev = bind(f,_3,_2,_1); // reverse argument order. 注意这里的 '_1, _2, _3'. 详情: http://en.cppreference.com/w/cpp/utility/functional/placeholders int x = frev(1.2,'c',7); // f(7,'c',1.2);
bind produce a function object with one or more of the arguments of the argument function ``bound'' or rearranged.
function is a type that can hold a value of just about anything you can invoke using the (...)syntax.
unique_ptr
works with standard algorithm.
thread
void f(vector<double>&); struct F { vector<double>& v; F(vector<double>& vv) :v{vv} { } void operator()(); }; int main() { std::thread t1{std::bind(f,some_vec)}; // f(some_vec) executes in separate thread std::thread t2{F(some_vec)}; // F(some_vec)() executes in separate thread t1.join(); t2.detach(); }
必须调用 join(等待线程结束) 或者 detach(让该线程单独运行). 在线程结束时才能正常释放资源.
没办法让它停下.
mutex
一个线程 lock, 其它线程 lock 会 block.
同一线程 lock 会引发异常.
避免 lock 导致的 block, 可使用 try_lock, 返回 true 表示获得锁, 否则返回 false.
程序结束没有 unlock 则会引发异常.
uncopiable and unmovable.
recursive_mutex
同一线程可多次获得锁.
多次 lock 需要多次 unlock.
timed_mutex
std::timed_mutex m; int sh; // shared data // ... if (m.try_lock_for(std::chrono::seconds(10))) { // manipulate shared data: sh+=1; m.unlock(); } else { // we didn't get the mutex; do something else }
带 timeout 的 mutex.
unique_lock
std::mutex m; int sh; // shared data // ... void f() { // ... std::unique_lock lck(m,std::defer_lock); // make a lock, but don't acquire the mutex // ... if (lck.try_lock()) { // manipulate shared data: sh+=1; } else { // maybe do something else } }
What you get from using a lock rather than the mutex directly is exception handling and protection against forgetting to unlock().
Time utility
等研究详细后补充.
future
X v = f.get(); // if necessary wait for the value to get computed if (f.wait_for(0)) { // there is a value to get() // do something } else { // do something else }
Note that you can call get() only once, because get() invalidates the future’s state.
从异步执行的过程中等待结果.
packaged_task
double compute (int x, int y); std::packaged_task<double(int,int)> task(compute); // create a task std::future<double> f = task.get_future(); // get its future ... task(7,5); // start the task (typically in a separate thread) ... double res = f.get(); // wait for its end and process result/exception
提供了和 async 一样的能力, 但是不需要立即执行.
promise
待补充.
async
template<class T, class V> struct Accum { // simple accumulator function object T* b; T* e; V val; Accum(T* bb, T* ee, const V& v) : b{bb}, e{ee}, val{vv} {} V operator() () { return std::accumulate(b,e,val); } }; double comp(vector<double>& v) // spawn many tasks if v is large enough { if (v.size()<10000) return std::accumulate(v.begin(),v.end(),0.0); auto f0 {async(Accum{&v[0],&v[v.size()/4],0.0})}; auto f1 {async(Accum{&v[v.size()/4],&v[v.size()/2],0.0})}; auto f2 {async(Accum{&v[v.size()/2],&v[v.size()*3/4],0.0})}; auto f3 {async(Accum{&v[v.size()*3/4],&v[v.size()],0.0})}; return f0.get()+f1.get()+f2.get()+f3.get(); }
多么 easy & powerful 代码.
The idea behind async() is to provide a simple way to handle the simplest, rather common, case and leave the more complex examples to the fully general mechanism.
random number
uniform_int_distribution<int> one_to_six {1,6}; // distribution that maps to the ints 1..6 default_random_engine re {}; // the default engine int x = one_to_six(re); // x becomes a value in [1:6]
A random number generator consists of two parts an engine that produces a sequence of random or pseudo-random values and a distribution that maps those values in to a mathematical distribution in a range.
regular expression
typedef basic_regex<char> regex; typedef basic_regex<wchar_t> wregex; typedef match_results<const char*> cmatch; typedef match_results<const wchar_t*> wcmatch; typedef match_results<string::const_iterator> smatch; typedef match_results<wstring::const_iterator> wsmatch; typedef sub_match<const char*> csub_match; typedef sub_match<const wchar_t*> wcsub_match; typedef sub_match<string::const_iterator> ssub_match; typedef sub_match<wstring::const_iterator> wssub_match;
Other symbols:
$1: What matches the first capture group
$2: What matches the second capture group
$&: What matches the whole regular expression
$`: What appears before the whole regex
$': What appears after the whole regex
$$: $
[:alnum:] [:cntrl:] [:lower:] [:space:]
[:alpha:] [:digit:] [:print:] [:upper:]
[:blank:] [:graph:] [:punct:] [:xdigit:]
Basics:
const string &str = "1234-abcd-ABCD"; // 1. // Note that regex_search can successfully match any subsequence of the // given sequence, whereas std::regex_match will only return true if the // regular expression matches the entire sequence. regex_match(str, regex("[[:digit:]]+")); // 0. regex_search(str, regex("[[:digit:]]+")); // 1. // 2. Ignore case. smatch res; regex_search(str, regex("[a-z]+$")); // . regex_search(str, regex("[a-z]+$", regex::icase)); // ABCD. // 3. regex_replace(str, regex("[[:digit:]]"), "x"); // xxxx-abcd-ABCD. // 4. regex_replace(str, regex("^(.+)-(.+)-(.+)$"), "$3-$2-$1"); // ABCD-abcd-1234.
Advance:
const string &str = "c:\\windows\\system32\\foo.dll"; // 1. "\" needs R"(\\)". Even in "[]", you have to write 'R"([\\])"'. regex_replace(str, regex("\\\\"), "/"); // c:/windows/system32/foo.dll // 2. Lazy expression. regex_search(str, regex(".+\\\\")); // c:\windows\system32\. regex_search(str, regex(".+?\\\\")); // c:\. // 3. Repeat. Do NOT support "{x, y}". regex_search(str, regex("o{2}")); // oo. Equal to 'regex("oo")'.
有关 Unicode 的正则, 请看这里: http://www.unicode.org/reports/tr18/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号