


深入浅出的javascript的正则表达式学习教程
2015-12-11 00:29 龙恩0707 阅读(33758) 评论(11) 收藏 举报深入浅出的javascript的正则表达式学习教程
阅读目录
- 了解正则表达式的方法
- 了解正则中的普通字符
- 了解正则中的方括号[]的含义
- 理解javascript中的元字符
- RegExp特殊字符中的需要转义字符
- 了解量词
- 贪婪模式与非贪婪模式讲解
- 理解正则表达式匹配原理
- 理解正则表达式----环视
- 理解正则表达式---捕获组
- 理解非捕获性分组
- 反向引用详细讲解
- 正则表达式实战
了解正则表达式的方法
RegExp对象表示正则表达式,它是对字符串执行模式匹配的工具;
正则表达式的基本语法如下2种:
- 直接量语法:
/pattern/attributes;
2. 创建RegExp对象的语法
new RegExp(pattern,attributes);
参数:参数pattern是一个字符串,指定了正则表达式的模式;参数attributes是一个可选的参数,包含属性 g,i,m,分别使用与全局匹配,不区分大小写匹配,多行匹配;
@return 返回值:一个新的RegExp对象,具有指定的模式和标志;
1-1. 支持正则表达式的String对象的方法
1. search()方法;该方法用于检索字符串中指定的子字符串,或检索与正 则表达式相匹配的字符串。
基本语法:stringObject.search(regexp);
@param 参数regexp可以需要在stringObject中检索的字符串,也可以 是需要检索的RegExp对象。
@return(返回值) stringObject中第一个与regexp对象相匹配的子串的起 始位置。如果没有找到任何匹配的子串,则返回-1;
注意:search()方法不执行全局匹配,它将忽略标志g,同时它也没有regexp对象的lastIndex的属性,且总是从字符串开始位置进行查找,总是返回的是stringObject匹配的第一个位置。
测试demo如下:
var str = "hello world,hello world"; // 返回匹配到的第一个位置(使用的regexp对象检索) console.log(str.search(/hello/)); // 0 // 没有全局的概念 总是返回匹配到的第一个位置 console.log(str.search(/hello/g)); //0 console.log(str.search(/world/)); // 6 // 也可以是检索字符串中的字符 console.log(str.search("wo")); // 6 // 如果没有检索到的话,则返回-1 console.log(str.search(/longen/)); // -1 // 我们检索的时候 可以忽略大小写来检索 var str2 = "Hello"; console.log(str2.search(/hello/i)); // 0
2. match()方法;该方法用于在字符串内检索指定的值,或找到一个或者多个正则表达式的匹配。该方法类似于indexOf()或者lastIndexOf(); 但是它返回的是指定的值,而不是字符串的位置;
基本语法:
stringObject.match(searchValue) 或者stringObject.match(regexp)
@param(参数)
searchValue 需要检索字符串的值;
regexp: 需要匹配模式的RegExp对象;
@return(返回值) 存放匹配成功的数组; 它可以全局匹配模式,全局匹配的话,它返回的是一个数组。如果没有找到任何的一个匹配,那么它将返回的是null;返回的数组内有三个元素,第一个元素的存放的是匹配的文本,还有二个对象属性;index属性表明的是匹配文本的起始字符在stringObject中的位置;input属性声明的是对stringObject对象的引用;
如下测试代码:
var str = "hello world"; console.log(str.match("hello")); // ["hello", index: 0, input: "hello world"] console.log(str.match("Hello")); // null console.log(str.match(/hello/)); // ["hello", index: 0, input: "hello world"] // 全局匹配 var str2="1 plus 2 equal 3" console.log(str2.match(/\d+/g)); //["1", "2", "3"]
3. replace()方法:该方法用于在字符串中使用一些字符替换另一些字符,或者替换一个与正则表达式匹配的子字符串;
基本语法:stringObject.replace(regexp/substr,replacement);
@param(参数)
regexp/substr; 字符串或者需要替换模式的RegExp对象。
replacement:一个字符串的值,被替换的文本或者生成替换文本的函数。
@return(返回值) 返回替换后的新字符串
注意:字符串的stringObject的replace()方法执行的是查找和替换操作,替换的模式有2种,既可以是字符串,也可以是正则匹配模式,如果是正则匹配模式的话,那么它可以加修饰符g,代表全局替换,否则的话,它只替换第一个匹配的字符串;
replacement 既可以是字符串,也可以是函数,如果它是字符串的话,那么匹配的将与字符串替换,replacement中的$有具体的含义,如下:
$1,$2,$3....$99 含义是:与regexp中的第1到第99个子表达式相匹配的文本。
$& 的含义是:与RegExp相匹配的子字符串。
lastMatch或RegExp["$_"]的含义是:返回任何正则表达式搜索过程中的最后匹配的字符。
lastParen或 RegExp["$+"]的含义是:返回任何正则表达式查找过程中最后括号的子匹配。
leftContext或RegExp["$`"]的含义是:返回被查找的字符串从字符串开始的位置到最后匹配之前的位置之间的字符。
rightContext或RegExp["$'"]的含义是:返回被搜索的字符串中从最后一个匹配位置开始到字符串结尾之间的字符。
如下测试代码:
var str = "hello world"; // 替换字符串 var s1 = str.replace("hello","a"); console.log(s1);// a world // 使用正则替换字符串 var s2 = str.replace(/hello/,"b"); console.log(s2); // b world // 使用正则全局替换 字符串 var s3 = str.replace(/l/g,''); console.log(s3); // heo word // $1,$2 代表的是第一个和第二个子表达式相匹配的文本 // 子表达式需要使用小括号括起来,代表的含义是分组 var name = "longen,yunxi"; var s4 = name.replace(/(\w+)\s*,\s*(\w+)/,"$2 $1"); console.log(s4); // "yunxi,longen" // $& 是与RegExp相匹配的子字符串 var name = "hello I am a chinese people"; var regexp = /am/g; if(regexp.test(name)) { //返回正则表达式匹配项的字符串 console.log(RegExp['$&']); // am //返回被搜索的字符串中从最后一个匹配位置开始到字符串结尾之间的字符。 console.log(RegExp["$'"]); // a chinese people //返回被查找的字符串从字符串开始的位置到最后匹配之前的位置之间的字符。 console.log(RegExp['$`']); // hello I // 返回任何正则表达式查找过程中最后括号的子匹配。 console.log(RegExp['$+']); // 空字符串 //返回任何正则表达式搜索过程中的最后匹配的字符。 console.log(RegExp['$_']); // hello I am a chinese people } // replace 第二个参数也可以是一个function 函数 var name2 = "123sdasadsr44565dffghg987gff33234"; name2.replace(/\d+/g,function(v){ console.log(v); /* * 第一次打印123 * 第二次打印44565 * 第三次打印987 * 第四次打印 33234 */ }); /* * 如下函数,回调函数参数一共有四个 * 第一个参数的含义是 匹配的字符串 * 第二个参数的含义是 正则表达式分组内容,没有分组的话,就没有该参数, * 如果没有该参数的话那么第四个参数就是undefined * 第三个参数的含义是 匹配项在字符串中的索引index * 第四个参数的含义是 原字符串 */ name2.replace(/(\d+)/g,function(a,b,c,d){ console.log(a); console.log(b); console.log(c); console.log(d); /* * 如上会执行四次,值分别如下(正则使用小括号,代表分组): * 第一次: 123,123,0,123sdasadsr44565dffghg987gff33234 * 第二次: 44565,44565,11,123sdasadsr44565dffghg987gff33234 * 第三次: 987,987,22,123sdasadsr44565dffghg987gff33234 * 第四次: 33234,33234,28,123sdasadsr44565dffghg987gff33234 */ });
4. split()方法: 该方法把一个字符串分割成字符串数组。
基本语法如:stringObject.split(separator,howmany);
@param(参数)
1. separator[必填项],字符串或正则表达式,该参数指定的地方分割stringObject;
2. howmany[可选] 该参数指定返回的数组的最大长度,如果设置了该参数,返回的子字符串不会多于这个参数指定的数组。如果没有设置该参数的话,整个字符串都会被分割,不考虑他的长度。
@return(返回值) 一个字符串数组。该数组通过在separator指定的边界处将字符串stringObject分割成子字符串。
测试代码如下:
var str = "what are you doing?"; // 以" "分割字符串 console.log(str.split(" ")); // 打印 ["what", "are", "you", "doing?"] // 以 "" 分割字符串 console.log(str.split("")); /* * 打印:["w", "h", "a", "t", " ", "a", "r", "e", " ", "y", "o", "u", " ", "d", "o", "i", "n", * "g", "?"] */ // 指定返回数组的最大长度为3 console.log(str.split("",3)); // 打印 ["w", "h", "a"]
1-2 RegExp对象方法
1. test()方法:该方法用于检测一个字符串是否匹配某个模式;
基本语法:RegExpObject.test(str);
@param(参数) str是需要检测的字符串;
@return (返回值) 如果字符串str中含有与RegExpObject匹配的文本的话,返回true,否则返回false;
如下测试代码:
var str = "longen and yunxi"; console.log(/longen/.test(str)); // true console.log(/longlong/.test(str)); //false // 或者创建RegExp对象模式 var regexp = new RegExp("longen"); console.log(regexp.test(str)); // true
2. exec()方法: 该方法用于检索字符串中的正则表达式的匹配。
基本语法:RegExpObject.exec(string)
@param(参数):string【必填项】要检索的字符串。
@return(返回值):返回一个数组,存放匹配的结果,如果未找到匹配,则返回值为null;
注意:该返回的数组的第一个元素是与正则表达式相匹配的文本,该方法还返回2个属性,index属性声明的是匹配文本的第一个字符的位置;input属性则存放的是被检索的字符串string;该方法如果不是全局的话,返回的数组与match()方法返回的数组是相同的。
如下测试代码:
var str = "longen and yunxi"; console.log(/longen/.exec(str)); // 打印 ["longen", index: 0, input: "longen and yunxi"] // 假如没有找到的话,则返回null console.log(/wo/.exec(str)); // null
了解正则中的普通字符
字母,数字,汉字,下划线及一些没有特殊定义的标点符号,都属于普通字符,正则中的普通字符,在匹配字符串的时候,匹配与之相同的字符即可~ 比如如下代码:
var str = "abcde";
console.log(str.match(/a/)); // ["a", index: 0, input: "abcde"]
如上代码,字符串abcde匹配a的时候,匹配成功,索引位置从0开始;
了解正则中的方括号[]的含义
方括号包含一系列字符,能够匹配其中任意一个字符, 如[abc]可以匹配abc中任意一个字符,使用[^abc]包含的字符abc,则能够匹配abc字符之外的任何一个字符,只能是一个字符。如下的含义:
[abc]: 查找在方括号中的任意一个字符;
[^abc]: 查找不在方括号中的任意一个字符;
[0-9]: 查找0-9中的任意一个数字;
[a-z]: 查找从小写a到z中的任意一个字符;
(red|blue|green); 查找小括号中的任意一项,小括号中的 | 是或者的意思;
列举1:表达式[bcd][bcd] 匹配 "abcde"时候,匹配成功,内容是bc,匹配到的位置开始于1,结束与3;如下代码:
var str = "abcde";
console.log(str.match(/[bcd][bcd]/)); // ["bc", index: 1, input: "abcde"]
理解javascript中的元字符
| 元字符 | 描述 |
|
. |
查找任意的单个字符,除换行符外 |
|
\w |
任意一个字母或数字或下划线,A_Za_Z0_9,_中任意一个 |
|
\W |
查找非单词的字符,等价于[^A_Za_z0_9_] |
|
\d |
匹配一个数字字符,等价于[0-9] |
|
\D |
匹配一个非数字字符,等价于[^0-9] |
|
\s |
匹配任何空白字符,包括空格,制表符,换行符等等。等价于[\f\n\r\t\v] |
|
\S |
匹配任何非空白字符,等价于[^\f\n\r\t\v] |
|
\b |
匹配一个单词边界,也就是指单词和空格间的位置,比如’er\b’可以匹配”never”中的”er”,但是不能匹配”verb”中的”er” |
|
\B |
匹配非单词边界,’er\B’能匹配’verb’中的’er’,但不能匹配’never’中的’er’ |
|
\0 |
查找NUL字符。 |
|
\n |
匹配一个换行符 |
|
\f |
匹配一个换页符 |
|
\r |
匹配一个回车符 |
|
\t |
匹配一个制表符 |
|
\v |
匹配一个垂直制表符 |
|
\xxx |
查找一个以八进制数xxx规定的字符 |
|
\xdd |
查找以16进制数dd规定的字符 |
|
\uxxxx |
查找以16进制数的xxxx规定的Unicode字符。 |
1. 元字符. 用于匹配任何单个字符(除了换行符以外);
基本语法:new RegExp(“regexp.”) 或者直接量语法 /regexp./
比如代码如下:
var str = "abcde";
console.log(str.match(/a.c/)); // ["abc", index: 0, input: "abcde"]
2. \w; 查找任意一个字母或数字或下划线,等价于A_Za_z0_9,_
基本语法:new RegExp(“\w”); 或 直接量语法:/\w/
比如代码如下:
var str = "abcde";
// 匹配单个字符,找到一个直接返回
console.log(str.match(/\w/)); // ["a", index: 0, input: "abcde"]
// 匹配所有字符
console.log(str.match(/\w+/)); //["abcde", index: 0, input: "abcde"]
3. \W; 查找非单词的字符,等价于[^A_Za_z0_9_]
基本语法:new RegExp(“\W”) 或直接量 /\W/
var str = "abcde";
// 匹配单个字符,没有找到返回null
console.log(str.match(/\W/)); // null
4. \d;匹配与一个数字字符,等价于[0-9];
基本语法:new RegExp(“\d”); 或 直接量语法:/\d/
代码如下:
var str = "abcde111";
console.log(/\d/g.exec(str)); // ["1", index: 5, input: "abcde111"]
5. \D; 匹配一个非数字字符,等价于[^0-9]
基本语法:new RegExp(“\D”) 或直接量 /\D/
如下测试代码:
var str = "abcde111";
console.log(/\D+/g.exec(str)); // ["abcde", index: 0, input: "abcde111"]
6. \s;匹配任何空白字符,包括空格,制表符,换行符等等。等价于[\f\n\r\t\v]
基本语法:new RegExp(“\s”) 或直接量 /\s/
如下测试代码:
var str="Is this all there is?";
console.log(/\s/g.exec(str)); // [" ", index: 2, input: "Is this all there is?"]
7. \S;匹配任何非空白字符,等价于[^\f\n\r\t\v]
基本语法:new RegExp(“\S”) 或直接量 /\S/
如下测试代码:
var str="Is this all there is?";
console.log(/\S+/g.exec(str)); // ["Is", index: 0, input: "Is this all there is?"]
8. \b; 匹配一个单词边界,也就是指单词和空格间的位置,比如’er\b’可以匹配”never”中的”er”,但是不能匹配”verb”中的”er”
基本语法:new RegExp(“\bregexp”) 或直接量 /\bregexp/
如下测试代码:
var str="Is this all there is?";
console.log(/\bthis\b/g.exec(str)); // ["this", index: 3, input: "Is this all there is?"]
9. \B; 匹配非单词边界,’er\B’能匹配’verb’中的’er’,但不能匹配’never’中的’er’
基本语法:new RegExp(“\Bregexp”) 或直接量 /\Bregexp/
测试代码如下:
var str="Is this all there is?";
console.log(/\Bhi/g.exec(str)); // ["hi", index: 4, input: "Is this all there is?"]
10. \n; 匹配一个换行符;返回换行符被找到的位置。如果未找到匹配,则返回 -1。
基本语法:new RegExp(“\n”) 或直接量 /\n/
如下测试代码:
var str="Is this all \nthere is?";
console.log(/\n/g.exec(str)); // ["换行符", index: 12, input: "Is this all ↵there is?"]
11. \xxx; 查找一个以八进制数xxx规定的字符,如果未找到匹配,则返回 null。
基本语法:new RegExp(“\xxx”) 或直接量 /\xxx/
如下测试代码:
var str="Visit W3School. Hello World!";
console.log(/\127/g.exec(str)); // ["W", index: 6, input: "Visit W3School. Hello World!"]
如上代码分析:127的八进制转换为10进制的值等于 1*8的二次方 + 2*8的一次方 + 7*8的0次方 = 64 + 16 + 7 = 87 而W的ASCLL编码转换为10进制也是87,因此打印W
12. \xdd;查找以16进制数dd规定的字符。如果未找到匹配,则返回 null。
基本语法:new RegExp(“\xdd”) 或直接量 /\xdd/
如下测试代码:
var str="Visit W3School. Hello World!";
console.log(/\x57/g.exec(str)); // ["W", index: 6, input: "Visit W3School. Hello World!"]
W的16进制数等于57;
13.\uxxxx; 查找以16进制数的xxxx规定的Unicode字符。
基本语法:new RegExp(“\uxxx”) 或直接量 /\uxxx/
如下测试代码:
var str="Visit W3School. Hello World!";
console.log(/\u0057/g.exec(str)); // ["W", index: 6, input: "Visit W3School. Hello World!"]
RegExp特殊字符中的需要转义字符
需要转义的特殊字符前面加 \
$ 匹配输入字符串的结尾位置,如果需要匹配$本身的话,使用\$
^ 匹配输入字符串的开始位置,匹配^本身的话,使用\^
* 匹配前面的子表达式的零次或者多次,匹配*本身的话,使用\*
+ 匹配子表达式的1次或者多次,匹配+本身的话,使用\+
. 匹配除换行符之外的任何一个字符,匹配.本身的话,使用\.
[ 匹配一个中括号开始,匹配本身的,使用\[
? 匹配前面的子表达式的零次或者1次,或指明一个非贪婪限定符,要匹配本身的话,使用\?
\ 匹配本身的话,请使用\\
{ 标记限定符开始的地方,要匹配{ ,请使用\{
| 指明多项中的一个选择,可以理解含义为或的意思,匹配本身的话,使用\|
了解量词
1. n+ 匹配至少包含一个或者多个n的字符串。
基本语法:new RegExp(“n+”) 或直接量 /n+/
如下测试代码:
var str = "hello longen"; // 匹配至少一个或者多个l的字符串 console.log(str.match(/l+/g)); //["ll", "l"] // 匹配至少一个或者多个字母数字或者下划线 console.log(str.match(/\w+/g)); //["hello", "longen"]
2. n* 匹配零个或者多个n的字符串。
基本语法:new RegExp(“n*”) 或直接量 /n*/
如下测试代码:
var str = "hello longen hello"; // 匹配至少零个或者多个l的字符串 // 可以匹配多个l或者不匹配l 全局匹配 console.log(str.match(/el*/g)); //["ell", "e", "ell"] // 可以匹配多个u或者不匹配u 全局匹配 console.log(str.match(/hu*/g)); //["h", "h"]
3. n?匹配零个或者1个n的字符串,可以匹配n字符串,也可以只匹配一个n;先尽量匹配,如没有匹配到,就回溯,再进行不匹配;
基本语法:new RegExp(“n?”) 或直接量 /n?/
如下测试代码:
var str = "hello longen hello"; // 匹配至少零个或者1个l的字符串 console.log(str.match(/el?/g)); //["el", "e", "el"] // 可以匹配1个u或者不匹配u 全局匹配 console.log(str.match(/hu?/g)); //["h", "h"]
4. n{x} 匹配包含x个的n的序列字符串。X必须是数字。
基本语法:new RegExp(“n{x}”) 或直接量 /n{x}/
如下测试代码:
var str="100, 1000 or 10000?"; // 匹配4个数字的 匹配到1000和10000 console.log(str.match(/\d{4}/g)); //["1000", "1000"]
5. n{x,y} 匹配包含至少x个的n字符串,最多y个n字符串。
基本语法:new RegExp(“n{x,y}”) 或直接量 /n{x,y}/
如下测试代码:
var str="100, 1000 or 10000?"; // 匹配最小3个数字,最多四个数字的 匹配到100,1000和10000 console.log(str.match(/\d{3,4}/g)); //["100", "1000", "1000"]
6. n{x,} 匹配至少包含x个n序列的字符串;
基本语法:new RegExp(“n{x,}”) 或直接量 /n{x,}/
如下测试代码:
var str="100, 1000 or 10000?"; // 匹配最小3个数字 匹配到100,1000和10000 console.log(str.match(/\d{3,}/g)); //["100", "1000", "1000"]
7. n$ 匹配任何以n结尾的字符串;
基本语法:new RegExp(“n$”) 或直接量 /n$/
如下测试代码:
var str="my name is longen"; // 匹配以en结尾的字符串 console.log(str.match(/en$/g)); //["en"]
8. ^n 匹配任何以n开头的字符串;
基本语法:new RegExp(“^n”) 或直接量 /^n/
如下测试代码:
var str="my name is longen"; // 匹配以my开头的字符串 console.log(str.match(/^my/g)); //["my"] // 匹配以na开头的字符串,没匹配到,返回null console.log(str.match(/^na/g)); //null
9. ?=n 匹配任何其后紧接指定字符串n的字符串;
基本语法:new RegExp(“regexp(?=n)”) 或直接量 /regexp(?=n)/
如下测试代码:
var str="my name is longen"; // 匹配以na其后紧接m的字符串 // ?= 只是匹配位置,不会返回值 console.log(str.match(/na(?=m)/g)); //["na"]
10 ?!n 匹配任何其后不紧接n的字符串
基本语法:new RegExp(“regexp(?!n)”) 或直接量 /regexp(?!n)/
如下测试代码:
var str="my name is longen"; // 匹配以na其后不紧接ma的字符串 // ?! 只是匹配位置,不会返回值 console.log(str.match(/na(?!ma)/g)); //["na"] console.log(str.match(/na(?!m)/g)); // null
11. ^ 以字符串开始的地方匹配,不匹配任何字符;
比如:表达式^aaa 在匹配字符串 “longen aaa bbb”的时候,匹配的结果是失败的;因为^的含义是以某某字符串开始进行匹配;只有当aaa在字符串起始位置才能匹配成功;比如”aaa longen bbb” 才匹配成功;
12. $ 以字符串结束的地方匹配,不匹配任何字符;
比如:表达式aaa$ 在匹配字符串 “longen aaa bbb”的时候,匹配的结果是失败的;因为$的含义是以某某字符串结束进行匹配;只有当aaa在字符串结束位置才能匹配成功;比如”longen bbb aaa” 才匹配成功;
13. \b 匹配一个单词边界,也就是单词与空格之间的位置,不匹配任何字符;
如下测试代码:
var str="my name is longen"; // 匹配单词边界的字符 console.log(str.match(/\bname\b/g)); //["name"] // 如果不是单词边界的地方,就匹配失败 console.log(str.match(/\blong\b/g)); // null
14. | 左右两边表达式之间 “或” 关系,匹配左边或者右边。
如下测试代码:
var str = "hello world"; // 使用|的含义是 或者 匹配成功 结果为["hello "] //如果再次匹配的话 就是world console.log(str.match(/(hello | world)/g)); // ["hello "]
15:()的含义
在被修饰匹配次数的时候,括号中的表达式可以作为整体被修饰。取匹配结果的时候,括号中的表达式匹配到的内容可以被单独得到。
贪婪模式与非贪婪模式讲解
Javascript中的正则贪婪与非贪婪模式的区别是:被量词修饰的子表达式的匹配行为;贪婪模式在整个表达式匹配成功的情况下尽可能多的匹配;非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配;
一些常见的修饰贪婪模式的量词如下:
{x,y} , {x,} , ? , * , 和 +
那么非贪婪模式就是在如上贪婪模式后加上一个?(问号),就可以变成非贪婪模式的量词;如下:
{x,y}?,{x,}?,??,*?,和 +?
1. 什么是贪婪模式?
先看如下代码:
var str = "longen<p>我是中国人</p>yunxi<p>我是男人</p>boyboy"; // 贪婪模式 匹配所有字符 console.log(str.match(/<p>.*<\/p>/)[0]); // <p>我是中国人</p>yunxi<p>我是男人</p> // 后面加问号,变成非贪婪模式 console.log(str.match(/<p>.*?<\/p>/)[0]); // <p>我是中国人</p>
第一个console.log使用的是贪婪模式,我们来理解下匹配的基本原理;
首先正则是 /<p>.*<\/p>/ 匹配;<p>匹配字符串第一个字符匹配失败,接着往下,直接匹配到<p>时候,匹配成功,接着把匹配的控制权交给.*,从匹配到的<p>位置开始匹配,一直到</p>之前,接着把控制权交给</p>,接着在当前位置下往下匹配,因此匹配到</p>,匹配成功;由于它是贪婪模式,在匹配成功的前提下,仍然会尝试向右往下匹配,因此会匹配到两个<p>标签结束;但是非贪婪模式,也就是第二个console.log();他匹配到第一个p标签成功后,它就不会再进行匹配,因此打印的值为一个p标签的内容了;
理解匹配成功前提下的含义: 上面我们解释了,贪婪模式是要等一个表达式匹配成功后,再往下匹配;比如我们现在接着再看下们的表达式匹配代码:
var str = "longen<p>我是中国人</p>yunxi<p>我是男人</p>boyboy"; // 贪婪模式 console.log(str.match(/<p>.*<\/p>yunxi/)[0]); //打印 <p>我是中国人</p>yunxi
如上代码,打印出一个p标签内容,我们知道.*是贪婪模式匹配,如果按照上面的解释会打印出2个p标签的内容,因为这里在匹配到p标签后,会继续匹配后面的yunxi字符串,直到整个表达式匹配成功,才提示匹配成功,因此当匹配到第一个yunxi后,第一个子表达式匹配成功,接着尝试往右继续匹配,<p></p>都匹配成功,但是yunxi不会匹配boyboy,所以第二次尝试匹配的子表达式匹配失败,因此只返回匹配成功后的第一个p标签的内容了;
我们现在再来看看非贪婪模式的含义:
如下代码:
var str = "longen<p>我是中国人</p>yunxi<p>我是男人</p>boyboy<p>我是中国人2</p>yunxi<p>我是男人</p>boyboy"; // 非贪婪模式1 console.log(str.match(/<p>.*?<\/p>boyboy/)[0]); //<p>我是中国人</p>yunxi<p>我是男人</p>boyboy // 贪婪模式 console.log(str.match(/<p>.*<\/p>yunxi/)[0]); //<p>我是中国人</p>yunxi<p>我是男人</p>boyboy<p>我是中国人2</p>yunxi
我们先看表达式1,/<p>.*?<\/p>boyboy/ 匹配str字符串,首先先匹配到p标签内容;但是由于boyboy字符串一直没有匹配到,因此会一直尝试往后匹配,直到匹配到boyboy字符串后,才匹配成功,否则匹配失败;由于它是非贪婪模式,因此这时候它不会再往下进行匹配,所以匹配就结束了;因此第一个console输出为<p>我是中国人</p>yunxi<p>我是男人</p>boyboy;
我们可以再来看看贪婪模式 第二个console.log()输出的; 正则表达式 /<p>.*<\/p>yunxi/ 匹配到第一个p标签yunxi后,由于它是贪婪的,它还想接着向右继续匹配,直到匹配完成后,匹配成功,才结束,因此把所有p标签后面跟随yunxi的字符串都匹配到,且之间的所有的字符串都被返回;
理解正则表达式匹配原理
我们先来理解下占有字符和零宽度的含义。
1. 占有字符和零宽度
在正则表达式匹配的过程中,如果子表达式匹配到的是字符内容,而非位置的话,并被保存在匹配的结果当中,那么就认为该子表达式是占有字符的;如果子表达式匹配的仅仅是位置,或者说匹配中的内容不保存到匹配的结果当中,那么就认为该子表达式是零宽度的。我们先来理解下零宽度的列子,最常见的就是环视~ 它只匹配位置;比如顺序环视;环视待会就讲;
我们先理解下匹配过程如下图:
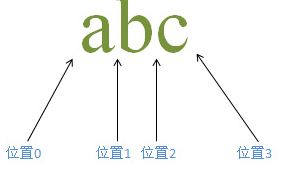
正则匹配方式 /abc/
匹配过程:首先由字符a取得控制权,从位置0开始进行匹配,a匹配a,匹配成功;接着往下匹配,把控制权交给b,那么现在从位置1开始,往下匹配,匹配到字符串b,匹配成功,接着继续往下匹配,位置是从2开始,把控制权交给c,继续往下匹配,匹配到字符串c,匹配成功,所以整个表达式匹配成功;匹配结果为 abc 匹配的开始位置为0,结束位置为3;
含有匹配优先量词的匹配过程
如下:

源字符串abc,正则表达式为ab?c ;量词?可以理解为匹配优先量词,在可匹配可不匹配的时候,会优先选择匹配;当匹配不到的时候,再进行不匹配。先匹配b是否存在,如果不存在的话,就不匹配b;因此结果可以匹配的有 abc,ac等
匹配过程:
首先由字符a取得控制权,从位置0开始匹配,a匹配到字符串a,匹配成功;接着继续匹配,把控制权交给b,b现在就从位置1开始匹配;匹配到字符串b,匹配成功;接着就把控制权交给c,c从位置2开始继续匹配,匹配字符串c,匹配成功;整个表达式匹配成功;假如b那会儿匹配不成功的话,它会忽略b,继续匹配字符串c,也就是如果匹配成功的话,结果是ac;
因此abc匹配字符串abc,匹配的位置从0开始,到3结束。
如果匹配的结果为ac的话,那么匹配的位置从0开始,到2结束;
假如我们把字符串改为abd,或者abe等其他的,那么当匹配到最后一个字符的时候,就匹配失败;
含有忽略优先量词的匹配过程
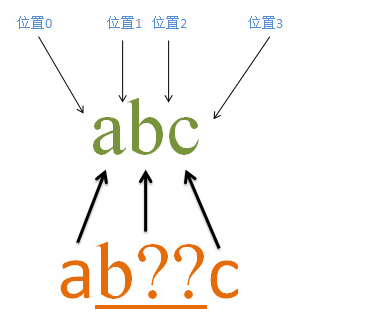
量词?? 含义是 忽略优先量词,在可匹配和可不匹配的时候,会选择不匹配,这里的量词是修饰b字符的,所以b?? 是一个整体的。匹配过程如下
首先由字符a取得控制权,从位置0开始匹配,有”a”匹配a,匹配成功,控制权交给b?? ;首先先不匹配b,控制权交给c,由c来匹配b,匹配失败,此时会进行回溯,由b??来进行匹配b,匹配成功,然后会再把控制权交给c,c匹配c,匹配成功,因此整个表达式都匹配成功;
理解正则表达式----环视
环视只进行子表达式匹配,不占有字符,匹配到的内容不保存到最终的匹配的结果,是零宽度的,它匹配的结果就是一个位置;环视的作用相当于对所在的位置加了一个附加条件,只有满足了这个条件,环视子表达式才能匹配成功。环视有顺序和逆序2种,顺序和逆序又分为肯定和否定,因此共加起来有四种;但是javascript中只支持顺序环视,因此我们这边来介绍顺序环视的匹配过程;
如下说明:
1. (?=Expression):
顺序肯定环视,含义是所在的位置右侧位置能够匹配到regexp.
2. (?!Expression)
顺序否定环视,含义是所在的位置右侧位置不能匹配到regexp
顺序肯定环视
先看如下图:
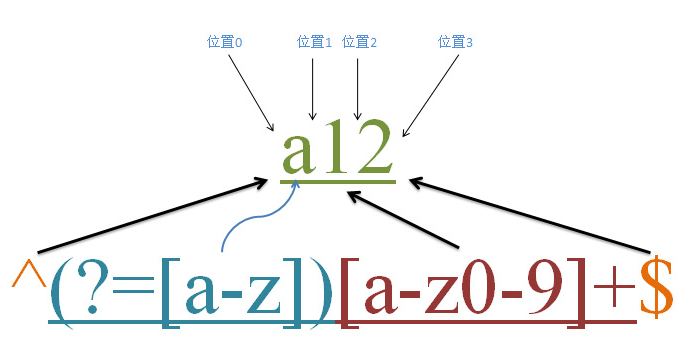
首先我们需要明白的是:^和$ 是匹配的开始和结束位置的;?= 是顺序肯定环视,它只匹配位置,不会占有字符,因此它是零宽度的。这个正则的含义是:
以字母或者数字组成的,并且第一个字符必须为小写字母开头;
匹配过程如下:
首先由元字符^取得控制权,需要以字母开头,接着控制权就交给 顺序肯定环视 (?=[a-z]); 它的含义是:要求它所在的位置的右侧是有a-z小写字母开头的才匹配成功,字符a12,第一个字符是a,因此匹配成功;我们都知道环视都是匹配的是一个位置,不占有字符的,是零宽度的,因此位置是0,把控制权交给[a-z0-9]+,它才是真正匹配字符的,因此正则[a-z0-9]+从位置0开始匹配字符串a12,且必须以小写字母开头,第一个字母是a匹配成功,接着继续从1位置匹配,是数字1,也满足,继续,数字2也满足,因此整个表达式匹配成功;最后一个$符合的含义是以字母或者数字结尾的;
顺序否定环视
当顺序肯定环视匹配成功的话,顺序否定环视就匹配失败,当顺序肯定环视匹配失败的话,那么顺序否定环视就匹配成功;
我们先看如下图:
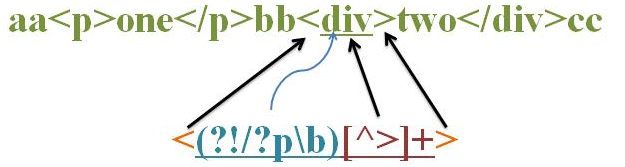
源字符串:aa<p>one</p>bb<div>two</div>cc
正则:<(?!/?p\b)[^>]+>
正则的含义是:匹配除<p>之外的其余标签;
如下图:
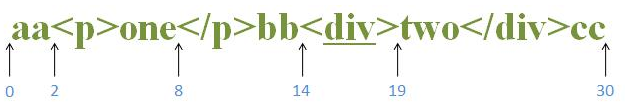
匹配过程如下:
首先由”<” 取得控制权,从位置0开始匹配,第一个位置和第二个位置都是字符a,因此匹配失败~ 接着从位置2匹配,匹配到<, 匹配成功了,现在控制权就交给(?!/?p\b);?!是顺序否定环视,只匹配一个位置,不匹配字符,这个先不用管,首先是 /? 取得控制权,它的含义是:可匹配/,或者不匹配/, 接着往下匹配的是p字符,匹配失败,进行回溯,不匹配,那么控制权就到一位了p字符,p匹配p,匹配成功,控制权就交给\b; \b的含义是匹配单词的边界符,\b就匹配到了 > ,结果就是匹配成功,子表达式匹配就完成了;/?p\b 就匹配成功了;所以(?!/?p\b) 这个就匹配失败了;从而使表达式匹配失败;我们继续往下匹配,从b字符开始,和上面一样匹配失败,当位置是从14开始的时候 < 字符匹配到”<”,匹配成功,把控制权又交给了(?!/?p\b), 还是/?取得控制权,和上面匹配的逻辑一样,最后?p\b匹配失败了,但是(?!/?p\b) 就匹配成功了,因此这一次表达式匹配成功;如下代码匹配:
var str = "aa<p>one</p>bb<div>two</div>cc";
// 匹配的结果为div,位置从14开始 19结束
console.log(str.match(/<(?!\/?p\b)[^>]+>/)[0]);
理解正则表达式---捕获组
捕获组就是把正则表达式中子表达式匹配的内容,保存到内存中以数字编号或显示命名的组里,方便后面使用;可以在正则表达式内部使用,也可以在外部使用;
捕获组有2种,一种是捕获性分组,另一种是 非捕获性分组;
我们先来看看捕获性的分组语法如下:
捕获组分组语法:(Expression)
我们都知道中括号是表示范围内选择,大括号表示重复次数,小括号的含义是允许重复多个字符;
捕获性分组的编号规则:编号是按照”(”出现的顺序,从左到右,从1开始进行编号;
比如如下代码:
// 分组的列子 console.log(/(longen){2}/.test("longen")); // false console.log(/(longen){2}/.test("longenlongen")); //true // 分组的运用 RegExp.$1 获取小括号的分组 var str = 11122; /(\d+)/.test(str); console.log(RegExp.$1); // 11122 // 使用replace替换 使用分组 把内容替换 var num = "11 22"; var n = num.replace(/(\d+)\s*(\d+)/,"$2 $1"); console.log(n); // 22 11
反向引用
反向引用标识由正则表达式中的匹配组捕获的子字符串。每个反向引用都由一个编号或名称来标识;并通过 ”\编号” 表示法来进行引用;
// 反向引用 console.log(/(longen)\1/.test("longen")); // false console.log(/(longen)\1/.test("longenlongen")); // true
理解非捕获性分组
并不是所有分组都能创建反向引用,有一种分组叫做非捕获性分组,它不能创建反向引用,要创建一个非捕获性分组,只要在分组的左括号的后面紧跟一个问号与冒号就ok;非捕获分组的含义我们可以理解为如下:子表达式可以作为被整体修饰但是子表达式匹配的结果不会被存储;如下:
// 非捕获性分组 var num2 = "11 22"; /#(?:\d+)/.test(num2); console.log(RegExp.$1); //"" 我们再来看下使用 非捕获性分组来把页面上的所有标签都去掉,如下代码: // 把页面上所有的标签都移除掉 var html = "<p><a href='http://baidu.com'>我来测试下</a>by <em>龙恩</em></p>"; var text = html.replace(/<(?:.|\s)*?>/g, ""); console.log(text); // 我来测试下by 龙恩
如上:我们来分析下:正则/<(?:.|\s)*?>/g 的含义是:g是修饰符,全局匹配的含义;使用非捕获性分组?: 的含义是 子表达式可以作为被整体修饰但是子表达式匹配的结果不会被存储;因此:正则/<(?:.|\s)*?>/g 的含义变为:匹配以< 开头 及 > 结束的所有字符;(?:.|\s)*? 含义是:. 代表任意字符,| 含义是或者的意思,\s 是匹配空格的意思;*号修饰符的含义是零个或者多个的意思;后面的?(问号)代表可匹配,可不匹配的含义;优先是可匹配;总起来的意思是:全局匹配字符串html 中的 以<开头 以>结尾的所有字符 替换成 空字符串,因此留下来就是文本;当然我们使用捕获性分组也可以得到同样的结果~
反向引用详细讲解
捕获性分组取到的内容,不仅可以在正则表达式外部通过程序进行引用,也可以在正则表达式内部进行引用,这种引用方式就叫做反向引用。
反向引用的作用是:是用来查找或限定重复,查找或限定指定标识配对出现等。
捕获性分组的反向引用的写法如:\number
Number是十进制数字,即捕获组的编号。
反向引用的匹配原理
捕获分组在匹配成功时,会将子表达式匹配到的内容,保存到内存中一个以数字编号的组里,可以简单的认为是对一个局部变量进行了赋值,这时就可以通过反向引用,引用这个局部变量的值。一个捕获分组在匹配成功之前,它的内容可以是不确定的,一旦匹配成功了,它的内容就确定了,反向引用的内容也就确定了。
比如如下代码:
var str = "longenaabcd"; console.log(str.match(/([ab])\1/)[0]);//aa
代码分析:对于如上代码中的正则 /([ab])\1/, 捕获组中子表达式[ab];可以匹配a,也可以匹配b,但是如果匹配成功的话,那么它的反向引用也就确定了,如果捕获分组匹配到的是a,那么它的反向引用就只能匹配a,如果捕获分组匹配到的是b,那么它的反向引用就只能匹配到b;\1的含义是 捕获分组匹配到是什么,那么它必须与捕获分组到是相同的字符;也就是说 只能匹配到aa或者bb才能匹配成功;
该正则匹配的过程我们可以来分析下:
字符串匹配正则/([ab])\1/, 在位置0处开始匹配,0处字符是l,很明显不满足,把控制权就交给下一个字符,一直到第6个字符,才匹配到a,匹配成功,把控制权交给\1, 也就是反向引用和分组中是相同的字符,因此也匹配a,字符串中下一个字符也是a,因此匹配成功,因此整个表达式找到匹配的字符,匹配的位置开始于6,结束与8;我们再可以匹配b,原理和上面一样,这里就不再多解释了;
正则表达式实战
1. 匹配以数字结尾的;
正则:/\d+$/g;
2. 去掉空格;
var str = "我 是 龙 恩";
console.log(str.replace(/\s+/g,""));//我是龙恩
3. 判断字符串是不是由数字组成;
var str = "123344我 是 龙 恩 1123344";
console.log(/^\d*$/.test(str)); //false
var str2 = "123445566";
console.log(/^\d*$/.test(str2)); // true
4. 电话号码正则
分析如下:电话号码有区号(3-4位数字),区号之后使用 ”-” 与电话号码连接;
区号正则:^\d{3,4}
电话号码7~8位 正则 \d{7,8}
电话号码也有分机号,分机号为3-4位数字,非必填项,如果要填写的话,则以”-”与电话号码相连接。
正则(-\d{3,4})?
因此正则匹配电话号码正则为:
/^\d{3,4}-/d{7,8}(-\d{3,4})?$/;
5. 手机号码正则
手机号码需要匹配;手机号码开头不以0开始的,并且是11位数字,目前的手机号码有如下开头的:13,14,15,17,18开头的;因此正则如下:
/(^1[3|4|5|7|8][0-9]{9}$)/
如下测试代码:
var str = 15606512345;
var reg = /(^1[3|4|5|7|8][0-9]{9}$)/;
console.log(reg.test(str)); //true
6. 删除字符串左右空格
// 删除字符串两侧的空白 /* * 下面的正则的含义是以1个或者多个空白开头的 * | 是或者的意思 或者以1个或者多个空白结尾的 * 也就是去掉头部和尾部的1个或者多个空格 */ function trim(str) { return str.replace(/^\s+|\s+$/g,''); } var str1 = " 1234 "; console.log(trim(str1)); // 输出去掉空格的 1234
7. 限制文本框只能输入数字和小数点(二位小数点)
分析:开头有0个或者多个数字,中间有0个或者1个小数点,小数点后面有0个或者最多2个数字;
正则:
/^\d*\.?\d{0,2}$/
//测试代码如下:
var reg = /^\d*\.?\d{0,2}$/;
var str1 = .9;
console.log(reg.test(str1)); // true
var str2 = 1.99;
console.log(reg.test(str2)); // true
var str3 = "1a.99";
console.log(reg.test(str3)); // false
8.替换小数点前面的内容为指定内容
var href = "aa.php?d=1"; var reg = href.replace(/\b^(\w*)(?=\.)/,"bb"); console.log(reg); // bb.php?d=1
代码分析如下:
如上代码的含义是 使用正则replace替换操作
找出以字母数字下划线开头的字符,前面以\b分隔单词与边界的地方
因此会找出第一个字符串中第一个开头的字符,后面是以捕获性分组来匹配
后面紧跟着一个.号的匹配,分组只匹配位置,不匹配字符,是零宽度的;
9. 匹配中文的正则
使用 Unicode,必须使用\u开头,接着是字符编码的四位16进制表现形式。
console.log(/[\u4E00-\u9FA5\uf900-\ufa2d]/g.test("我是")); //true
10. 返回字符串中 中文字符的个数。
分析:使用replace方法把不是中文字符全部替换成空
返回被替换的字符,因此是中文字符;
代码如下:
var str = "111我是涂根华说得对aaaaa1234556"; var reg = /[^\u4E00-\u9FA5\uf900-\ufa2d]/g; var val = str.replace(reg,''); console.log(val); // 我是涂根华说得对 console.log(val.length); // 长度为 8
11. 正则获取ip地址的前三段
比如如:192.168.16.162 需要变成 192.168.16
分析:使用正则匹配 .号后面带1-3位数字即可,
且以数字结尾的,把他们替换成空字符串。
代码如下:
var ip = "192.168.16.162"; console.log(ip.replace(/\.\d{1,3}$/,""));// 192.168.16
12. 匹配标签中的内容
比如匹配如代码 <ul><li>aaa</li><li>bbb</li></ul>
分析: 想获取ul中的内容,可以对匹配的内容使用分组
然后打印RegExp.$1 就获取到分组的内容了; 匹配所有字符
使用[\s\S]+ 空白和非空白的所有字符,且使用修饰符g代表全局的
如下代码:
var str2 = "<ul><li>aaa</li><li>bbb</li></ul>"; str2.match(/<ul>([\s\S]+?)<\/ul>/g); console.log(RegExp.$1); //<li>aaa</li><li>bbb</li>
13. 匹配标签中的文本。
匹配文本思路:可以先把字符串内的所有标签替换成空字符串
因此返回的就是文本了;
正则/<\/?[\s\S]+?>/gi
如下代码:
var str3 = "<ul><li>aaa</li><li>bbb</li></ul>"; var c = str3.replace(/<\/?[\s\S]+?>/gi,""); console.log(c); // aaabbb
14. 正则获取文件名
文件名有如下几种:
1. c:\images\tupian\006.jpg
2. C:\006.JPG
3. "c:\\images\\tupian\\006.jpg";
4. "c:\\images\\tupian\\aa.jpg";
5. "c:/images/tupian/test2.jpg";
正则如:/[^\\\/]*[\\\/]+/gi;
上面的正则含义是:[^\\\/]* 不以一个\ 或者 2个\\ 或者 /(需要转义,使用\)这样的反斜杠开头的
零个或者多个字符,后面紧跟以一个\ 或者 两个\\ 或者 /(需要转义,使用\)这样一个或者多个分隔符
全局匹配;
代码如下:
var s1 = "c:\\images\\tupian\\006.jpg", s2 = "c:\\images\\tupian\\aa.jpg", s3 = "c:/images/tupian/test2.jpg"; function getFileName(str){ var reg = /[^\\\/]*[\\\/]+/gi; str = str.replace(reg,''); return str; } console.log(getFileName(s1)); // 006.jpg console.log(getFileName(s3)); // test2.jpg
15. 绝对路径变成相对路径
比如绝对路径 http://172.16.28.162/images/a.jpg 需要替换成
./images/a.jpg
使用正则匹配 http:// //需要使用转义字符转义的 继续匹配除/以外的任何一个字符
直到有反斜杠/为止;然后替换成 . 字符
代码如下:
var reg = /http:\/\/[^\/]+/g; var r1 = "http://172.16.28.162/images/a.jpg"; console.log(r1.replace(reg,'.')); // ./images/a.jpg
16. 用户名正则
匹配规则:只能是中文,英文,数字,下划线,4-16个字符;
匹配中文字符正则:/[\u4E00-\u9FA5\uf900-\ufa2d]/
\w是 匹配英文,数字,下划线
测试代码如下:
var reg = /^[\u4E00-\u9FA5\uf900-\ufa2d\w]{4,16}$/; var str = "我是12345678aa_123"; console.log(reg.test(str)); // true var str = "我是12345678aa_1235"; console.log(reg.test(str)); // 17位 false
17. 匹配英文地址
匹配规则:包含点,字母,空格,逗号,数字,但是开头和结尾必须为字母
分析:开头必须为字母可以这样写 /^[a-zA-Z]/
结尾必须为字母可以这样写:/[a-zA-Z]+$/
中间包含点,字母,空格,逗号,数字的正则:/[\.a-zA-Z\s,0-9]*?/
外面的*号是0个或者多个,后面的问号? 代表可有可无;有就匹配,没有就不匹配;
测试代码如下:
var reg = /^[a-zA-Z][\.a-zA-Z\s,0-9]*?[a-zA-Z]+$/; var str1 = "11aa"; console.log(reg.test(str1)); // false var str2 = "aa111aaa"; console.log(reg.test(str2)); // true
18 匹配价格
匹配规则: 开头有0个或者多个数字,中间可能有一个小数点,后面有可能有0-2位小数
正则:/^\d*(\.\d{0,2})?$/
代码如下测试
var reg = /^\d*(\.\d{0,2})?$/ var num1 = 12; console.log(reg.test(num1)); // true var num2 = .01; console.log(reg.test(num2)); // true var num3 = 1.01; console.log(reg.test(num3)); // true var num4 = "1.aa1"; console.log(reg.test(num4)); //false var num5 = "1.1a"; console.log(reg.test(num5)); //false
19. 身份证号码的匹配
匹配规则:身份证号码有15位或者18位,其中最后一位可能是X,其他全是数字
正则: /^(\d{14}|\d{17})(\d|[xX])$/
var reg = /^(\d{14}|\d{17})(\d|[xX])$/; var identity1 = "36232919578996x"; console.log(reg.test(identity1)); // true var identity2 = "36232919578996a"; console.log(reg.test(identity2)); // false // 16位 var identity3 = "362329195789961x"; console.log(reg.test(identity3)); // false
20. 单词的首字母大写
匹配字符串,让其字符串的首个字母大写
正则:/\b(\w)|\s(\w)/g
测试代码如下:
function replaceReg(reg,str) { // 先转换为小写 str = str.toLowerCase(); return str.replace(reg,function(m){ return m.toUpperCase(); }); } var reg = /\b(\w)|\s(\w)/g; var str = "aadfdfCC"; console.log(replaceReg(reg,str)); // Aadfdfcc
21. 验证日期格式
日期格式有2种 第一种是yyyy-mm-dd 或 yyyy/mm/dd
分析 月和天数可以有1位或者2位
正则:/^\d{4}[-\/]\d{1,2}[-\/]\d{1,2}$/;
测试代码如下:
var reg = /^\d{4}[-\/]\d{1,2}[-\/]\d{1,2}$/; var d1 = "2015-12-1"; console.log(reg.test(d1)); //true var d2 = "2015-12-02"; console.log(reg.test(d2)); //true var d3 = "2015/12/12"; console.log(reg.test(d3)); // true
22. 验证邮箱的正则表达式
思路分析: 邮箱的规则是: 由3部分组成
由1个或者多个字母数字下划线和杠 + @ + 1个或者多个字母数字下划线和杠 + . + 1个或者多个字母数字下划线和杠
因此正则:/^([a-zA-Z_0-9-])+@([a-zA-Z_0-9-])+(\.[a-zA-Z_0-9-])+$/
测试代码如下:
var reg = /^([a-zA-Z_0-9-])+@([a-zA-Z_0-9-])+(\.[a-zA-Z_0-9-])+/; var email1 = "tugenhua@126.com"; console.log(reg.test(email1)); //true var email2 = "879083421_aaAA@qqAAzz_AA.comaaa"; console.log(reg.test(email2)); // true
23. 匹配代码中的a链接
比如<a href='http://www.baidu.com'>222</a> 匹配这样的
使用正则:/<a[.\s]*href\s*=\s*'http:\/\/.*'>\w*<\/a>/gi;
测试代码如下:
var reg = /<a[.\s]*href\s*=\s*'http:\/\/.*'>\w*<\/a>/gi; var html = "<div><a href='http://www.baidu.com'>222</a><p>344</p></div>"; console.log(html.match(reg)); // ["<a href='http://www.baidu.com'>222</a>"] var html2 = "<div><a href='http://www.baidu.com'>222</a><p>344</p><a href='http://www.baidu2.com'>333</a></div>"; console.log(html2.match(reg)); //["<a href='http://www.baidu.com'>222</a><p>344</p><a href='http://www.baidu2.com'>333</a>"]
24. 正则判断标签是否闭合
没有闭合的标签有2种 类型 一种像img标签那样的
<img src=""
还有一种像div或者p标签那样的
<div>aaa</div>
<p></p>
分析:先匹配起始标签 如<img 或 <p 使用正则:/<[a-z]+/i
接着匹配标签里面的多个属性 使用正则 /(\s*\w*?\s*=\s*.+?)*(\s*?>[\s\S]*?(<\/\1>)+|\s*\/>)/i
因此整个正则表达式合并为 /<([a-z]+)(\s*\w*?\s*=\s*.+?)*(\s*?>[\s\S]*?(<\/\1>)+|\s*\/>)/i
正则分析如下:
首先我们匹配像img标签或者div标签的开头位置时候 <img 或 <div 使用正则 /<([a-z]+)/i 以 < 开始 [a-z]中任意一个字符,修饰符+是一个或者多个字符 i代表不区分大小写
(\s*\w*?\s*=\s*.+?)*的含义是:比如<img src = "" 或 <div id = "" 先\s*匹配0个或多个空白 \w* 匹配0个或者多个(数字或者字母或下划线) 后面的问号?(尽可能少的匹配)
接着\s* 匹配0个或者多个空白 = 号紧接后面的 \s* 也是匹配0个或者多个空白 .+? 的含义是匹配除换行符之外的任意一个或多个字符(尽可能少的匹配);
下面我们继续看标签的闭合 标签闭合有2种,一种像img这样的 <img src=""/> 还有一种是 <div></div>这样的;
如果是类似img标签这样的话,匹配结束字符为 /> 匹配正则为:(\s*\/>); 如果是div这样的话 正则为:(\s*?>[\s\S]*?<\/\1>)
<\/\1> 的含义是:指的是 ([a-z]+) 这个分组
整个正则 /<([a-z]+)(\s*\w*?\s*=\s*".+?")*(\s*?>[\s\S]*?<\/\1>)|\s*\/>/i
注意:在元字符* 或者 + 号后加一个问号(?) 目的是 尽可能少的匹配;
var reg = /<([a-z]+)(\s*\w*?\s*=\s*".+?")*(\s*?>[\s\S]*?<\/\1>)|\s*\/>/i; var str1 = "<img src='aa' />"; var str2 = "<div></div>"; console.log(reg.test(str1)); // true console.log(reg.test(str2)); // true var str3 = "<img src='bb'"; console.log(reg.test(str3)); // false var str4 = "<div>aaa"; console.log(reg.test(str4)); // false //但是如上正则对下面的这个demo列子就不适用了;相同的标签嵌套没有闭合的情况下 如下 var str5 = "<div><div>aaa</div>"; console.log(reg.test(str5)); // true 实际上是false 因为有没有闭合标签
25. 获取标签里面的内容
正则和上面一样 只是使用了一个分组后,再获取那个分组即可;
var str = "<div>111</div>"; str.match(/<([a-z]+)(\s*\w*?\s*=\s*".+?")*\s*?>([\s\S]*?)<\/\1>/); console.log(RegExp.$3); // 111
26. 正则判断是否为数字和字母的混合
规则:字母和数字的混合
正则如: /^(([a-z]+)([0-9]+)|([0-9]+([a-z]+)))[a-z0-9]*$/i
分析:^([a-z]+)([0-9]+) 含义是 以1个或多个字母开头 后面紧跟1个或者多个数字
^([0-9]+([a-z]+)) 或者是以1个或者多个数字开头 后面紧跟1个或者多个字母
[a-z0-9]*$ 后面还可以紧跟数字或者字母0个或者多个
测试代码如下:
var reg = /^(([a-z]+)([0-9]+)|([0-9]+([a-z]+)))[a-z0-9]*$/i; var str1 = "aaaa"; var str2 = "aa22"; var str3 = "111sddtr"; var str4 = "问问啊啊啊ass"; var str5 = "1111ssdsd111sasddas"; console.log(reg.test(str1)); //false console.log(reg.test(str2)); // true console.log(reg.test(str3)); // true console.log(reg.test(str4)); // false console.log(reg.test(str5)); // true
27. 将阿拉伯数字转换为中文大写字符
var arrs = ["零","壹","贰","叁","肆","伍","陆","柒","捌","玖"]; function replaceReg2(reg,str){ return str.replace(reg,function(m){return arrs[m];}) } var reg = /\d/g; var str1 = '13889294444'; var str2 = '12889293333'; var str3 = '23445567'; console.log(replaceReg2(reg,str1)); // 壹叁捌捌玖贰玖肆肆肆肆 console.log(replaceReg2(reg,str2)); // 壹贰捌捌玖贰玖叁叁叁叁 console.log(replaceReg2(reg,str3)); // 贰叁肆肆伍伍陆柒
28. 替换文本中的url为链接
比如一段文本中有 aaaaahttp://www.baidu.combbbbb 需要替换成 aaaaa<a href="http://www.baidu.com">http://www.baidu.com</a>bbbbb
分析:最主要的还是需要正则匹配http://www.baidu.com 的url
正则如:/http:\/\/\w*(\.\w*)+/ig;
测试代码如下:
var str1 = "aaaaahttp://www.baidu.com bbbbb"; //var reg = /http:\/\/\w*(\.\w)+/ig; var reg = /http:\/\/\w*(\.\w*)+/ig; function replaceUrl(reg,str) { return str.replace(reg,function(r){ return "<a href='"+r+"'>"+r+"</a>"; }); } console.log(replaceUrl(reg,str1)); // aaaaa<a href='http://www.baidu.com'>http://www.baidu.com</a> bbbbb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号