
项目实操:
项目实现:
①明确目标
爬取知乎大v李淼的文章“标题”、“摘要”、“链接”,并存储到本地文件。
②分析目标
李淼的知乎文章URL在这里:https://www.zhihu.com/people/lisanshui1230/posts?page=1。(这里的文章排序我们按照默认排序,也就是按时间排序)
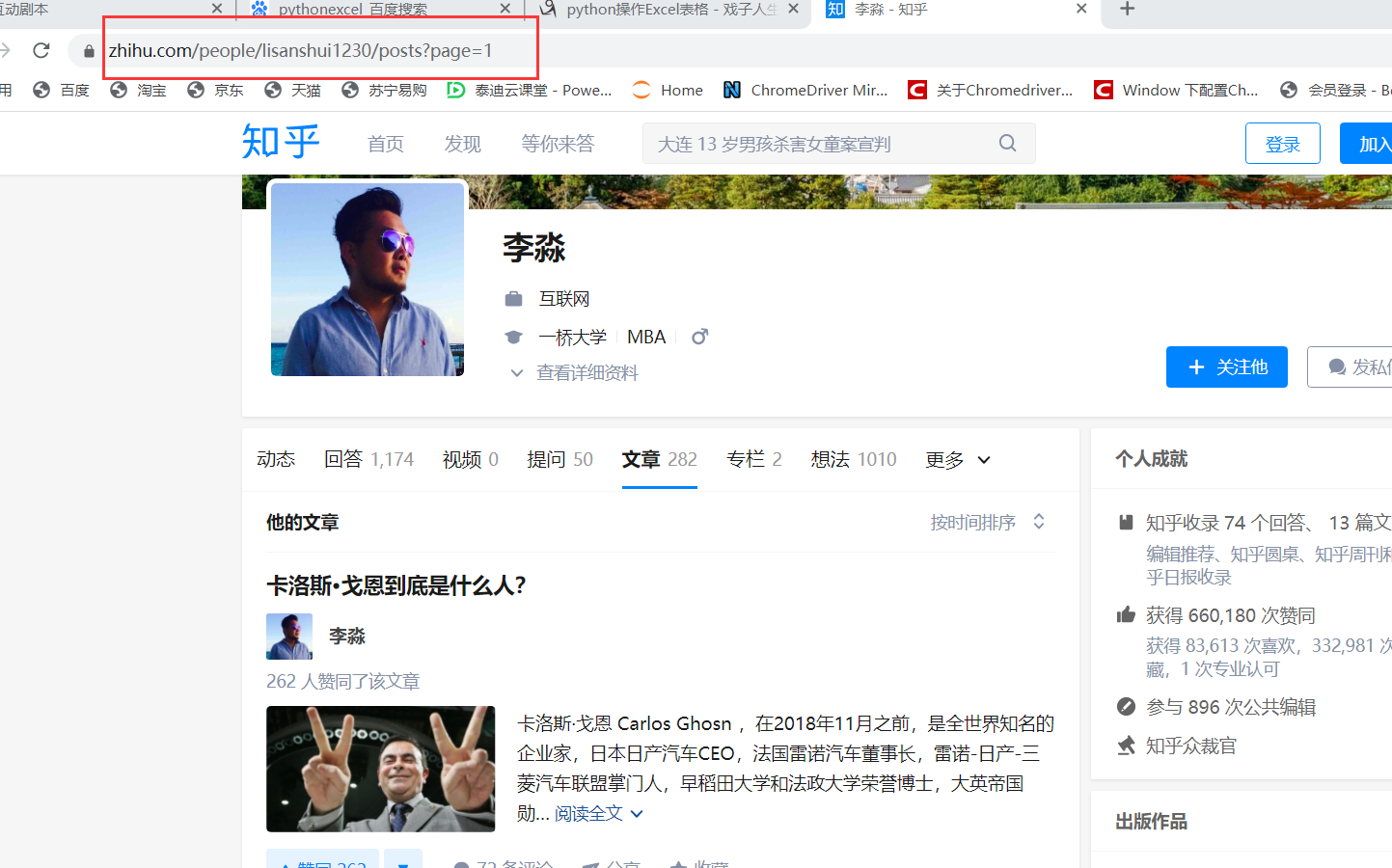
单击鼠标右键,点检查,点击network——>all——>清空——>刷新, 第一数据接口请求就是,然后在点Preview就可以看到我们所需要的数据就在HTML中
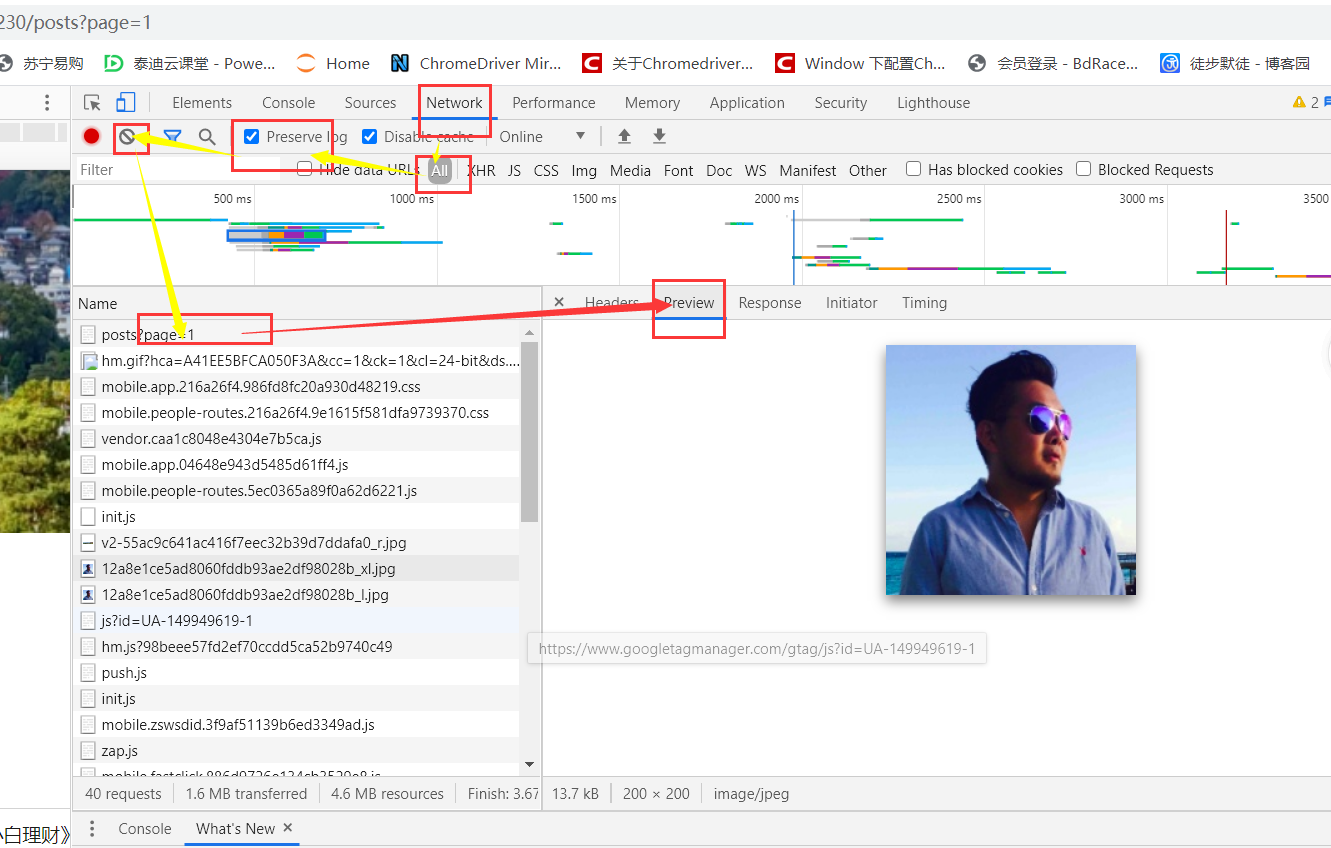
接下来判断使用解析数据的方法:bs
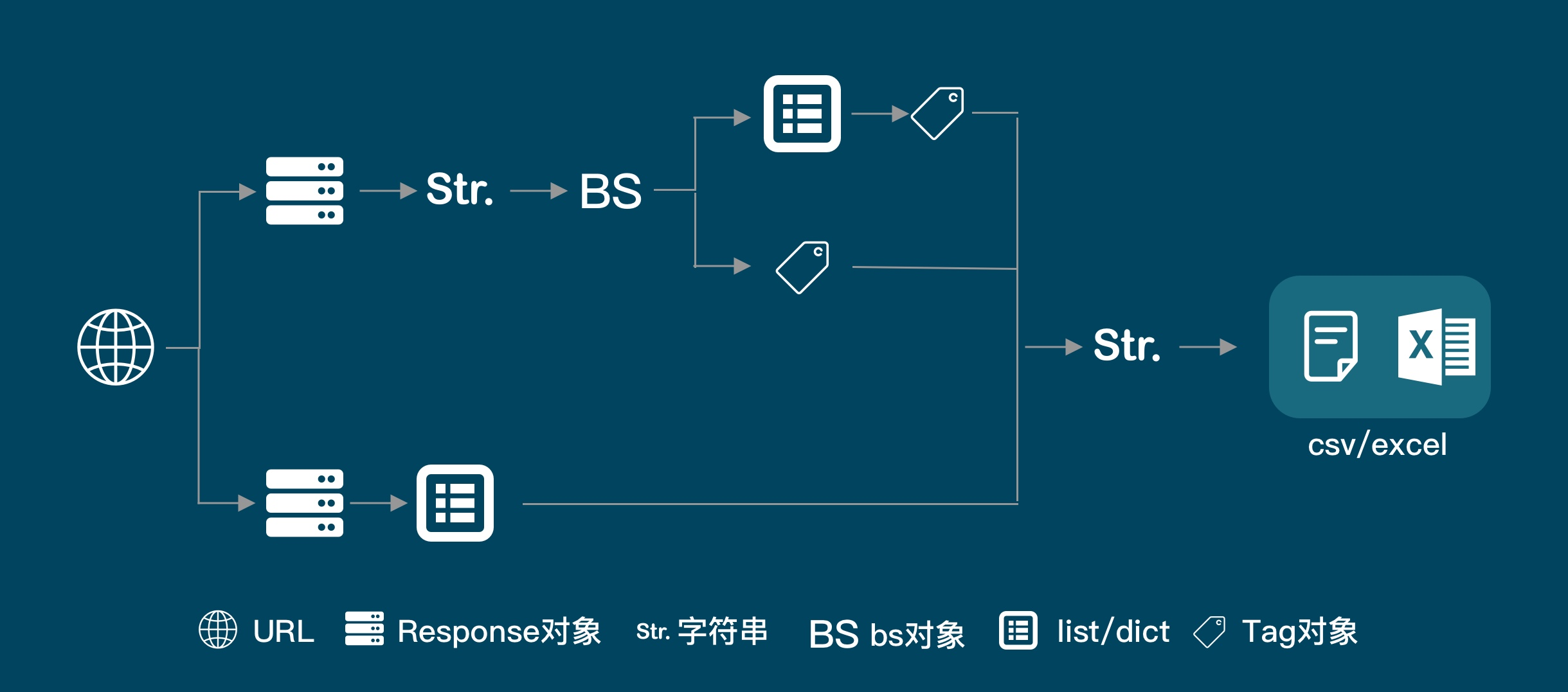
接下来让我们在上文的基础上点击Elements
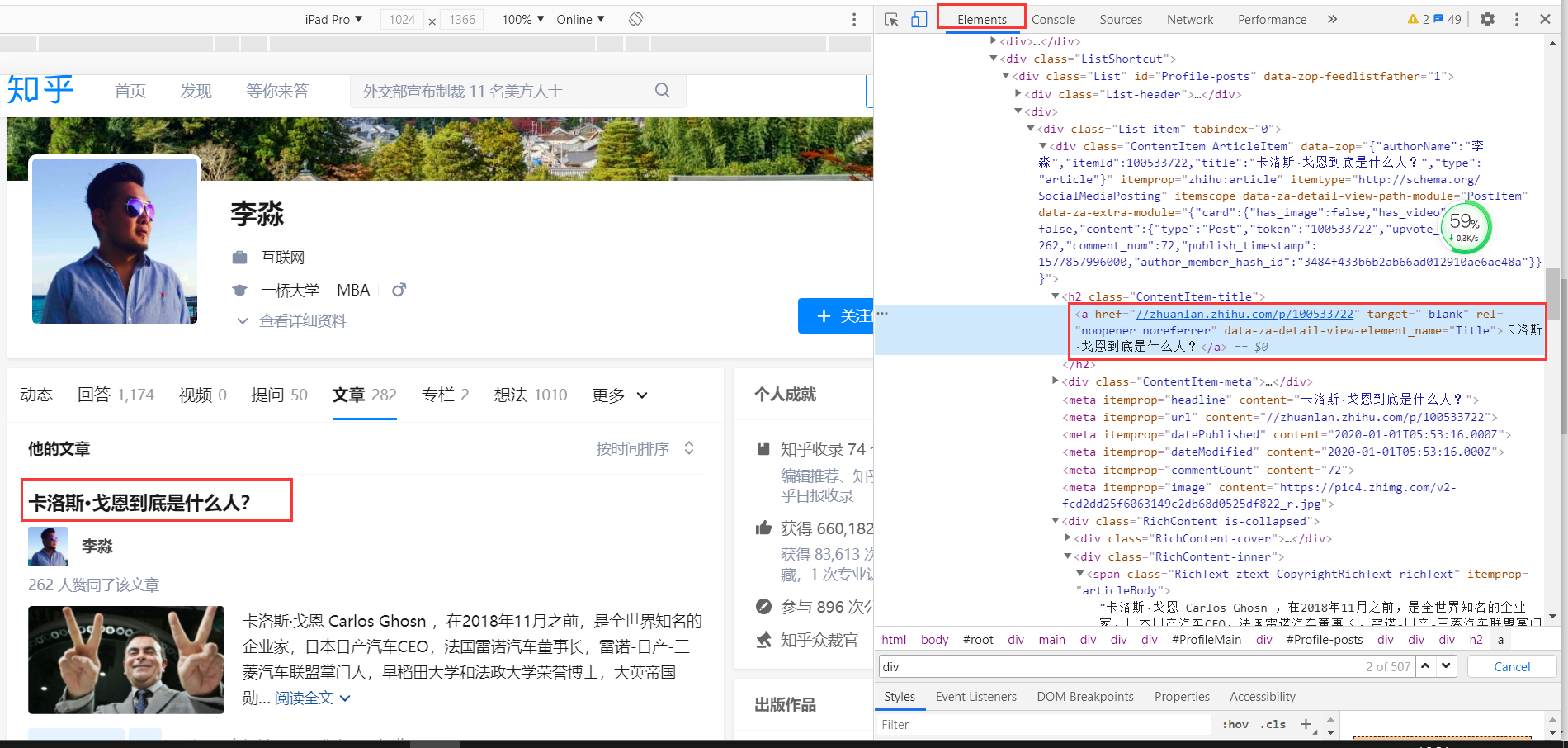
Ctrl+f查找target属性有90个所以无法精准定位大于了文章的数量
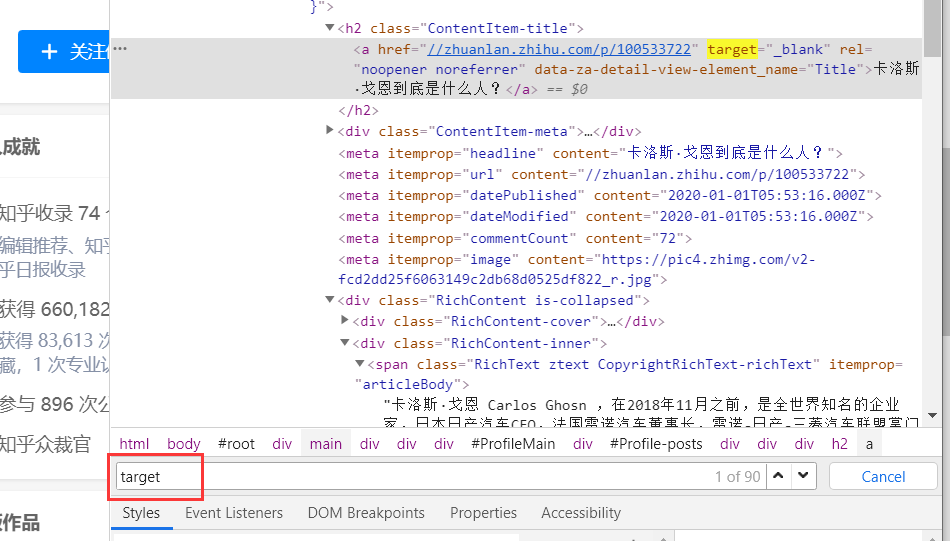
继续分析找a标签的上一级h2标签,h2标签经过搜索20,通过h2可以获取我们标题
流程:导入requests模块和BeautifulSoup模块,获取数据requests,解析数据BeautifulSoup,提取数据BeautifulSoup中的find_all(),获取多页数据
观察第一页和后面页,观察网址找规律,写循环,存储数据——用csv和openpyxl都可以
③代码实现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号