

AdaBoost对实际数据分类的Julia实现
写在前面
AdaBoost是机器学习领域一个很重要很流行的算法,而Julia是一门新兴的发展迅速的科学计算语言。本文将从一个实际例子出发,展示如何用Julia语言实现AdaBoost算法。
什么是AdaBoost
这方面的资料有很多,我将基于Hastie和Tibshirani的ESL(The Elements of Statistical Learning)有关章节的内容,从统计学习的角度简单介绍一下。另外,我一直在进行ESL的翻译工作,并试图实现书中有关算法,欢迎访问ESL-CN项目主页,本节的相关翻译内容参见这里。
给定预报向量\(X\),分类器\(G(X)\)在二值\(\\{-1,1\\}\)中取一个值得到一个预测。在训练样本上的误差率是
在未来预测值上的期望误差率为\(E_{XY}I(Y\neq G(X))\)
弱分类器是误差率仅仅比随机猜测要好一点的分类器。boosting的目的是依次对反复修改的数据应用弱分类器算法,因此得到弱分类器序列\(G_m(x),m=1,2,\ldots,M\) 根据它们得到的预测再通过一个加权来得到最终的预测
用一个概念图(图来自ESL原书)表示如下:
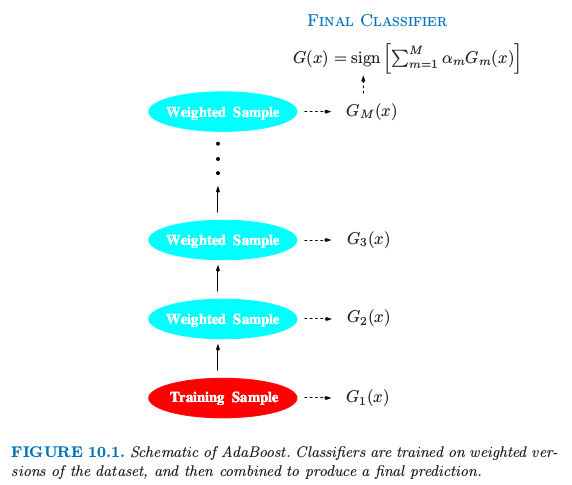
具体来说,对每步boosting的数据修改是对每个训练观测\((x_i,y_i),i=1,2,\ldots,N\)赋予权重\(w_1,w_2,\ldots,w_N\)。初始化所有的权重设为\(w_i=1/N\),使得第一步以通常的方式对数据进行训练分类器。对每个接下来的迭代\(m=2,3,\ldots,M\),单独修改观测的权重,然后将分类算法重新应用到加权观测值上。在第\(m\)步,上一步中被分类器\(G_{m-1}(x)\)的误分类的观测值增大了权重,而正确分类的观测值权重降低了。因此当迭代继续,很难正确分类的观测受到越来越大的影响。每个相继的分类器因此被强制集中在上一步误分类的训练数据上。
算法10.1显示了AdaBoost.M1算法的详细细节。当前的分类器\(G_m(x)\)由第2(a)行的加权观测值得到。在第2(b)行计算加权误差率。第2(c)行计算赋予\(G_m(x)\)的权重\(\alpha_m\)来得到最终的分类器\(G(x)\)(第3行)。每个观测的个体权重在第2(d)行进行更新。在导出序列中下一个分类器\(G_{m+1}(x)\)时,被分类器\(G(x)\)错误分类的观测值的权重被因子\(exp(\alpha_m)\)进行缩放以提高它们的相对影响。

例子
特征\(X_1,\ldots,X_{10}\)是标准独立高斯分布,目标\(Y\)定义如下
这里\(\chi_{10}^2(0.5)=9.34\)是自由度为10的卡方随机变量的中位数(10个标准的高斯分布的平方和)。有2000个训练情形,每个类别大概有1000个情形,以及10000个测试观测值。这里我们取称为“stump”的弱分类器:含两个终止结点的分类树。
实现
Julia的具体细节参见官方manual。
首先我们定义模型的结构,我们需要两个参数,弱分类器的个数n_clf和存储n_clf个弱分类器的n_clf\(\times 4\)的矩阵。因为对于每个弱分类器——两个终止结点的stump,我们需要三个参数确定,分割变量的编号idx,该分割变量对应的cutpoint值val,以及分类的方向flag(当flag取1时则所有比cutpoint大的观测值分到树的右结点,而flag取0时分到左结点),另外算法中需要确定的alpha参数,所以一个stump需要四个参数。下面代码默认弱分类器个数为10。
struct Adaboost
n_clf::Int64
clf::Matrix
end
function Adaboost(;n_clf::Int64 = 10)
clf = zeros(n_clf, 4)
return Adaboost(n_clf, clf)
end
训练模型
function train!(model::Adaboost, X::Matrix, y::Vector)
n_sample, n_feature = size(X)
## initialize weight
w = ones(n_sample) / n_sample
threshold = 0
## indicate the classification direction
## consider observation obs which is larger than cutpoint.val
## if flag = 1, then classify obs as 1
## else if flag = -1, classify obs as -1
flag = 0
feature_index = 0
alpha = 0
for i = 1:model.n_clf
## step 2(a): stump
err_max = 1e10
for feature_ind = 1:n_feature
for threshold_ind = 1:n_sample
flag_ = 1
err = 0
threshold_ = X[threshold_ind, feature_ind]
for sample_ind = 1:n_sample
pred = 1
x = X[sample_ind, feature_ind]
if x < threshold_
pred = -1
end
err += w[sample_ind] * (y[sample_ind] != pred)
end
err = err / sum(w)
if err > 0.5
err = 1 - err
flag_ = -1
end
if err < err_max
err_max = err
threshold = threshold_
flag = flag_
feature_index = feature_ind
end
end
end
## step 2(c)
#alpha = 1/2 * log((1-err_max)/(err_max))
alpha = 1/2 * log((1.000001-err_max)/(err_max+0.000001))
## step 2(d)
for j = 1:n_sample
pred = 1
x = X[j, feature_index]
if flag * x < flag * threshold
pred = -1
end
w[j] = w[j] * exp(-alpha * y[j] * pred)
end
model.clf[i, :] = [feature_index, threshold, flag, alpha]
end
end
预测模型
function predict(model::Adaboost,
x::Matrix)
n = size(x,1)
res = zeros(n)
for i = 1:n
res[i] = predict(model, x[i,:])
end
return res
end
function predict(model::Adaboost,
x::Vector)
s = 0
for i = 1:model.n_clf
pred = 1
feature_index = trunc(Int64,model.clf[i, 1])
threshold = model.clf[i, 2]
flag = model.clf[i, 3]
alpha = model.clf[i, 4]
x_temp = x[feature_index]
if flag * x_temp < flag * threshold
pred = -1
end
s += alpha * pred
end
return sign(s)
end
接下来应用到模拟例子中
function generate_data(N)
p = 10
x = randn(N, p)
x2 = x.*x
c = 9.341818 #qchisq(0.5, 10)
y = zeros(Int64,N)
for i=1:N
tmp = sum(x2[i,:])
if tmp > c
y[i] = 1
else
y[i] = -1
end
end
return x,y
end
function test_Adaboost()
x_train, y_train = generate_data(2000)
x_test, y_test = generate_data(10000)
m = 1:20:400
res = zeros(size(m, 1))
for i=1:size(m, 1)
model = Adaboost(n_clf=m[i])
train!(model, x_train, y_train)
predictions = predict(model, x_test)
println("The number of week classifiers ", m[i])
res[i] = classification_error(y_test, predictions)
println("classification error: ", res[i])
end
return hcat(m, res)
end
作出误差随迭代次数的图象如下
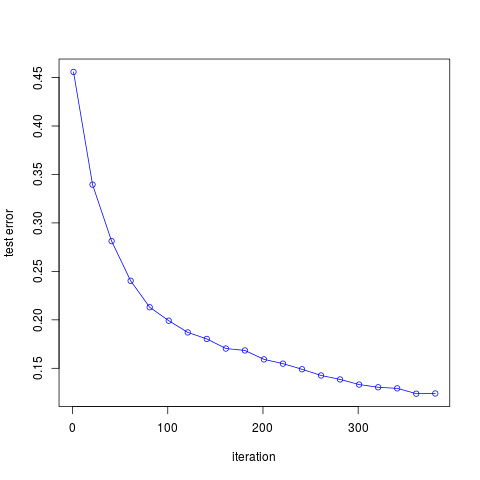
完整代码参见这里觉得项目很好的话记得star鼓励一下哦

 浙公网安备 33010602011771号
浙公网安备 33010602011771号