


一、背景目的
互联网的兴起,知识的获取变得越来越便利,然而大量信息有时候会对我们的选择造成干扰,通过其他用户的点击评阅可以作为一个有效的参考,方便人们搜寻到有效信息,本项目基于豆瓣图书TOP250进行数据分析
二、数据获取
通过python爬虫获取豆瓣图书top250的书名、网址链接、评分、点评数、一句话简介评语
from lxml import etree
import requests
import csv
import time
fp = open('/Users/cc/Desktop/doubanbook.csv', 'wt', newline='', encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(('name', 'url', 'author', 'publisher', 'date', 'price', 'date', 'price', 'rate', 'comment'))
urls = ['https://book.douban.com/top250?start={}'.format(str(i)) for i in range(0, 250, 25)]
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
infos = selector.xpath('//tr[@class="item"]')
for info in infos:
name = info.xpath('td/div/a/@title')[0]
url = info.xpath('td/div/a/@href')[0]
book_infos = info.xpath('td/p/text()')[0]
author = book_infos.split('/')[0]
publisher = book_infos.split('/')[-3]
date = book_infos.split('/')[-2]
price = book_infos.split('/')[-1]
rate = info.xpath('td/div/span[2]/text()')[0]
comments = info.xpath('td/p/span/text()')
comment = comments[0] if len(comments) != 0 else "空"
time.sleep(2)
writer.writerow((name, url, author, publisher, date, price, date, price, rate, comment))
三、数据预处理
1. 格式处理:刚爬虫下来的数据直接通过excel打开是乱码形式,通过记事本(另存为ANSI格式),再通过EXCEL(数据,查询新建。从文本)打开可观察相关信息
2. 使用numpy、pandas进行数据清洗处理
# 导入相关API工具
import pandas as pd import numpy as np import seaborn as sns import matplotlib as mpl from matplotlib import pyplot as plt import warnings %matplotlib inline
# 读入文件
df_books1 = pd.read_csv('C:/Users/cc/Desktop/doubanbook.csv')
print(df_books1.head())
print(df_books1.shape)
# 转化为DataFrame
pd.DataFrame(df_books1)
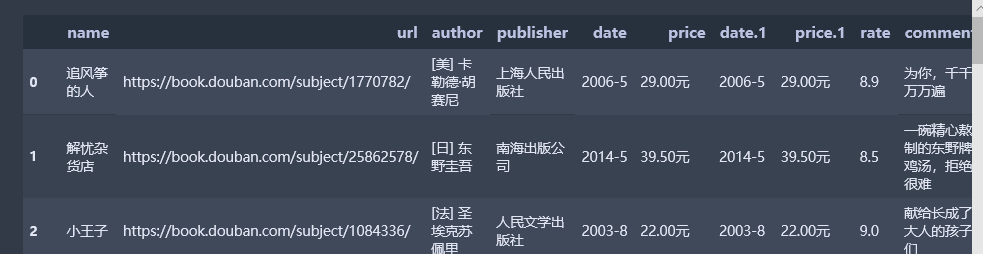
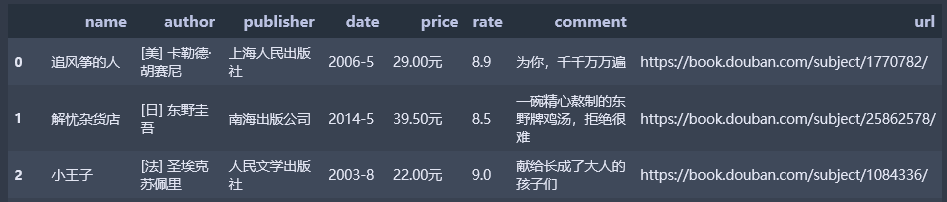
由表中数据观察可知,出版日期和价格特征重复,故删除重复特征,并对特征重新排序
df_books1 = pd.DataFrame(df_books1,columns=['name','author','publisher','date','price','rate','comment','url',]) df_books1
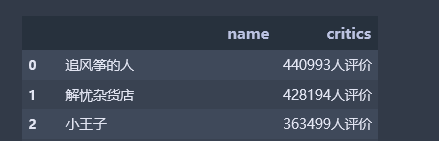
经分析数据发现缺少点评人数这一关键特征,通过爬虫重新获取点评人数这一特征
# 爬虫获取书名和评论人数
import requests from lxml import etree import time with open ('/Users/cc/Desktop/top2501.csv','w',encoding = 'utf-8') as f: for a in range(10): url = "https://book.douban.com/top250?start={}".format(a*25) data = requests.get(url).text s = etree.HTML(data) file = s.xpath('//*[@id="content"]/div/div[1]/div/table') for div in file: title = div.xpath('./tr/td[2]/div[1]/a/@title')[0] num = div.xpath('./tr/td[2]/div[2]/span[3]/text()')[0].strip('(').strip().strip(')') time.sleep(2) f.write('{}, {}\n'.format(title,num,))
#导入数据
df_books2 = pd.read_csv('C:/Users/cc/Desktop/top2501.csv',names=['name', 'critics',])
pd.DataFrame(df_books2)
将两个表格特征合并:
df_books = pd.merge(df_books1,df_books2 ,how='left') df_books

去除critics后面的“人评价”
df_books['critics'] = df_books['critics'].str[0:7] # 评论数不一致,截取长短不同,此方法不可取
df_books['critics'] = df_books['critics'].str.replace("人评价", "") # 通过str.replace替除“人评价”
df_books

由于书本价格相对较低廉,对消费者影响较小且该目录下书籍价格单位较多,故暂且不处理价格数据。
将时间中的年份提取出来单独作为一列
df_books['year'] =df_books.date.str[:5] df_books

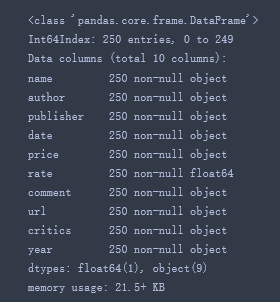
查看元素数据类型:数据类型相同方可进行算术运算
df_books.info()
将数据转化为统一类型
# 将critics元素转化为float64类型
df_books.loc[:,'critics'] = df_books.loc[:,'critics'].astype('float64') # float64类型方可进行描述性统计 df_books.info()

四、数据分析与可视化
数据如下:
df_books = df_books[['name','author','rate','critics','publisher','year','comment','price','url']] df_books

通过describe对数据进行描述性统计(总数、均值、标准差、最小值、下四分位、中位数、上四分位、最大值)
df_books.describe()
sns.lmplot(x="rate", y="critics", data=df_books) # 散点图
sns.lmplot(x="rate", y="critics", data=df_books,x_jitter=.08) # x轴方向上抖动
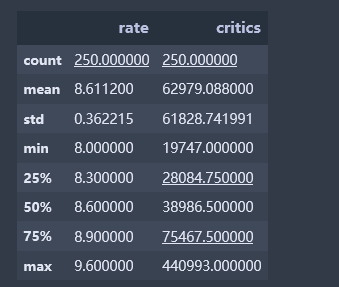
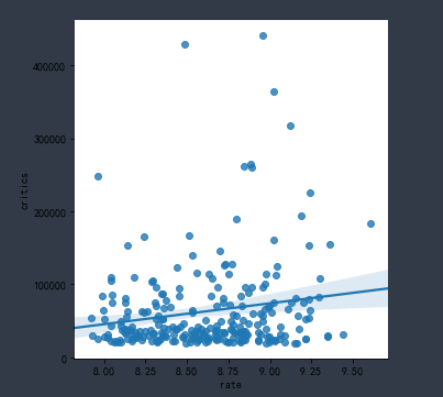
分析:平均评分在8.6,最高评分9.6,最低评分8.0
最高点评人数440993,最低点评人数19747,平均点评人数62979
评分可以反映一本书的好坏,而点评人数可以反映一本书的受众程度,从商业角度上来说,点评人数为重要特征。
按作者进行分类:
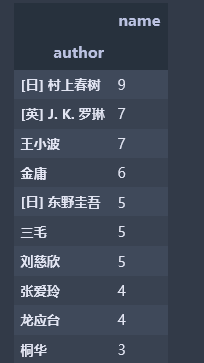
出书最多的前十名作者:
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
author_df1 = pd.DataFrame(df_books.groupby('author').name.count().sort_values(ascending=False).head(10)) #取前十
author_df1
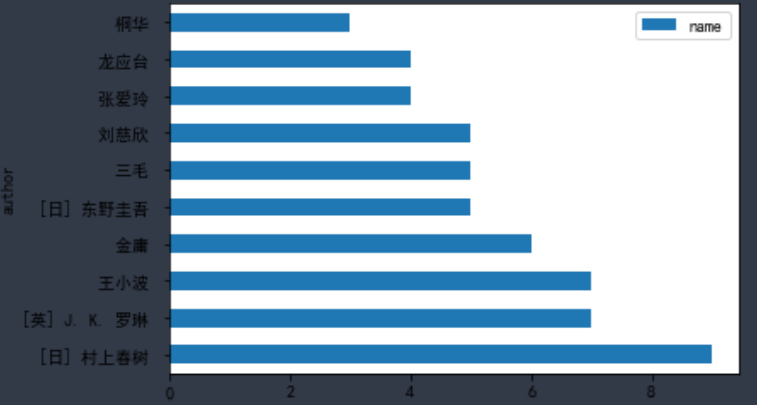
author_df1.plot.barh(stacked=True) #横状直方图
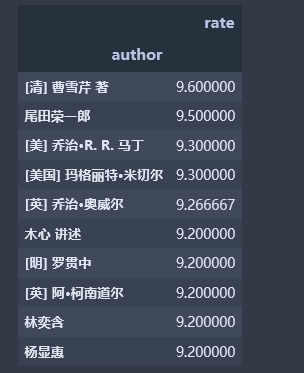
评分最高的前十名作者:
author_df2 = pd.DataFrame(df_books.groupby('author').rate.mean().sort_values(ascending=False).head(10)) author_df2
author_df2.plot.barh(stacked=True

点评书最高的前十名作者
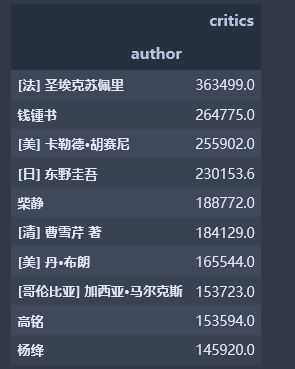
author_df3 = pd.DataFrame(df_books.groupby('author').critics.mean().sort_values(ascending=False).head(10)) author_df3
author_df3.plot.barh(stacked=True)

分析:豆瓣图书top250中出书最多的作者是日本作家村上春树、其次为英国作家J.K.罗琳,第三名为王小波
豆瓣图书top250中评分最高的作者是清朝曹雪芹、其次为日本尾田荣一郎,第三名为美国乔治·R.R.马丁
豆瓣图书top250中评论数最多的作者是法国圣埃克苏佩里、其次为中国钱钟书,第三名为美国卡勒德·胡塞尼
书籍评分与点评人数:
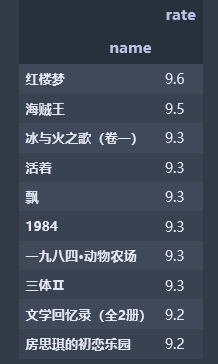
name_df2 = pd.DataFrame(df_books.groupby('name').rate.max().sort_values(ascending=False).head(10)) name_df2

name_df3 = pd.DataFrame(df_books.groupby('name').critics.mean().sort_values(ascending=False).head(10)) name_df3 name_df3.plot.barh(stacked=True)

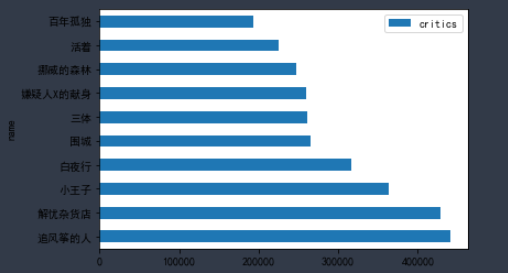
书籍评分最高和点评人数最多并不一致,其中《活着》这本书在两者top间均有体现,商家在对此书的订购可以稍多一点,而读者也可以将此书列入自己书单。
出版社出版书籍类型数目:
publisher_df = df_books.groupby('publisher').rate.agg(['count']).sort_values(by='count',ascending=False)[:10] publisher_df
publisher_df.plot.barh(stacked=True)

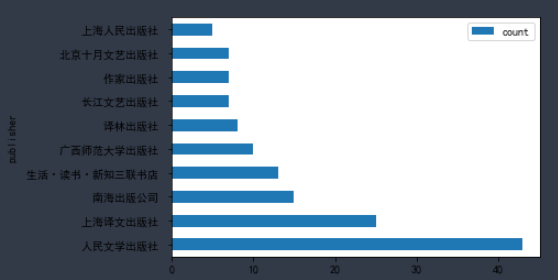
人民文学出版社:1951年3月成立于北京,系国家级专业文学出版机构,现为中国出版集团公司成员单位。
上海译文出版社:中国最大的综合性专业翻译出版社,成立于1978年1月1日,系世纪出版集团的成员。
南海出版公司:成立于1988年10月,是出版社会科学、文学艺术(包括外国文学、摄影美术)的具有一定规模的综合性出版社。
出版时间分析:
df_books['year'] = df_books['year'].str.replace("53.0", "1981") # 异常值处理,替换为正确出版年
data = df_books.groupby('year').name.agg(['count']).sort_values(by='count',ascending=False)# 按统计数排序
data = df_books.groupby('year').name.agg(['count']).sort_values(by='year',ascending=True) # 按时间排序 data
data.plot.bar(stacked=True)
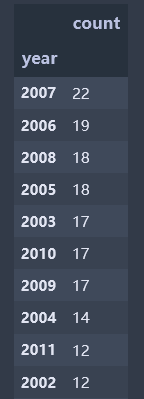
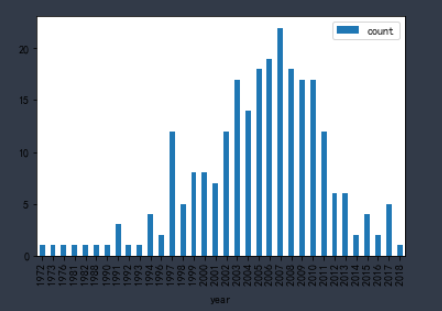
从1972至2018年,出版书籍数目随时间变化而提升,2007年达到高峰有22本,而之后猜测伴随电子书发展,出版量逐渐降低。
基于一句话点评做词云分析:
# 引入相关库包
import warnings warnings.filterwarnings("ignore") import jieba #分词包 import numpy #numpy计算包 import codecs #codecs提供的open方法来指定打开的文件的语言编码,它会在读取的时候自动转换为内部unicode import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import matplotlib matplotlib.rcParams['figure.figsize'] = (10.0, 5.0) from wordcloud import WordCloud#词云包
# 导入图书点评数据、分词
df = pd.read_csv("C:/Users/cc/Desktop/comment.csv", encoding='utf-8') #词云文件存储位置,路径不允许中文文件夹存在
df = df.dropna()
content = df.comment.values.tolist() # 做词云的特征量 ,此处例如comment
#jieba.load_userdict(u"data/user_dic.txt")
segment=[]
for line in content:
try:
segs=jieba.lcut(line)
for seg in segs:
if len(seg)>1 and seg!='\r\n':
segment.append(seg)
except:
print (line)
continue
# 去停用词 ‘空’
words_df=pd.DataFrame({'segment':segment})
#words_df.head()
# stopwords文件采用记事本,保存为utf-8格式
stopwords=pd.read_csv("C:/Users/cc/Desktop/stopwords.txt",index_col=False,quoting=3,sep="\t",names=['空'], encoding='utf-8')#quoting=3全不引用
stopwords.head()
words_df=words_df[~words_df.segment.isin(stopwords.空)]
# 统计词频
words_stat=words_df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size})
words_stat=words_stat.reset_index().sort_values(by=["计数"],ascending=False)
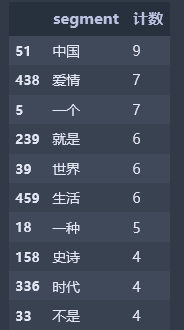
words_stat.head(10)
# 做词云,系统自带图片
wordcloud=WordCloud(font_path="data/simhei.ttf",background_color="white",max_font_size=80)
word_frequence = {x[0]:x[1] for x in words_stat.head(1000).values}
wordcloud=wordcloud.fit_words(word_frequence)
plt.imshow(wordcloud)

# 自定义背景图做词云
from scipy.misc import imread matplotlib.rcParams['figure.figsize'] = (15.0, 15.0) from wordcloud import WordCloud,ImageColorGenerator bimg=imread('C:/Users/cc/Desktop/entertainment.jpeg') wordcloud=WordCloud(background_color="white",mask=bimg,font_path='data/simhei.ttf',max_font_size=200) word_frequence = {x[0]:x[1] for x in words_stat.head(1000).values} wordcloud=wordcloud.fit_words(word_frequence) bimgColors=ImageColorGenerator(bimg) plt.axis("off") plt.imshow(wordcloud.recolor(color_func=bimgColors))


通过词云可以看出,字体越大的关键词,说明其在所有关键词中出现的次数越多。出现次数最多的10个词语,分别为“中国”、“爱情”、“一个”、“就是”、“世界”、“生活”、“一种”、“史诗”、“时代”、“不是”。
