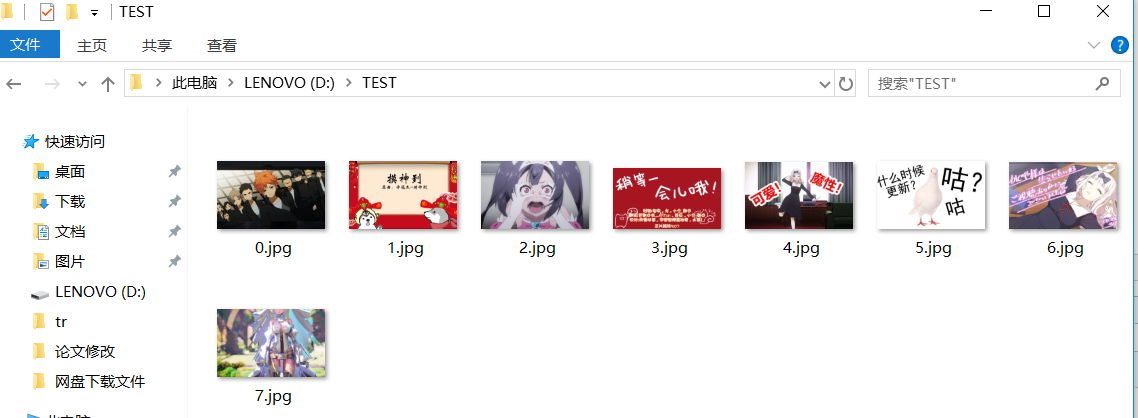
<爬虫>用正则爬取B站首页图片
import re
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
url = "https://www.bilibili.com/"
response = requests.get(url,headers=headers)
html = response.text
pattern = re.compile(r"<div.*?groom-module home-card.*?<img.*?src=(.*?)alt",re.S)
items = re.findall(pattern,html)
i = 0
for item in items:
item = "http:"+ re.sub('"','',item)
r = requests.get(item)
with open("D:\\TEST\\"+str(i)+'.jpg','wb') as f :
f.write(r.content)
print("图片:"+str(i)+'.jpg'+"写入成功!")
i+=1
B站首页情况:

运行结果: