

Spark Streaming 执行流程
原文连接 http://xiguada.org/spark-streaming-run/
Spark Streaming 是基于spark的流式批处理引擎,其基本原理是把输入数据以某一时间间隔批量的处理,当批处理间隔缩短到秒级时,便可以用于处理实时数据流。
本节描述了Spark Streaming作业的执行流程。
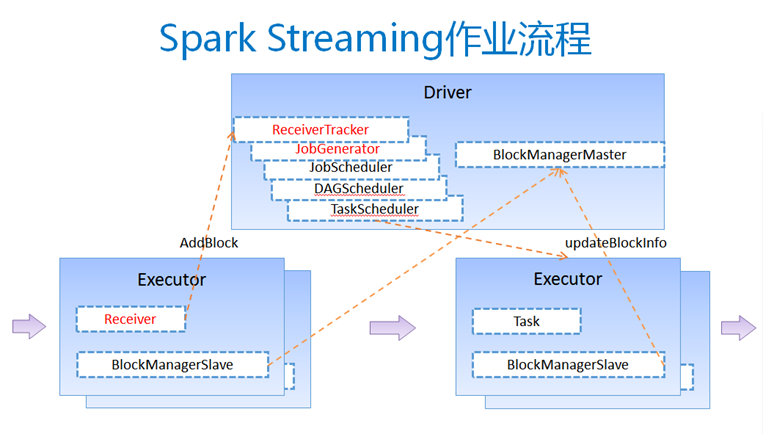
图1 Spark Streaming作业的执行流程
具体流程:
-
客户端提交作业后启动Driver,Driver是park作业的Master。
-
每个作业包含多个Executor,每个Executor以线程的方式运行task,Spark Streaming至少包含一个receiver task。
-
Receiver接收数据后生成Block,并把BlockId汇报给Driver,然后备份到另外一个Executor上。
-
ReceiverTracker维护Reciver汇报的BlockId。
-
Driver定时启动JobGenerator,根据Dstream的关系生成逻辑RDD,然后创建Jobset,交给JobScheduler。
-
JobScheduler负责调度Jobset,交给DAGScheduler,DAGScheduler根据逻辑RDD,生成相应的Stages,每个stage包含一到多个task。
-
TaskScheduler负责把task调度到Executor上,并维护task的运行状态。
-
当tasks,stages,jobset完成后,单个batch才算完成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号