
Spark Streaming实时计算框架介绍
随着大数据的发展,人们对大数据的处理要求也越来越高,原有的批处理框架MapReduce适合离线计算,却无法满足实时性要求较高的业务,如实时推荐、用户行为分析等。 Spark Streaming是建立在Spark上的实时计算框架,通过它提供的丰富的API、基于内存的高速执行引擎,用户可以结合流式、批处理和交互试查询应用。本文将详细介绍Spark Streaming实时计算框架的原理与特点、适用场景。
Spark Streaming实时计算框架
Spark是一个类似于MapReduce的分布式计算框架,其核心是弹性分布式数据集,提供了比MapReduce更丰富的模型,可以在快速在内存中对数据集进行多次迭代,以支持复杂的数据挖掘算法和图形计算算法。Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
Spark Streaming的优势在于:
-
能运行在100+的结点上,并达到秒级延迟。
-
使用基于内存的Spark作为执行引擎,具有高效和容错的特性。
-
能集成Spark的批处理和交互查询。
-
为实现复杂的算法提供和批处理类似的简单接口。
基于云梯Spark on Yarn的Spark Streaming总体架构如图1所示。其中Spark on Yarn的启动流程我的另外一篇文章(《程序员》2013年11月期刊《深入剖析阿里巴巴云梯Yarn集群》)有详细描述,这里不再赘述。Spark on Yarn启动后,由Spark AppMaster把Receiver作为一个Task提交给某一个Spark Executor;Receive启动后输入数据,生成数据块,然后通知Spark AppMaster;Spark AppMaster会根据数据块生成相应的Job,并把Job的Task提交给空闲Spark Executor 执行。图中蓝色的粗箭头显示被处理的数据流,输入数据流可以是磁盘、网络和HDFS等,输出可以是HDFS,数据库等。
图1 云梯Spark Streaming总体架构
Spark Streaming的基本原理是将输入数据流以时间片(秒级)为单位进行拆分,然后以类似批处理的方式处理每个时间片数据,其基本原理如图2所示。
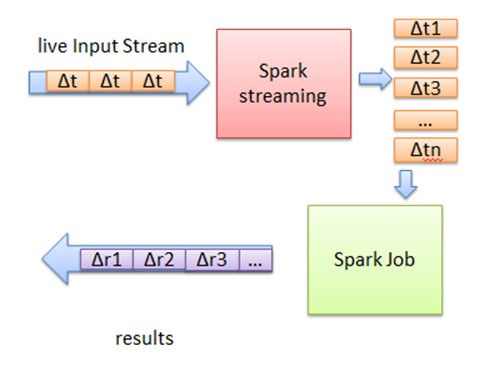
图2 Spark Streaming基本原理图
首先,Spark Streaming把实时输入数据流以时间片Δt (如1秒)为单位切分成块。Spark Streaming会把每块数据作为一个RDD,并使用RDD操作处理每一小块数据。每个块都会生成一个Spark Job处理,最终结果也返回多块。
下面介绍Spark Streaming内部实现原理。
使用Spark Streaming编写的程序与编写Spark程序非常相似,在Spark程序中,主要通过操作RDD(Resilient Distributed Datasets弹性分布式数据集)提供的接口,如map、reduce、filter等,实现数据的批处理。而在Spark Streaming中,则通过操作DStream(表示数据流的RDD序列)提供的接口,这些接口和RDD提供的接口类似。图3和图4展示了由Spark Streaming程序到Spark jobs的转换图。
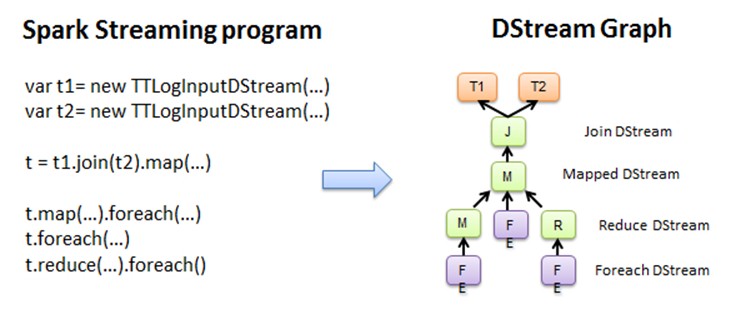
图3 Spark Streaming程序转换为DStream Graph
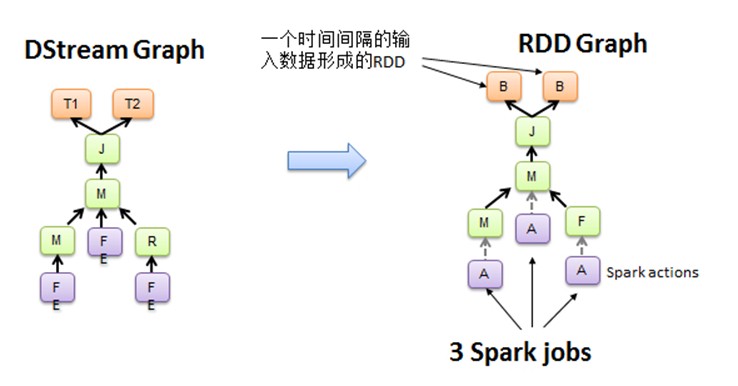
图4 DStream Graph转换为Spark jobs
在图3中,Spark Streaming把程序中对DStream的操作转换为DStream Graph,图4中,对于每个时间片,DStream Graph都会产生一个RDD Graph;针对每个输出操作(如print、foreach等),Spark Streaming都会创建一个Spark action;对于每个Spark action,Spark Streaming都会产生一个相应的Spark job,并交给JobManager。JobManager中维护着一个Jobs队列, Spark job存储在这个队列中,JobManager把Spark job提交给Spark Scheduler,Spark Scheduler负责调度Task到相应的Spark Executor上执行。
Spark Streaming的另一大优势在于其容错性,RDD会记住创建自己的操作,每一批输入数据都会在内存中备份,如果由于某个结点故障导致该结点上的数据丢失,这时可以通过备份的数据在其它结点上重算得到最终的结果。
正如Spark Streaming最初的目标一样,它通过丰富的API和基于内存的高速计算引擎让用户可以结合流式处理,批处理和交互查询等应用。因此Spark Streaming适合一些需要历史数据和实时数据结合分析的应用场合。当然,对于实时性要求不是特别高的应用也能完全胜任。另外通过RDD的数据重用机制可以得到更高效的容错处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号