

ElasticSearch 2 (10) - 在ElasticSearch之下(深入理解Shard和Lucene Index)
ElasticSearch 2 (10) - 在ElasticSearch之下(深入理解Shard和Lucene Index)
摘要
从底层介绍ElasticSearch Shard的内部原理,以及回答为什么使用ElasticSearch有必要了解Lucene的内部工作方式?
-
了解ElasticSearch API的代价
- 构建快速的搜索应用
- 不要任何时候都commit
- 何时使用Stored Fields和Document Values
- Lucene可能不是一个合适的工具
-
了解索引的存储方式
- term vector是索引大小的1/2
- 我移除了20%的文件,但是索引占用空间并未发生任何变化
版本
elasticsearch版本: elasticsearch-2.2.0
内容
索引
毫不夸张的说,如果不了解Lucene索引的工作方式,可以说完全不了解Lucene,对于ElasticSearch更是如此。
-
可以使搜索更快速
- 可以冗余信息
- 根据查询(queries)建立索引
-
在更新速度与查询速度间妥协
需要注意的是搜索的应用场景
- Grep vs. 全文检索(full-text indexing)
- Prefix queries vs. edge n-grams
- Phrase queries vs shingles
如果是进行前缀查询(右模糊匹配)或者是短语查询(phrase queries),ElasticSearch可能不合适,需要做特殊的优化。(在2.x中,ES对以上应用场景都有支持,具体使用方式可以参考:Search in Depth)
-
Lucene索引的速度
创建索引
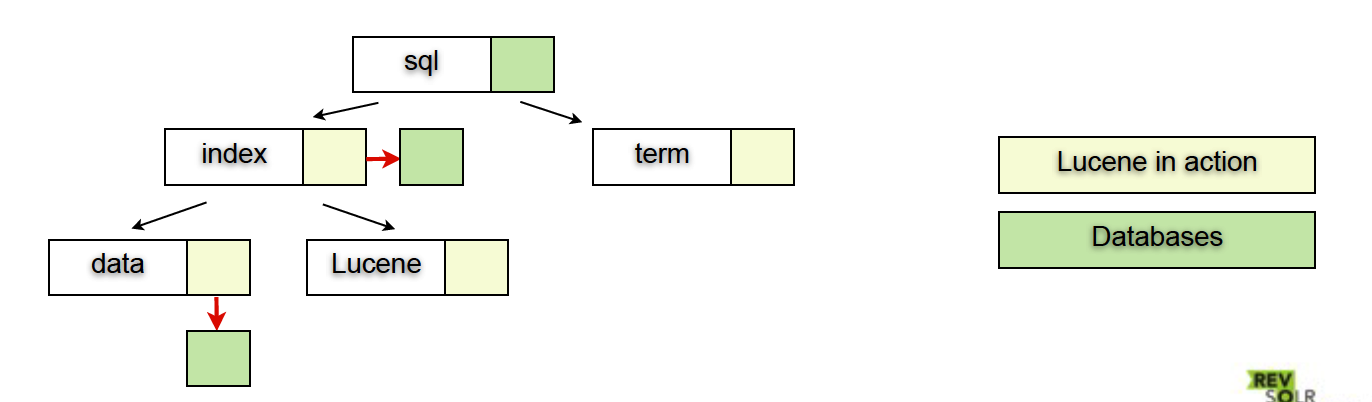
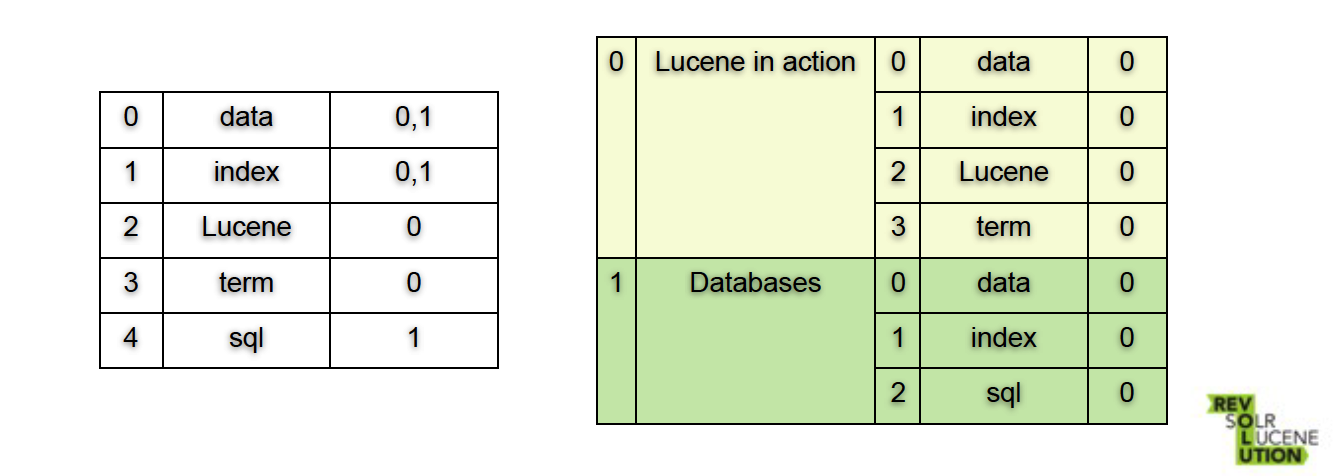
以两个简单的文件为例:Lucene in action和Databases。
假设Lucene in action里有单词
{index, term, data, Lucene}
Databases里有单词
{sql, index, data}
-
树形结构(Tree structure)
对于range query有序
查询的时间复杂度为O(log(n))![]()
一般的关系型数据库大致结构可能是上面这样的一颗B、B+树,但是Lucene是另外一种存储结构。
-
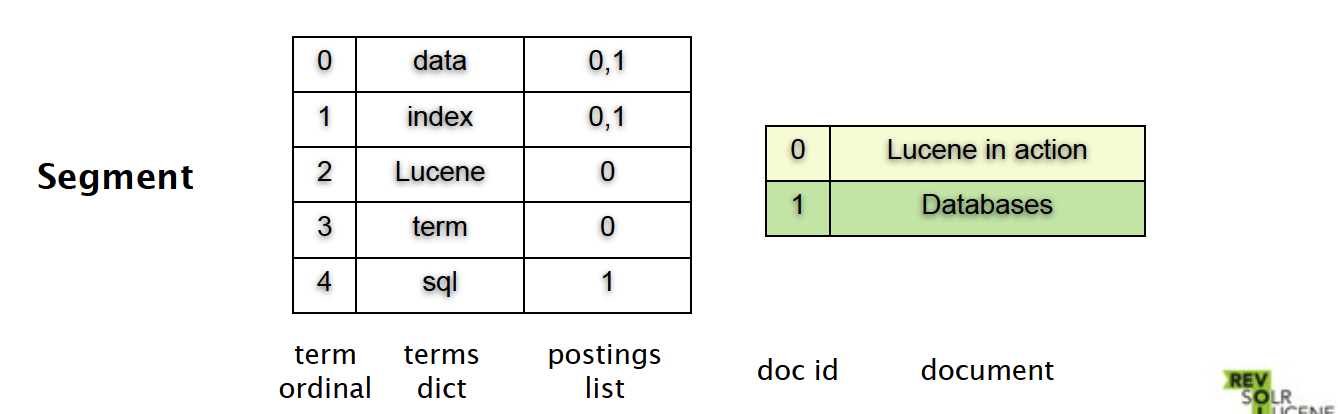
倒排索引(或反向索引Inverted Index)
对于Lucene来说,其主要的存储结构是一个反向索引,它是一个数组,数组里面是一个有序的数据字典。
![]()
这样一个存储结构存在与Lucene的Segment里。
- term ordinal —— 是一个词的序号
- term dict —— 是词的内容
- postings list —— 存放包含词的文件的id序列
- doc id —— 是每个文件的唯一标识
- document —— 存放每个文件的内容
这两种结构的一个重要区别是:在增加或删除文件时,系统会树形结构频繁操作,这个结构是一直变化的,而反向索引可以维持不变(Immutable)。
-
插入?
-
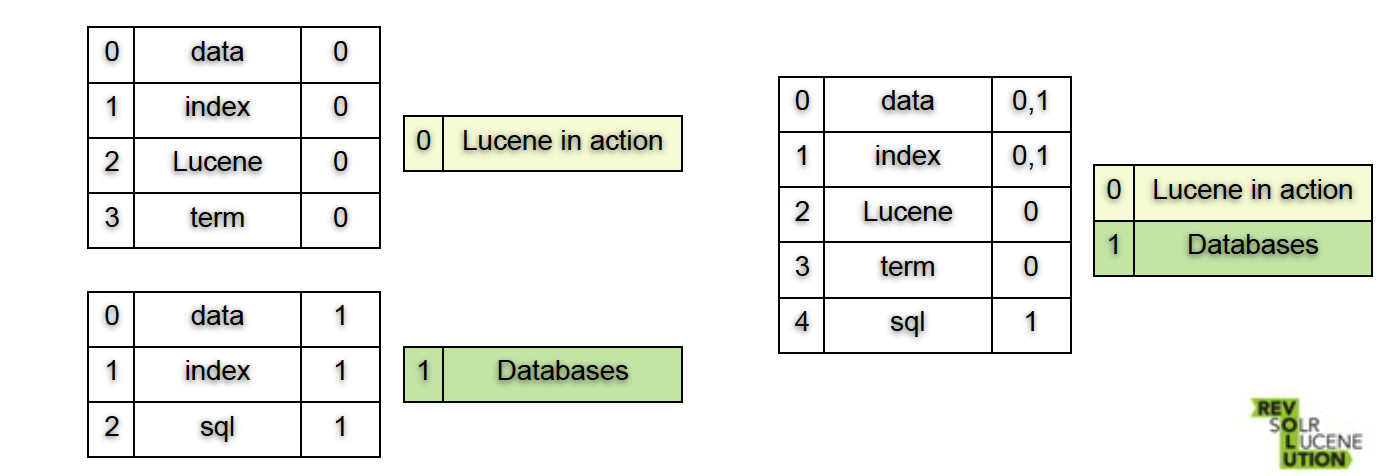
插入 即 创建一个新的segment
-
当有很多segment时,系统会合并segment
这个过程本质上是一个merge sort,做的事情就是- 连接文件
- 合并字典
- 合并postings lists
![]()
-
-
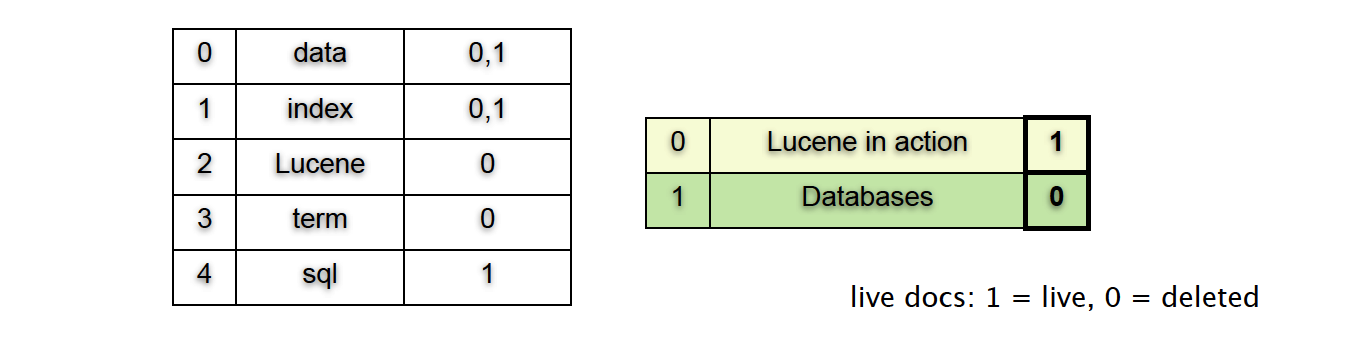
删除?
- 删除要做的只是置一个标志位
- 搜索及merge的时候系统会忽略被删除的文件
- 当有很多删除发生时,系统会自动运行merge
- 被标记为已删除的文件会在merge完成后回收其所占用的存储空间
![]()
-
孰优孰劣?
-
当更新一个文件的时候,我们实际上是创建了一个新的segment,因此
- 单个文件的更新代价高昂,我们需要使用bulk更新
- 所有的写操作都是顺序执行的
-
Segments永远不会被修改
- 文件系统缓存友好
- 不会出现锁的问题
-
Terms 高度去重
- 节省大量高频词所占用的空间
-
文件本身由唯一序号标识
- 跨API通信的时候非常方便
- Lucene可以在单个Query下使用多个索引index
-
Terms 由唯一序号标识
- 对于排序非常重要,只需要比较数字,而非字符串
- 对于faceting(分面搜索)非常重要
-
-
Lucene Index的强大之处(Index intersection)
很多数据库不支持同时使用多个索引,但是Lucene支持
![]()
-
Lucene为postings lists 维护一个skip list(Wiki),如果要搜索如上例子中的“red shoe”,系统参考skip list里的信息可以跳跃检索(“leap-frog”)
-
对于很多数据库,它们会挑选最主要的索引(most selective),而忽略其他
关于详细的index intersection算法以及如何使用skip list的可以参照(nlp.standford.edu)
-
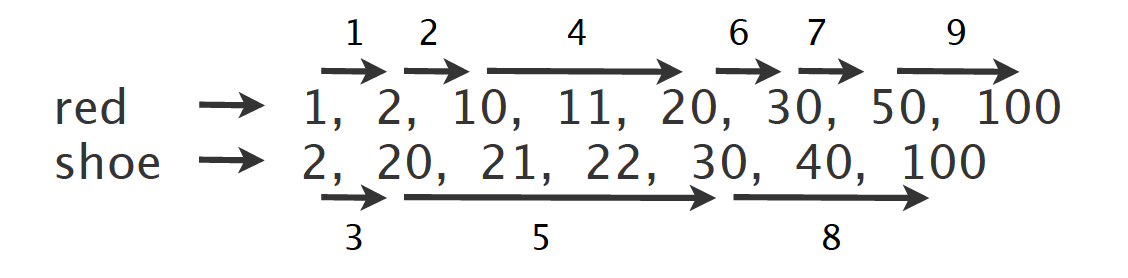
更多索引
-
术语向量(Term vectors)
- 为每个文件都会创建一个反向索引(Inverted Index)
- 适用场景:搜索更相似的内容
- 也可以用作高亮搜索结果
![]()
-
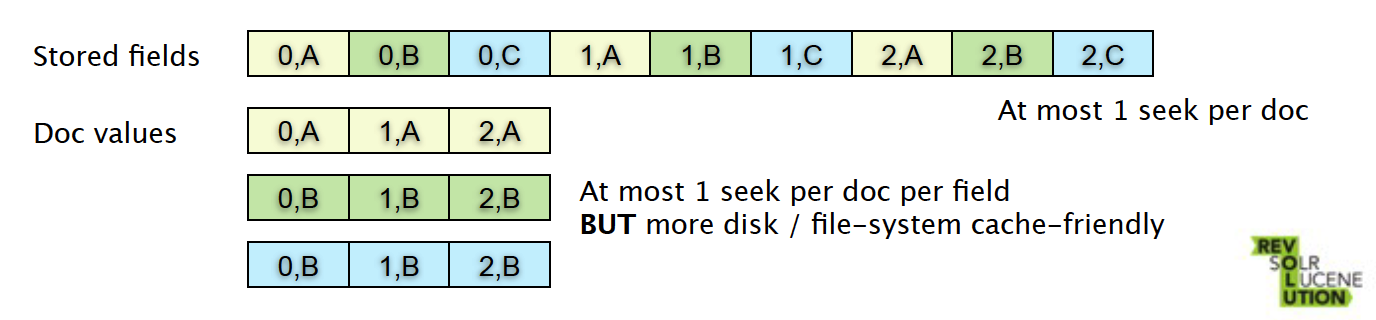
文件值(Document Values)
- 以文件字段为单位进行列式存储
- 适用场景:排序、权重记分
![]()
-
有序(集合)文件值
-
文件有序、字段有序
- 单字段:排序
- 多字段:分面搜索
![]()
-
-
分面搜索(Faceting)
分面是指事物的多维度属性。例如一本书包含主题、作者、年代等分面。而分面搜索是指通过事物的这些属性不断筛选、过滤搜索结果的方法。可以将分面搜索看成搜索和浏览的结合。分面搜索作为一种有效的搜索方式,已经被用在电子商务、音乐、旅游等多个方面。
例如,谷歌音乐的挑歌页面,将歌曲分为节奏、声调、音色、年代、流派等分面
-
根据文件与搜索匹配的情况计数
- 例如,电商网站根据衣服的款式、衣长、尺码、颜色等分面。
-
简单(naive)方案
- 利用哈希表计数(value to count)
- O(#docs) ordinal 查找
- O(#doc) value 查找
-
Lucene方案
- 哈希表(ord to count)
- 最后统计值
- O(#docs) ordinal 查找
- O(#values) value 查找
因为ordinal是密集的,所以可以简单用数组array来表示。
-
-
如何使用API?
ElasticSearch高级API 都是基于Lucene API构建的,这些基础的API包括:
----------------------------------------------------------------------------------------------- API | 用途 | 方法 ----------------------------------------------------------------------------------------------- Inverted index | Term -> doc ids, positions, offsets | AtomicReader.fields ----------------------------------------------------------------------------------------------- Stored fields | Summaries of search results | IndexReader.document ----------------------------------------------------------------------------------------------- Live docs | Ignoring deleted docs | AtomicReader.liveDocs ----------------------------------------------------------------------------------------------- Term vectors | More like this | IndexReader.termVectors ----------------------------------------------------------------------------------------------- Doc values/Norms | Sorting/faceting/scoring | AtomicReader.get*Values ----------------------------------------------------------------------------------------------- -
小结
-
数据有四份重复,只是结构各不相同
- 绝不是浪费空间
- 感谢immutable使数据易于管理
-
Stored Fields和Document Values
-
两种结构为不同的使用场景优化
- 少量文件获取多个字段:Stored Fields
- 大量文件获取少量字段:Document Values
-
![]()
-


文件格式的秘密
-
不能忘的规则
-
保存文件的句柄
不要为每个字段每个文件使用文件
-
避免磁盘寻址
磁盘寻址的时间大概为~10ms
-
不要忽略文件系统的缓存
随机访问小文件还是可以的
-
使用轻压缩
- 更少I/O
- 更小索引
- 文件系统缓存友好
-
-
编码解码
-
文件格式依赖与编码解码
-
默认的编码格式已经优化内存与速度之间的关系
不要使用RAMDirectory、MemoryPostingsFormat、MemoryDocValuesFormat。
-
详细信息参照
http://lucene.apache.org/core/4_5_1/core/org/apache/lucene/codecs/packagesummary.
html
-
-
合适的压缩技术
-
Bit packing / vlnt encoding
- postings lists
- numeric doc values
-
LZ4
- code.google.com/p/lz4
- 轻量压缩算法
- Stored fields, term vectors
-
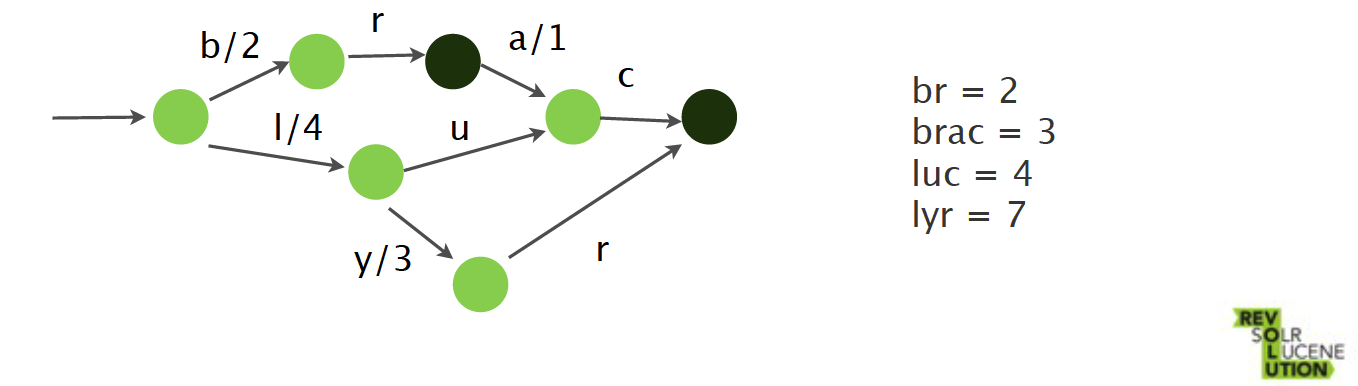
FSTs
- Map<String, ?>
- 键共享前缀(prefix)和后缀(suffix)
- terms index
-
-
TermQuery的背后
-
Terms Index
在索引中查找相应的词
- 在内存中FST存储了词的前缀prefix
- 提供词在字典中的偏移量
- 在不存在时可以快速失败
![]()
-
Terms Dictionary
-
跳到字典偏移的位置
压缩是基于共享前缀的,与“BlockTree term dict”类似
-
顺序读取直到找到特定的Term
![]()
-
-
Postings List
-
跳到postings list偏移量对应位置
-
用改进的FOR(Frame of Reference)进行增量编码
- 增量编码
- 将块拆分为N=128个值的大小
- 每个块使用位压缩(bit packing)
- 如果有剩余文档,使用vlnt压缩
![]()
-
-
Stored Fields
-
对一个子集的doc id,索引存于内存中
高效内存(monotonic)压缩
二分查找
-
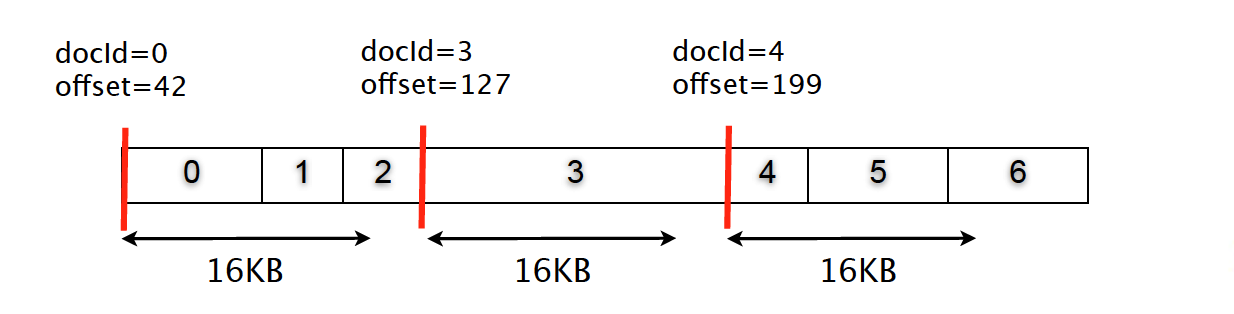
字段
顺序存储
使用16KB块存储压缩
![]()
-
-
-
查询过程小结
-
每个字段2次磁盘寻址
-
每个文件1次磁盘寻址(Stored Fields)
-
terms dict/postings lists都在文件系统的缓存中
此时不会发生磁盘寻址
-
“脉冲”优化
- 对于唯一的term,postings list存储在Terms dict中
- 1次磁盘寻址
- 永远作为主键
-


性能

上图中系统性能出现两次下降,可能的情况是
-
索引增长超过文件系统缓存的大小
Stored Fields不再全部存储于缓存中
-
Terms dict/Postings lists不全在缓存中
参考
参考来源:
SlideShare: What is in a Lucene index?
Youtube: What is in a Lucene index? Adrien Grand, Software Engineer, Elasticsearch
SlideShare: Elasticsearch From the Bottom Up
Youtube: Elasticsearch from the bottom up
Standford Edu: Faster postings list intersection via skip pointers
StackOverflow: how an search index works when querying many words?
StackOverflow: how does lucene calculate intersection of documents so fast?
Lucene and its magical indexes

 浙公网安备 33010602011771号
浙公网安备 33010602011771号