

“做中学”之关于我的系列调查
此篇文章包含了博主技能、C语言、JAVA、公文写作四个板块的自我调查。
博主技能小调查
如果要列举的话,博主有什么技能是比较好的呢?
如果一定要列举出一个的话,算来算去,能符合要求的也就是我的柔韧度了,现在我能够维持压腿时上身紧贴大腿的程度,最好的是侧身压的时候,其次是正面压。
现在的我能够保持以前小学初中上舞蹈课的柔韧程度,除了偶尔想刻意练习一下的请况以外,最主要的因素还是来自于自己的身体原因:如若缺乏运动,我的腿将进入长期不舒服的状态(非心理因素),躺着坐着的感受最为明显,而唯一暂时缓解办法是压腿。拉伸韧带的感觉能大大缓解我腿不舒服的状况。因为这样那样的原因,我保持了随时压腿的习惯,这也让我的柔韧度维持在了一个不错的水平上。
我认为我之所以能够保持自己的柔韧,原因在于我拥有一个“刺激源”,一个能够每天不断提醒我并促使我做出相应练习的“源”。如若没有需要压腿的需求的话,或许我的柔韧度就达不到这么高了。所以,如果要学好一门技术,关键在于找到那个能让你不断奋进,一提起来就精神百倍的事物来,可以是你的某个兴趣点,也可以是某个“压力点”,当然,后者如果加入一点自己的兴趣的话效果会更佳。
你的经验又与他人有什么共通之处么?
读了娄老师的“做中学”系列博客,其中让我印象最深刻的是《优秀的学习方法--做中学(Learning By Doing)》和《「做中学(Learning By Doing)」之乒乓球刻意训练一年总结》这两篇文章,里面提及的“做中学”,“刻意训练”等概念给我留下了很深的印象,其中“刻意训练”里面的“走出舒适区”这一项,令我想起了在网易公开课上看到的TalBen Shahar教授《哈佛大学公开课:幸福课》的第一集(也只看了第一集,不过现在又有动力继续看下去了),里面也曾提及过要走出自己的舒适区这一言论,当时自己内心就很震动,觉得,嗯?我是不是在自己的“舒适区”里待的太久了,都没有学习的动力之类的。如今再次看到这个词,发现我可以做的更好去达到老师所说的“摆脱‘舒适区’,进入‘学习区’学习,要循序渐进,不能进入‘恐慌区’”这个要求。
言归正传,与老师有共通之处的大概有以下几点:
- 都有一个能够激励自己的方法;
- 走出“舒适区”,进入“学习区”;
- “一万小时”:每天坚持不动摇。
C语言
学习C语言的方法
在上《程序设计基础》那门课时,老师有提供一个叫“高级语言程序设计能力训练平台”的网站,我是通过“每天”在做上面的题目前复习预习教材的内容,再在上面做题的方法学习的。当时正是因为在前半段时间,我兴致勃勃地在那上面做了大量的基础的题,看了一遍又一遍的书及笔记,给我的C语言打下了坚实的基础,再以后老师讲课的时候,对C的热情也越来越盛。比较遗憾的是我中间有一段时间没有上那个网站做题,因为前面有不错的基础后面还能较好的融会贯通,渡过了那段时期,但还是成为了我的遗憾,做一件事最重要的还是坚持。
留存代码行数
在电脑里有关C的文件一共有117个,如果按照每个最低有20行的话(大多超过这个数,有的超过了200行数),我共写了超过2340行的代码。
对C理解程度
当时我能够比较好的理解老师所提及的所有知识点,也曾尝试深入理解实践链表、文件等具体编程方法,现在我所能记得的主要是指针以前的主要内容,现在较常用数组及一维指针(基本编程:顺序、选择、循环、函数等当然也包括在内)。现在所涉及的有关C语言编程的实验都是我自己独立编出来的。当然,也因为只用了C语言前半部分的内容,编的程序比较初级。
数组指针与指针数组、函数指针与指针函数的区分
关于数组指针与指针数组、函数指针与指针函数的区分我还是大致能分清的:
数组指针与指针数组
数组指针,例如int (*p)[10];,指的是指针变量指向了一个类型为int型的数组,数组里面每个元素都是int型的,不是指针。
指针数组,例如int *p[10];,指的是数组p中每个元素都是指针,而这些指针所指向的类型是int型,相当于定义了10个指向int型的指针变量。
函数指针与指针函数
函数指针,例如int (*fx)(int a[], int n);,指的是指针指向了一个返回值为int型的函数,定义的是一个指针变量。
指针函数,例如int *fx(int a[], int n);,指的是定义了一个返回值为int型指针的函数,定义的是一个函数。
文件与流、文本文件与二进制文件
文件与流
查了一下相关教材与PPT,其中提及文件与流的有这些内容:
- 综上所述,无论一个C语言文件的内容是什么,它一律把数据看成是由字节构成的序列,即字节流。对文件的存取也是以字节为单位的,输入/输出的数据流仅受程序控制而不受物理符号(如回车换行符)的控制。所以,C语言文件又称为流式文件。
- ANSI C进一步对I/O的概念进行了抽象。就C程序而言,所有的I/O操作只是简单地从程序移进或移出字节的事情。因此,毫不惊奇的是,这种字节流便被称为流(stream)。
- 文件是由许多个字节数据组成的数据流。
-- 分别引用自《 C语言程序设计(第3版)》、《C和指针》、课堂PPT
网上对于流以及文件的解释分别为(摘取):
- 流
- 流(stream)是一个理想化的数据流,实际输入或输出映射到这个数据流。
- 电脑外设控制,磁盘文件输入输出,只要是输入或者输出所产生的数据都是流。
- 流是由输入输出产生的,是用于数据交换或转换的统一的标准(特指这一类的数据)。
- 流可以想象水从水管里出来,这就是一股水流。c语言中流动的不再是水,而是有顺序的,有排列结构的数据。比如100001111100001(二进制)。
- 文件
- 存储在外部介质上数据的集合。
- C语言将文件看作是一个字符(字节)的序列,即一个一个字符(字节)的数据顺序组成。
-- 分别引用自知乎、百度知道1、百度知道1、百度知道2、百度百科
如此看来,在C语言中,流是指输入输出所产生的数据,而文件是指由字节构成的序列,也即是数据流。所以说,两者的联系是文件是一种数据流。
文本文件与二进制文件
区分
文本文件是数字中的每一位都以ASCII码值的形式存储,而二进制文件是数字作为一个整体以二进制的形式存储。
例如“12”,用文本文件的形式存储就是“00110001 00110010 0001”('1'所对应的ASCII码值位00110001,'2'所对应的ASCII码值00110010),用二进制文件形式存储就是“00000000 00001100”(12所对应的二进制形式为1100)。
编程操作
两者编程的基本程序是:
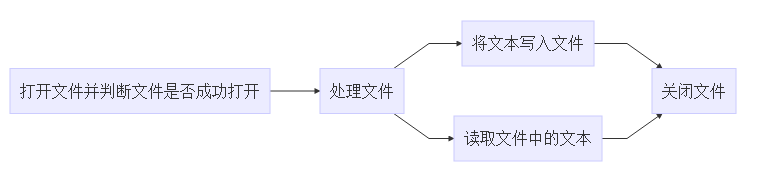
| 文本文件 | 二进制文件 | |
|---|---|---|
| 打开文件 | 文件后缀名为.txt | 文件后缀名为.bin |
| 打开文件 | 文件打开方式为"r"、"w"、"a"等 | 文件打开方式为"rb"、"wb"、"ab"等 |
| 读写文件中的文本 | 按字符读写(字符/字符串)、按格式读写、按数据块读写 | 同左 |
| 其他操作 | 搜索等 | 同左 |
面向过程程序设计
什么叫面向过程程序设计?其解决问题的方法又是什么?
个人印象
对于这个问题,我知道的主要是它区别于面向对象程序设计,其基本原则是“自顶向下,逐步求精,模块化,限制使用goto语句”。
资料总结
查阅了一下相关资料,对此的解说总结如下:
面向过程程序设计是一种以过程为中心的编程思想,具体说就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,它是通过主函数来调用一个个子函数,其方法由顺序、选择和循环这三种基本控制结构来表达。
-- 参考资料:
《全国计算机等级考试二级教程---公共基础知识(2016年版)》 高等教育出版社
模块与源文件
在C语言里面,什么是模块?
在C语言里面模块指的是一个一个函数,一个函数就代表一个模块。
你写过多个源文件的程序吗?
如果多个源文件的程序指的是一个程序里调用多个自己编写的.c文件的话,我并没有写过,我调用的都是C里面本身自带的头文件。
高内聚,低耦合
学过了C语言,你知道什么是“高内聚,低耦合”吗?
知道,指的是一个函数里面的联系紧密,而函数与函数之间的联系不大(除了一个函数调用了另一个函数的时候)。并不会有因为一个函数的内部变化导致连锁反应,其他函数都变了的这种情况。
这个原则如何应用到高质量程序设计中?
在一个程序中,不同的任务尽量用不同的子函数来编写,即将一个大型任务分成一小块一小块,分模块进行,这样能较好的维护调试程序。
数组的复制、查找与排序
- 数组的复制:元素逐个复制;
- 数组的查找:遍历数组中元素进行查找;
- 数组的排序:交换法排序、选择法排序、冒泡法排序等,主要是通过查找及交换来实现。
程序
#include <stdio.h>
#include <windows.h>
#define N 40
void Copy(int a[N], int b[N], int n);
void Search(int a[N], int n);
void Sort(int a[N],int n);
int main(void)
{
int i,n,ret;
int a[N],b[N];
printf("How many elements do you want to input:");
ret = scanf("%d",&n);
if(n<=0 || ret!=1)
{
printf("Wrong! Please input a positive integer.\n");
return 0;
}
printf("Please input a[N]:\n");
for(i=0;i<n;i++)
{
scanf("%d",&a[i]);
}
Copy(a,b,n);
Search(a,n);
Sort(a,n);
system("pause");
return 0;
}
/*函数功能:数组复制*/
void Copy(int a[N], int b[N], int n)
{
int i;
for(i=0;i<n;i++)
{
b[i] = a[i];
}
printf("result of copy:\n");
printf("a[N]:\t");
for(i=0;i<n;i++)
{
printf("%d\t",a[i]);
}
printf("\n");
printf("b[N]:\t");
for(i=0;i<n;i++)
{
printf("%d\t",a[i]);
}
printf("\n");
}
/*函数功能:数组元素查找*/
void Search(int a[N], int n)
{
int i,flag=0;
for(i=0;i<n;i++)
{
if(a[i]==5)
{
flag = 1;
break;
}
}
printf("\nresult of searching:\n");
if(flag) printf("Found 5.\n");
else printf("Not found 5!\n");
}
/*函数功能:数组排序(交换法排序)*/
void Sort(int a[N], int n)
{
int i,j,k;
for(i=0;i<n-1;i++)
{
k = i;
for(j=i+1;j<n;j++)
{
if(a[j]>a[k]) k = j; //由大到小排序,如果想由小到大排序的话,将“>”变为“<”
}
if(k!=i)
{
a[i] = a[i]^a[k];
a[k] = a[k]^a[i];
a[i] = a[i]^a[k];
}
}
printf("\nresult of sorting:\n");
for(i=0;i<n;i++)
{
printf("%d\t",a[i]);
}
printf("\n");
}
程序截图

统计代码行数
完成版
思路
用_findfirst、_findnext、_findclose函数查找硬盘E下的所有.c文件(留存代码都在E盘有备份)。
大致思路展示

注意
代码中的空白、制表符、注释不计入代码行,也即代码中的空白行、注释行不计入代码行部分。
程序
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<io.h>
#include<windows.h>
#define DOUBLE 2
#define N 260
const char *head_name="E:"; //搜索硬盘E下所有文件
void Sumc(char name[N], int *count);
int Searchdotc(char a[N]);
void Deepsearch(int *count, char name[N], char search_name[N], char search_namedd[N], long handle, struct _finddata_t fileinfo);
void Judge(int *count, char name[N], char search_name[N], char search_namedd[N], long *handle, struct _finddata_t *fileinfo);
int main(void)
{
int count=0;
char name[N]; //文件目录名
char search_name[N]; //搜索目录名,不加后缀
char search_namedd[N]; //搜索目录名,加后缀
long handle;
struct _finddata_t fileinfo;
strcpy(search_name,head_name); //赋初值给search_name
strcpy(search_namedd,head_name);
strcat(search_namedd,"\\*.*"); //搜索目录名,加后缀
if((handle=_findfirst(search_namedd,&fileinfo))!=-1L) //第一个目录下的查询
{
if((fileinfo.attrib==16 || fileinfo.attrib==32 || fileinfo.attrib==17)
&& (strcmp(fileinfo.name,".")!=0 && strcmp(fileinfo.name,"..")!=0)) //排除一切"."和".."文件夹所带来的影响
{
strcpy(name,search_name); //将文件目录名整理后赋给name
strcat(name,"\\");
strcat(name,fileinfo.name);
if(Searchdotc(fileinfo.name)) //如果是.c文件的话,统计行数
{
Sumc(name,&count); //根据文件目录名name统计文件代码行数
}
else if((fileinfo.attrib==16 || fileinfo.attrib==17)
&& (strcmp(fileinfo.name,".")!=0 && strcmp(fileinfo.name,"..")!=0)) //如果是文件夹则深入到它的子目录继续调查
{
_findclose(handle); //结束这个目录的句柄
Deepsearch(&count,name,search_name,search_namedd,handle,fileinfo);
}
//if-else区域结束
}
while(_findnext(handle,&fileinfo)==0)//继续搜索这个目录的下一个文件名
{
if((fileinfo.attrib==16 || fileinfo.attrib==32 || fileinfo.attrib==17)
&& (strcmp(fileinfo.name,".")!=0 && strcmp(fileinfo.name,"..")!=0)) //简化运算,搜索范围在文件属性是文件夹+正常、存档+正常、文件夹+正常+只读
{
strcpy(name,search_name); //将文件目录名整理后赋给name
strcat(name,"\\");
strcat(name,fileinfo.name);
Judge(&count,name,search_name,search_namedd,&handle,&fileinfo);
}
}
_findclose(handle); //第一个目录查询结束
}
printf("The total lines is %d\n",count);
system("pause");
return 0;
}
/*统计一个.c文件的代码行数(去掉注释、空白行的影响)*/
void Sumc(char name[N], int *count)
{
int k=0,flag=0,begin1=0,begin2=0,blank=0,c=0; //c判断是否为行头
char ch[DOUBLE]={'0','0'}; //初始化
FILE *fp;
//printf("%s\n",name); 可用作查找展示
if((fp=fopen(name,"r"))==NULL)
{
printf("Failure to open %s!\n",name);
exit(0);
}
while((ch[k]=fgetc(fp))!=EOF)
{
if(ch[k]==' ') //**防空格,制表符也防了,因为在文本文件中,制表符相当于4个空格(已试验)**
{
ch[k]='\n'; //忽略空格和制表符,将之改为'\n',使得下面判断/*是否在行头提供便利
blank = 1; //但为了防止与后面的防空白行判断相冲,加一个改动标志,并在后面每个分支里加一个消除改动标志的语句,这样改动标志的有效期就变为了一个循环时间
}
else if(ch[k]=='/' && c==0) //判断/是否在行头!!!编程需注意有多种情况
{
begin1 = 1; //判断/(/*)行头标志
blank = 0;
}
else if(ch[k]=='*' && ch[!k]=='/' && begin1==1)
{
flag = 1; //防/*注释标志
begin1 = 0; //取消/(/*)行头标志
blank = 0;
}
else if(ch[k]=='/' && ch[!k]=='/' && begin1==1)
{
begin2 = 1; //判断//行头标志
begin1 = 0; //取消/(/*)行头标志
blank = 0;
}
else if(ch[k]=='/' && ch[!k]=='*' && flag==1)
{
flag = 2; // /**/型注释结束,但不取消防/*注释标志flag
blank = 0;
}
else if(ch[k]=='\n' && ch[!k]!='\n' && blank==0 && flag==0 && begin2==0) //防空白行
{
*count = *count+1;
flag = 0;
//blank = 0;
}
else blank = 0;
if(flag==2 && ch[k]=='\n') flag = 0; //取消防/(/*)注释标志,下一行可开始继续计数
if(begin2==1 && ch[k]=='\n') begin2 = 0;//取消防//注释标志,下一行可开始继续计数
if(ch[k]=='\n' && blank==0) c = 0;//c等于0表明下一个字符在行头
else c++; //c不等于0表明下一个字符不在行头
k = !k;
}
fclose(fp);
}
/*搜索倒数两个是否为“.c”,是则返回1,不是则返回0*/
int Searchdotc(char a[N])
{
int n;
n = strlen(a);
if(n!=1 && a[n-2]=='.' && a[n-1]=='c') return 1;
return 0;
}
/*子目录查询*/
void Deepsearch(int *count, char name[N], char search_name[N], char search_namedd[N], long handle, struct _finddata_t fileinfo)
{
long handle1;
struct _finddata_t fileinfo1;
char name1[N],search_name1[N],search_namedd1[N];
handle1 = handle;
fileinfo1 = fileinfo;
strcpy(name1,name);
strcpy(search_name1,search_name);
strcpy(search_namedd1,search_namedd);
strcpy(search_name1,name1); //赋初值给search_name
strcpy(search_namedd1,name1);
strcat(search_namedd1,"\\*.*"); //搜索目录名,加后缀
if((handle1=_findfirst(search_namedd1,&fileinfo1))!=-1L) //这个子目录下的查询
{
if(strcmp(fileinfo1.name,".")==0 || strcmp(fileinfo1.name,"..")==0) ; //空目录下需排除"."和".."文件夹,否则会无限循环,但为什么?"."和".."又是什么?
else if(fileinfo1.attrib==16 || fileinfo1.attrib==32 || fileinfo1.attrib==17)
{
strcpy(name1,search_name1); //将文件目录名整理后赋给name
strcat(name1,"\\");
strcat(name1,(fileinfo1).name);
if(Searchdotc(fileinfo1.name)) //如果是.c文件的话,统计行数
{
Sumc(name1,count); //根据文件目录名name统计文件代码行数
}
else if((fileinfo1.attrib==16 || fileinfo1.attrib==17)
&& (strcmp(fileinfo1.name,".")!=0 && strcmp(fileinfo1.name,"..")!=0)) //如果是文件夹则深入到它的子目录继续调查
{
_findclose(handle1); //结束这个目录的句柄
Deepsearch(count,name1,search_name1,search_namedd1,handle1,fileinfo1); //除count外其他变量不混用
}
//if-else区域结束
}
while(_findnext(handle1,&fileinfo1)==0)//继续搜索这个目录的下一个文件名
{
if((fileinfo1.attrib==16 || fileinfo1.attrib==32 || fileinfo1.attrib==17)
&& (strcmp(fileinfo1.name,".")!=0 && strcmp(fileinfo1.name,"..")!=0))
{
strcpy(name1,search_name1); //将文件目录名整理后赋给name
strcat(name1,"\\");
strcat(name1,(fileinfo1).name);
Judge(count,name1,search_name1,search_namedd1,&handle1,&fileinfo1);
}
}
_findclose(handle1); //这个子目录查询结束
}
}
/*判断这个文件是.c还是文件夹*/
void Judge(int *count, char name[N], char search_name[N], char search_namedd[N], long *handle, struct _finddata_t *fileinfo)
{
strcpy(name,search_name); //将文件目录名整理后赋给name
strcat(name,"\\");
strcat(name,(*fileinfo).name);
if(Searchdotc((*fileinfo).name)) //如果是.c文件的话,统计行数
{
Sumc(name,count); //根据文件目录名name统计文件代码行数
}
else if(((*fileinfo).attrib==16 || (*fileinfo).attrib==17)
&& (strcmp((*fileinfo).name,".")!=0 && strcmp((*fileinfo).name,"..")!=0)) //如果是文件夹则深入到它的子目录继续调查
{
Deepsearch(count,name,search_name,search_namedd,*handle,*fileinfo);
}
}
截图
(因为硬盘中有比较多的.c文件是以全注释的形式存在(程序都在注释里,这些文件的原存放地址在练习网站上,以注释的形式保存在E盘里),所以去掉注释的话代码行数较少。)

体会
为了写这个程序,我有以下收获:
- 初步掌握如何使用_findfirst、_findnext、_findclose函数;
- 回顾基本文件操作编程方法;
- 尝试遍历硬盘文件;
- 了解文本文件;
- 尝试编写如何让空白行、注释行不计入代码行数;
- 借助网络学习掌握新的知识。
不足
编写的程序还是有点繁琐,有待改进。
参考资料
断点
你知道什么叫断点吗?给出自己调试程序的例子。
断点的意思是在某行代码处设置断点的话,调试程序时会直接从头运行到你所设置的地方停止,方便调试之后的程序。
例子
几乎每一个较长的程序我都单步调试过。
1.设置断点
鼠标左键点击红点所在位置,出现红点。

2. 调试程序
点击Run to cursor键  ,黄色三角形光标将出现在红点处。
,黄色三角形光标将出现在红点处。
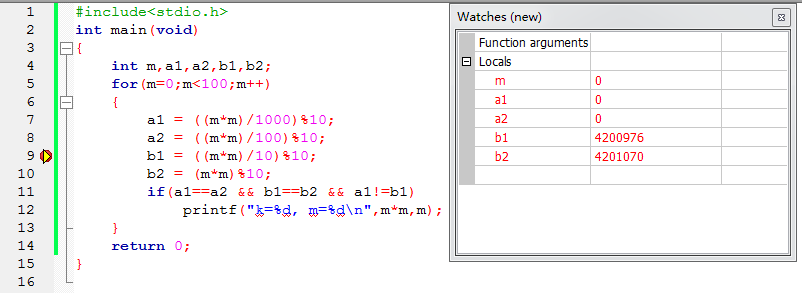
Tip1:初次运行这个软件的话,需要先点击 ,选择下拉列表里的Watches,显示变量变化过程。
,选择下拉列表里的Watches,显示变量变化过程。
Tip2:注意如果想实现这一步的话,需一开始将文件创建在没有中文名的目录下,否则不能实现,如果想创建在有中文名的目录下又想单步调试的话,可以跳过这一条直接执行下一个步骤。
3. 继续调试
点击  程序运行到下一行,点击
程序运行到下一行,点击  进入到子函数里面。
进入到子函数里面。
JAVA
学习目标
具体目标
每天能够坚持学习又或是编写一点JAVA。
如何通过刻意训练提高程序设计能力和培养计算思维
- 刻意培养自己的学习氛围,通过塑造良好的学习氛围推动自己走出“舒适区”,进入“学习区”;
- 每天练习一小部分;
- 与他人进行有效的沟通,促使自己不断前进。
如何通过“做中学”实现你的目标
- 实践与理论相结合,既不能一味编程,也不能只读书本;
- 及时反馈问题;
- 进行大量基础练习。
公文写作
我的写作能力
我的写作能力如果是认真完成一项公文的话,还是可以的,不过还需要磨练。
所以,若要提高我的公文写作能力,当务之急是多积累见识,涉猎面广了,兴趣自然也就上来了,不至于面对一项工作而茫然不知,感到“前途漫漫而远之,吾将上下而求索”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号