Python全栈之路6--正则表达式
正则本身就是一门语言:
正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,在文本处理方面功能非常强大,也经常用作爬虫,来爬取特定内容,Python本身不支持正则,但是通过导入re模块,Python也能用正则表达式,下面就来讲一下python正则表达式的用法。
下图列出了Python支持的正则表达式元字符和语法:
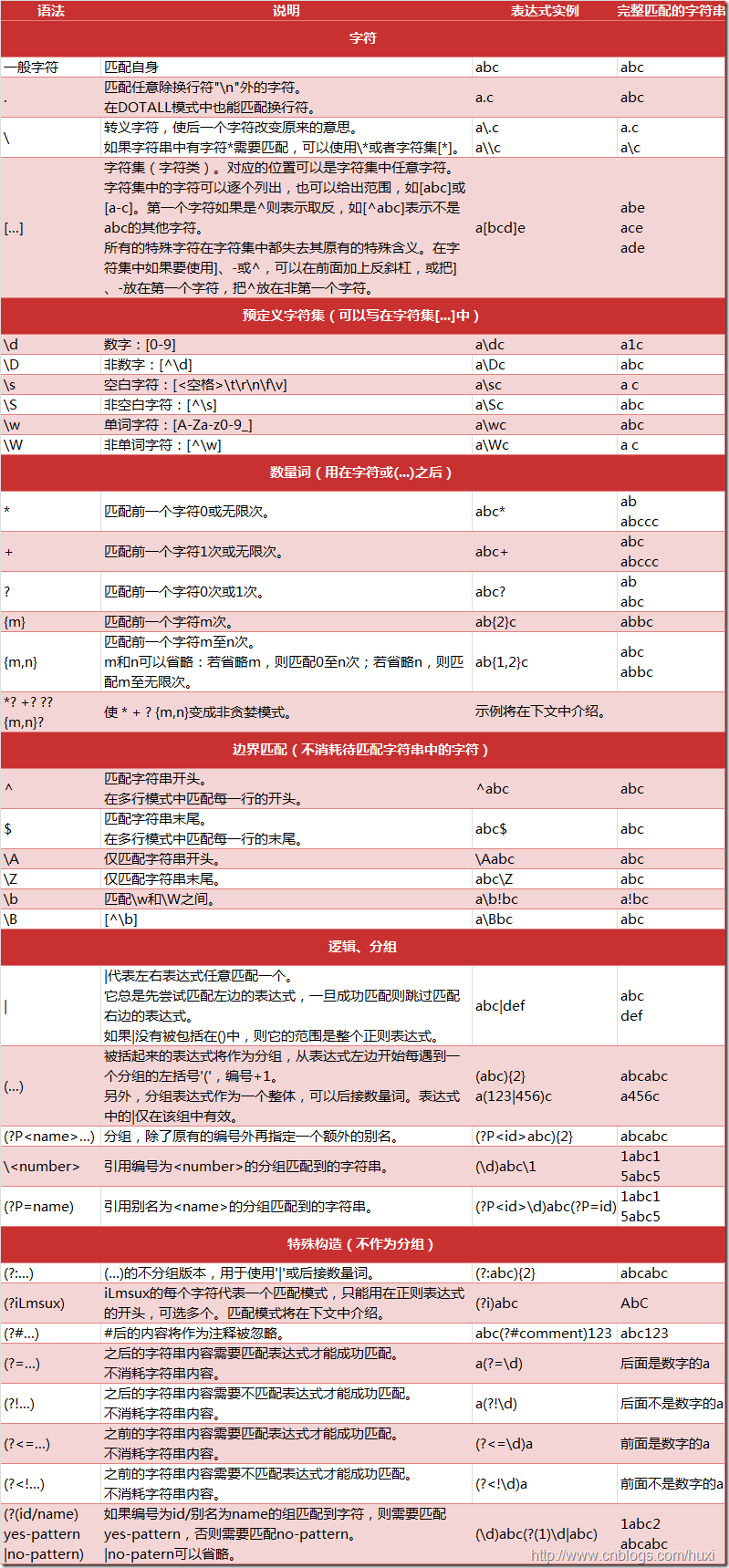
一、Python正则的字符:
1、普通字符:
大多数的字符和字母都会和自身匹配
2、元字符:
元字符:. ^ $ * + ? { } [ ] | ( ) \
2.1、[]详解
例如,[abc] 将匹配"a", "b", 或 "c"中的任意一个字符;也可以用区间[a-c]来表示同一字符集,和前者效果一致。如果你只想匹配小写字母,那么 RE 应写成 [a-z].
2.2()详解
>>> p = re.compile('(a(b)c)d')
>>> m = p.match('abcd')
>>> m.group(0)
'abcd'
>>> m.group(1)
'abc'
>>> m.group(2)
'b'
2.3:+、*、?、{}详解
贪婪模式和非贪婪模式:
从前面的描述可以看到'*','+'和'?'都是贪婪的,但这也许并不是我们说要的,所以,可以在后面加个问号,将策略改为非贪婪,只匹配尽量少的RE。示例,
体会两者的区别: <STRONG>findall 只匹配输出 分组内容如果是分组的话,如果不是分组的话都输出匹配到输出的内容</STRONG> 后面介绍
>>> re.findall(r"a(\d+?)","a234b") # 非贪婪模式 如果\d+匹配的是两个数字的话,
['2']
>>> re.findall(r"a(\d+)","a234b")
['234']<BR>
正则匹配的时候的 r 的作用
>>> re.findall(r"\bI","I love u") ['I'] >>> re.findall(r"\bIl","Ilove u") ['Il']
二、re模块的各种方法
1、findall (获取字符串中所有的匹配字符串)
findall(),可以将匹配到的结果以列表的形式返回,如果匹配不到则返回一个空列表,下面来看一下代码中的使用
import re
l=re.findall(r'\d','4g6gggg9,9') # \d代表数字,将匹配到的元素放到一个列表里
print(l) # ['4', '6', '9', '9']
print(re.findall(r'\w','ds.._ 4')) # ['d', 's', '_', '4'],匹配字母数字下划线
print(re.findall(r'^sk','skggj,fd,7')) # 以sk开头的,['sk']
print(re.findall(r'^sk','kggj,fd,7')) # []
print(re.findall(r'k{3,5}','ffkkkkk')) # 取前面一个字符‘k'的3到5次,['kkkkk']
print(re.findall(r'a{2}','aasdaaaaaf')) # 匹配前一个字符a两次,['aa', 'aa', 'aa']
print(re.findall(r'a*x','aaaaaax')) # ['aaaaaax'] 匹配前面一个字符0次或多次,贪婪匹配
print(re.findall(r'\d*', 'www33333')) # ['', '', '', '33333', '']
print(re.findall(r'a+c','aaaacccc')) # ['aaaac'] 匹配前面一个字符的一次或多次,贪婪匹配
print(re.findall(r'a?c','aaaacccc')) # ['ac', 'c', 'c', 'c'] 匹配前面一个字符的0次或1次
print(re.findall(r'a[.]d','acdggg abd')) # .在[]里面失去了意义,所以结果为[]
print(re.findall(r'[a-z]','h43.hb -gg')) # ['h', 'h', 'b', 'g', 'g']
print(re.findall(r'[^a-z]','h43.hb -gg')) # 取反,['4', '3', '.', ' ', '-']
print(re.findall(r'ax$','dsadax')) # 以'ax'结尾 ['ax']
print(re.findall(r'a(\d+)b','a23666b')) # ['23666']
print(re.findall(r'a(\d+?)b','a23666b')) # ['23666']前后均有限定条件,则非贪婪模式失效
print(re.findall(r'a(\d+)','a23b')) # ['23']
print(re.findall(r'a(\d+?)','a23b')) # [2] 加上一个?变成非贪婪模式
find 的高级用法:?:
默认是取分组()内的信息,但是我想让分组外的匹配信息也取到,就要用到 ?:
>>> import re >>> re.findall(r"www.(baidu|laonanhai).com","sdfsd www.baidu.comwww.laonanhai.com") ['baidu', 'laonanhai'] >>> re.findall(r"www.(?:baidu|laonanhai).com","sdfsd www.baidu.comwww.laonanhai.com") ['www.baidu.com', 'www.laonanhai.com']
finditer():迭代查找
>>> p = re.compile(r'\d+')
>>> iterator = p.finditer('12 drumm44ers drumming, 11 ... 10 ...')
>>> for match in iterator:
... match.group() , match.span()
...
('12', (0, 2))
('44', (8, 10))
('11', (24, 26))
('10', (31, 33))
2、match(pattern, string, flag=0)
- 正则表达式
- 要匹配的字符串
- 标志位,用于控制正则表达式的匹配方式
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
方法: 1.group([group1, …]): 获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。 2.groups([default]): 以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。 3.groupdict([default]): 返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。 4.start([group]): 返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。 5.end([group]): 返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。 6.span([group]): 返回(start(group), end(group))。 7.expand(template): 将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
3、search(pattern, string, flag=0)
根据模型去字符串中匹配指定内容,匹配单个,只匹配一次,可以结合split 将匹配到内容分割 拼接 然后再次循环查找。因为findall尽管可以找到所有,但是在处理分组()时候分组外的内容匹配不到。而findall是返回列表 后面会有介绍
4、grouop和groups
group(0) 显示全部
group(1) 显示第一个分组()
group(2) 显示第二个分组()
如果没有分组或超出分组个数就会报错
5、sub(pattern, repl, string, count=0, flag=0)
用于替换匹配的字符串 pattern内必须为正则表达式,不能是正则表达式search或findall 查找到的赋值变量
比如我的计算器处理括号的方法,用正则search匹配到后,不能直接将变量出入 sub的pattern,因为不起作用
sub 疑点
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
subn方法 返回总共替换的次数
>>> re.subn(r'\d','ZZ','23*,5sfds.6hsdf')
('ZZZZ*,ZZsfds.ZZhsdf', 4)
subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
返回 (sub(repl, string[, count]), 替换次数)。
import re
p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
print p.subn(r'\2 \1', s)
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print p.subn(func, s)
### output ###
# ('say i, world hello!', 2)
# ('I Say, Hello World!', 2)
6、split(pattern, string, maxsplit=0, flags=0)
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
import re
p = re.compile(r'\d+')
print p.split('one1two2three3four4')
### output ###
# ['one', 'two', 'three', 'four', '']
7 re.compile(strPattern[, flag]): compile 编译方法
如果一个匹配规则,以后要使用多次,就可以先将其编译,以后就不用每次都在去写匹配规则
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为
Pattern对象。
第二个参数flag是匹配模式,取值可以使用按位或运算符'|'
表示同时生效,比如re.I |
re.M
可以把正则表达式编译成一个正则表达式对象。可以把那些经常使用的正则
表达式编译成正则表达式对象,这样可以提高一定的效率。下面是一个正则表达式
对象的一个例子:
import re text = "JGood is a handsome boy, he is cool, clever, and so on..." regex = re.compile(r'\w*oo\w*') print regex.findall(text) #查找所有包含'oo'的单词
三、原生字符串、编译、分组
1、原生字符串
细心的人会发现,我每一次在写匹配规则的话,都在前面加了一个r,为什么要这样写,下面从代码上来说明,
import re
#“\b”在ASCII 字符中代表退格键,\b”在正则表达式中代表“匹配一个单词边界”
print(re.findall("\bblow","jason blow cat")) #这里\b代表退格键,所以没有匹配到
print(re.findall("\\bblow","jason blow cat")) #用\转义后这里就匹配到了 ['blow']
print(re.findall(r"\bblow","jason blow cat")) #用原生字符串后就不需要转义了 ['blow']
你可能注意到我们在正则表达式里使用“\d”,没用原始字符串,也没出现什么问题。那是因为ASCII 里没有对应的特殊字符,所以正则表达式编译器能够知道你指的是一个十进制数字。但是我们写代码本着严谨简单的原理,最好是都写成原生字符串的格式。
2、编译
如果一个匹配规则,我们要使用多次,我们就可以先将其编译,以后就不用每次都在去写匹配规则,下面来看一下用法
import re
c=re.compile(r'\d') #以后要在次使用的话,只需直接调用即可
print(c.findall('as3..56,')) #['3', '5', '6']
3、分组
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组,可以有多个组,分组的用法很多,这里只是简单的介绍一下
import re
print(re.findall(r'(\d+)-([a-z])','34324-dfsdfs777-hhh')) # [('34324', 'd'), ('777', 'h')]
print(re.search(r'(\d+)-([a-z])','34324-dfsdfs777-hhh').group(0)) # 34324-d 返回整体
print(re.search(r'(\d+)-([a-z])','34324-dfsdfs777-hhh').group(1)) # 34324 获取第一个组
print(re.search(r'(\d+)-([a-z])','34324-dfsdfs777-hhh').group(2)) # d 获取第二个组
print(re.search(r'(\d+)-([a-z])','34324-dfsdfs777-hhh').group(3)) # IndexError: no such group
print(re.search(r"(jason)kk\1","xjasonkkjason").group()) #\1表示应用编号为1的组 jasonkkjason
print(re.search(r'(\d)gg\1','2j333gg3jjj8').group()) # 3gg3 \1表示使用第一个组\d
# 下面的返回None 为什么是空?而匹配不到3gg7,因为\1的不仅表示第一组,而且匹配到的内容也要和第一组匹配到的内容相同,第一组匹配到3,第二组匹配到7 不相同所以返回空
print(re.search(r'(\d)gg\1','2j333gg7jjj8'))
print(re.search(r'(?P<first>\d)abc(?P=first)','1abc1')) # 1abc1 声明一个组名,使用祖名引用一个组
r=re.match('(?P<n1>h)(?P<n2>\w+)','hello,hi,help') # 组名的另外一种用法
print(r.group()) # hello 返回匹配到的值
print(r.groups()) # ('h', 'ello')返回匹配到的分组
print(r.groupdict()) # {'n2': 'ello', 'n1': 'h'} 返回分组的结果,并且和相应的组名组成一个字典
# 分组是从已经匹配到的里面去取值
origin ="hello alex,acd,alex"
print(re.findall(r'(a)(\w+)(x)',origin)) # [('a', 'le', 'x'), ('a', 'le', 'x')]
print(re.findall(r'a\w+',origin)) # ['alex', 'acd', 'alex']
print(re.findall(r'a(\w+)',origin)) # ['lex', 'cd', 'lex']
print(re.findall(r'(a\w+)',origin)) # ['alex', 'acd', 'alex']
print(re.findall(r'(a)(\w+(e))(x)',origin)) # [('a', 'le', 'e', 'x'), ('a', 'le', 'e', 'x')]
r=re.finditer(r'(a)(\w+(e))(?P<name>x)',origin)
for i in r :
print(i,i.group(),i.groupdict())
'''
[('a', 'le', 'e', 'x'), ('a', 'le', 'e', 'x')]
<_sre.SRE_Match object; span=(6, 10), match='alex'> alex {'name': 'x'}
<_sre.SRE_Match object; span=(15, 19), match='alex'> alex {'name': 'x'}
'''
print(re.findall('(\w)*','alex')) # 匹配到了alex、但是4次只取最后一次即 x 真实括号只有1个
print(re.findall(r'(\w)(\w)(\w)(\w)','alex')) # [('a', 'l', 'e', 'x')] 括号出现了4次,所以4个值都取到了
origin='hello alex sss hhh kkk'
print(re.split(r'a(\w+)',origin)) # ['hello ', 'lex', ' sss hhh kkk']
print(re.split(r'a\w+',origin)) # ['hello ', ' sss hhh kkk']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号