C#图解教程 第二十五章 其他主题
其他主题
概述
在本章中,我会介绍使用C#时的一些重要而又不适合放到其他章节的主题,包括字符串操作、可空类型、Main方法、文档注释以及嵌套类型。
字符串
对于内部计算来说0和1很适合,但是对于人类可读的输入和输出,我们需要字符串。BCL提供了很多能让字符串操作变得更简单的类。
C#预定义的string类型代表了.NET的System.String类。对于字符串,最需要理解的概念如下。
- 字符串是Unicode字符串数组
- 字符串是不可变的(immutable ) 它们不能被修改
string类型有很多有用的字符串操作成员,包括允许我们进行诸如检测长度、改变大小写、连接字符串等一些有用的操作。下表列出了其中一些最有用的成员。

从上表中的大多数方法的名字来看,好像它们都会改变字符串对象。其实,它们不会改变字符串而是返回了新的副本。对于一个string,任何“改变”都会分配一个新的恒定字符串。
例如,下面的代码声明并初始化了一个叫做s的字符串。第一个WriteLine语句调用了s的ToUpper方法,它返回了字符串中所有字母为大写形式的副本。最后一行输出了s的值,可以看到,字符串并没有改变。
string s = "Hi there."; Console.WriteLine("{0}",s.ToUpper()); //输出所有字母为大写的副本 Console.WriteLine("{0}", s); //字符串没有变

笔者自己编码时,发现上表中很有用的一个方法是Split。它将一个字符串分隔为若干子字符串,并将它们以数组的形式返回。将一组按预定位置分隔字符串的分隔符传给Split方法,就可以指定如何处理输出数组中的空元素。当然,原始字符串依然不会改变。
下面的代码显示了一个使用Split方法的示例。在这个示例中,分隔符由空字符和4个标点符号组成。
class Program { static void Main() { string s1="hi there!this,is:a string."; char[] delimiters={' ','!',',',':','.'}; string[] words=s1.Split(delimiters,StringSplitOption.RemoveEmptyEntries); Console.WriteLine("Word Count:{0}\n\rThe Words…",words.Length); foreach(string s in words) { Console.WriteLine(" {0}",s); } } }

使用 StringBuilder类
StringBuilder类可以帮助你动态、有效地产生字符串,并且避免创建许多副本。
- StringBuilder类是BCL的成员,位于System.Text命名空间中
- StringBuilder对象是Unicode字符的可变数组
例如,下面的代码声明并初始化了一个StringBuilder类型的字符串,然后输出了它的值。第四行代码通过替换初始字符串的一部分改变了其实际对象。当输出它的值,隐式调用ToString时,我们可以看到,和string类型的对象不同,StringBuilder对象确实被修改了。
using System; using System.Text; class Program { static void Main() { StringBuilder sb = new StringBuilder( "Hi there."); Console.WriteLine( "{0}", sb.ToString()); sb.Replace( "Hi", "Hello"); Console.WriteLine( "{0}", sb.ToString()); } }

当依据给定的字符串创建了StringBuilder对象之后,类分配了一个比当前字符串长度更长的缓冲区。只要缓冲区能容纳对字符串的改变就不会分配新的内存。如果对字符串的改变需要的空间比缓冲区中的可用空间多,就会分配更大的缓冲区,并把字符串复制到其中。和原来的缓冲区一样,新的缓冲区也有额外的空间。
要获取StringBuilder对应的字符串内容,我们只需要调用它的ToString方法即可。
把字符串解析为数据值
字符串都是Unicode字符的数组。例如,字符串"25.873"是6个字符而不是一个数字。尽管它看上去像数字,但是我们不能对它使用数学函数。把两个字符串进行“相加”只会串联它们。
- 解析允许我们接受表示值的字符串,并且把它转换为实际值
- 所有预定义的简单类型都有一个叫做Parse的静态方法,它接受一个表示这个类型的字符串值,并且把它转换为类型的实际值
以下语句给出了一个使用Parse方法语法的示例。注意,Parse是静态的,所以我们需要通过目标类型名来调用它。
double dl = double.Parse("25.873"); ↑ ↑ 目标类型 要转换的字符串
以下代码给出了一个把两个字符串解析为double型值并把它们相加的示例:
static void Main() { string s1 = "25.873"; string s2 = "36.240"; double dl = double.Parse(s1); double d2 = double.Parse(s2); double total = dl + d2; Console.WriteLine("Total: {0}", total); }
这段代码产生了如下输出:

关于Parse有一个常见的误解,由于它是在操作字符串,会被认为是string类的成员。其实不是,Parse根本不是一个方法,而是由目标类型实现的很多个方法。
Parse方法的缺点是如果不能把string成功转换为目标类型的话会抛出一个异常。异常是昂贵的操作,应该尽可能在编程中避免异常。TryParse方法可以避免这个问题。有关TryParse需要知道的亟要事项如下。
- 每一个具有Parse方法的内置类型同样都有一个TryParse方法
- TryParse方法接受两个参数并且返回一个bool值
- 第一个参数是你希望转换的字符串
- 第二个是指向目标类型变量的引用的out参数
- 如果TryParse成功,返回true,否则返回false
如下代码演示了使用int.TryParse方法的例子:
class Program { static void Main() { string parseResultSummary; string stringFirst = "28"; int intFirst; 输入字符串 输出变置 ↓ ↓ bool success = int.TryParse( stringFirst, out intFirst ); parseResultSummary = success ? "was successfully parsed" :"was not successfully parsed"; Console.WriteLine( "String {0} {1}", stringFirst, parseResultSummary ); string stringSecond = "vt750"; int intSecond; 输入字符串 输出变最 ↓ ↓ success = int.TryParse( stringSecond, out intSecond ); parseResultSummary = success ? "was successfully parsed" :"was not successfully parsed"; Console.WriteLine( "String {0} {1}", stringSecond, parseResultSummary ); } }

关于可空类型的更多内容
在第3章中我们已经介绍过了可空类型。你应该记得,可空类型允许我们创建一个值类型变量并且可以标记为有效或无效,这样我们就可以有效地把值类型设置为"null"。我本来想在第3章中介绍可空类型及其他内置类型,但是既然现在你对C#有了更深入的了解,现在正是时候介绍其更复杂的方面。
复习一下,可空类型总是基于另外一个叫做基础类型(underlying type)的已经被声明的类型。
- 可以从任何值类型创建可空类型,包括预定义的简单类型
- 不能从引用类型或其他可空类型创建可空类型
- 不能在代码中显式声明可空类型,只能声明可空类型的变童。之后我们会看到,编译器会使用泛型隐式地创建可空类型
要创建可空类型的变量,只需要在变量声明中的基础类型的名字后面加一个问号。
例如,以下代码声明了一个可空int类型的变量。注意,后缀附加到类型名--而不是变量名称。
后缀 ↓ int? myInt=28;
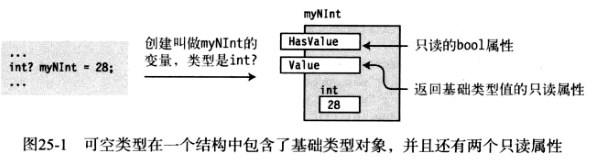
有了这样的声明语句,编译器就会产生可空类型并关联变量类型。可空类型的结构如下图所示。
- 基础类型的实例
- 几个重要的只读属性
- HasValue属性是bool类型,并且指示值是否有效
- Value属性是和基础类型相同的类型并且返回变最的值--如果变量有效的话
使用可空类型基本与使用其他类型的变量一样。读取可空类型的变量返回其值。但是你必须确保变量不是null的,尝试读取一个null的变量会产生异常。
- 跟任何变量一样,要获取可空类型变量的值,使用名字即可
- 要检测可空类型是否具有值,可以将它和null比较或者检查它的HasValue属性
int? myInt1=15; if(myInt1!=null) { Console.WriteLine("{0}",myInt1); }
你可以像下面那样显式使用两个只读属性。读取可空类型的变量返回其值。但是你必须确保变量不是null的,尝试读取一个null的变量会产生异常。
可空类型和相应的非可空类型之间可轻松实现转换。有关可空类型转换的重要事项如下:
- 非可空类型和相应的可空版本之间的转换是隐式的,也就是说,不需要强制转换
- 可空类型和相应的可空版本之间的转换是显式的
例如,下面的代码行显示了两个方向上的转换。第一行int类型的字面量隐式转换为int?类型的值,并用于初始化可空类型的变量。第二行,变量显式转换为它的非可空版本。
int? myInt1 = 15; // 将int隐式转换为 int? int regInt = (int) myInt1; // 将int?显式转换为int
为可空类型赋值
可以将以下三种类型的值赋给可空类型的变量:
- 基础类型的值
- 同一可空类型的值
- Null值
以下代码分別给出了三种类型赋值的示例:
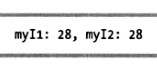
int? myI1,myI2,myI3 myI1 = 28; //基础类型的值 myI2 = myI1; //可空类型的值 myI3 = null; //null Console.WriteLine("myI1: {0}, myI2: {1}", myI1, myI2);
使用空接合运算符
标准算术运算符和比较运算符同样也能处理可空类型。还有一个特别的运算符叫做空接合运算符(null coalescing operator),它允许我们在可空类型变量为null时返回一个值给表达式。
空接合运算符由两个连续的问号组成,它有两个操作数。
- 第一个操作数是可空类型的变量
- 第二个是相同基础类型的不可空值
- 在运行时,如果第一个操作数运算后为null,那么第二个操作数就会被返回作为运算结果
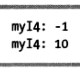
int? myI4 = null; 空接合运算符 ↓ Console.WriteLine("myI4: {0}", myI4 ?? -l); myI4 = 10; Console.WriteLine("myI4: {0}", myI4 ?? -1);
如果你比较两个相同可空类型的值,并且都设置为null,那么相等比较运算符会认为它们是相等的(==和!=)。
例如,在下面的代码中,两个可空的int被设置为null,相等比较运算符会声 明它们是相等的。
int? i1 = null,i2 = null; //都为空 if (i1 == i2) //返回true { Console.WriteLine("Equal"); }
使用可空用户自定义类型
至此,我们已经看到了预定义的简单类型的可空形式。我们还可以创建用户自定义值类型的可空形式。这就引出了在使用简单类型时没有遇到的其他问题。
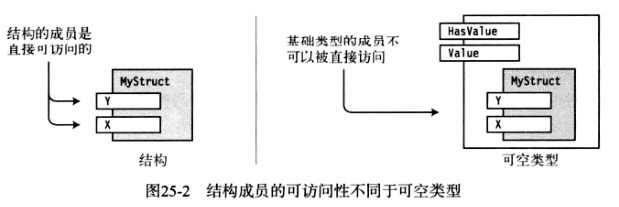
主要问题是访问封装的基础类型的成员。一个可空类型不直接暴露基础类型的任何成员。例如,来看看下面的代码和下图中它的表示形式。代码声明了一个叫做MyStruct的结构(值类型),它有两个公共字段。
- 由于结构的字段是公共的,所以它可以被结构的任何实例所访问到,如图左部分所示。
- 然而,结构的可空形式只通过Value属件暴露基础类型,它不直接暴露它的任何成员。尽管这些成员对结构来说是公共的,但是它们对可空类型来说不是公共的,如图右部分所示
struct MyStruct { public int X; public int Y; public MyStruct(int xVal,int yVal) { X=xVal; Y=yVal; } } class Program { static void Main() { MyStruct? mSNull=new MyStruct(5,10); … } }
例如,以下代码使用之前声明的结构并创建了结构和它对应的可空类型的变量。在代码的第三行和第四行中,我们直接读取结构变量的值。在第五行和第六行中,就必须从可空类型的Value属性返回的值中进行读取。
MyStruct mSStruct=new MyStruct(6,11); MyStruct? mSNull=new MyStruct(5,10); Console.WriteLine("mSStruct.X: {0}",mSStruct.X); Console.WriteLine("mSStruct.Y: {0}",mSStruct.Y); Console.WriteLine("mSNull.X: {0}",mSNull.Value.X); Console.WriteLine("mSNull.Y: {0}",mSNull.Value.Y);
Nullable<T>
可空类型通过一个叫做System.Nullable<T>的.NET类型来实现,它使用了C#的泛型特性。C#可空类型的问号语法是创建Nullable<T>类型变量的快捷语法,在这里T是基础类型。Nullable<T>接受了基础类型并把它嵌入结构中,同时给结构提供可空类型的属性、方法和构造函数。
我们可以使用Nullable<T>这种泛型语法,也可以使用C#的快捷语法。快捷语法更容易书写和理解,并且也减少了出错的可能性。以下代码使用Nullable<T>语法为之前示例中声明的 MyStruct 结构创建一个叫做mSNull的Nullable<MyStruct>类型。
Nullable<MyStruct> mSNull = new Nullable<MyStruct>();
下面的代码使用了问号语法,完全等同于Nullable<T>语法:
MyStruc? mSNull=new MyStruct();
Main 方法
每一个C#程序都必须有一个入口点--一个必须叫做Main的方法。
在贯穿本书的示例代码中,都使用了一个不接受参数并且也不返回值的Main方法。然而,一共有4种形式的Main可以作为程序的入口点。这些形式如下:
- static void Main {…}
- static void Main(string[] args) {…}
- static int Main() {…}
- static int Main(string[] args) {…}
前面两种形式在程序终止后都不返回值给执行环境。后面两种形式则返回int值。如果使用返回值,通常用于报告程序的成功或失败,0通常用于表示成功。
第二种和第四种形式允许我们在程序启动时从命令行向程序传入实参,也叫做参数。命令行参数的一些重要特性如下。
- 可以有0个或多个命令行参数。即使没有参数,args参数也不会是null,而是一个没有元素的数组
- 参数由空格或制表符隔开
- 每一个参数都被程序解释为是字符串,但是你无须在命令行中为参数加上引号
例如,下面叫做CommandLineArgs的程序接受了命令行参数并打印了每一个提供的参数:
class Program { static void Main(string[] args) { foreach (string s in args) { Console.WriteLine(s); } } }
如下命令行使用5个参数执行CommandLineArgs程序。
CommandLineArgs Jon Peter Beth Julia Tammi
↑ ↑
可执行程序名 参数
前面的程序和命令行产生了如下的输出:

其他需要了解的有关Main的重要事项如下。
- Main必须总是声明为static
- Main可以被声明为类或结构
一个程序只可以包含Main的4种可用入口点形式中的一种声明。当然,如果你声明其他方法的名称为Main,只要它们不是4种入口点形式中的一种就是合法--但是,这样做是非常容易混淆的。
Main的可访问性
Main可以被声明为public或private。
- 如果Main被声明为private,其他程序集就不能访问它,只有执行环境才能启动程序
- 如果Main被声明为public,其他程序集就可以调用它
然而,无论Main声明的访问级或所属类或结构的访问级別是什么,执行环境总是能访问Main。
默认情况下,当Visual Studio创建了一个项目时,它就创建了一个程序框,其中的Main是隐式private。如果需要,你随时可以添加public修饰符。
文档注释
文档注释特性允许我们以XML元素的形式在程序中包含文档(第19章介绍XML)。Visual Studio会帮助我们插入元素,以及从源文件中读取它们并复制到独立的XML文件中。
下图给出了一个使用XML注释的概要。这包括如下步骤。
- 你可以使用Visual Studio来产生带有嵌人了XML的源文件。Visual Studio会自动插入大多数重要的XML元素
- Visual Studio从源文件中读取XML并且复制XML代码到新的文件
- 另外一个叫做文档编译器的程序可以获取XML文件并且从它产生各种类型的文件
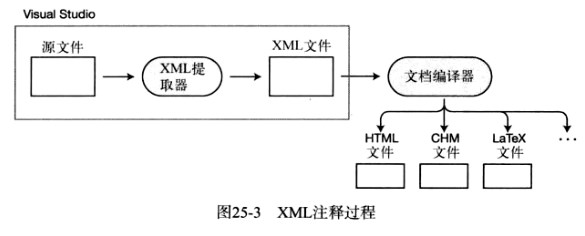
之前的Visual Studio版本包含了基本的文档编译器,但是它在Visual Studio 2005发布之前被删除了。微软公司正在开发一个叫做Sandcastle的新文档编译器,它已经被用来生成.NET框架的文档。从http://sandcastle.codeplex.com 可更详细地了解以及免费下载这个软件。
插入文档注释
文档注释从3个连续的正斜杠开始。
- 前两个斜杠指示编译器这是一行注释,并且需要从程序的解析中忽略
- 第三个斜杠指示这是一个文档注释
例如,以下代码中前4行就是有关类定义的文档注释。这里使用<summary>XML标签。在字段声明之上有3行来说明这个字段--还是使用<summary>标签。
///<summary> ← 类的开始XML标签 /// This is class MyClass, which does the following wonderful things, using /// the following algorithm. …Besides those, it does these additional /// amazing things. ///</summary> ← 关闭 XML 标签 class MyClass { ///<summary> /// Field1 is used to hold the value of … ///</summary> public int Field1 = 10; … }
每一个XML元素都是当我们在语言特性(比如类或类成员)的声明上输入3条斜杠时,ViSual Studio 自动增加的。
例如,从下面的代码可以看到,在MyClass类声明之上的2条斜杠:
// class MyClass {…}
只要我们增加了第三条斜杠,Visual Studio会立即扩展注释为下面的代码,而我们无须做任何事情。然后我们就可以在标签之间输入任何希望注释的行了。
/// <summary> 自动插入 /// 自动插入 /// </summary> 自动插入 class MyClass {…}
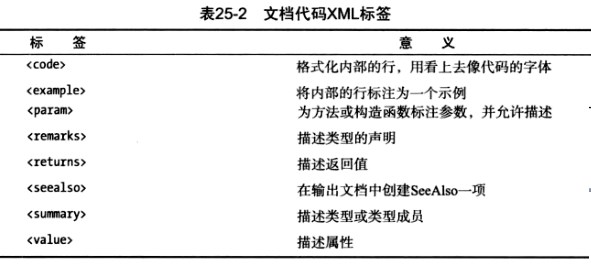
使用其他XML标签
在之前的示例中,我们看到了summay XML标签的使用。C#可识别的标签还有很多。下表列出了最重要的一些。
嵌套类型
我们通常直接在命名空间中声明类型。然而,我们还可以在类或结构中声明类型。
- 在另一个类型声明中声明的类型叫做嵌套类型。和所有类型声明一样,嵌套类型是类型实例的模板
- 嵌套类型像封闭类型(enclosing type)的成员一样声明
- 嵌套类型可以是任意类型
- 嵌套类型可以是类或结构
例如,以下代码显示了MyClass类,其中有一个叫做MyCounter的嵌套类。
class MyClass //封闭类 { class MyCounter//嵌套类 {…} … }
如果一个类型只是作为帮助方法并且只对封闭类型有意义,可能就需要声明为嵌套类型了。不要跟嵌套这个术语混淆。嵌套指声明的位置--而不是任何实例的位置。尽管嵌套类型的声明在封闭类型的声明之内,但嵌套类型的对象并不一定封闭在封闭类型的对象之内。嵌套类型的对象(如果创建了的话)和它没有在另一个类型中声明时所在的位置一样。
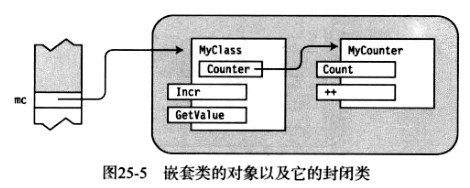
例如,下图显示了前面代码框架中的MyClass对象和MyCounter对象。另外还显式了MyClass类中的一个叫做Counter的字段,这就是指向嵌套类型对象的引用,它在堆的另一处。

嵌套类的示例
以下代码把MyClass和MyCounter完善成了完整的程序。MyCounter实现了一个整数计数器,从0开始并且使用++运算符来递增。当MyClass的构造函数被调用时,它创建嵌套类的实例并且为字段分配引用,下图演示了代码中对象的结构。
class MyClass { class MyCounter { public int Count{get;private set;} public static MyCounter operator ++(MyCounter current) { current.Count++; return current; } } private MyCounter counter; public MyClass(){counter=new MyCounter();} public int Incr(){return (counter++).Count;} public int GetValue(){return counter.Count;} } class Program { static void Main() { var mc=new MyClass(); mc.Incr();mc.Incr();mc.Incr(); mc.Incr();mc.Incr();mc.Incr(); Console.WriteLine("Total: {0}",mc.GetValue()); } }

可见性和嵌套类型
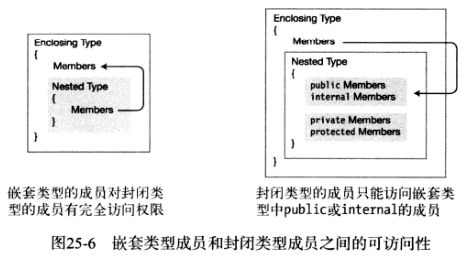
在第7章中,我们已经了解到类和类型通常有public或internal的访问级别。然而,嵌套类型的不同之处在于,它们有成员访问级别而不是类型访问级别。因此,下面的命题是成立的。
- 在类内部声明的嵌套类型可以有5种类成员访问级别中的任何一种:public、protected、private、internal或protected internal
- 在结构内部声明的嵌套类型可以有3种结构成员访问级別中的任何一种:public、internal或private
在这两种情况下,嵌套类型的默认访问级别都是private,也就是说不能被封闭类型以外的对象所见。
封闭类和嵌套类的成员之间的关系是很容易理解的,如下图所示。不管封闭类型的成员声明了怎样的访问级別,包括private和protected,嵌套类型都能访问这些成员。
然而,它们之间的关系不是对称的。尽管封闭类型的成员总是可见嵌套类型的声明并且能创建它的变量及实例,但是它们不能完全访问嵌套类型的成员。相反,这种访问权限受限于嵌套类成员声明的访问级别--就好像嵌套类型是一个独立的类型一样。也就是说,它们可以访问public或internal的成员,但是不能访问嵌套类型的private或protected成员。
我们可以把这种关系总结如下。
- 嵌套类型的成员对封闭类型的成员总是有完全访问权限
- 封闭类型的成员
- 总是可以访问嵌套类型本身
- 只能访问声明了有访问权限的嵌套类型成员
嵌套类型的可见性还会影响基类成员的继承。如果封闭类型是一个派生类,嵌套类型就可以通过使用相同的名字来隐藏基类成员。可以在嵌套类型的声明上使用new修饰符来显式隐藏。
嵌套类型中的this引用指的是嵌套类型的对象--不是封闭类型的对象。如果嵌套类型的对象需要访问封闭类型,它必须持有封闭类型的引用。如以下代码所示,我们可以把封闭对象提供的this引用作为参数传给嵌套类型的构造函数:
class SomeClass //封闭类 { int Field1=15,Field2=20; //封闭类的字段 MyNested mn=null; //嵌套类的引用 public void PrintMyMembers() { mn.PrintOuterMembers(); //调用嵌套类中的方法 } public SomeClass() //构造函数 { mn=new MyNested(this); //创建嵌套类的实例 } class MyNested //嵌套类声明 { SomeClass sc=null; //封闭类的引用 public MyNested(SomeClass SC)//嵌套类构造函数 { sc=SC; //存储嵌套类的引用 } public void PrintOuterMembers() { Console.WriteLine("Field1: {0}",sc.Field1);//封闭字段 Console.WriteLine("Field2: {0}",sc.Field2);//封闭字段 } } //嵌套类结束 } class Program { static void Main() { var MySC=new SomeClass(); MySC.PrintOuterMembers(); } }
析构函数和dispose模式
第6章介绍了创建类对象的构造函数。类还可以拥有析构函数(destructor),它可以在一个类的实例不再被引用的时候执行一些操作,以清除或释放非托管资源。非托管资源是指类似用Win32 API或非托管内存块获取的文件句柄这样的资源。使用.NET资源是无法获取它们的,因此如果我们只用.NET类,是不需要编写太多析构函数的。
关于析构函数要注意以下几点。
- 每个类只能有一个析构函数
- 析构函数不能有参数
- 析构函数不能有访问修饰符
- 析构函数名称与类名相同,但要在前面加一个波浪符
- 析构函数只能作用于类的实例。因此没有静态析构函数
- 不能在代码中显式调用析构函教。相反,当垃圾同收器分析代码并认为代码中不存在指向该对象的可能路径时,系统会在垃圾回收过程中调用析构函数
例如,下面的代码通过类Class1演示了析构函数的语法:
Class1 { ~Class1() { CleanupCode } … }
使用析构函数时一些重要的原则如下:
- 不要在不需要时实现析构函数,这会严重影响性能
- 析构函数应该只释放对象拥有的外部资源
- 析构函数不应该访问其他对象,因为无法认定这些对象是否已经被销毁
在C#3.0发布之前,析构函数有时也叫终结器(finalizer)。你可能会经常在文本或.NET API方法名中遇到这个术语。
标准dispose模式
与C++析构函数不同,C#析构函数不会在实例超出作用域时立即调用。事实上,你无法知道何时会调用析构函数。此外,如前所述,你也不能显式调用析构函数。你所能知道的只是,系统会在对象从托管堆上移除之前的某个时刻调用析构函数。
如果你的代码中包含的非托管资源越快释放越好,就不能将这个任务留给析构函数,因为无法保证它会何时执行。相反,你应该采用标准dispose模式。
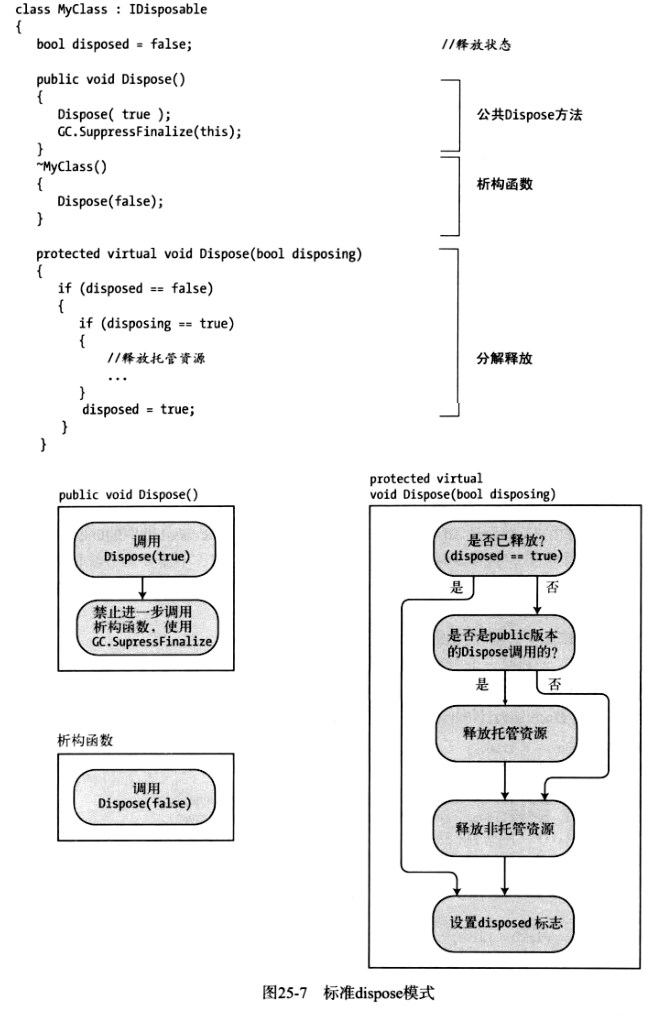
标准dispose模式包含以下特点。
- 包含非托管资源的类应该实现IDisposable接口,后者包含单一方法Dispose。Dispose包含释放资源的清除代码
- 如果代码使用完了这些资源并且希望将它们释放,应该在程序代码中调用Dispose方法。注意,这是在你的代码中(不是系统中)调用Dispose
- 你的类还应该实现一个析构函数,在其中调用Dispose方法,以防止之前没有调用该方法。
可能会有点混乱,所以我们再总结一下。你想将所有清除代码放到Dispose方法中,并在使用完资源时调用。以防万一Dispose没有调用,类的析构函数也应该调用Dispose。而另一方面如果调用了Dispose,你就希望通知垃圾回收器不要再调用析构函数,因为已经由Dispose执行了清除操作。析构函数和Dispose代码应该遵循以下原则。
- 析构函数和Dispose方法的逻辑应该是,如果由于某种原因代码没有调用Dispose,那么析构函数应该调用它,并释放资源
- 在Dispose方法的最后应该调用GC.SuppressFinalize方法,通知CLR不要调用该对象的析构函数,因为清除工作已经完成
- 在Dispose中实现这些代码,这样多次调用该方法是安全的。也就是说代码要这样写:如果该方法已经被调用,那么任何后续调用都不会执行额外的工作,也不会抛出任何异常
下面的代码展示了标准的dispose模式,下图对其进行了阐释。这段代码的要点如下:
- Dispose方法有两个重载:一个是public的,一个是protected的。protected的重载包含实际的清除代码
- public版本可以在代码中显式调用以执行清除工作。它会调用protected版本
- 析构函数调用protected版本
- protected版本的bool参数通知方法是被析构函数或是其他代码调用。这一点很重要,因为结果不同所执行的操作会略有不同。细节如下面的代码所示
比较构造函数和析构函数
下表对何时调用构造函数和析构函数进行了总结和比较。

和COM的互操作
尽管本书不介绍COM编程,但是C#4.0专门增加了几个语法改变,使得COM编程更容易。其中的一个改变叫做“省略ref”特性,允许不需要使用方法返回值的情况下,无需ref关键字即可调用COM方法。
例如,如果程序所在的机器上安装了微软Word,你就可以在自己的程序中使用Word的拼写检査功能。这个方法是 Microsoft.Office.Tools.Word 命名空间的Document类中的CheckSpelling方法。这个方法有12个参数,且都是ref参数。也就是说,之前即使你不需要为方法传入数据或是从方法取回数据,也只能为每一个参数提供一个引用变量。省略ref关键字只能用于COM方法, 否则就仍然会收到编译错误。
代码差不多应该如下,对于这段代码注意几点。
- 我只使用第二个和第三个参数,都是布尔型。但是我不得不创建两个变量,object类型的ignoreCase和alwaysSuggest来保存值,因为方法需要ref参数
- 我创建了叫做optional的object变量用于其他10个参数
object ignoreCase=true; object alwaysSuggest=false; object optional=Missing.Value; tempDoc.CheckSpelling(ref optional,ref ignoreCase,ref alwaysSuggest, ref optional,ref optional,ref optional,ref optional,ref optional, ref optional,ref optional,ref optional,ref optional);
有了“省略ref”特性,我们的代码就干净多了,因为对于不需要输出的参数,我们不再需要使用ref关键字,只需要为我们关心的两个参数使用内联的bool。简化后的代码如下:
object optional=Missing.Value; tempDoc.CheckSpelling(optional,true,false, optional,optional,optional,optional,optional, optional,optional,optional,optional);
除了“省略ref”特性,对于可选的参数我们可以使用C#4.0的可选参数特性,比之前的又简单很多,如下所示:
tempDoc.CheckSpelling( Missing.Value, true, false );
如下代码是一个包含这个方法的完整程序。要编译这段代码,你需要在本机上安装 Visual Studio Tools for Office(VSTO)并且必须为项目添加 Microsoft.Office.Interop.Word 程序集的引用。要运行这段编译的代码,必须在本机上安装 Microsoft Word。
using System; using System.Reflection; using Microsoft.Office.Interop.Word; class Program { static void Main() { Console.WriteLine("Enter a string to spell-check"); string stringToSpellCheck=Console.ReadLine(); string spellingResults; int errors=0; if(stringToSpellCheck.Length==0) { spellingResults="No string to check"; } else { Microsoft.Office.Interop.Word.Application app= new Microsoft.Office.Interop.Word.Application(); Console.WriteLine("\nChecking the string for misspellings …"); app.Visible=false; Microsoft.Office.Interop.Word._Document tempDoc=app.Document.Add(); tempDoc.Words.First.InsertBefore(stringToSpellCheck); Microsoft.Office.Interop.Word.ProofreadingErrors spellErrorsColl= tempDoc.SpellingErrors; errors=spellErrorsColl.Count; // 1.不是用可选参数 // object ignoreCase=true; // object alwaysSuggest=false; // object optional=Missing.Value; // tempDoc.CheckSpelling(ref optional,ref ignoreCase,ref alwaysSuggest, // ref optional,ref optional,ref optional,ref optional,ref optional, // ref optional,ref optional,ref optional,ref optional); // 2.使用C#4.0的“省略ref”特性 object optional=Missing.Value; tempDoc.CheckSpelling(optional,true,false, optional,optional,optional,optional,optional, optional,optional,optional,optional); //3.使用“省略ref”和可选参数特性 app.Quit(false); spellingResults=errors+" errors found"; } Console.WriteLine(spellingResults); Console.WriteLine("\nPress <Enter> to exit program"); Console.WriteLine(); } }
如果你运行这段代码,会得到如图25-8所示的一个控制台窗口,它会要求你输入希望进行拼写检査的字符串。在收到宇符串之后它会打开Word然后运行拼写检査。此时,你会看到出现了一个Word的拼写检査窗口,如图25-9所示。

<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">
作者:Moonache
出处:http://www.cnblogs.com/moonache/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号