

解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译)
解剖SQLSERVER 第十六篇 OrcaMDF RawDatabase --MDF文件的瑞士军刀(译)
http://improve.dk/orcamdf-rawdatabase-a-swiss-army-knife-for-mdf-files/
当我最初开始开发OrcaMDF的时候我只有一个目标,比市面上大部分的书要获取MDF文件内部的更深层次的知识
随着时间的推移,OrcaMDF确实做到了。在我当初没有计划的时候,OrcaMDF 已经可以解析系统表,元数据,甚至DMVs。我还做了一个简单UI,让OrcaMDF 更加容易使用。
这很好,但是带来的代价是软件非常复杂。为了自动解析元数据 例如schemas, partitions, allocation units 还有其他的东西,更不要提对于堆表和索引的细节的抽象层了,抽象层需要很多代码并且需要更多的数据库了解。鉴于不同SQLSERVER版本之间元数据的改变,OrcaMDF 目前仅支持SQL Server 2008 R2。然而,数据结构是相对稳定的,元数据的存储方式只有一点不同,使用DMVs暴露数据等等。要让OrcaMDF 正常运行,需要元数据是完好无损的,这就导致当SQLSERVER损坏的时候OrcaMDF 也是一样的。遇到损坏的boot page吗?无论SQLSERVER还是 OrcaMDF 都不能解析数据库
向RawDatabase问好
我在憧憬OrcaMDF 的未来 和如何使用他才是最有用的。我能够不断增加新的特性进去以使SQLSERVER支持什么功能他也支持,最终使得他能100%解析MDF文件。但是意义何在?当然,这是一个很好的学习机会,不过重点是,你使用软件读取数据,SQLSERVER能比你做得更好。所以,该如何选择?
RawDatabase, 参照Database 类,他不会尝试解析任何东西除非你让他去解析。
他不会自动解析schemas。他不知道系统表。他不知道DMVs。然而他知道SQLSERVER数据结构和给他一个接口他可以直接读取MDF文件。
让RawDatabase 只解析数据结构意味着他可以跳过损坏的系统表或者损坏的数据
例子
这个工具还在开发的早起,不过让我展示一下使用RawDatabase能够做什么东西。
当我运行LINQPad上的代码,他很容易的显示出结果,结果只是标准的.NET 对象。
所有的例子都在AdventureWorks 2008R2 LT (Light Weight)数据库上运行
获取单个页面
很多时候,我们只需要解析单个页面
// Get page 197 in file 1 var db = new RawDatabase(@"C:\AWLT2008R2.mdf"); db.GetPage(1, 197).Dump();

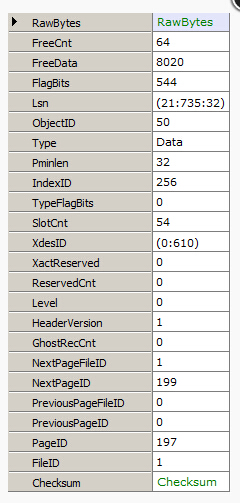
解析页头
现在我们获取到页面,我们如何把页头dump出来
// Get the header of page 197 in file 1 var db = new RawDatabase(@"C:\AWLT2008R2.mdf"); db.GetPage(1, 197).Header.Dump();
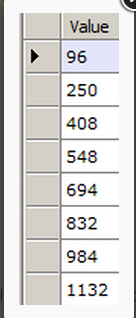
解析行偏移阵列
就像页头那样,我们也可以把页尾的行偏移阵列条目dump出来
// Get the slot array entries of page 197 in file 1 var db = new RawDatabase(@"C:\AWLT2008R2.mdf"); db.GetPage(1, 197).SlotArray.Dump();
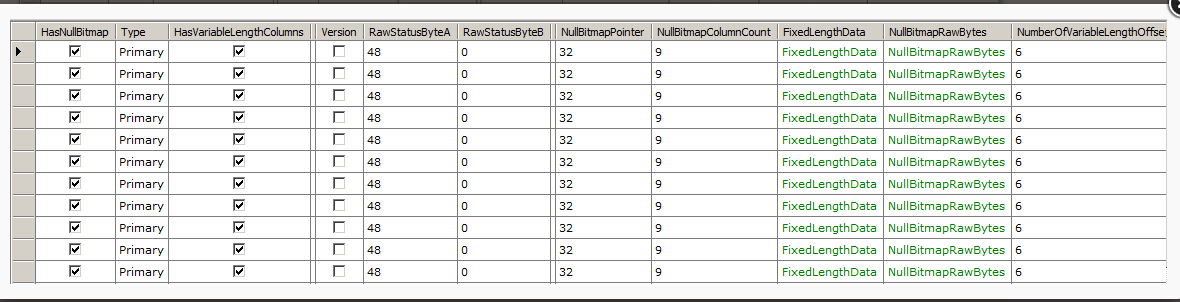
解析数据记录
当获取到行偏移条目的原始数据,你通常想看一下数据行记录的内容。幸运的是,这也很容易做到
// Get all records on page 197 in file 1 var db = new RawDatabase(@"C:\AWLT2008R2.mdf"); db.GetPage(1, 197).Records.Dump();
从记录中检索数据
一旦你得到记录,你现在可以利用FixedLengthData 或者 VariableLengthOffsetValues 属性
去获取原始的定长数据内容和变长数据内容。然而,你肯定只想获取到实际的已解析的数据值。
对于解析,OrcaMDF会帮你解析,你只需要为他提供schema.
// Read the record contents of the first record on page 197 of file 1 var db = new RawDatabase(@"C:\AWLT2008R2.mdf"); RawPrimaryRecord firstRecord = (RawPrimaryRecord)db.GetPage(1, 197).Records.First(); var values = RawColumnParser.Parse(firstRecord, new IRawType[] { RawType.Int("AddressID"), RawType.NVarchar("AddressLine1"), RawType.NVarchar("AddressLine2"), RawType.NVarchar("City"), RawType.NVarchar("StateProvince"), RawType.NVarchar("CountryRegion"), RawType.NVarchar("PostalCode"), RawType.UniqueIdentifier("rowguid"), RawType.DateTime("ModifiedDate") }); values.Dump();

RawColumnParser.Parse方法做的事情是 跟他一个schema,他帮你自动将raw bytes转换为Dictionary<string, object>,key就是从schema 那里获取到的列名,
而value就是数据列的实际值,例如int,short,guid,string等等。让你的用户给定schema, OrcaMDF 可以跳过大量的依赖的元数据进行解析,因此可以忽略可能的元数据错误带来的数据读取失败。
由于页头已经给出了 NextPageID 和 PreviousPageID属性 ,这能够让软件简单的遍历链表中的所有页面,并解析这些页面里面的数据 --他基本上是根据给定的allocation unit来进行扫描
过滤页面
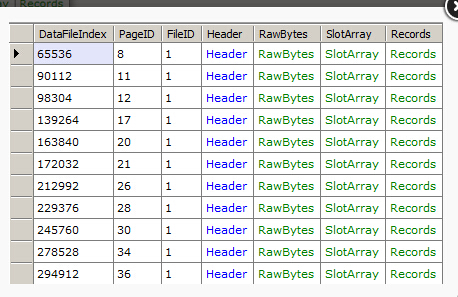
除非检索一个特定的页面,RawDatabase 也有一个页面属性能够枚举数据库中的所有页面。
使用这个属性,举个例子,获取数据库中所有的IAM页面的列表
// Get a list of all IAM pages in the database var db = new RawDatabase(@"C:\AWLT2008R2.mdf"); db.Pages .Where(x => x.Header.Type == PageType.IAM) .Dump();
并且由于这是使用LINQ技术,这很容易去设计你想要的属性。
举个例子,你可以获取所有的 index pages 和他们的 slot counts 就像这样:
// Get all index pages and their slot counts var db = new RawDatabase(@"C:\AWLT2008R2.mdf"); db.Pages .Where(x => x.Header.Type == PageType.Index) .Select(x => new { x.PageID, x.Header.SlotCnt }).Dump();
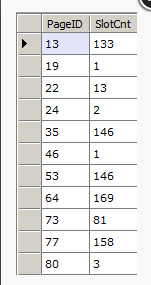
或者假设你想获得如下条件的页面
1、页面里面至少有一条记录
2、free space空间至少有7000 bytes
下面是page id, free count, record count 和 平均记录大小的输出
var db = new RawDatabase(@"C:\AWLT2008R2.mdf"); db.Pages .Where(x => x.Header.FreeCnt > 7000) .Where(x => x.Header.SlotCnt >= 1) .Where(x => x.Header.Type == PageType.Data) .Select(x => new { x.PageID, x.Header.FreeCnt, RecordCount = x.Records.Count(), RecordSize = (8096 - x.Header.FreeCnt) / x.Records.Count() }).Dump();
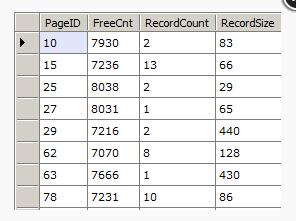
最后一个例子,,假设你只有一个MDF文件并且你已经忘记了有哪些对象存储在MDF文件里面。
不要紧,我们只需要查询系统表sysschobjs !sysschobjs 系统表包含了所有对象的数据
并且幸运的是,他的object ID 是 34。利用这些信息,我们可以把所有属于object ID 34的数据页面
过滤出来,并且从这些页面里读取记录并只需要解析这个表的前两列(你可以定义一个分部schema, 只要你在最后忽略列)
最后我们只需要把名称dump出来(当然我们可以把表里的所有列都查询出来,如果我们想的话)
SELECT * FROM sys.sysschobjs

var db = new RawDatabase(@"C:\AWLT2008R2.mdf"); var records = db.Pages .Where(x => x.Header.ObjectID == 34 && x.Header.Type == PageType.Data) .SelectMany(x => x.Records); var rows = records.Select(x => RawColumnParser.Parse((RawPrimaryRecord)x, new IRawType[] { RawType.Int("id"), RawType.NVarchar("name") })); rows.Select(x => x["name"]).Dump();
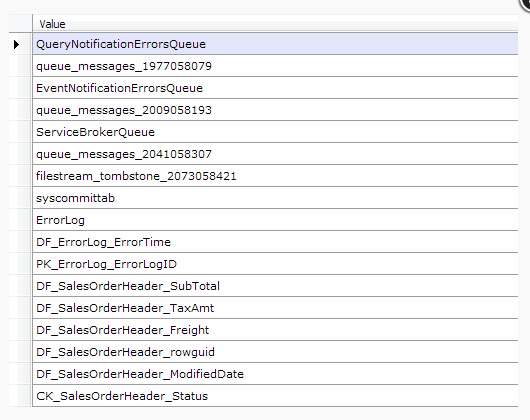
兼容性
可以看到 RawDatabase并不依赖于元数据,这很容易兼容多个版本的SQLSERVER。
因此,我很高兴的宣布:RawDatabase 完全兼容SQL Server 2005, 2008, 2008R2 , 2012.
这也有可能兼容2014,不过我还未进行测试。说到测试,所有的单元测试都是自动运行的
在测试期间使用AdventureWorksLT for 2005, 2008, 2008R2 and 2012 。
现在有一些测试demo来让OrcaMDF RawDatabase去解析AdventureWorks LT 数据库里面每个表的每条记录
数据损坏
其中一个有趣的使用RawDatabase 的方法是用来附加损坏的数据库。你可以检索特定object id的所有页面然后硬解析每个页面
无论他们是否是可读的。如果元数据损坏,你可以忽略他,你手工提供schema (输入表的每个列的列名)并且只需要沿着页面链表
或者解析IAM页面去读取堆表里面的数据。接下来的几个星期我将会 写一些关于OrcaMDF RawDatabase 的使用场景的博客,其中包括数据损坏
源代码和反馈
我非常兴奋因为最新的RawDatabase 已经添加到OrcaMDF 里面并且我希望不单只只有我一个见证他的威力。
如果你也想试一试,或者有任何想法,建议或者其他反馈,我都很乐意接受。
如果你想试用,在GitHub上签出OrcaMDF项目。一旦这个工具做得比较完美了,我会把他放上去NuGet 。
就好像OrcaMDF一样,在GPL v3 licensed 下发布
第十六篇完

 浙公网安备 33010602011771号
浙公网安备 33010602011771号